







本文是我看论文时写的知识点摘要
基础知识:
P问题( Polynomial ):有多项式时间算法,O(n^k)
NP问题( nondeterministic Polynomial ):如果可以在多项式级的时间里去验证问题的任意给定解是否有效,则该问题是NP问题
NPC问题:1.是NP问题2.所有NP问题可以归约成该问题并得到解
NP-hard:满足2但不满足1
贝叶斯公式 :P (A|B)=P (B|A)*P (A)/P (B)
先验概率:统计得到的
后验概率:P(X|Y)
正则化regularization:
我理解成约束化,通过在最小化经验误差函数(训练集上的误差,得不到真实的期望风险)上加上约束项解决过拟合。
作用:解决过拟合、降低模型复杂度、让先验知识融入到模型的学习。
监督学习目标函数:
w
∗
=
arg
min
w
∑
i
L
(
y
i
,
f
(
x
i
;
w
)
)
+
λ
Ω
(
w
)
监督学习目标函数:w^{*}=\arg \min _{w} \sum_{i} L\left(y_{i}, f\left(x_{i} ; w\right)\right)+\lambda \Omega(w)
监督学习目标函数:w∗=argwmini∑L(yi,f(xi;w))+λΩ(w)
前面一项为loss函数(loss函数不同拟合不同,有最小二乘、SVM、Boosting等),后面的Omega就是正则化函数(对权重向量w约束化)
L0正则化:
∥
x
∥
0
=
∑
i
=
1
k
∣
x
i
∣
0
\|x\|_{0}=\sum_{i=1}^{k}\left|x_{i}\right|^{0}
∥x∥0=i=1∑k∣xi∣0
表示向量中非0元素的个数。用L0约束就是让w的大部分元素为0,即稀疏(适合稀疏编码,视觉皮层就是稀疏编码,计算简便)但是是nphard,一般用L1。
L1正则化(Lasso回归):
∥
x
∥
1
=
∑
i
=
1
k
∣
x
i
∣
\|x\|_{1}=\sum_{i=1}^{k}\left|x_{i}\right|
∥x∥1=i=1∑k∣xi∣
向量中各个元素绝对值之和,使用L1范数可以使得权值稀疏。
L2正则化(Ridge回归/岭回归):
∥
x
∥
2
=
∑
i
=
1
k
∣
x
i
∣
2
\|x\|_{2}=\sqrt{\sum_{i=1}^{k}\left|x_{i}\right|^{2}}
∥x∥2=i=1∑k∣xi∣2
用于改善过拟合
对比
1.L1会趋向于产生少量的特征,而其他的特征都是0(稀疏性),而L2会选择更多的特征,这些特征都会接近于0(平滑性)。
2.L1范数可以使权值稀疏,方便特征提取。L2范数可以防止过拟合,提升模型的泛化能力。
参考:正则化
AlexNet
模型分割和GPU技术方面暂时用不到就先跳过,以后用到再看
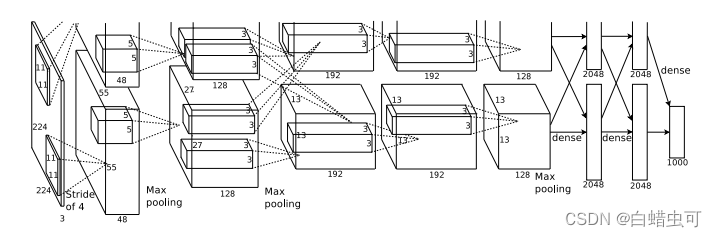
1.输入224 *224 *3通道的图片,卷积核大小为11 *11 *3通道,步长为4,padding为2
为什么会有padding?
后面的大小为55 * 55,padding=0时,(224-11+2*0)/4+1=54,不符合
增加padding后图片大小是227 * 227
计算参考:https://blog.csdn.net/liuweiyuxiang/article/details/88111943
2.得到的特征映射组大小为55 * 55 * 48通道(一个GPU48个,两个GPU96通道,代表语义空间种类):
先卷积:卷积核5*5共256个,步长为1,padding=2,输出为(55+2 *2 -5)/1+1=5,即55 *55 * 128(一个GPU)
LRN
后重叠最大池化:池化方格大小:3*3,步长2,输出特征映射组:(55-3)/2+1=27,即27 *27 * 128
3.得到的特征映射组大小为27 * 27 * 128通道(语义变多并且两个GPU开始发生交互):
先卷积:卷积核3*3共384个,步长为1,padding=1,输出为(27+2 *1 -3)/1+1=27,即27 *27 * 192(一个GPU)
后重叠最大池化:池化方格大小:3*3,步长2,输出特征映射组:(27-3)/2+1=13,即13 *13 * 256(两个GPU的通道 *2)
4.得到的特征映射组大小为13 * 13 * 192通道:
卷积:卷积核3*3共384个,步长为1,padding=1,输出为(13+2 *1 -3)/1+1=13,即13 *13 * 192(一个GPU)
5.得到的特征映射组大小为13 * 13 * 192通道:
卷积:卷积核3*3共256个,步长为1,padding=1,输出为(13+2 *1 -3)/1+1=13,即13 *13 * 128(一个GPU)
6.2个GPU分别得到两个特征映射,大小13 *13 *128通道:
重叠最大池化:池化方格大小:3*3,步长2,输出特征映射组:(13-3)/2+1=6,即6 *6 * 256(两个GPU的通道 *2),两个GPU的图拼到一起
全连接:用4096个神经元对6 * 6 *256个通道的特征映射进行全连接,期间进行dropout
7.同上,全连接。
8.用1000个神经元对前4096个神经元进行全连接,再通过一个softmax进行输出得到1000个类别的概率
为什么会有全连接?(查到的)
1.将特征映射组转化为向量
2.提取高层语义特征
3.方便交给分类器分类/回归
部分要点:
1.ReLU:max(0,x)
- 饱和与非饱和函数:当x趋向于正无穷与负无穷时,函数的导数都趋近于0,此函数即为饱和函数如Sigmoid和tanh。
- 非饱和函数优点:1.解决梯度消失。 2.加快收敛速度。例如ReLU,本文激活函数使用ReLU。
2.Local Response Normalization:
ReLU不需要输入归一化来防止饱和,但作者认为LRN的引入可以提高泛化能力。没深入读。
3.overlapping pooling:
一般的池化窗口sizeX=stride,重叠池化窗口sizeX>stride。
效果:略微减轻了过拟合,减少了错误率。
避免过拟合方法
1.dropout:
以0.5的概率将每个隐藏层神经元输出设为0。文章里在前面两个全连接层用了。
论文作者认为dropout相当于产生了多个模型进行融合,后来他们认为dropout类似于L2正则项。
2.Data Augmentation:
数据增强方法,用了截取,平移,翻转还有在RGB像素值集上做PCA,丰富数据集。(256 * 256 大小随机扣成224 * 224大小的图)
模型效果:
好就对了
实验复现:
还没做














 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









