










ERROR: Could not find a version that satisfies the requirement xgboost (from versions: none) ERROR: No matching distribution found for xgboost
解决办法:
换成国内的pip源
pip install xgboost -i http://pypi.doubanio.com/simple/ --trusted-host py看提示还是报错:
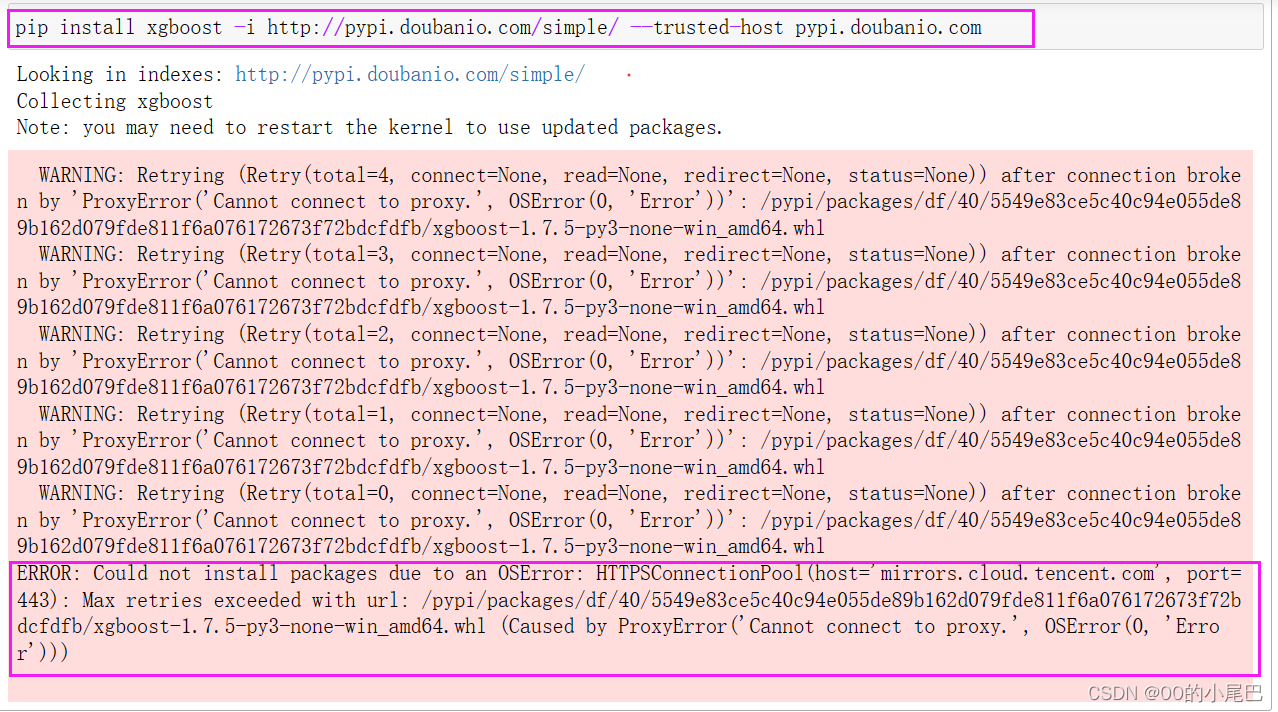
换为阿里云就可以了
pip install xgboost -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com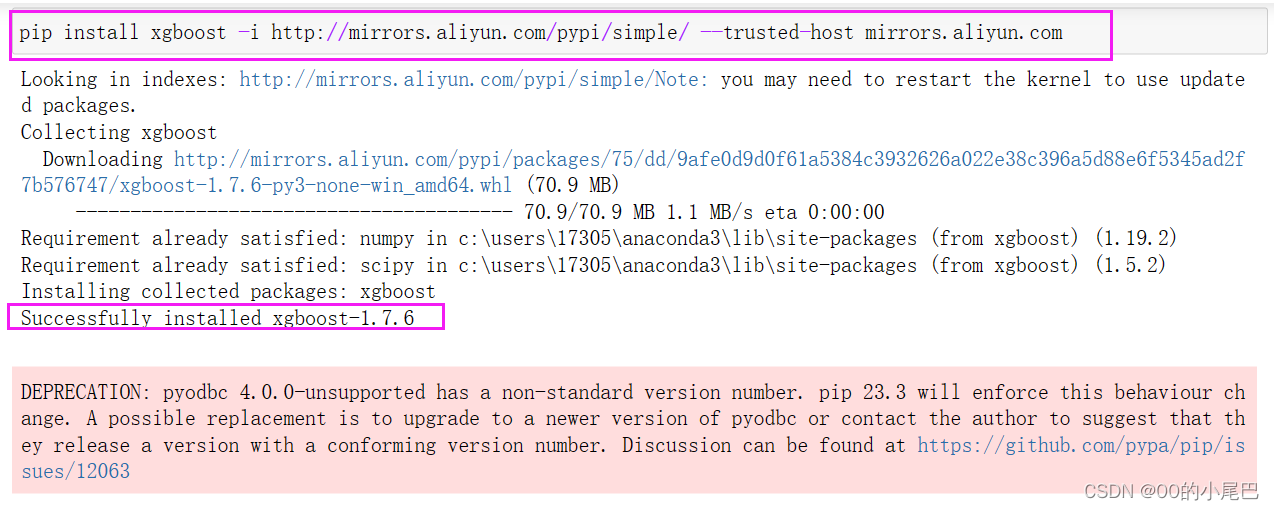

















 2471
2471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









