






 本文档介绍了形式语言与自动机理论的基础知识,包括文法的定义、推导规则、最左推导和最右推导的概念,以及如何构造文法来表示特定语言,如偶整数集合。此外,还探讨了文法的句型、简单短语和句柄等概念,并给出了多个推导示例。
本文档介绍了形式语言与自动机理论的基础知识,包括文法的定义、推导规则、最左推导和最右推导的概念,以及如何构造文法来表示特定语言,如偶整数集合。此外,还探讨了文法的句型、简单短语和句柄等概念,并给出了多个推导示例。
练习2-1
-
给出下述句子的推导,并画出语法树:
(1) John ate the big peanut
(2) John ate the big brown peanut
(3) John ate the big roasted peanut
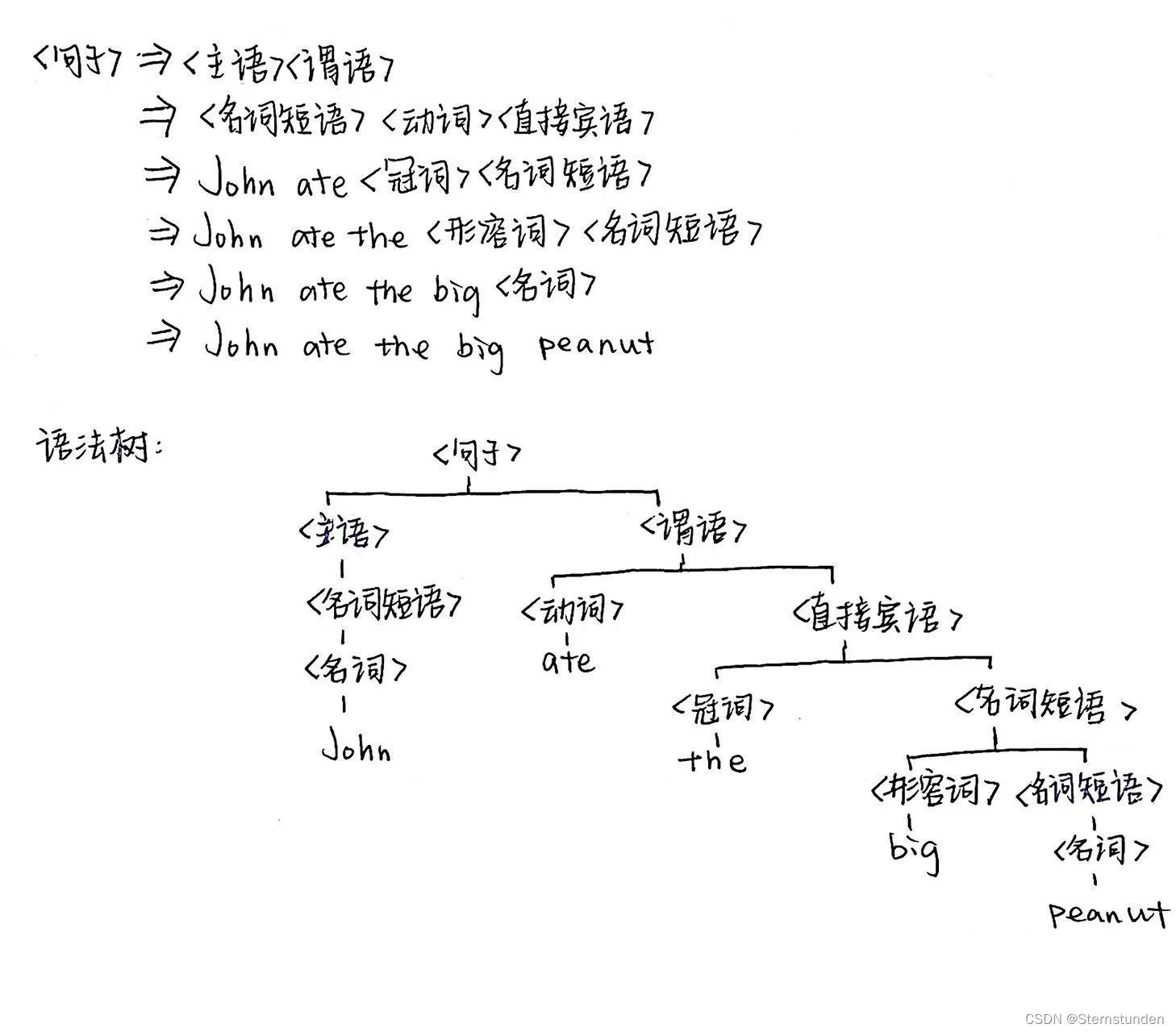 (2)(3)推导方式类似,区别为最后的<名词短语>继续推导为<形容词><名词短语>
(2)(3)推导方式类似,区别为最后的<名词短语>继续推导为<形容词><名词短语> -
利用规则2-1,除最左推导外,给出句子"The big elephant ate the peanut"的另外两种推导(其中一种为最右推导)。
注:所谓最左(最右)推导,是指在推导的每一步中,若符号串中有两个以上语法成分(非终结符号)同时存在时,总是选取最左边(最右边)的语法成分进行推导。后面将给出这两种推导的形式定义。


练习2-2
-
令A={0,1,2},又令x=01,y=2和z=001,写出如下符号串及其长度:
xy={012} |xy|=3
xyz={012001} |xyz|=6
x4={01010101} |x4|=8
(x3)(y2)={01010122} |(x3)(y2)|=8
(xy)2={012012} |(xy)2|=6
-
令A={0,1,2},写出集合A+和集合A*的7个最短的符号串。
A+: 0,1,2,00,01,02,10
A*: ε,0,1,2,00,01,02
-
试证明:A+=AA*=A*A
由定义:A+ =A1∪A2∪A3∪......∪An∪...... ={x, x2, x3, ... ,xn,... |x∈A}
A* =A0∪A+={ε, x, x2, x3, ... ,xn,... |x∈A}
故 A ={x, x2, x3, ... ,xn,... |x∈A}
={xε, xx, xx2, x3, ... ,xn,... |x∈A}
=AA*
={εx, xx, x2x, x3x, ... ,xnx,... |x∈A}
=A*A
练习2-3
-
写一文法,使其语言是偶整数的集合。
G = <Vn,Vt,P,Z> = <{F,S,D,N}, {0,1,2,...,9,+, -}, P, S>
P:
F ::= + | -
S ::= FND | FD | ND | D
D ::= 0 | 2 | 4 | 6 | 8
N ::= NN | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
-
写一文法,使其语言是偶整数的集合,但不允许有以0开始的偶整数。
G = <Vn,Vt,P,Z> = <{F,S,K,D,N}, {0,1,2,...,9}, P, S>
P:
F ::= + | -
S ::= KD | D
K ::= KN | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
D ::= 0 | 2 | 4 | 6 | 8
N ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
-
设文法G的规则是< A > ::= b< A >|cc, 试证明:cc, bcc, bbcc, bbbcc ∈ L[G]。
A => cc ∈ L[G]
A => bA => bcc ∈ L[G]
A => bA => bbA => bbcc ∈ L[G]
-
有文法G3[<表达式>]:
<表达式> ::= <项> | <表达式>+<项> | <表达式>-<项>
<项> ::= <因子> | <项>*<因子> | <项>/<因子>
<因子> ::= (<表达式>) | i
试给出下列符号串的推导:i, (i), i* i, i* i+i , i*(i+i)。
<表达式> => <项> => <因子> => i
<表达式> => <项> => <因子> => (<表达式>) => (<表达式>) => (<项>) => (<因子>) => (i)
<表达式> => <项> => <因子> => <项>*<因子> => <项> *i => <因子> *i => i *i
<表达式> => <表达式>+<项> => <表达式>+i => i*i+i
<表达式> => <表达式>+<项> => <表达式>+<因子> => <表达式>+ (<表达式>) => <表达式>+ (<表达式>+<项>) => i+(i+i)
9. 设文法G为
N ::= D |ND
D ::= 0|1|2|3|4|5|6|7|8|9
(1) G的语言L(G)是什么?
(2) 给出句子0125和783的最右推导(规范推导)和最左推导。
(1) L(G) = {0,1,2,3,4,5,6,7,8,9}
(2) 0125: 最右:N => ND => N5 => ND5 => N25 => ND25 => N125 => D125 => 0125
最左:N => ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0125
783: 最右:N => ND => N3 => ND3 => N83 => D83 => 783
最左:N => ND => NDD => DDD => 7DD => 78d =>783
知识点
从集合的角度看语言(符号、符号串)
符号: 字母表中的元素 例: a,b,c (–用英文字母表开头的小写字母和字母表靠近末尾 的大写字母来表示符号)
符号串: 符号的有穷序列 例:a, aa, ac, abc,... (用英文字母表靠近末尾的小写字母来表示符号串)
文法的形式定义:4元组
文法::G=<Vn,Vt,P,Z>
推导: 直接推导:v=>w
间接推导:v=>u0=>u1=>u2=>...=>un=w
规约
递归规则:规则右部具有和左部相同非终结符号。
简单短语: Z=*=>xUy且U=>u,称u是一个相对于非终结符号U的句型w的简单短语。
句柄: 任一句型最左简单短语称为该句型的句柄。
构造文法的基本技巧 :枚举、重复生成、对称
推导树:给定文法,推导句子
复习
文法:G=(Vn,Vt,P,Z)
-
若有规则U ::= u,且 v=x Uy,w=xuy, 则有推导 xUy =>xuy ,即 v =>w
-
注意弄清 =>【上面是+,*,|,+|】的概念
-
文法G对应的语言L(G[Z]) = {x| x∈Vt*, Z+=>x}
-
递归U =+= ...U...
-
有句型w=xuy,若Z=*=>xUy,且U=+=u,则u是句型w相对于U的短语
-
简单短语: Z=*=>xUy且U=>u,称u是一个相对于非终结符号U的句型w的简单短语。
-
句柄: 任一句型最左简单短语称为该句型的句柄。

















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









