







 本文记录了在数据库维护中遇到的两个问题:数据插入错误1366和索引失效。针对错误1366,解决方案是调整表和行的字符集为UTF8。对于索引失效,讨论了包括前缀搜索、OR操作和列运算在内的常见原因,并强调了最佳左前缀法则的重要性。理解这些原理有助于提升数据库性能。
本文记录了在数据库维护中遇到的两个问题:数据插入错误1366和索引失效。针对错误1366,解决方案是调整表和行的字符集为UTF8。对于索引失效,讨论了包括前缀搜索、OR操作和列运算在内的常见原因,并强调了最佳左前缀法则的重要性。理解这些原理有助于提升数据库性能。
今天在日常维护中遇到几个个小问题,比较有意思
1. 在数据迁移后,重新数据失败,发现报错
ERROR 1136 (21S01): 。。。。。
2. 在接口调用时,发现查询效率极其低下,估计是索引失效
这里新建一个表复现一下
目录
1. 插入中文报错1366


新建一个test数据库以及一个emp表
create table emp(
id int unique primary key,
name varchar(10),
age int,
gender char(1)
)依次展开故事
此时insert插入数据
insert into emp values(1,'张三',12,'男'),(2,'李四',18,'女');会发现报一个错

1366,这个错误就是在mysql表中有一个或者多个字段的编码不是utf-8
解决:
通过show create table emp 查看,发现数据表中的内容为latin1字符集

于是,给这张表重新设置字符集
alter table emp default character set utf8; 
然后,重新去插入数据

依然报错,查看建表语句,发现字符集确实是utf8

是因为表设置了,但是行依然是latin1字符集
给行也设置
alter table emp change gender gender varchar(20) character set utf8;此时再去插入就OK了

2. 索引失效的小问题
在发现问题后,通过慢日志,profile等,发现了是索引失效的问题
首先给张张表建立一下索引
1. 默认的唯一主键索引
2. age的常规索引
3. name和gender的联合索引

再添加一个字段tap,不设置索引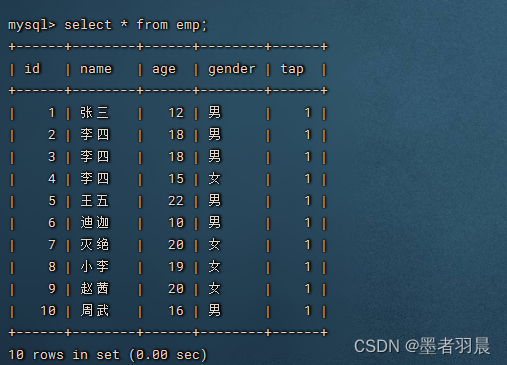
1. 首先,就是 “ 最左前缀法则 ”
这里不多演示,就是一句话,联合查询带头大哥不能不在,后边的兄弟不能乱
2. 头部模糊搜索导致索引失效
这里先演示一下
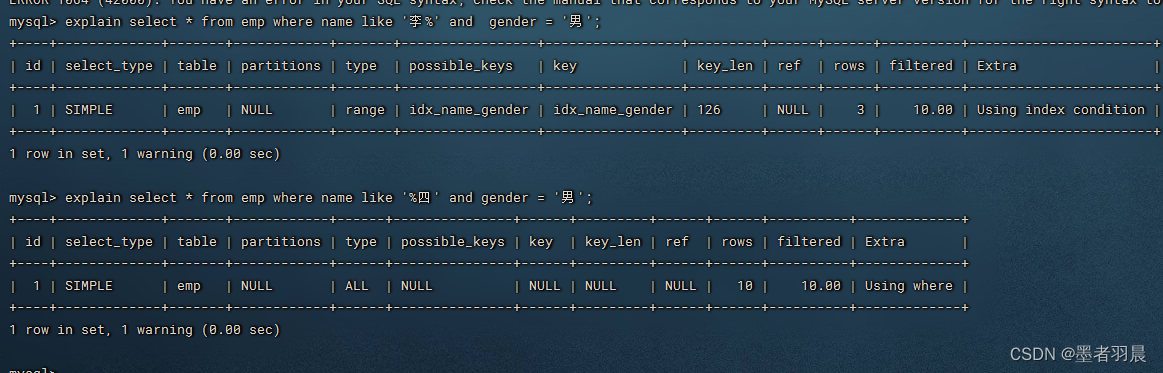
发现第一次查询时, 索引是OK的,但是当头部模糊搜索后,type成了ALL,索引失效了
所有,在日常维护和开发中,要避免对头部的模糊搜索,后续会讲原理
3. or链接导致的索引失效
演示

对于or链接来说,当or 两侧都有索引时,or后的索引就会失效
4. 对于索引列进行运算导致索引失效

此处对有索引的age进行简单运算-,但是索引就会失效
总结:
MySQL默认的InnoDB引擎使用的是B+tree的数据结构,一个节点只存一个键值对
从本质上来说,联合索引也是一个B+树,和单值索引不同的是,联合索引的键值对不是1,而是大于1个。
a, b 排序分析
a顺序:1,1,2,2,3,3
b顺序:1,2,1,4,1,2
可以发现a字段是有序排列,b字段是无序排列(因为B+树只能选一个字段来构建有序的树),在a相等的情况下,b字段是有序的。
平时中我们要对两个字段排序,是不是先按照第一个字段排序,如果第一个字段出现相等的情况,就用第二个字段排序。这个排序方式同样被用到了B+树里。
分析最佳左前缀原理
先举一个遵循最佳左前缀法则的例子
select * from testTable where a=1 and b=2分析如下:
首先a字段在B+树上是有序的,所以我们可以通过二分查找法来定位到a=1的位置。
其次在a确定的情况下,b是相对有序的,因为有序,所以同样可以通过二分查找法找到b=2的位置。
再来看看不遵循最佳左前缀的例子
select * from testTable where b=2
分析如下:
我们来回想一下b有顺序的前提:在a确定的情况下。
现在你的a都飞了,那b肯定是不能确定顺序的,在一个无序的B+树上是无法用二分查找来定位到b字段的。
所以这个时候,是用不上索引
like索引失效原理
where name like "a%"
where name like "%a%"
where name like "%a"
我们先来了解一下%的用途
%放在右边,代表查询以"a"开头的数据,如:abc两个%%,代表查询数据中包含"a"的数据,如:cab、cba、abc%放在左边,代表查询以"a"为结尾的数据,如cba
为什么%放在右边有时候能用到索引
- %放右边叫做:
前缀 - %%叫做:
中缀 - %放在左边叫做:
后缀
没错,这里依然是最佳左前缀法则这个概念
开始分析
一、%号放右边(前缀)
由于B+树的索引顺序,是按照首字母的大小进行排序,前缀匹配又是匹配首字母。所以可以在B+树上进行有序的查找,查找首字母符合要求的数据。所以有些时候可以用到索引。
二、%号放右边
是匹配字符串尾部的数据,我们上面说了排序规则,尾部的字母是没有顺序的,所以不能按照索引顺序查询,就用不到索引。
三、两个%%号
这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的。
一句话,InnoDB是B+tree数据结构,检索时,条件不满足当然就会索引失效了
当然,导致索引失效的原因远远不止这些,此上只是我早上遇到的问题

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









