






三剑客和正则表达式
grep
擅长过滤,或者说查找,按行来过滤
# 为了演示下面的参数,先创建一个示例环境,也就是一个练习文件
head -50 /etc/services > text.txt
#grep参数
-n 显示行号
grep -n 'tcp' test.txt
-c 对结果行计数
grep -c 'tcp' test.txt
-i 不区分大小写
grep -i 'tcp' test.txt
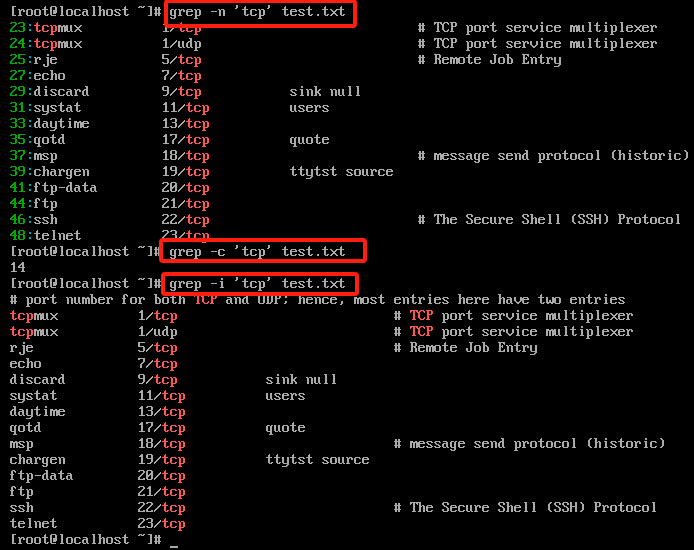
-v 反向搜搜,取反
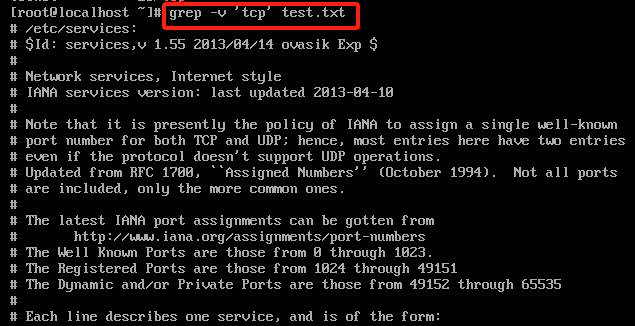
grep -v 'tcp' test.txt #将不含有udp的行全部过滤出来
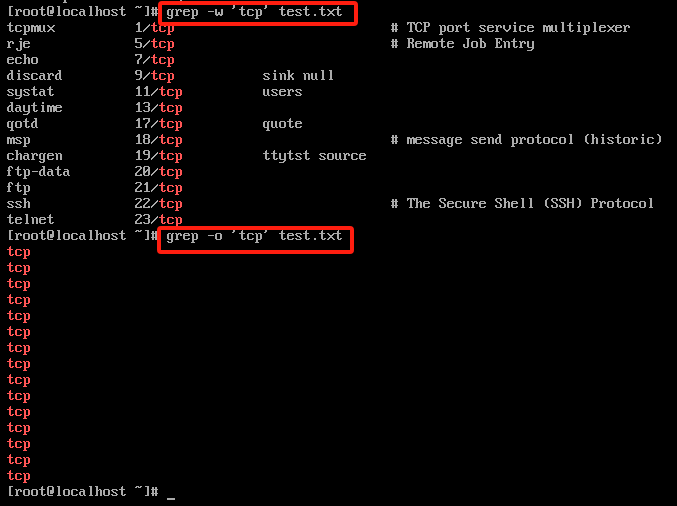
-w 精准匹配
grep -w 'tcp' test.txt
-o 只显示匹配结果
grep -o 'tcp' test.txt
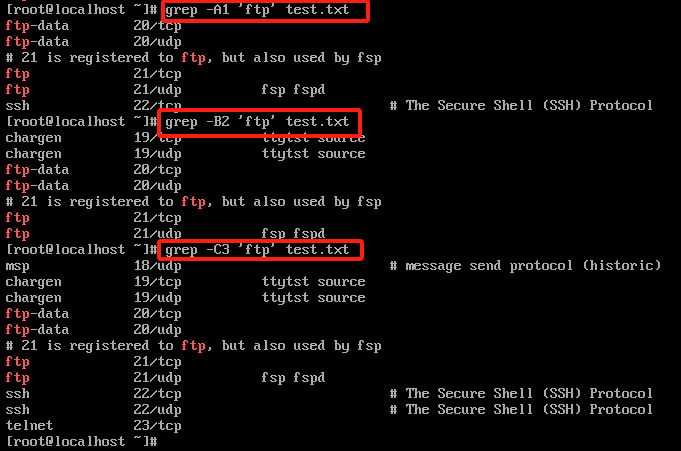
-A1 同时显示搜索结果最后一行的后面一行,A是after的简写,A后面可以加任意数字,即显示搜索结果最后一行的后面n行
grep -A1 'ftp' test.txt
-B2 同时显示搜索结果第一行的前面两行,B是before的简写,
grep -B2 'ftp' test.txt
-C3 同时显示搜索结果的前后各两行
grep -C3 'ftp' test.txt
-E 扩展正则表达式
-P 使用perl正则
sed
擅长取行和修改替换
用法:sed [-nri] [动作] 目标文件
选项与参数:
-n :使用安静(silent)模式,在一般sed的用法中,所有来自STDIN的数据一般都会被列出到终端上,但如果加上 -n 参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来
-r :sed的动作支持的是延伸型正则表示法的语法(默认是基础正则表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端
动作说明:
[n1[,n2]]function
n1,n2一般表示为行号,[,n2]表示这个参数可选,可有可无。
function:
a :指定行后面插入一行
d :删除 不会删除原文件,只打印出删除后的结果
i :指定行前面插入一行
p :打印 一般和 -n 参数一起用
s :替换 忽略大小写需要I,全局替换需要g
sed指令的动作需要写在 '' 中
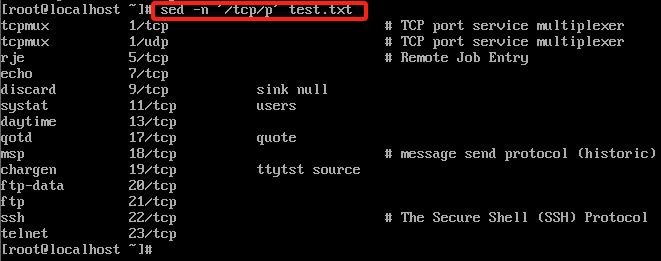
例:打印出test.txt中包含tcp的行
sed -n '/tcp/p' test.txt
替换:sed 's/原文内容/要替换的内容/[ig]' 文件名
awk
擅长取列
再创建一个测试文件3.txt,内容如下:
2 this is a test
3 Do you like awk
This's a test
10 There are orange,apple,mongo
awk默认按照空格来识别一列
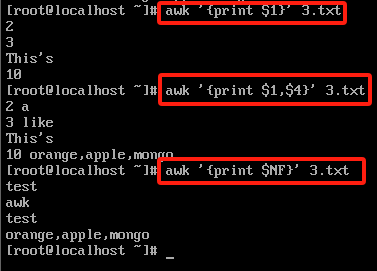
#取列
awk '{print $第几列}' 文件 #最后一列用NF表示
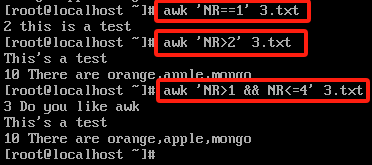
#根据行号来筛选内容 grep不会取出特定行,只能筛选哪些行有指定的内容
# a = 1 表示变量赋值,让a的值为1
# a == 1 表示判断一下a的值是不是等于1,等于1那么条件判断结果为真,不等于1那么条件判断结果为假
# 支持符号:< > == <= >=
awk 'NR==1' 3.txt
awk 'NR>2' 3.txt
awk 'NR>1 && NR<=4' 3.txt
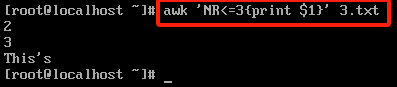
#取行的同时取列
awk 'NR<=3{print $1}' 3.txt
#指定分隔符,默认是按照空格作为分隔符
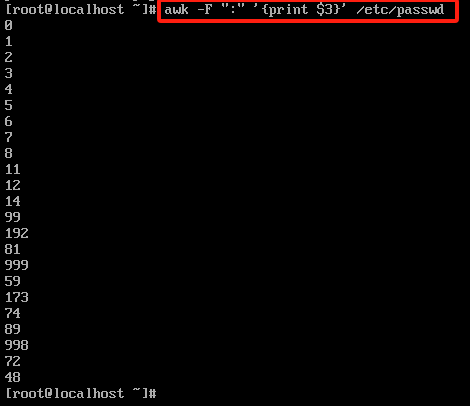
awk -F ":" '{print $3}' /etc/passwd
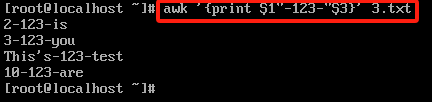
#拼凑指定文本,双引号之间原样输出
awk '{print $1"-123-"$3}' 3.txt
正则表达式
1.什么是正则表达式?
简单的说,正则表达式就是一套处理大量的字符串而定义的规则和方法,通过正则表达式这些特殊符号,可以快速的过滤、替换需要的内容。
Linux正则一般以行为单位处理的。
2.正则表达式
# 准备示例:head -100 /etc/services > test.txt
1) ^ 表示搜索以什么开头的行
grep -E '^#' test.txt #找出开头为#号的行
grep -E -v '^#' test.txt #找出开头不是#号的行
2) $ 表示搜索以什么结尾的行
grep -E 'ol$' test.txt #找出结尾为ol字母的行
3) ^$ 表示空行,不是空格
grep -E '^$' test.txt #找出所有的空白行
grep -E -v '^$' test.txt #找出所有的非空白行,如果保存一下,相当于快速删除所有空行
4) . 代表且只能代表任意一个字符
grep -E '.dp' test.txt #找出xdp(x代表任意一个字符)所在的行
5) \ 转义字符,让所有有特殊意义的符号还原成本身意思
grep -E '\.' test.txt #找出有小数点的行
6) * 重复0个或多个前面的一个字符,不代表所有
grep -E 'ww*' test.txt #找出含有w ww www wwww ...的行
7) .* 匹配所有字符 ^.* 任意多个字符开头
8) [abc] 匹配字符集合内任意一个字符 [a-z][0-9][A-Z]多选一[0,9]二选一
grep -E '[0-9]' test.txt
grep -E '[0,9]' test.txt
9) [^abc] ^在中括号里表示非,不包含a或b或c
10) {n,m} 重复n到m次前一个字符
#匹配一下ip地址:0.0.0.0 -- 255.255.255.255 这是ip地址的范围,个数上就是7-15个
grep -E '[0-9.]{7-15}' /var/log/secure #但是如果有大于7位的数字,也会匹配上
11) + 重复1到多次前一个字符
grep -E 'w+' test.txt
12) ? 重复0到多次,和*很像
13) \d perl正则,和[0-9]是一样的,grep使用perl正则的时候需要用-P参数来指定
grep -P '\d' test.txt















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









