







目录
1、项目解读
1)赛题背景:
O2O又被称为线上线下电子商务,电商通过互联网把线下商店的消息推送给用户,消费者在线支付并在线下享受产品和服务。在这一过程中商家可以通过互联网在线上揽客,用户可以在线筛选产品和服务,是一种简单方便的新型电子商务模式。随着移动互联网+的高速发展,o2o消费也越来越吸引眼球,其中行业内估值商业的公司至少有十家。以优惠券找回老用户或者是吸引新客户进店消费是O2O的一种重要的营销方式。
合理利用o2o优惠券的投放,可以有效地增大用户的生命周期,也可以找回老用户;增加某品类的流水或者是促进用户的购买;拉新等等。但是这首营销方式也有缺点比如说随机投放优惠券会对多数的用户造成无意的干扰。
2).赛题解读:
我们的项目目标是实现优惠券的个性化投放,从而提高优惠券的和效率。本赛题提供了用户2016年1月1日至2016年6月30日时间真实的线上线下消费行为,需要预测用户在2016年7月以后15天以内的使用情况,预测投放优惠券是否核销。
本次大赛提供了四个数据集,我们需要通过训练文件进行训练模型,再通过测试文件进行预测,训练文件中包括Date_received即领取优惠券日期,而测试文件中是没有消费日期的,我们需要运用机器学习来预测其使用概率。
在本赛题中,官方使用优惠券核销预测的平均AUC(ROC曲线下面积)作为评价标准,即对每个优惠券coupon_id单独计算核销预测的AUC值,再对所有优惠券的AUC值求平均作为最终的评价标准。
3).方案概述:
首先对提供的数据进行简单的预处理,接着时间窗口划分法将数据集进行划分和打标,最后进行特征工程处理,即特征提取和模型建立与参数优化,进而完成整个数据的预测。
- 目标:预测投放的优惠券是否核销(使用)
- 实质:分类问题,也就是:是/否消费优惠券
2、数据分析与预处理
- 可视化分析数据:使用基于Pyecharts的数据可视化(各种图表)
- 具体预处理:
在实际的数据集中通常存在着缺失值、异常值等噪声数据,而且某些属性的格式也并不适合进行模型构建,所以就需要对数据进行数据预处理。通常数据预处理包括数据替换与转化、异常数据检测与剔除、缺失值处理等步骤
(1)copy函数主要用于复制对象。
(2)fillna函数用于填充缺失值。本任务将距离缺失值填充为-1。
(3)pd.to_datetime函数用于将str类型转为datetime类型。本任务将领券时间、消费时间转为datetime类型。
(4)将折扣券转为折扣率。
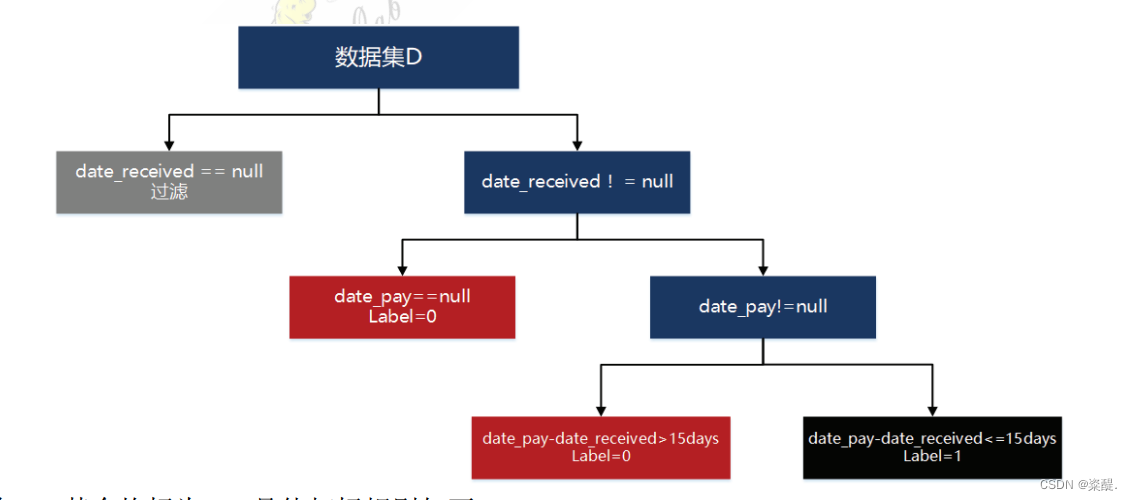
(5)为数据打上标签,将领券后15天被消费的数据标记为正例,其余标记为负例。
(6)添加几列新数据:是否为满减优惠券、领券时间为周几、领券月份、消费月份。
3、数据划分与打标
- 数据划分为:
1)训练集(TrainSet):用于训练算法模型2)验证集(ValidationSet):用于优化和选择训练好的算法模型,可选3)测试集(TestSet):测试训练与验证后的模型,也就是最终的结果输出
- 数据划分基本方法:
1)留出法(Hold-out)
a.把数据集分成互不相交的两部分,一部分是训练集,一部分是测试集。
b.保持数据分布大致一致,类似分层抽样
c.训练集数据的数量应占2/3到4/5d.为了保证随机性,将数据集多次随机划分为训练集和测试集,然后在对多次划分结果取平均。
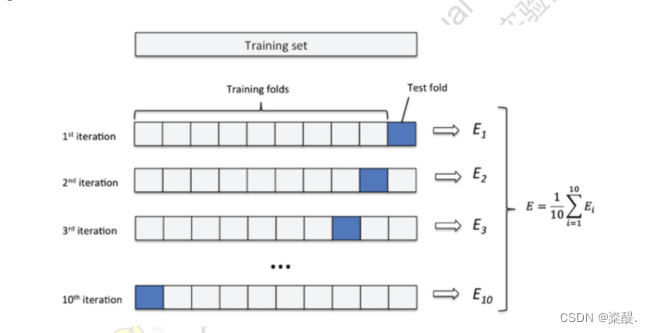
2)交叉验证法(CrossValidation)
a.将数据集随机分为互斥的k个子集,为保证随机性,p次随机划分取平均。
b.将k个子集随机分为k-1个一组剩下一个为另一组,有k种分法。
c.将每一种分组结果中,k-1个子集的组当做训练集,另外一个当做测试集,这样就产生了k次预测结果,对其取平均
d.称为p次k折交叉验证,一般取k=10,称为十折交叉验证
3)自助法(Bootstrapping)
a.适用于样本量较小,难以划分时。换句话说,样本量足够时,用自助法并不如留出法和交叉验证法,因其无法满足数据分布一致。
b.每次随机从数据集(有m个样本)抽取一个样本,然后再放回(也就是说可能被重复抽出),m次后得到有m个样本的数据集,将其作为训练集
c.始终不被抽取到的样本的比例:也就是说这保证了训练集样本数(不重复)在2/3左右
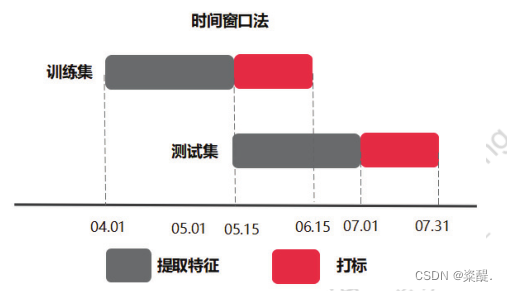
4)时间窗口划分法 (用的这个)
在实际问题中,我们的做法一般是根据历史数据去预测未来某段时间发生的事情,在这种情况下,基于时间窗口的训练集、测试集划分方案就很有用。我们根据线上线下一致性原则,将用户的历史数据按照时间窗口划分,例如选取4月到5月的数据为训练集,5月到6月的数据为测试集。一般在划分时分为标签窗口用于对待考察样本打标签,特征提取窗口用于对待考察样本提取特征。时间窗口划分法中的两个主要概念为窗口时间粒度的大小和窗口滑动的范围,粒度大小指包含了多少天,滑动的范围指从哪一天到哪一天。

- 数据打标
4、基础特征与模型
- 提取特征
以下为基础特征,需要矩阵自己挖掘更多,以提高准确率

- 用XGBoost模型输出,并调参
两篇参考:
机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
XGboost数据比赛实战之调参篇(完整流程)
xgboost的参数分为4种,general参数、learning task参数、command
line 参数、booster 参数。在o2o这个赛题中,主要是用到的是 general 参数和 booster 参数,general 参数决定了模型的样式,可以是树的,也可以是线性的,booster参数,比如eta [default=0.3] 为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。 eta通过缩减特征的权重使提升计算过程更加保守。缺省值为0.3,取值范围为:[0,1]
5、模型融合
对于要使用的模型,可以通过参数的调节来使得模型达到近优。对于树模型而言,常见的就是学习率、迭代次数的调节;对于线性模型,常见的就是迭代次数的调节。由于本赛题主要采用XGBoost进行建模,所以我们一般对max_depth、eta、num_boost_round等参数进行调节。其中eta取值范围一般设为:0.01-0.03;num_boost_round和eta的乘积取值范围:10-15之间可能比较合适;max_depth一般不超过5。
将两个xgb融合的方法
线性加权:
从算法的角度来看,则最常用的是采用加权型的混合推荐技术,即将来自不同推荐算法生成的候选结果及结果的分数,进一步进行组合(Ensemble)加权,生成最终的推荐排序结果。
具体来看,比较原始的加权型的方法是根据推荐效果,固定赋予各个子算法输出结果的权重,然后得到最终结果。很显然这种方法无法灵活处理不同的上下文场景,因为不同的算法的结果,可能在不同的场景下质量有高有低,固定加权系统无法各取所长。所以更好的思路是设置训练样本,然后比较用户对推荐结果的评价、与系统的预测是否相符,根据训练得到的结果生成加权的模型,动态的调整权重。
面试可能的问题
1、用了什么模型,介绍一下这个模型,主要调了什么参
首先需要说一说GBDT,它是一种基于boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。
XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









