




 本文详细介绍了12种无监督学习聚类算法,包括K-Means、Mini-Batch K-Means、Affinity Propagation、Mean Shift、Spectral Clustering、Ward Hierarchical、Agglomerative Clustering、DBSCAN、BIRCH、OPTICS、Gaussian Mixture和HDBSCAN。这些算法根据连接性、质心和密度等模型进行区分,适用于不同场景和数据特性。文章还涵盖了算法的应用和代码实现,是数据科学家的重要参考资料。
本文详细介绍了12种无监督学习聚类算法,包括K-Means、Mini-Batch K-Means、Affinity Propagation、Mean Shift、Spectral Clustering、Ward Hierarchical、Agglomerative Clustering、DBSCAN、BIRCH、OPTICS、Gaussian Mixture和HDBSCAN。这些算法根据连接性、质心和密度等模型进行区分,适用于不同场景和数据特性。文章还涵盖了算法的应用和代码实现,是数据科学家的重要参考资料。
目录
编辑 (1)K-Means --Centroid models
(2)Mini-Batch K-Means -- Centroid models
(3)AffinityPropagation (Hierarchical) -- Connectivity models
(4)Mean Shift -- Centroid models
(5)Spectral Clustering -- Connectivity models
(6) Ward (Hierarchical) -- Connectivity models
(7) Agglomerative Clustering (Hierarchical) -- Connectivity models
(9) BIRCH -- Connectivity models
(11) Gaussian Mixture Model -- Distribution models
(12) HDBSCAN -- Density Models
一、12种聚类(无监督学习)算法说明和区分比较
聚类算法的类型(一)
- 连通性模型:顾名思义,这些模型基于数据点在数据空间中越接近,彼此之间的相似性就越高,而距离较远的数据点则相似性较低。这些模型可以采用两种方法。第一种方法是将所有数据点分类为单独的簇,然后随着距离的减小进行聚合。第二种方法是将所有数据点分类为单个簇,然后随着距离的增加进行划分。此外,距离函数的选择是主观的。这些模型非常易于解释,但缺乏处理大型数据集的可扩展性。这些模型的例子是层次聚类算法及其变体。
- 质心模型:这些是迭代聚类算法,其中相似性的概念是通过数据点与簇的质心的距离来推导的。K-Means聚类算法是一种流行的属于这一类的算法。在这些模型中,需要预先指定最终所需的簇的数量,这要求对数据集有先验知识。这些模型通过迭代寻找局部最优解。
- 分布模型:这些聚类模型基于所有簇中的数据点属于同一分布(例如:正态、高斯)的可能性。这些模型往往容易过拟合。这类模型的一个流行例子是期望最大化算法,它使用多元正态分布。
- 密度模型:这些模型在数据空间中搜索数据点密度不同的区域。它将各种不同密度的区域隔离开来,并将这些区域内的数据点分配到同一个簇中。密度模型的流行例子是DBSCAN和OPTICS。
from IPython.display import Image
Image(filename='./Lesson33-cluster.png')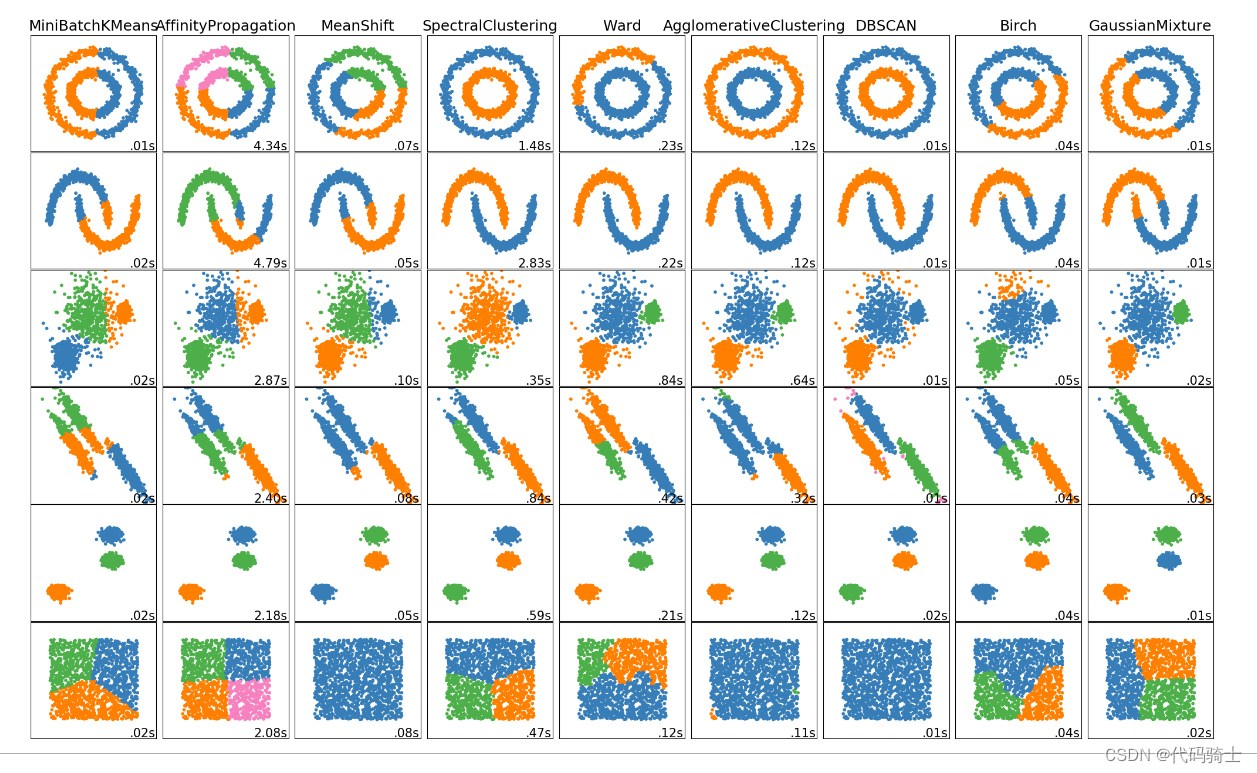 导入函数库
导入函数库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.cluster as cluster
import time
%matplotlib inline加载数据集
data = np.load('Lesson33-clusterable_data.npy')
plot_kwds = {'marker': 'o', 's': 50, 'alpha': 0.2}
plt.scatter(data.T[0], data.T[1], c='g', **plot_kwds)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False) 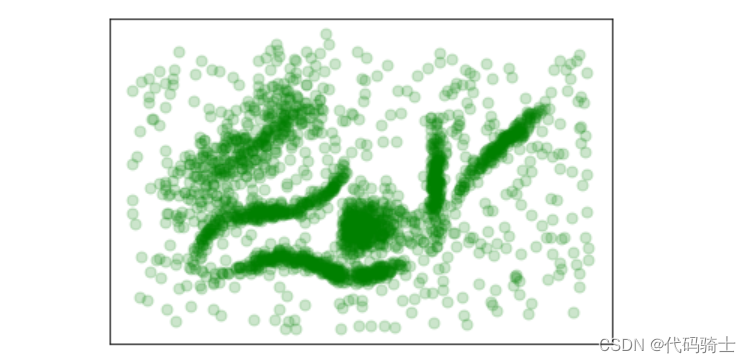
 (1)K-Means --Centroid models
(1)K-Means --Centroid models
K-Means是一种基于质心模型的聚类算法,其目标是将n个数据点划分到k个不同的簇中,使得每个数据点与其所属簇的质心距离之和最小。
算法步骤如下:
1. 随机选择k个数据点作为初始质心;
2. 对于每个数据点,计算其与所有质心的距离,并将其分配到距离最近的簇中;
3. 对于每个簇,重新计算该簇内所有数据点的平均值,将其作为新的质心;
4. 重复步骤2和步骤3,直到质心不再发生变化或达到最大迭代次数。
K-Means算法的优点在于简单、快速、易于实现,并且适用于大规模数据集。但是,它也有一些缺点,例如对初始质心的选择敏感、需要预先指定簇的数量、可能收敛到局部最优解等。
# k-means clustering
from numpy import unique
from sklearn.cluster import KMeans
from matplotlib import pyplot
# define the model
model = KMeans(n_clusters=6)
# fit the model
model.fit(data)
# assign a cluster to each example
yhat = model.predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors, **plot_kwds)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by K-Means') 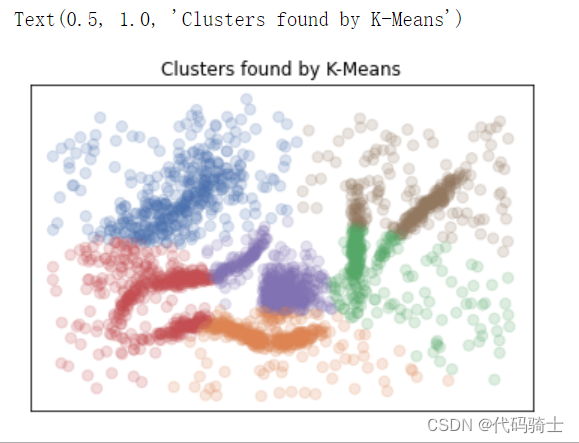

K-Means算法中心点的选取主要有以下几种常见的方法:
- 多次选取中心点进行多次试验,并用损失函数来评估效果,选择最优的一组。
- 选取距离尽量远的K个样本点作为中心点:随机选取第一个样本C1作为第一个中心点,遍历所有样本选取离C1最远的样本C2为第二个中心点,以此类推,选出K个初始中心点。
- 在k-means聚类算法中,我们还可以采用随机选择和均匀采样等方法来选择合适的初始中心点。除此之外,一些改进的k-means聚类算法,如k-means++、Mini Batch k-means等,也能提高算法的效率和精度。
这些方法的选择可以根据数据集的特性和应用需求来确定。
在sklearn库中,KMeans算法的聚类中心点是通过迭代优化算法来选取的。
具体来说,KMeans算法首先随机选择k个样本作为初始聚类中心点,然后通过计算每个数据点到各个聚类中心点的距离,将数据点分配到距离最近的聚类中心点所在的簇中。接下来,重新计算每个簇的中心点(即该簇中所有点的均值),并重复上述过程直到满足停止条件为止。
停止条件包括:达到最大迭代次数、簇内平方误差的变化小于某个阈值或者簇内平方误差的变化小于某个阈值并且新的簇中心点与旧的簇中心点之间的差异小于某个阈值。
需要注意的是,KMeans算法的初始聚类中心点是随机选择的,因此每次运行的结果可能会有所不同。
(2)Mini-Batch K-Means -- Centroid models
Mini-Batch K-Means是k-means的一个改进版本,它使用样本的小型批次而不是整个数据集来更新簇质心,这可以使其更快地处理大型数据集,并且可能对统计噪声更具鲁棒性。
# mini-batch k-means clustering
from numpy import unique
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
model = MiniBatchKMeans(n_clusters=6)
# fit the model
model.fit(data)
# assign a cluster to each example
yhat = model.predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors, **plot_kwds)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by Mini-Batch K-Means')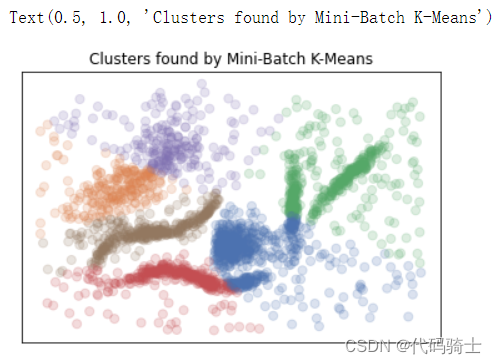

(3)AffinityPropagation (Hierarchical) -- Connectivity models
基于数据点之间的“消息传递”概念。与k-means或k-medoids等聚类算法不同,亲和力传播不需要在运行算法之前确定或估计簇的数量。类似于k-medoids,亲和力传播找到“范例”,即代表集群的输入集成员。
在统计和数据挖掘中,"消息传递"是一种信息交换方式,通过这种方式,数据点之间可以相互传递信息并更新彼此的状态。而"范例"则是亲和力传播算法中的一个核心概念,代表的是输入集合中的成员,它们是输出聚类结果的代表性样本。
具体来说,亲和力传播算法的基本思想是将全部数据点都当作潜在的聚类中心(称之为exemplar),然后数据点两两之间连线构成一个网络(相似度矩阵)。之后,算法运行过程中会进行多轮的消息传递,每一轮都会更新每个数据点的代表值(即“范例”)和每个簇的质心。这个过程会一直持续到满足一定的停止条件,例如达到预设的最大迭代次数或者簇内的平均相似度达到了一定的阈值。
from IPython.display import Image
Image(filename='./Lesson33-Illustration-of-how-affinity-propagation-works.png')
from IPython.display import Image
Image(filename='./Lesson33-preference_median.gif')
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
from numpy import unique
# fit the model
model = AffinityPropagation(damping=0.95)#set阻尼系数
model.fit(data)
yhat = model.predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors, **plot_kwds)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by AffinityPropagation')

(4)Mean Shift -- Centroid models
Mean shift算法是一种非参数聚类技术,它不需要预先知道簇的数量,也不限制簇的形状。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











