






torch.profiler
PyTorch中的torch.profile是性能分析的强大工具,在优化深度学习模型时特别有用。它提供了在训练或推理过程中花费时间和资源的见解,这可以帮助识别瓶颈或优化资源利用率。但是vllm中内置了profiler工具,所以可以直接用它的。
在vllm使用torch.profiler,vllm的/examples/offline_inference_with_profiler.py文件中,通过指定VLLM_TORCH_PROFILER_DIR,来记录离线推理的轨迹。代码如下:
import os
from vllm import LLM, SamplingParams
# enable torch profiler, can also be set on cmd line
os.environ["VLLM_TORCH_PROFILER_DIR"] = {profiler压缩包存放的位置}
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
# Sample prompts.
prompts = [
"What is your name" # 因为生成的json文件会比较大,所以就只输入一个序列
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="模型名称", tensor_parallel_size=1, gpu_memory_utilization=0.1) # 用的很小参数量的模型,所以gpu_memory_utilization只占用10%
llm.start_profile()
outputs = llm.generate(prompts, sampling_params)
llm.stop_profile()
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"{prompt!r}, {generated_text!r}")生成的trace文件是压缩包,解压后得到推理轨迹的trace.json文件。
以json文件中的一个trace event为例来分析:
{
"ph": "X", "cat": "python_function", "name": "offline_inference_with_profiler.py(19): <module>", "pid": 28878, "tid": 28878,
"ts": 2532126956206.363, "dur": 344524.169,
"args": {
"Python parent id": null, "Python id": 16, "Ev Idx": 4492
}
}cat表示这是一个什么程序;
name是这次调用的名称;
ts是时间戳;
dur是调用的持续时间;
args中的python parent id表示上一级调用的python id,本例中为null表示它没有上一级调用
如果不用vllm进行推理也可以,代码如下:
import torch.profiler
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model_name = "模型路径"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
model.eval()
# 定义输入
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
with torch.no_grad():
outputs = model(**inputs)
prof.export_chrome_trace("输出文件名称.json")输出的结果同样是一个json文件,格式和上面的相同。
trace.json可视化:
非常简便,只需要在https://ui.perfetto.dev/中,点击open trace file,选中上面生成的json文件即可。
transformer和vllm推理的不同
基于上面的torch.profiler,基于transformers库和vllm库加载模型,并执行相同的推理任务,生成两个不同的trace.json文件。
模型使用的是llama2-7b-chat-hf。注意,使用vllm推理时,一定要用llama和huggingface兼容的hf版本,否则会出现一大堆错误。
在可视化网页查看transformers的轨迹文件:

生成每一个token的时候都调用了llama2-7b的32层transformer
在可视化网页查看vllm的轨迹文件: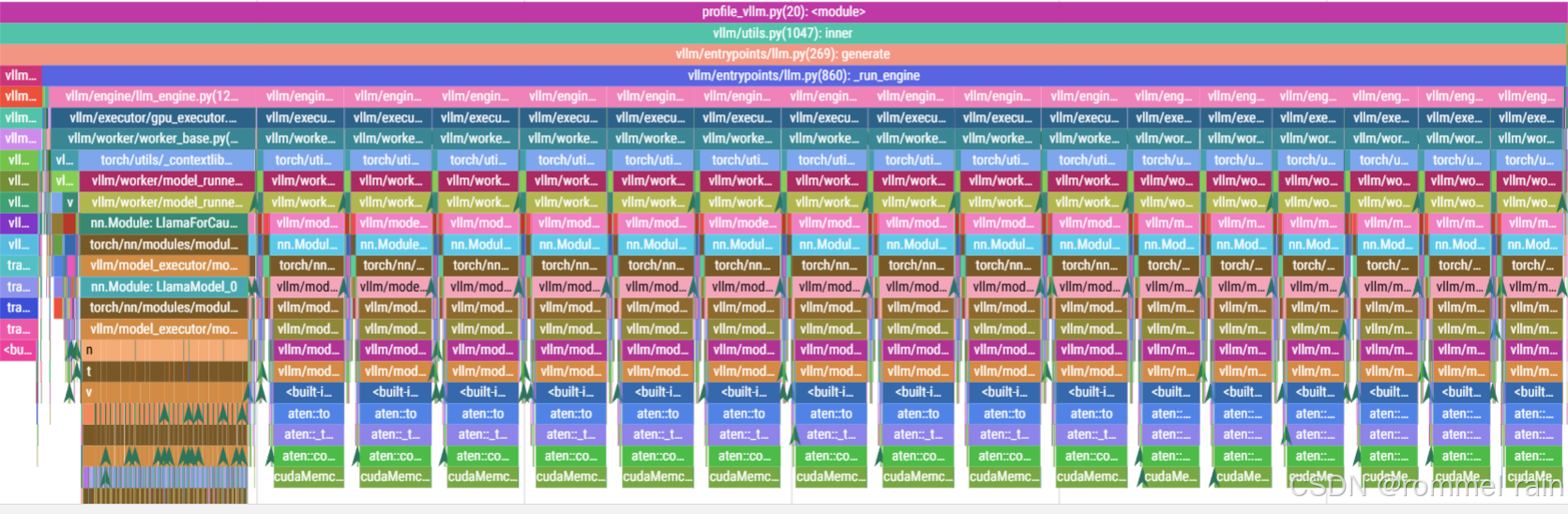
![]()
发现它调用了17次llm_engine中的step函数,调用次数和生成的token个数相同,说明它是自回归地生成token。
生成第一个token的时候调用了llama2-7b的32层transformer,后面生成每个token时都没有再调用。
transformers和vllm之所以有这样的区别,chatgpt的解释是:
在 Transformer 结构中,后续 token 的生成依赖于前面已生成 token 的上下文表示。对于每层 Transformer 层的 self-attention 机制来说,只需在每次生成新的 token 时基于先前的上下文状态更新当前 token 的表示,而无需重新计算整个序列。因此,vllm利用缓存机制(常见的 KV 缓存,即 key 和 value 的缓存)来存储每层 Transformer 的上下文状态,从而在生成后续 token 时只需调用更新步骤而不必重复调用所有的层。

















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









