







1、项目解读
随着外卖迅猛发展也带来了一定的食品安全隐患,本赛题旨在通过对O2O店铺评论的监测,加强对店铺的食品安全监管。需要从用户评论挖掘出用评论是否与安全有关,本方案将从深度学习对该自然语言处理问题做出解读,主要使用bert模型对数据进行训练,最后使用n折交叉验证结果进行模型融合。
2、数据预处理
使用tokenizer分词器进行分词,为了保证 Tokenizer 处理之后的结果和原来的字符串等长,所以这里将tokenizer进行重写
首先,对文本内容进行填充让每条文本的长度相同,方便后续切割文本。由于深度学习计算较复杂,不能直接将全部数据放入模型训练,过大的数据集无法同时加载到内存中,然而模型的性能提升又不得不使用大规模数据集,所以如何在训练过程中调用体积庞大的数据集是一个非常现实的问题。
在本方案中采用一种数据集逐批生成方法,来实时多核生成数据集并且可以立刻交付给你的深度学习模型所以要将数据进行分批处理。文本截断后,输入大小为[batch_size, max_segment, maxlen],其中batch_size是批大小,max_segment是截断后的最大句子数量,maxlen是每个句子的最大长度。这里设置batch_size=32用来把训练数据分成多个小组,分组处理数据,每次输出一个batch,基于keras.utils.Sequence这样可以节约内存,提高效率。
本方案主要使用的模型为BERT模型,故还需要将训练数据、测试数据和标签转化为模型输入格式
预训练模型是深度学习架构,已经过训练以执行大量数据上的特定任务(例如,识别图片上的分类问题)。这种训练不容易执行,并且需要大量的资源,超出许多可用于深度学习模型的人可用的资源。预训练模型是在训练结束时结果比较好的一组权重值,研究人员分享出来供其他人使用。我们可以在GitHub上找到许多具有权重的库,但是在获取预训练模型的最简单的方法可能是直接来自你选择的深度学习库。我认为预训练对于分数的影响还是很大的,在我尝试的几个不同的预训练模型中,在参数等其他变量都相同的情况下,几个预训练模型对结果的影响还是很明显的(分数最低为0.9108,最高为0.9400)。最终我选择了哈工大讯飞联合实验室发布中文RoBERTa-wwm-ext预训练模型
3、特征工程
top-k正确率
在文章多分类下的召回率中,分类任务中常见的四种指标:包括准确率、精确率、召回率和F值,top-K准确率就是用来计算预测结果中概率最大的前K个结果包含正确标签的占比,Top-K准确率考虑的是预测结果中最有可能的K个结果是否包含有真实标签,如果包含则算预测正确,如果不包含则算预测错误。所以在这里我们能够知道,K值取得越大计算得到的Top-K准确率就会越高,极端情况下如果取K值为分类数,那么得到的准确率就肯定是1。但通常情况下我们只会看模型的Top-1、Top-3和Top-5准确率。
bert模型
在本方案中,主要运用的模型为BERT模型,BERT 改进了基于微调的方法, 是 Transformer 的双向编码器表示。BERT 使用“遮蔽语言模型”(Masked Language Model, MLM)解决了前面提到的单向约束。与从左到右的语言模型预训练不同,MLM 目标允许表示融合左右上下文,这允许预训练一个深层双 Transformer。
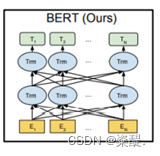
图3 BERT预训练模型架构
我们的输入表示能够在一个标记序列中清楚地表示单个文本句子或一对文本句,通过把给定标记对应的标记嵌入、句子嵌入和位置嵌入求和来构造其输入表示。在使用 BERT 进行下游任务时,最有效的方式是微调(fine-tuning),这里的关键步骤就是根据下游具体任务修改模型结构。搭建微调BERT模型,本方案直接选择BERT的[CLS]层对应的向量用来做分类。
adam学习率
Adam(Adaptive Moment Estimation)是一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,这里学习率要取得比较小。Adam 的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。Adam 方法也会比RMSprop 方法收敛的结果要好一些, 所以在实际应用中,Adam 为最常用的方法,可以比较快地得到一个预估结果。
学习率是一个超参数,它控制每次更新模型权重时响应估计错误而更改模型的程度。选择学习率具有挑战性,因为很小的值可能会导致很长的训练过程被卡住,而非常大的值可能会导致学习一组次优权重过快或训练过程不稳定。在本次实验中,我采用了“差分学习率”来提高准确率,“差分学习率”一词意味着在网络的不同部分使用不同的学习率,初始层的学习率较低,后期逐渐提高学习率。
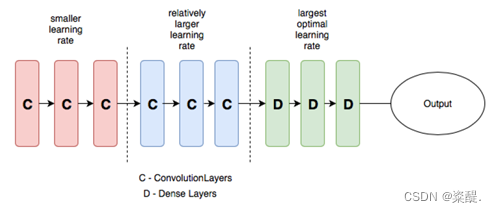
图4 带DI的CNN示例
在Keras中实现差异学习率,为了在Keras中实现差异学习,需要修改优化器源代码。修改后的函数为:
1)拆分层:拆分层1和拆分层2是分别进行第一个和第二个拆分的层的名称。
2)参数lr被修改为接受一个学习率列表-接受3个学习率列表(因为架构分为3个不同的部分)
在更新每一层的学习速率时,初始代码将迭代所有层,并为其分配一个学习速率。我们将此更改为包含不同层次的不同学习率。但最后结果可能是我的参数一直没有找到合适的,所以分数比单层低,所以最后还是选择了单层2e-5的学习率。之前也有尝试过其他优化器以及改写的adam,但效果都不怎么理想。
3、模型实现
n折交叉验证
交叉验证是一种模型验证技术,可用于评估统计分析(模型)结果在其它独立数据集上的泛化能力。它主要用于预测,我们可以用它来评估预测模型在实践中的准确度。
交叉验证的目标是定义一个数据集,以便于在训练阶段(例如,验证数据集)中测试模型,从而限制模型过拟合、欠拟合等问题,并且帮助我们了解模型在其它独立数据集上的泛化能力,挑选出那些能够在预测数据集上取得最好性能的模型。这里的验证集和训练集必须满足独立同分布条件,否则交叉验证只会让结果变得更加糟糕。
在本方案中使用交叉验证中的k 分交叉验证,可以看做是执行了多次的简单二分划分验证,然后我们在执行了 k 次不同的简单划分验证之后继续简单地将得分进行平均。数据集中的每个数据点只能在验证集中出现一次,并且在训练集中出现 k-1 次。这种做法将大大减轻欠拟合现象,因为我们使用了几乎所有的数据来训练模型,同时还能显著减少过拟合现象。
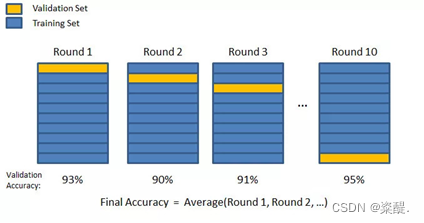
图5 k分交叉验证图示
本方案调用k分叉验证方法进行5折交叉均值融合,将原始训练集划分为5个 Part,每次取 1 个不同的 Part 出来,其余 4 个 Part 组合成一个新的训练集来训练模型,共取 5 次;每个模型训练完成之后对测试集进行预测,最后将这5 个概率求均值作为最终的概率。
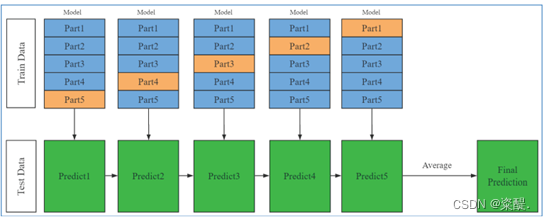
图6五折交叉融合示例图
提前终止法
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。提前终止法便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
提前终止法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算验证集的正确率,当正确率不再提高时,就停止训练。这种做法很符合直观感受,因为正确率都不再提高了,在继续训练也是无益的,只会提高训练的时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









