







 本文详细介绍了如何在SPSS中通过多层感知器构建神经网络,以银行贷款数据集bankloan.sav为例,进行违约预测。首先,通过随机数生成器划分训练集和测试集,然后配置神经网络的体系结构,包括输入层、隐含层和输出层,并进行训练。结果显示,模型的分类误差和坚持分类误差表明预测效果有待提高,关键特征如工龄、地址、信用卡负债等对预测结果影响较大。
本文详细介绍了如何在SPSS中通过多层感知器构建神经网络,以银行贷款数据集bankloan.sav为例,进行违约预测。首先,通过随机数生成器划分训练集和测试集,然后配置神经网络的体系结构,包括输入层、隐含层和输出层,并进行训练。结果显示,模型的分类误差和坚持分类误差表明预测效果有待提高,关键特征如工龄、地址、信用卡负债等对预测结果影响较大。
目录:
3.用bankloan.sav数据集进行实验,对数据集个体分类:是/否违约
1.选用数据集
实验选用SPSS自带数据集:bankloan.sav,该数据集涉及某银行在降低贷款拖欠率方面的举措。
2.SPSS实现神经网络
在SPSS中实现神经网络的构建可分为两个步骤:1.产生随机数来选择样本数据集;2.生成多层感知器。
1.产生随机数来选择样本数据集
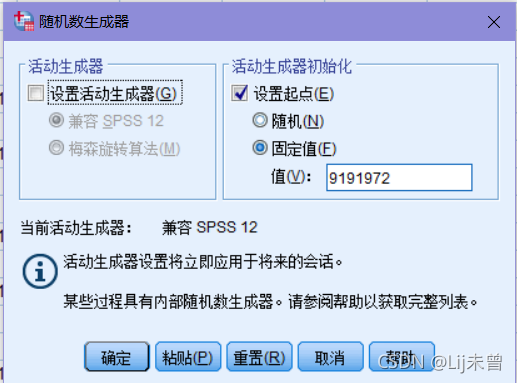
在菜单中选择“转换→随机数生成器→设置起点→固定值→值(此处需输入数值)→确定”
<用于设定随机数种子,保证在以后生成的随机数一致>
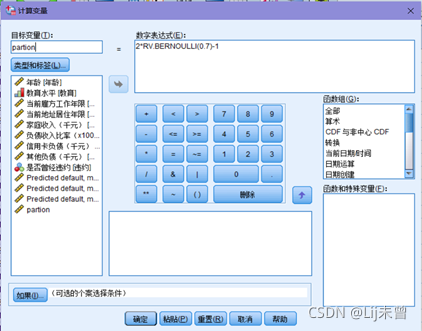
菜单“转换→计算变量→目标变量(此处需输入自定义变量名称)→数字表达式(输入“2*RV.BERNOULLI(0.7)-1”)→确定”
<用于产生bernoulli(伯努利)分布数列,数列名即为输入的自定义名,括号中的0.7是对样本数据进行划分的标准,如随机抽取数据的70%值为1,30%值为-1>
2.生成多层感知器
菜单选择“分析→神经网络→多层感知器→变量(分别选入因变量、因子和协变量,按照数据集情况选择“协变量重新标度”)→分区(有“根据个案的相对数目随机分配个案”和“使用分区变量来分配个案”两种选择)→体系结构(可选择“体系结构自动选择”或“定制体系结构”)→训练(选择“训练类型”和 “优化算法”)→输出(选择需要输出的结果显示)→保存/导出/选项→确定”
3.用bankloan.sav数据集进行实验,对数据集个体分类:是/否违约
①转换→随机数生成器→设置起点→固定值→值(输入9191972)→确定
<此处设定固定值,是为了避免训练集和测试集内数据的不随机性,在值部分输入的数值可以随意输入,但下次如果还需要生成同样的随机数据集合,需选择同样的固定值>
②转换→计算变量→目标变量(输入partion)→数字表达式(输入“2*RV.BERNOULLI(0.7)-1”)→确定
<承接上步操作生成的随机数种子,用伯努利公式,随机抽取70%为训练集,30%为检验集,也就是测试集。公式:2*RV.BERNOULLI(0.7)-1的含义是将新的变量partion划分为1或-1,直接写RV.BERNOULLI(0.7),就能把新变量partion分为0或1>
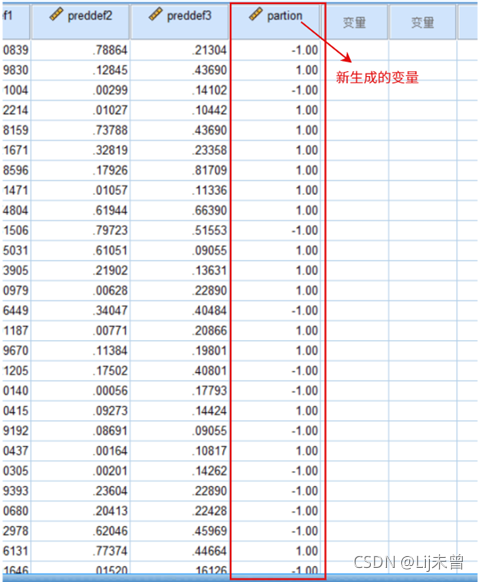
输出结果如下:
③分析→神经网络→多层感知器→变量(“是否曾经违约[违约]”选入因变量、“教育水平[教育]”选入因子和“年龄[年龄]、当前雇方工作年限[工龄]、当前地址居住年限[地址]、家庭收入(千元)[收入]、负债收入比率(×100)[负债率]、信用卡负债(千元)[信用卡负债]和其他负债(千元)[其他负债]”选入协变量, 协变量重新标度选择“标准化”)→分区(选择“使用分区变量来分配个案”,将partion选入“分区变量”)→输出(全选)→保存(勾上“保存每个变量的预测值或类别”和“保存每个变量的预测拟概率”)→确定
<这里的“协变量重新标度”有标准化、正态化、调整后正态化和无,四种选项,可根据数据集的情况来选择,对数据进行预处理>
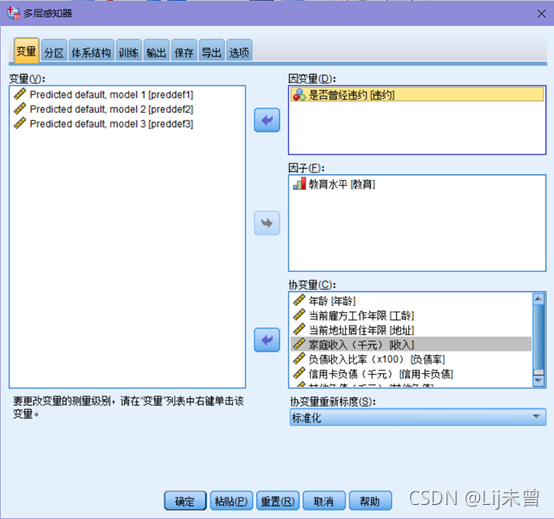
<此处选择“使用分区变量来分配个案”,并将partion选入分区变量中,意义为:接下来的模型训练直接使用之前随机划分好的训练集和测试集;这里也可以选择“根据个案的相对数目随机分配个案”这个选项,但如果之后再重复一遍操作,就不能保证下一次训练集和检验集里的数据与上一次的数据相同。使用该项目时,分区下有训练和检验两个部分,默认值为7和3,即训练集:检验集=7:3,若不想要该比例,也可以自己更改数值>
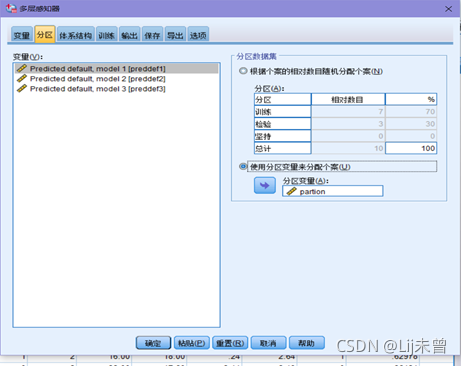
<输出部分可以全选,待结果出来之后再从输出结果中选择自己需要的结果>
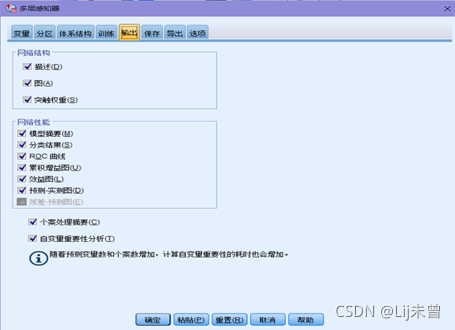
保存:
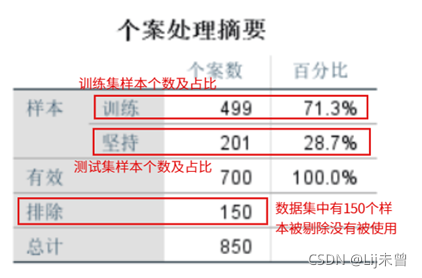
输出结果如下:
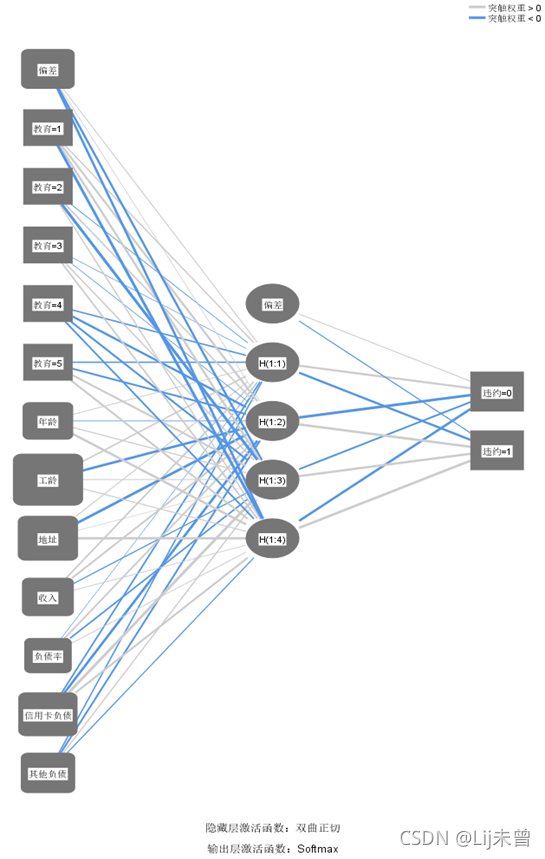
此结果输出中显示了输入层、隐含层和输出层的构成(“偏差”未写出)及使用的函数。输入层由7个协变量、1个因子(包含5种类别)和偏差组成;隐含层只有一层,且该层的单元数有4个;输出层单元数有2个,分别为是否违约。

线条颜色越深,表示权重越大;属性所在方块面积越大,表示该属性在模型中的贡献值越大。
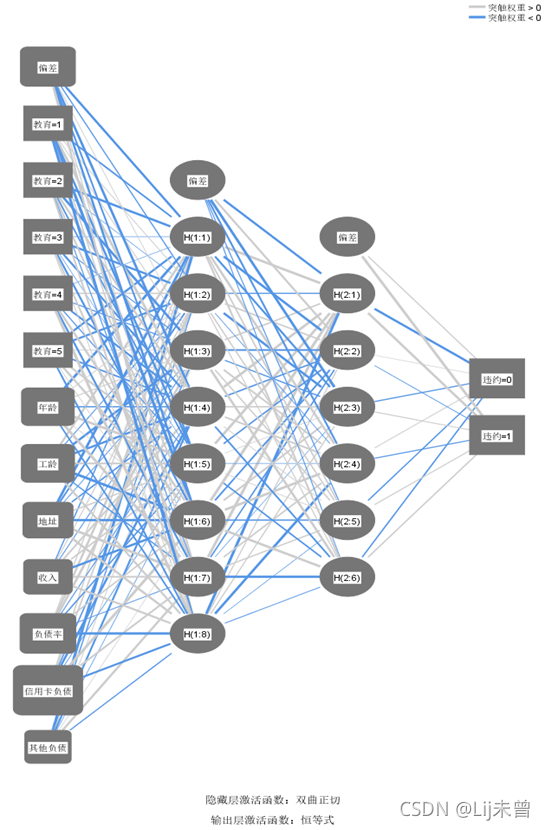
(附:也可在 “体系结构”中,选择“定制体系结构”,然后在“隐藏层数”中选择生成两层隐含层,如下图所示。但要注意的是,多增一层可能会导致数据过拟合的问题)
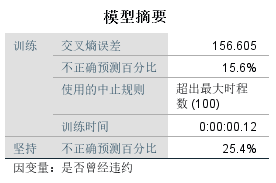
训练集的分类误差为15.6%,坚持分类误差为25.4%,可见此时的分类效果并不理想。
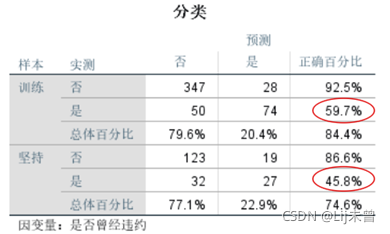
从下面红圈内的百分比可以看到,该模型的分类效果在实际看来并不理想。
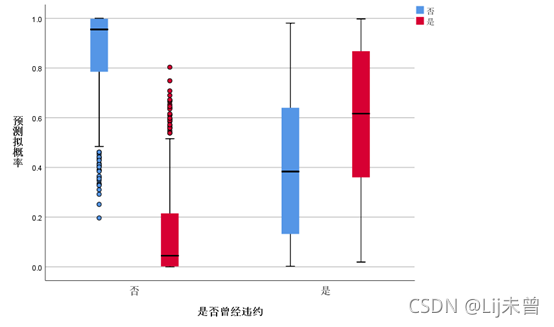
盒图:
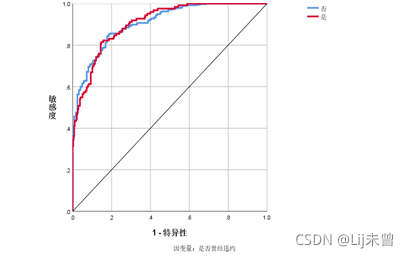
ROC曲线:

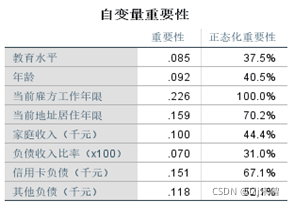
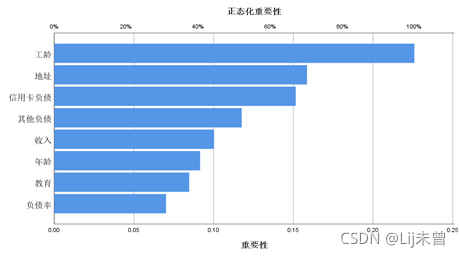
属性重要性:工龄>地址>信用卡负债>其他负债>收入>年龄>教育>负债率


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











