






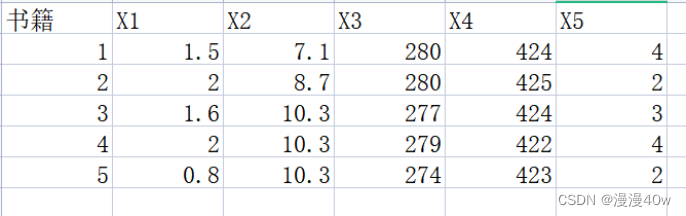
1、例题背景及其数据
数据的形式一般为多个样本的多个指标,如下是5本书在5个指标上的表现,即为5*5的矩阵。将其保存到xls表格中和空白txt文件中并保存,作为程序的原始数据。下面为相关数据。
2、运用算法分析
2.1主成分分析法
2.1.1 思想
该方法的基本思想是运用较少的变量去解释原始数据中的大部分变异,通过对原始数据相关矩阵内部结构关系的分析和计算,产生一系列互不相关的新变量。根据需要从中选取比原始变量个数少的几个新变量,这些新的变量就是所谓的主成分,它们能够充分解释原始数据的变化。因此,主成分分析法本质上是一种降维方法,也多被用于高维数据的降维处理。
2.1.2主成分分析的步骤
原始数据(X1,X2,⋯⋯, Xn)标准化,建立变量的相关系数阵,计算特征根和相应的特征向量,确定主成分的个数k(k<n),建立主成分(F1,F2,⋯⋯, Fk)的表达式,建立综合指标F的表达式。
2.1.3 MATLAB代码
%主成分分析(降维) clc,clear data = load('gd.txt');%将原始数据保存在txt文件中 data=zscore(data); %数据的标准化 r=corrcoef(data); %计算相关系数矩阵r %下面利用相关系数矩阵进行主成分分析,vec1的第一列为r的第一特征向量,即主成分的系数 [vec1,lamda,rate]=pcacov(r); %lamda为r的特征值,rate为各个主成分的贡献率 f=repmat(sign(sum(vec1)),size(vec1,1),1); %构造与vec1同维数的元素为±1的矩阵 vec2=vec1.*f; %修改特征向量的正负号,使得每个特征向量的分量和为正,即为最终的特征向量 num = max(find(lamda>1)); %num为选取的主成分的个数,这里选取特征值大于1的 df=data*vec2(:,1:num); %计算各个主成分的得分 tf=df*rate(1:num)/100; %计算综合得分 [stf,ind]=sort(tf,'descend'); %把得分按照从高到低的次序排列 stf=stf'; ind=ind'; %stf为得分从高到低排序,ind为对应的样本编号
2.1.4结果显示
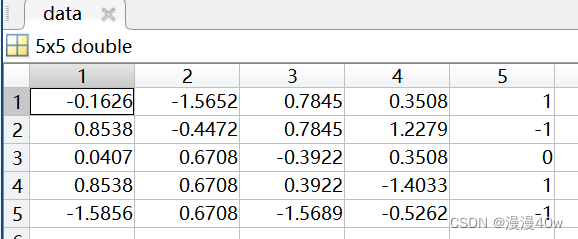
标准化结果保存在data中
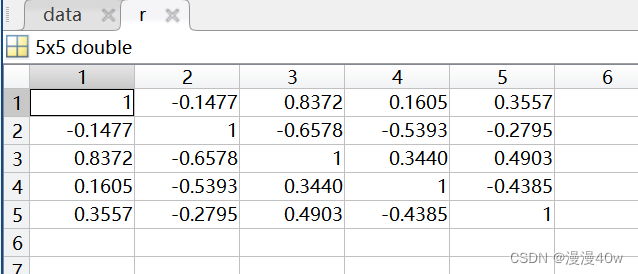
相关系数矩阵保存在r中
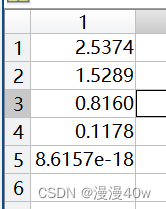
特征值保存在lamda中
特征向量保存在vec2中,每一列代表一个特征向量,对应一个主成分。
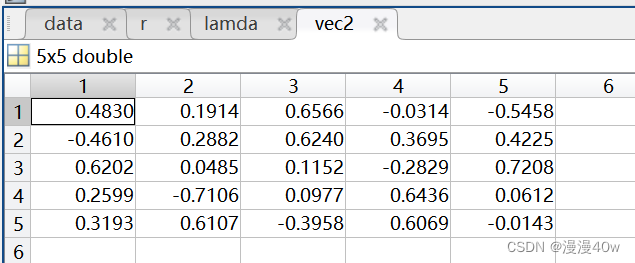
将特征向量作为系数,对应的指标作为自变量,可以得出每一个主成分的计算表达式。将标准化数据Xi代入表达式,就可以得到对应的主成分值。
形如:F1=0.4830X1+0.1914X2+0.6566X3-0.0314X4-0.5458X5
F2=-4610X1+0.2882X2+0.6240X3+0.3695X4+0.4225X5
将特征值lamda作为系数,对应的主成分作为自变量,可以确定综合评价值的表达式,F=L1F1+L2F2+……+LkFk,
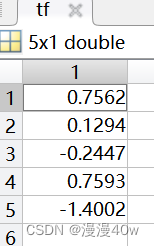
得到每个样本的综合评价值(保存在tf中)
将综合评价值从高到低排序(保存在stf中)
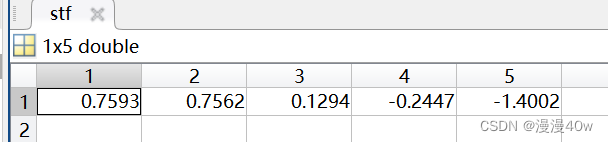
并输出对应的样本编号(保存在ind中)

2.2 因子分析
2.2.1 思想
因子分析法的运用首先是要进行相关性的分组,在不同分组中所包含的变量相关性一致,那么把相关性一致的这一组就称为其中的一个公共因子。在实证中实际要研究的就是这一小组中所涵盖的每一个变量,公共因子就是多个变量最终的集合,最终都依据关联性的大小捆绑成综合因子。既没有破坏繁杂的信息,又避免了相关性因子繁多造成的干扰,使信息得到精简。
2.2.2 步骤
1、对原始样本数据进行无纲量化处理,消除不同单位造成的差异;
2、将样本相关系数矩阵标准化后形成标准化矩阵,求出标准化矩阵的特征值,计算特征值的贡献率;
3、依据提出的公因子的累计贡献率,确认是否可以表达大部分的信息内容;
4、利用最大方差法求得因子载荷矩阵,并确定公因子;
5、建立因子得分函数,计算出每个销售的效率得分并排名。
2.2.3MATLAB代码
%因子分析
clc,clear
load gd.txt %把原始数据保存在纯文本文件gd.txt中
n=size(gd,1);
x=gd(:,[1:4]); y=gd(:,5); %分别提出自变量x1...x4和因变量x的值
x=zscore(x); %数据标准化
r=corrcoef(x) %求相关系数矩阵
[vec1,val,con1]=pcacov(r) %进行主成分分析的相关计算
f1=repmat(sign(sum(vec1)),size(vec1,1),1);
vec2=vec1.*f1; %特征向量正负号转换
f2=repmat(sqrt(val)',size(vec2,1),1);
a=vec2.*f2 %求初等载荷矩阵
num=input('请选择主因子的个数:'); %交互式选择主因子的个数
am=a(:,[1:num]); %提出num个主因子的载荷矩阵
[bm,t]=rotatefactors(am,'method', 'varimax') %am旋转变换,bm为旋转后的载荷阵
bt=[bm,a(:,[num+1:end])]; %旋转后全部因子的载荷矩阵,前两个旋转,后面不旋转
con2=sum(bt.^2) %计算因子贡献
check=[con1,con2'/sum(con2)*100]%该语句是领会旋转意义,con1是未旋转前的贡献率
rate=con2(1:num)/sum(con2) %计算因子贡献率
coef=inv(r)*bm %计算得分函数的系数
score=x*coef %计算各个因子的得分
weight=rate/sum(rate) %计算得分的权重
Tscore=score*weight' %对各因子的得分进行加权求和,即求各企业综合得分
[STscore,ind]=sort(Tscore,'descend') %对企业进行排序
display=[score(ind,:)';STscore';ind'] %显示排序结果
[ccoef,p]=corrcoef([Tscore,y]) %计算F与资产负债的相关系数
[d,dt,e,et,stats]=regress(Tscore,[ones(n,1),y]);%计算F与资产负债的方程
d,stats %显示回归系数,和相关统计量的值
2.2.4结果显示
r =
1.0000 -0.1477 0.8372 0.1605
-0.1477 1.0000 -0.6578 -0.5393
0.8372 -0.6578 1.0000 0.3440
0.1605 -0.5393 0.3440 1.0000
vec1 =
0.4684 0.6258 0.2996 -0.5470
-0.4947 0.4572 0.6018 0.4290
0.6144 0.2632 -0.2047 0.7151
0.3979 -0.5745 0.7115 0.0732
val =
2.3906
1.0969
0.5125
0.0001
con1 =
59.7652
27.4213
12.8122
0.0014
a =
0.7242 0.6554 0.2145 -0.0041
-0.7649 0.4789 0.4308 0.0032
0.9500 0.2756 -0.1465 0.0054
0.6152 -0.6017 0.5093 0.0006
请选择主因子的个数:3
bm =
0.9977 0.0016 0.0674
-0.1297 0.9467 -0.2948
0.8312 -0.5405 0.1301
0.0963 -0.2570 0.9616
t =
0.6988 -0.5833 0.4139
0.6956 0.4195 -0.5832
0.1666 0.6955 0.6989
con2 =
1.7125 1.2544 1.0330 0.0001
check =
59.7652 42.8117
27.4213 31.3606
12.8122 25.8262
0.0014 0.0014
rate =
0.4281 0.3136 0.2583
coef =
0.6971 0.3650 0.0694
0.2201 0.9544 0.2004
0.4049 -0.3252 -0.1819
-0.0362 0.3110 1.1211
score =
-0.1530 -1.6993 -0.0744
0.7699 0.0116 1.2036
0.0045 0.8918 0.6019
0.9523 0.3879 -1.4509
-1.5738 0.4081 -0.2802
weight =
0.4281 0.3136 0.2583
Tscore =
-0.6176
0.6441
0.4371
0.1546
-0.6182
STscore =
0.6441
0.4371
0.1546
-0.6176
-0.6182
ind =
2
3
4
1
5
display =
0.7699 0.0045 0.9523 -0.1530 -1.5738
0.0116 0.8918 0.3879 -1.6993 0.4081
1.2036 0.6019 -1.4509 -0.0744 -0.2802
0.6441 0.4371 0.1546 -0.6176 -0.6182
2.0000 3.0000 4.0000 1.0000 5.0000
ccoef =
1.0000 -0.2071
-0.2071 1.0000
p =
1.0000 0.7382
0.7382 1.0000
d =
0.3667
-0.1222
stats =
0.0429 0.1344 0.7382 0.4445
2.3 聚类分析
2.3.1思想
简单说,就是多个影响因素按不同联系程度分类
2.3.2步骤
输入:n个样本数据
1.随机选择k个聚类中心,
2. 针对剩余的样本数据,将其类别标签设为距离其最近的聚类中心的标签。
3. 将每个聚类中心的值更新为与该类所有样本的平均值。
4. 重复以上步骤,直到聚类中心的变化小于规定的阈值即可。
2.3.3 MATLAB代码
%聚类分析
X=xlsread('gd.xls');
X; %X为导入数据的名称(类型:数值矩阵)
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,'single');
dendrogram(Z);
T=cluster(Z,'maxclust',3)
2.3.4 结果显示
将综合评估值从高到底排序并输出相应的序号
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









