






lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
(这里推荐一个比较好用的浏览器插件Xpath Helper,开启插件后按住shift键即可开始进行xpath表达式匹配,如果觉得表达式太长,可以将前面的前缀删除)
附上插件图标:

就像下面这样(记住要按住shift键)

言归正传,在获取想要的数据后进行打印会发现出现了乱码,就像下面这样
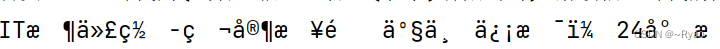
我们对数据的类型进行打印,发现xpath匹配后返回的是一个<class ‘lxml.etree._ElementUnicodeResult’>的结果,我们的解决办法是使用encode将lxml对象编码成 ‘ISO-8859-1’ 字节串,然后在使用decode其解码成’ utf-8’ 字符串。

然后进行打印,发现编码已经恢复正常了

最后附上自己编写的代码:
"""
获取IT时代网的图片、标题、简介,附代码及运行成功截图。(网址:https://www.ittime.com.cn/)
"""
import requests
from lxml import etree
#获取网页内容
def get_html(url):
headers = {
"headers":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.9 Safari/537.36",
"refer":"https://www.ittime.com.cn/"
}
html = requests.get(url,headers=headers).text
return html
#解析网页内容
def parse_html(html,url):
"""
图片 //a[@class="logo"]/img/@src 获取图片的基准url,后面需要进行拼接
标题 //title/text() 获取里面内容
简介 //meta[@name="description"]/@content
"""
html = etree.HTML(html)
#图片
image =url + html.xpath('//a[@class="logo"]/img/@src')[0]
#标题
title = html.xpath('//title/text()')[0].encode('ISO-8859-1').decode('UTF-8')
#简介
intro = html.xpath('//meta[@name="description"]/@content')[0].encode('ISO-8859-1').decode('UTF-8')
info = {"image":image,"title":title,"intro":intro}
return info
#存储网页或者打印网页内容信息
def save(info,filename):
#这里选择打印信息,不选择进行存储信息
print("爬取网站:" + filename)
print("标题:" + info["title"])
print("简介:" + info["intro"])
print("图片地址:" + info["image"])
if __name__ == "__main__":
url = "https://www.ittime.com.cn"
html = get_html(url)
info = parse_html(html,url)
filename = "IT时代网"
save(info,filename)















 4113
4113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









