







目录
项目背景
你是否觉得与大模型的聊天方式太过于人机没有人情味儿?你是否想微调一个属于自己的大模型能用你的聊天风格去让人真假难辨?如果你也有类似的想法,此篇文章将将你的idea转化成现实、
首先你需要具备科学上网的能力。其次依次实现以下三个步骤:
- 第一步,在github上下载一个软件可以导出微信的聊天数据。
- 第二步,将导出的数据转化成可以进行模型微调的数据格式。
- 第三步,使用Unsloth和Huggingface微调你的大模型。
一、获取微信聊天数据
我使用的github软件如下:
GitHub - LC044/WeChatMsg: 提取微信聊天记录,将其导出成HTML、Word、Excel文档永久保存,对聊天记录进行分析生成年度聊天报告,用聊天数据训练专属于个人的AI聊天助手
往下滑,找到下载地址
点击下载即可。
使用方式也非常简单:
首先在电脑登录微信。
其次将手机上到聊天记录迁移到电脑。
我——>设置——>通用——>聊天记录迁移与备份——>迁移——>迁移到电脑。
最后打开刚刚下载好的软件实现聊天记录导出。
在工具栏:点击获取信息——>然后解析数据,微信信息回自动填写。
在聊天栏:选择对应的聊天记录,然后选择导出格式即可。
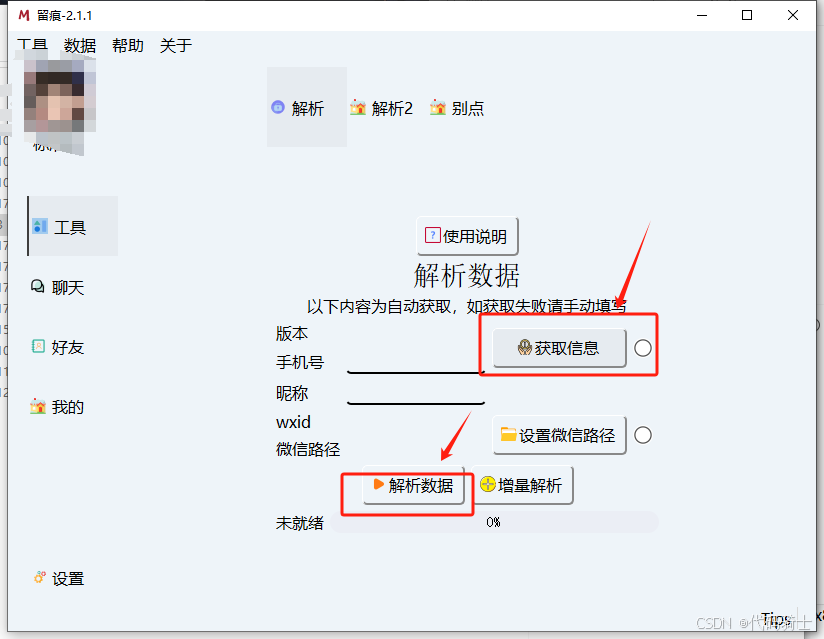
我这里的导出格式为csv,因为方便我对数据进行处理。
二、处理csv数据
一开始,我的数据用编译器打开有很多乱码,因为编码格式的问题,用记事本打开csv数据,右下角显示ANSI,属于gbk编码,不是utf8格式,需要进行编码类型转换。
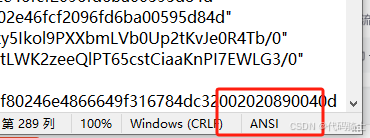
1、文件编码转换
import pandas as pd
import numpy as np
import re
# 假设你知道原文件的编码是 'ISO-8859-1',请根据实际情况调整
original_encoding = 'gbk'
input_file_path = '../data/chat.csv'
output_file_path = '../data/chat_utf8.csv'
# 读取CSV文件
df = pd.read_csv(input_file_path, encoding=original_encoding)
# 将DataFrame保存为UTF-8编码的CSV文件
df.to_csv(output_file_path, index=False, encoding='utf-8')2、特征抽取
删除没用的列。
# 选择StrContent和Remark作为特征。
new_df = df[['StrContent','Reamark']]
new_df3、数据清洗
将数据中非中文的字符去掉。
# 将new_df中StrContent列中所有与中文不相关字符删除(只保留中文汉字)
# 定义一个函数,用于仅保留中文字符,并且安全处理非字符串类型的数据
def retain_chinese(text):
if pd.isna(text) or not isinstance(text, str): # 如果是 NaN 或者不是字符串,则直接返回
return text
# 这个正则表达式将仅保留中文字符
return ''.join(re.findall(r'[\u4e00-\u9fff]+', text))
# 应用该函数到 StrContent 列
new_df['StrContent'] = new_df['StrContent'].apply(retain_chinese)
new_df.head(10)4、缺失值处理
查看整体情况
new_df.info()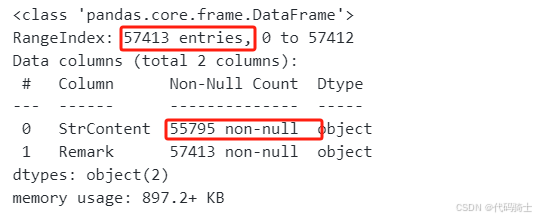
发现缺失值
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











