







一、机器人动作执行主要三种方法
在机器人学习(Robot Learning)领域,机器人动作执行主要有三种方法:包括直接回归、分类预测和生成式模型。
- 回归
连续值问题,一个输入对应一个数值输出,不能解决多模态Multi-Modal Action问题,即一个输入可以对应多个输出。
- 分类预测
离散值,将可能的数值分成几个区间,进行离散预测。在预测Multi-Modal Action的时候(解决了多模态行为),人们倾向于采用离散预测,将连续值问题转化为分类问题,但这样做存在问题: 一次只能向前预测一步, 而实际需求是希望一次性预测多步动作;在处理高维空间时,预测成本非常高。
- 生成模型
生成模型都可以预测连续的多模态分布,但很多生成模型的问题是训练不稳定。
基于Diffusion Model的生成模型方法具有一个重要的优势,即训练非常稳定, 不管怎么训,最终都能得到一个可以work的模型。
在Robot Learning领域,机器人操作比较常用的两个路径是强化学习(Reinforcement Learning)和模仿学习(Imitation Learning)。
二、基础术语
- 操作(Manipulation)和移动(Locomotion)
移动(Locomotion):下肢操作,专注于机器人自身的运动能力,主要考虑机器人的物理特性和动力学(例如关节、足部接触力等)。移动任务通常涉及对机器人本体的建模和控制(如步态规划、平衡控制等),较少依赖外界环境中的动态变化。
操作/操控/操纵(Manipulation):上肢操作,涉及与各种各样的物体进行交互,pick取&place放,others,每个物体都具有独特的物理特性,如重心、摩擦力和动力学。这些在模拟器中难以准确模拟,即便能够模拟,精度通常较低,速度较慢。需要考虑的因素较多,其中一个关键区别是在机器人操作中除了需要考虑机器人本身的物理特性,同时还要适应复杂多变的环境和被操作物体。
在机器人学习(Robot Learning)中,移动(Locomotion)有更好的效果,而在操作(Manipulation),存在最大的问题是 Sim2Real Gap(从仿真到现实的差距), 即从模拟环境(仿真器)到现实环境的迁移过程中,模型的性能通常会因为物理模拟的不精确而显著下降。
-
DOF(自由度, Degrees of Freedom)
定义:机器人关节或末端执行器在空间中独立运动的方向数量。例如:
工业机械臂:通常6-DOF(3个平移+3个旋转),实现任意位姿控制。
无人机:4-DOF(俯仰、横滚、偏航+垂直升降)。
关键点:DOF越多灵活性越高,但控制复杂度指数级上升。 -
末端执行器(End-Effector)
定义:机器人直接与环境交互的部件(如夹具、焊枪、吸盘)。
案例:手术机器人达芬奇系统的微型手术钳末端可完成7-DOF微操作。 -
正向运动学 vs. 逆运动学
正向运动学(FK): 已知关节角度,计算机器人末端位姿。
公式: x = f ( θ ) x = f(\theta) x=f(θ),其中 θ θ θ 为关节角度向量。
逆运动学(IK): 已知末端目标位姿,反推关节角度。
痛点:可能存在多解或无解,需引入优化约束(如关节限位、能耗最小化)。
三、仿真工具
- MuJoCo
特点:高精度物理引擎,支持接触力学和柔性体仿真,适合训练控制策略。
典型应用:OpenAI的Dactyl(机械手解魔方)。 - PyBullet
优势:开源免费,兼容ROS,适合快速原型验证。 - Isaac Sim
亮点:NVIDIA开发,支持光线追踪和大规模并行仿真(1000个机器人同时训练)。
四、示教种类
-
直接动觉示教: 手把手指导;
-
遥操作示教: 通过工具VR眼镜远程操作示范;
-
视频演示示教: 通过学习视频中的动作进行模仿学习。
示教+模仿
示教越直接,差异越小,模仿难度越小。
示教越自然,差异越大,模仿难度越大。

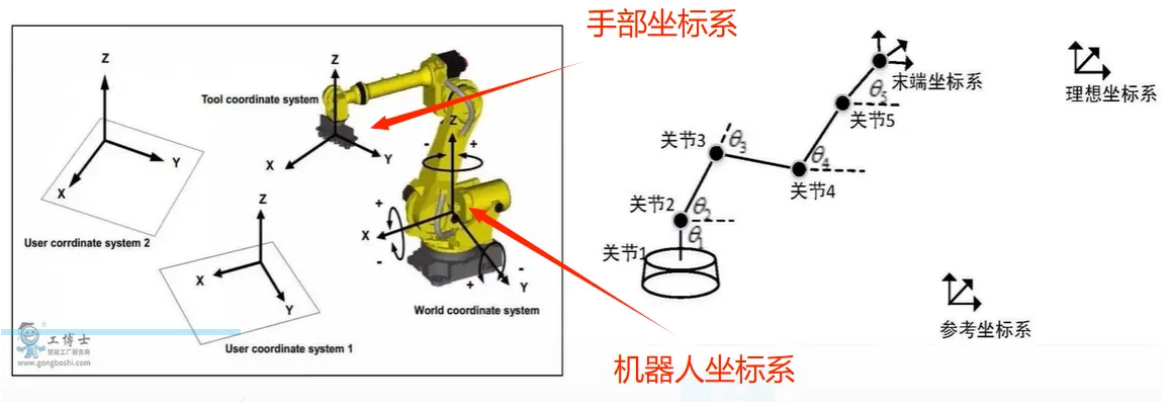
三大坐标系:机器人坐标系,手部(末端)坐标系,相机坐标系
ROS系统:机器人操作系统
适合多人开发。支持C++、python语言。
有ROS1和ROS2。ROS1开源社区更好一点,个人科研用得多;工业追求文档,ROS2用得多。
五、相关入门论文
1、UMI
论文名: Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots UMI
斯坦福团队提出通用操作接口UMI,是一种数据收集和策略学习框架,可以直接从人类演示中学习有能力且可泛化的操纵策略。该项工作解决了机器人训练中“先有鸡还是先有蛋”的难题。
2、Aloha —— ACT
论文名: 【aloha1】Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware ALOHA
【aloha2】Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation Mobile ALOHA
斯坦福ALOHA团队推出的动作序列预测算法ACT(Action Chunking with Transformers)。
动作分块算法ACT,ALOHA + ACT解决现有机器人昂贵且难以做精确任务的问题。抽象精细的操作任务,比如穿线扎带或开槽电池。
动作分块(action chunking),将一系列动作组合在一起作为一个块,最终作为一个单元执行。作者将chunk size设置为固定的k步。每k步,agent获取一次输入,预测后k步的动作,然后按照顺序执行这些动作。具体
3、Diffsusion Policy
论文名: Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
扩散策略
扩散策略是一种新颖的机器人行为生成方法,它将机器人的视觉运动策略表示为条件去噪扩散过程。
使用了模仿学习,即由人类遥控机器人执行动作,收集数据,并通过学习将其转化为策略。这种学习过程通过遥控机器人完成一系列动作开始,然后将其迁移到机器人身上。输入数据包括过去几帧的图像,而输出涉及对未来动作的预测。
输入是观测值obs,输出是一系列使用扩散模型生成的动作actions。

4、Diff-Control: A Stateful Diffusion-based Policy for Imitation Learning
Diff-Control
解决动作生成的一致性问题。
论文提出了一种基于扩散模型(Diffusion Model)的策略,称为Diff-Control。该策略通过引入ControlNet作为状态转移模型,能够捕捉动作的时间动态,从而使策略具有“状态性”(stateful)。这意味着Diff-Control在生成新动作时,能够考虑之前生成的动作序列,从而确保动作的一致性和连贯性。
动作序列的时间一致性指的是在机器人执行任务时,生成的动作序列在时间上是连贯和合理的,能够根据之前的动作状态来调整当前和未来的动作,从而确保整个动作流程的顺畅和有效。简单来说,时间一致性要求机器人在执行任务时,能够“记住”之前的动作,并根据这些动作来做出合理的后续决策,而不是每次只根据当前的观察来生成独立的动作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









