







文章目录
Linux磁盘与文件系统管理
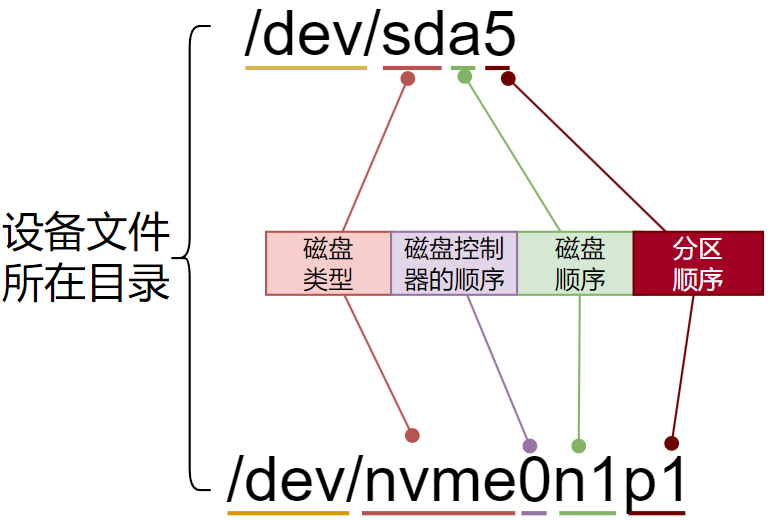
在Linux系统中,“一切皆文件”是一个经典的观念,意味着Linux将许多系统资源和设备都视为文件来对待。一般都存储在/dev目录下
物理设备的命名规则
常见的设备类型
| 硬件设备 | 文件名称 |
|---|---|
| IDE设备 | /dev/hda,hdb,hdc… |
| SCSI/SATA/U盘 | /dev/sda,sdb,sdc… |
| NVME设备 | /dev/nvme0n1,/dev/nvme01n2 … |
| virtio设备 | /dev/vda,vdb,vdc… |
| 软驱 | /dev/fd0,fd1 … |
| 打印机 | /dev/lp0,lp1,lp2 … |
| 光驱 | /dev/cdrom或者/dev/sr0,sr1,sr2… |
| 鼠标 | /dev/mouse |
| 磁带机 | /dev/st0或者/dev/ht0 |
磁盘设备名称解释
磁盘分区表
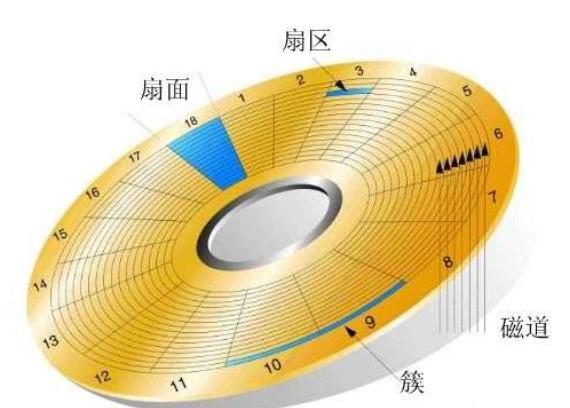
磁盘主要由碟片、机械手臂、磁头与主轴马达所组成,而数据的写入其实是在碟片上面。
碟片上面又可细分出扇区与磁道两种单位,其中扇区的物理大小设计有两种,分别是 512 字节与 4K 字节
整块磁盘的第一个扇区特别重要,因为它记录了整块磁盘的重要信息。
早期磁盘第一个扇区里面含有的重要信息我们称为 MBR(Master Boot Record)格式,但是由于近年来磁盘的容量不断扩大,造成读写上的一些困扰,甚至有些 2TB 以上的磁盘分区已经让某些操作系统无法存取,因此后来又多了一个新的磁盘分区格式,称为 GPT(GUID partition table )
那么分区表又是啥?其实你刚刚拿到的整块硬盘就像一根原木,你必须要在这根原木上面切割出你想要的区段,这个区段才能够再制作成为你想要的家具,如果没有进行切割,那么原木就不能被效地使用。同样的道理,你必须要针对你的硬盘进行分区,这样硬盘才可以被你使用。
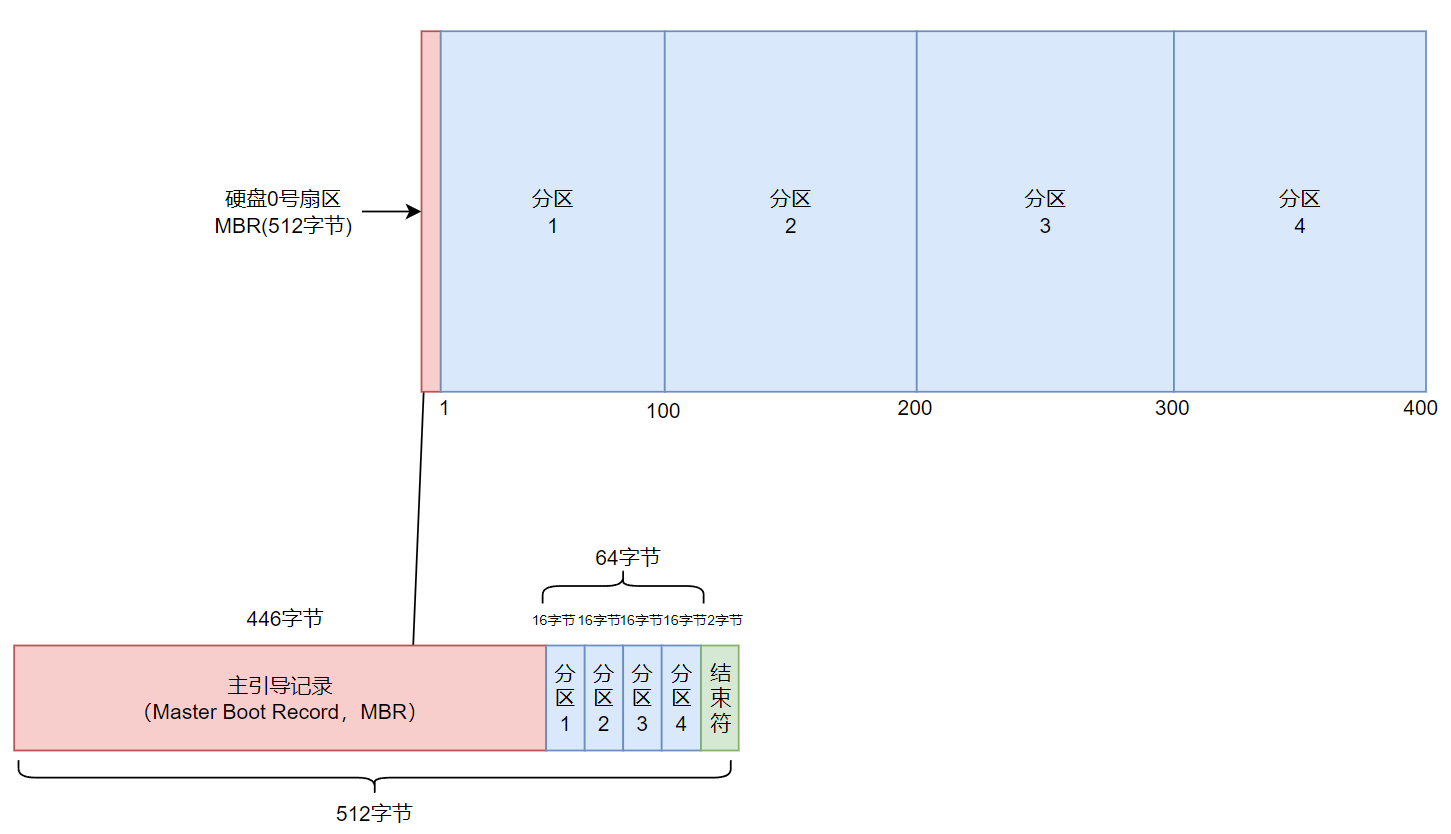
MBR磁盘分区表
- 主引导记录(Master Boot Record,MBR):可以安装启动引导程序的地方,有446字节
- 分区表(partition table):记录整块硬盘分区的状态,有64字节
由于分区表所在区块仅有 64字节容量,因此最多仅能有四组记录区,每组记录区记录了该区段的启始与结束的柱面号码。
- 所谓的分区只是针对那个64字节的分区表进行设置而已
- 硬盘默认的分区表仅能写入四组分区信息
- 这个四组划分信息我们称为主要或扩展分区
- 分区的最小单位通常为柱面
- 当系统要写入磁盘时,一定会参考磁盘分区表,才能针对某个分区进行数据的处理
虽然主分区只能有四个,但可以通过创建扩展分区来克服这个限制,从而在一块硬盘上划分出更多的分区。扩展分区是一种特殊的分区类型,它可以容纳多个逻辑分区。通过在扩展分区中创建逻辑分区,可以突破主分区数量的限制。
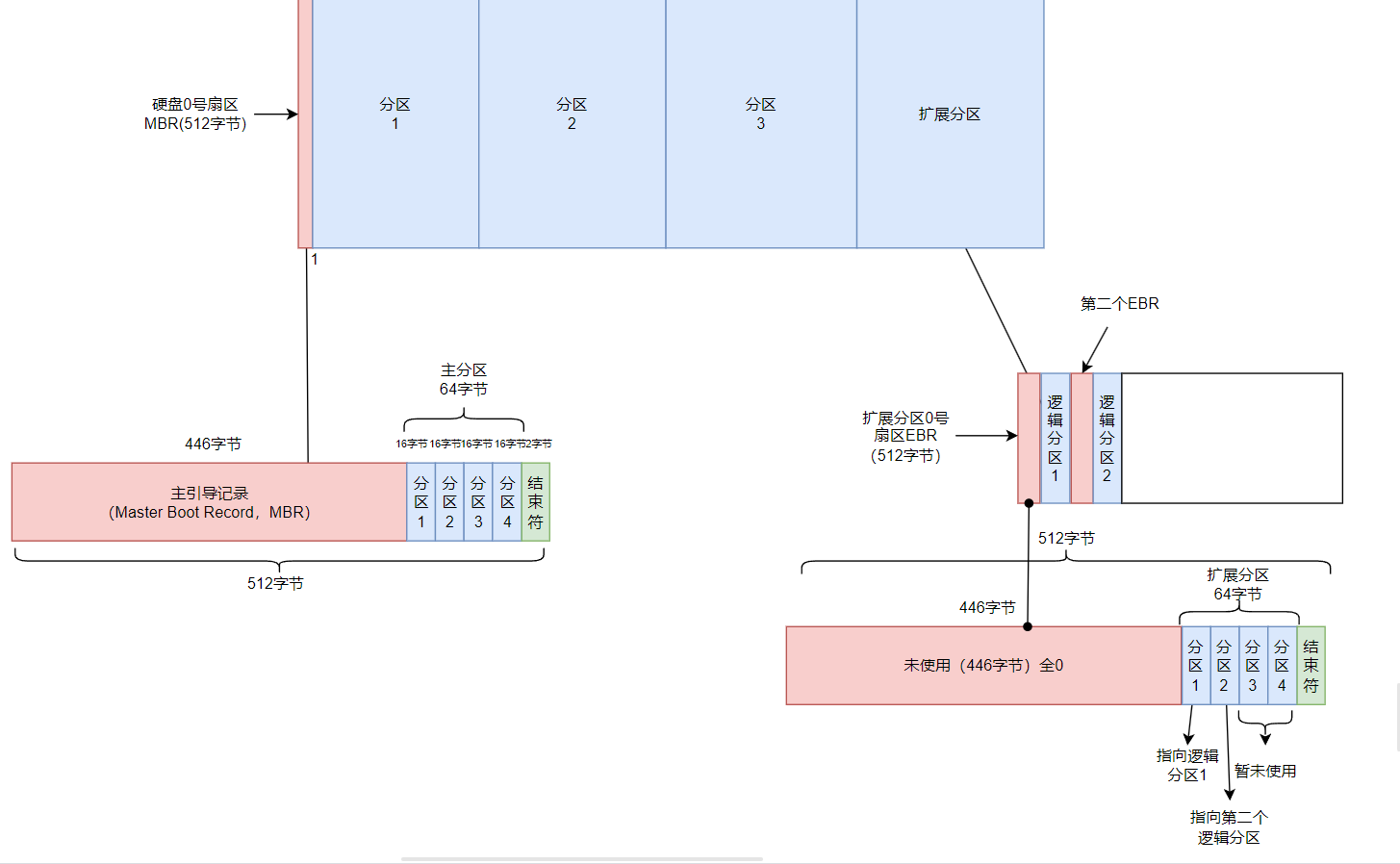
可以看到扩展分区并不是一个区块,而是会分布每个分区的最前面几个扇区来记录分区信息
扩展分区的目的是使用额外的扇区来记录分区信息,扩展分区本身不能被拿来格式化
可以通过扩展分区指向的那个区块继续做分区的记录,由扩展分区切出来的分区,就被称为逻辑分区
逻辑分区的设备名称号码由5号开始
主要分区、扩展分区与逻辑分区的特性:
-
主要分区与扩展分区最多可以有4个(硬盘限制)
-
扩展分区最多只能有一个(操作系统的限制)
-
逻辑分区是由扩展分区持续划分出来的分区
-
能够被格式化后作为数据存取的分区是主要分区与逻辑分区,扩展分区无法格式化
-
逻辑分区的数量依操作系统而不同
MBR分区表的缺点:
- 操作系统无法使用2.2TB以上的磁盘容量
- MBR仅有一个区块,若被破坏后,很难恢复
- MBR内的存放启动引导程序区块仅446字节,无法存储就较多的程序代码
GPT磁盘分区表
过去磁盘的一个扇区大小仅有512字节,由于目前出现了4k扇区,因此在扇区的定义上,大多会采用逻辑区块地址(Logical Block Address,LBA)来处理。
GPT会将磁盘的所有区块以LBA(默认512字节)进行规划,从数字0从小到大开始编号,第一个LBA为LBA0
与MBR仅使用第一个512字节区块来记录不同,GPT使用了34个LBA区块来记录分区信息。同时MBR仅有一个区块,被干掉就挂了。GPT除了前面34个LBA之外,整个磁盘的最后34个LBA也拿来作为另一个备份。
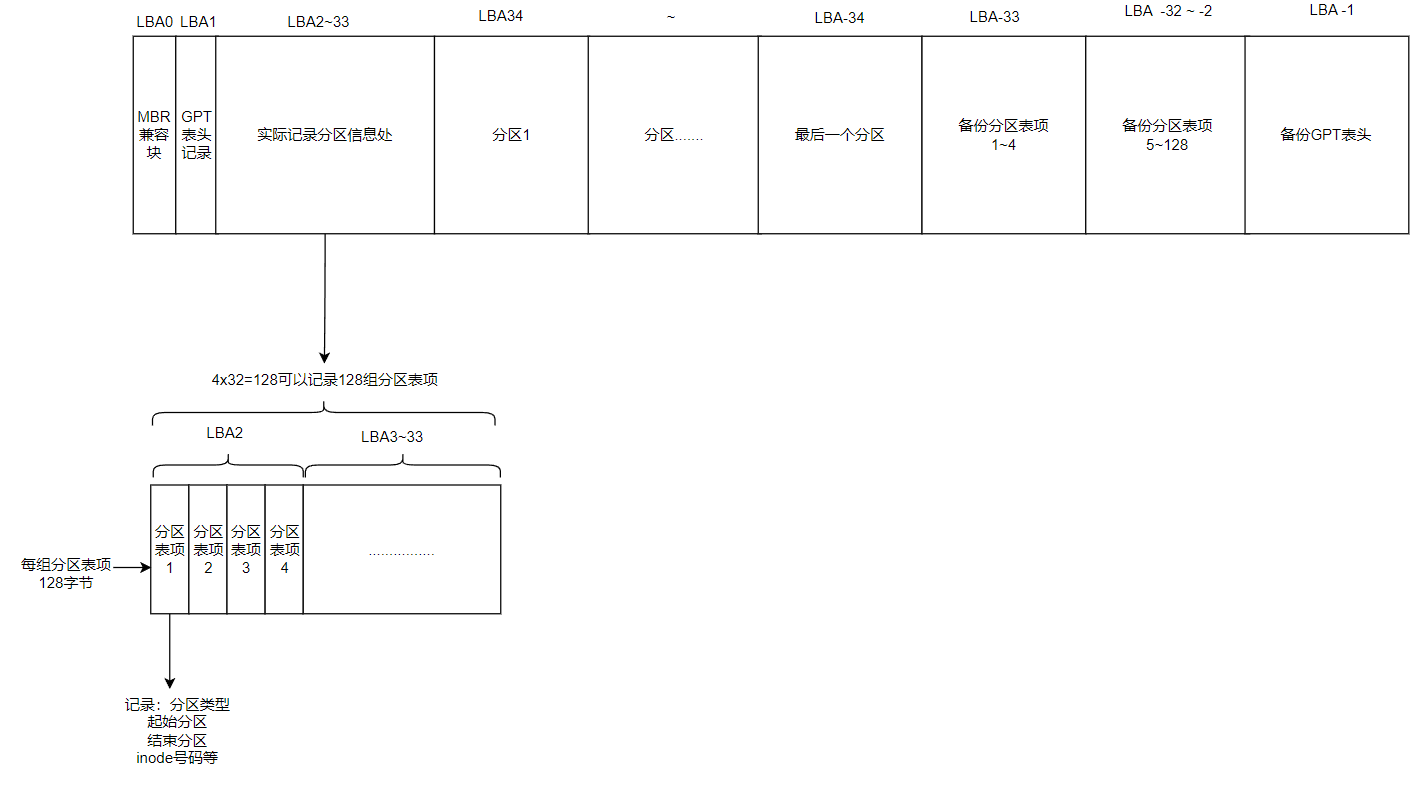
LBA0(MBR兼容块)
与 MBR 模式相似,这个兼容区块也分为两个部分,一个就是跟之前 446 字节相似的区块,存储了第一阶段的启动引导程序。而在原本的分区表的记录区内,这个兼客模式仅放入一个特殊标志符,用来表示此磁盘为 GPT 格式之意。而不懂 GPT 分区表的磁盘管理程序,就不会认识这块磁盘,除非用户有特别要求要处理这块磁盘,否则该管理软件不能修改此分区信息,进一步保护了磁盘。
LBA1(GPT表头记录)
这部分记录了分区表自身的位置和大小,同时也记录了前面提到备份用的GPT分区所在位置(最后34个LBA),还放置了分区表的校验码(CRC32),校验码的作用是让操作系统判断GPT的正确与否,倘若发现错误则可以从备份的GPT中恢复正常运行
LBA2-33(实际记录分区信息处)
从LBA2开始,每个LBA可以提供4组的分区记录,一共可以记录128组分区信息,每组分区信息占用128字节的空间,因为每个LBA都有512字节,除了每组记录需要的标识符和相关记录信息外,GPT在每组记录中提供了64位记载始末的扇区号码,以至于GPT的单个分区的最大容量提升到了【264×512字节=263×1k字节=233×8ZB】,1ZB=230TB,这也是GPT与MBR在这一点上的区别。
GPT分区已经没有所谓的主、扩展、逻辑分区的概念,每组记录都可以独立存在,每个都可以视为是主要分区,每个分区都可以拿来格式化使用。
``在磁盘管理工具上:fdisk不支持GPT,要使用GPT的话,需要用到parted或gdisk命令`
文件系统的特性
磁盘分区完毕后还需要进行格式化,之后操作系统才能够使用这个文件系统
为什么要进行格式化?
因为每种操作系统所设置的文件属性/权限并不相同,为了存放这些文件所需的数据,因此就需要将分区进行格式化,以成为操作系统能够利用的文件系统格式(filesystem)
| OS类型 | 常见文件系统 |
|---|---|
| Linux | ext2/ext3/ext4/xfs |
| Windows | NTFS/FAT |
文件系统如何存放数据位置?
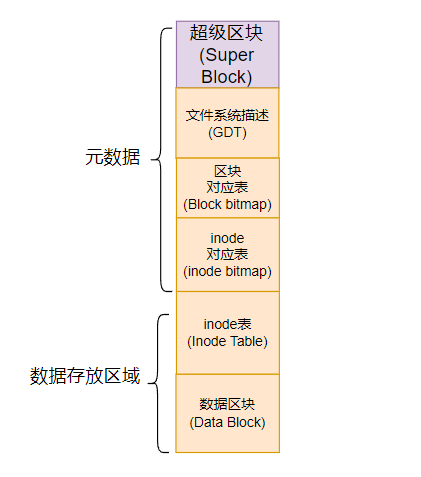
例如 Linux操作系统的文件权限(rwx)与文件属性(拥有者、用户组、时间参数等)文件系统通常会将这两部分的数据分别存放在不同的区块,权限与属性放置到 inode中,至于实际数据则放置到数据区块中。另外,还有一个超级区块(superblock)会记录整个文件系统的整体信息,包括 inode 与数据区块的总量、使用量、剩余量等
-
Super Block(超级区块):记录此文件系统的整体信息,包括inode与数据区块的总量、使用量、剩余量以及文件系统的格式与相关信息等
-
inode table(inode表):记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的区块号码
-
Date block(数据区块):实际记录文件的内容,若文件太大时,会占用多个区块
由于每个inode与数据区块都有编号,而每个文件都会占用一个inode,inode内则有文件数据放置的区块号码
ext2文件系统数据存取
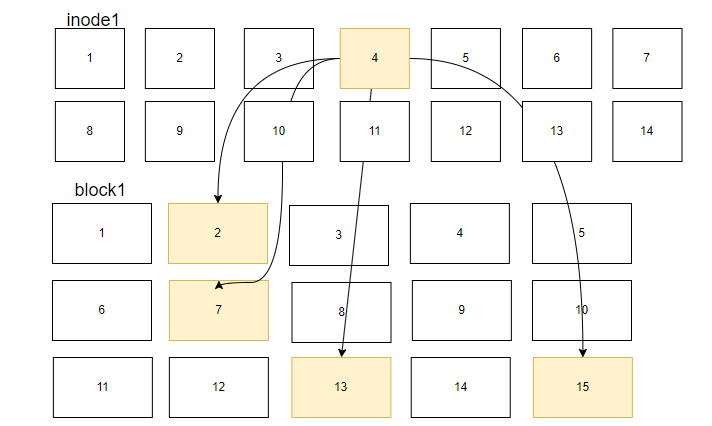
如下图,假设某一个文件的属性与权限数据是放置到inode4号中,而这个inode记录了文件数据的实际放置位置点为2、7、13、15这4个区块号码,此时我们的操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个区块内容读出来
通过inode和数据区块的记录与对应关系,操作系统可以有效地读取文件数据,这种存取方法我们称为索引式文件系统(indexed allocation)
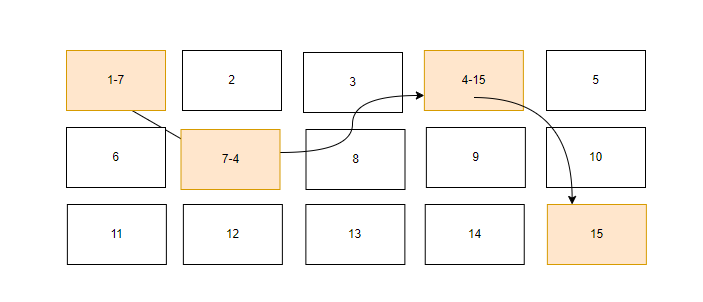
FAT文件系统数据存取
假设文件的数据依序写入 1>7>4>15 号 4个区块号码中,但这个文件系统没有办法一口气就知道四个区块的号码,它要一个一个地将区块读出来后,才会知道下一个区块在何处。
如果同一文件区块太分散,则我们的磁头将无法在磁盘旋转一圈就读到所有的数据,因此磁盘就会多转好几圈才能完整地读取到这个文件的内容
常常会听到碎片整理,碎片整理就是原因就是因为文件写入的区块太过于离散,此时文件读取的性能将会变得很差所致
这个时候可以通过碎片整理将同一个文件所属区块集合在一起,这样数据的读取会比较容易
因此FAT的文件系统需要不时地将碎片整理一下
Linux的ext2文件系统(inode)
ext2就是使用这种inode为基础的Linux文件系统
-
inode记录了文件的权限和相关属性
-
数据区块存储文件的实际内容
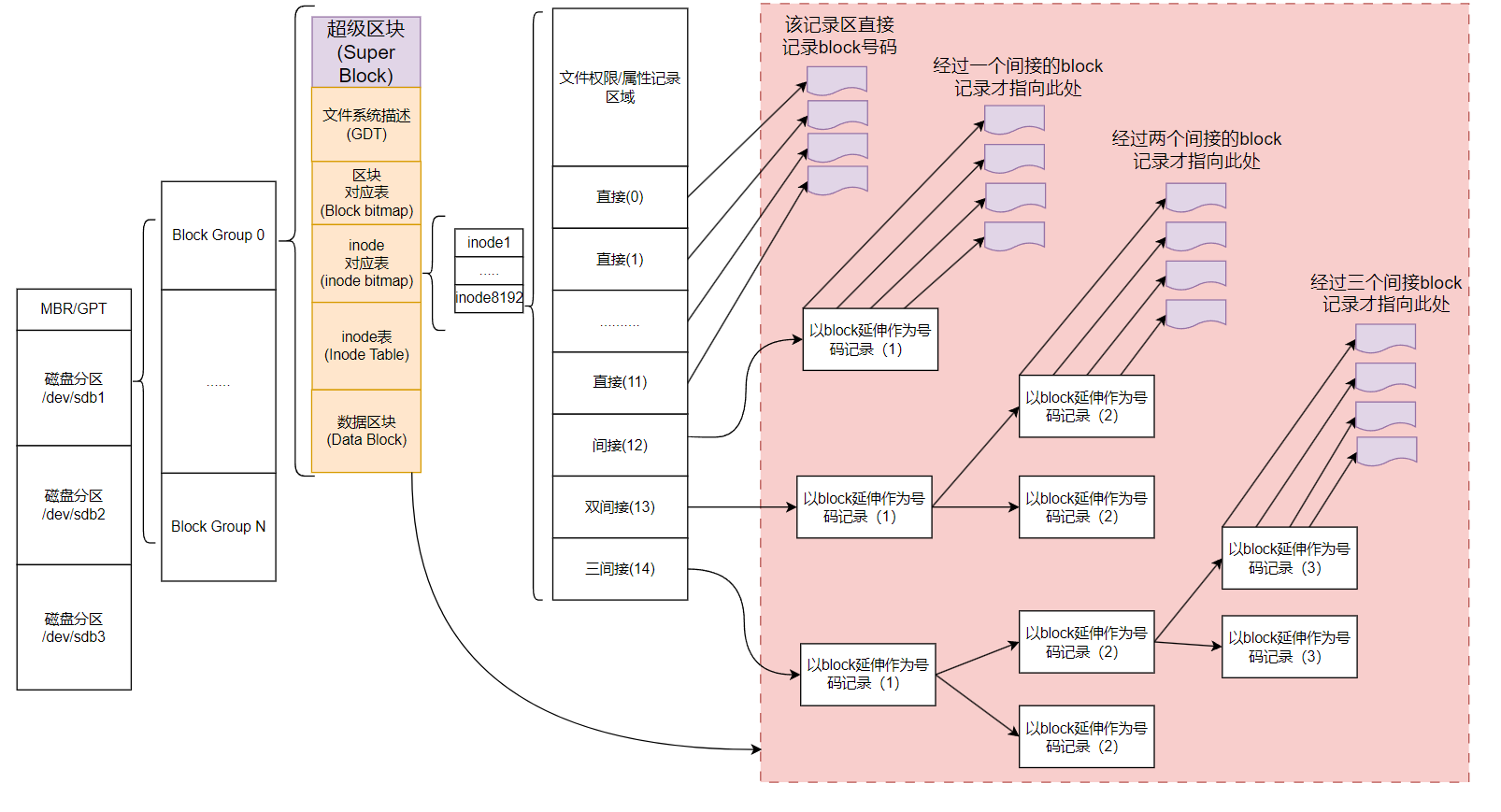
在文件系统创建时就规划好了inode和数据区块的位置,固定后一般不会再变动,除非重新格式化或调整大小(resize2fs 等命令修改其大小)。如果我的文件系统高达百GB时,集中存放所有的inode和数据区块会导致管理困难,因为数量庞大。
因此,ext2文件系统格式化的时候基本上是区分为多个区块模组(block group),每个区块群组都有独立的inode、数据区块(Date block)、超级区块系统(Super block)
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装启动引导程序,这是个非常重要的设计,因为如此一来我们就能够将不同的启动引导程序安装到别的文件系统最前端,而不用覆盖整块磁盘唯一的 MBR,这样也才能够制作出多重引导的环境。至于每一个区块群组(block group)的六个主要内容如下
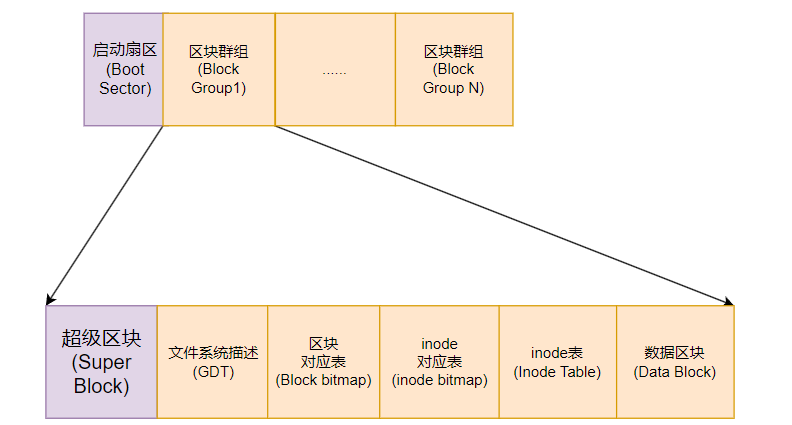
数据区块(data block)
真正存储文件数据的地方,文件的实际内容存储在这些数据块中,在ext2文件系统中所支持的区块大小有1k、2k及4k三种,在格式化时区块大小就固定了,且每个区块都有编号,以便inode记录。
不同的区块大小会影响最大支持的磁盘容量和单个文件的最大大小。通常情况下,较大的区块大小能够提高文件系统的性能,因为可以减少磁盘寻址次数,但同时会浪费一些空间。以下是不同区块大小对文件系统支持容量的影响:
| Block大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件限制 | 16GB | 256GB | 2TB |
| 最大文件系统总容量 | 2TB | 8TB | 16TB |
除了最大支持的磁盘容量和单个文件大小受区块大小影响外,ext2文件系统中区块还存在着以下限制:
- 原则上,区块的大小与数量在格式化完就不能够再修改(除非重新格式化)
- 每个区块内最多只能够放置一个文件的数据
- 承上,如果文件大于区块的大小,则一个文件会占用多个区块数量
- 承上,若文件小于区块,则该区块的剩余容量就不能够再被使用了
inode表区(inode table)
inode记录的数据至少有下面这些:
- 该文件的读写属性(read、write、excute)
- 该文件的拥有者与用户组(owner、group)
- 该文件的大小
- 该文件建立或状态改变的时间(ctime)
- 最近一次的读取时间(atime)
- 最近修改的时间(mtime)
- 定义文件特性的标识(flag),如SetUID(SUID)
- 该文件的真正内容的指向
除了在格式化时就被固定的数量和大小外,inode还具有以下特点:
- 每个inode大小均固定位128B(新的ext4与xfs可设置到256B)
- 每个文件都仅会占用一个inode而已
- 承上,因此文件系统能够建立的文件数量与inode的数量有关
- 系统读取文件时需要先找到inode,并分析inode所记录的权限与用户是否相符,若符合才能够读取区块的内容
inode要记录的数据非常多,但偏偏又只有128B而已,而inode记录一个数据区块要使用4B,假设一个文件有400MB且每个区块为4K时,那么至少也要十万个区块的记录。
为此我们的系统很聪明地将inode记录区块号码的区域定义为12个直接、一个间接、一个双间接与一个三间接记录区
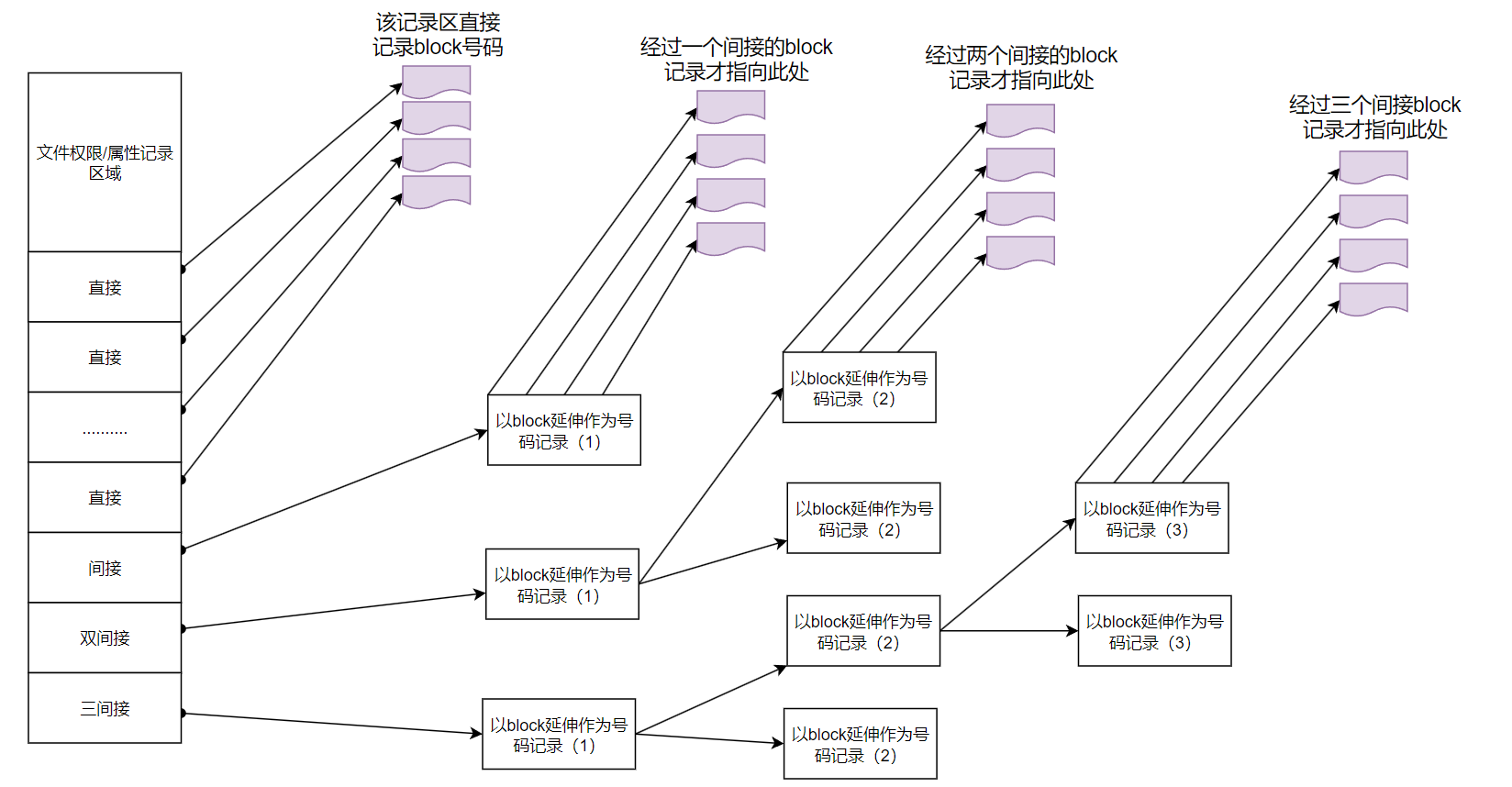
上图最左边为 inode 本身(128B),里面有 12个直接指向区块号码的对照,这 12 条记录就能够直接取得区块号码。至于所谓的间接就是再拿一个区块来当作记录区块号码的记录区,如果文件太大就会使用间接的区块来记录编号。如图所示,间接只是拿一个区块来记录额外的号码而已。同理,如果文件持续变大,那么就会利用所谓的双间接,第一个区块仅再指出下一个记录编号的区块在那里,实际记录的在第二个区块当中。依此类推,三间接就是利用第三层区块来记录编号。
例如:假设我们使用较小的1K(1024字节)的数据块大小来进行说明
- 12个直接指向:12x1k=12KB
由于是直接指向,所以总共可以记录12条数据
- 间接:256x1k=256KB
每条区块号码的记录会使用4B,因此1k的大小能够记录256条记录
- 双间接:256x256x1KB=256^2KB
第一层区块会指定256个第二层,每个第二层可以指定256个号码
- 三间接:256x256x256x1KB=256^3KB
第一层区块会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码
- 总额:将直接、间接、双间接、三间接相加,得到:12+256+256x256+256x256x256=16GB
此时可以知道,当文件系统将区块格式化为1K大小时,能够容纳的最大文件为16GB
这个方法不能用在2k及4k区块大小的计算中,因为大于2k的区块将受到ext2文件系统本身的限制,所以计算的结果会不太符合。
超级区块(Super block)
超级区块是记录整个文件系统相关信息的地方,没有超级区块,就没有这个文件系统,他记录的信息主要有:
- 数据区块与 inode 的总量
- 未使用与已使用的 inode 与数据区块 数量
- 数据区块与inode 的大小(block为1、2、4K,inode为 128B或 256B)
- 文件系统的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统的相关信息
- 一个有效位数值,若此文件系统已被挂载,则有效位为0,若未被挂载,则有效位为1
在文件系统中,超级区块包含了关于整个文件系统的重要信息,如文件系统的类型、大小、使用情况等。通常情况下,一个文件系统只有一个超级区块。这个超级区块通常位于文件系统的第一个块,用于标识整个文件系统的属性和结构。
区块群组是为了更好地管理大容量文件系统而引入的概念。文件系统将数据分成多个区块群组,每个区块群组包含一组数据块、索引节点(inode)等。第一个区块群组中通常包含有一个超级区块,而后续的区块群组可以选择性地包含备份超级区块,以便在超级区块损坏时进行恢复
文件系统描述说明(Filesystem Description)
这个区段可以描述每个区块群组的开始与结束的区块,以及说明每个区段(超级区块、对照表、inode 对照表、数据区块)分别介于哪一个区块之间,这部分也能够用 dumpe2fs 来观察
区块对应表(block bitmap)
区块对应表用于记录数据块的分配情况,标识哪些数据块已被使用,哪些是空闲的
inode对应表(inode bitmap)
inode 对应表用于记录 inode 的分配情况,标识哪些 inode 已被使用,哪些是空闲的
dumpe2fs:查询ext系列超级区块信息
dumpe2fs 是一个用于查询 ext 系列文件系统超级块信息的实用程序。显示文件系统的详细信息,包括块大小、inode大小、文件系统状态等
[root@chenshiren ~]# dumpe2fs [-bh] 设备文件名
选项:
-b:列出保留位坏道的部分
-h:仅列出superblock的数据,不会列出其他的区段内容
# 示例
# 显示ext4文件系统内容
[root@chenshiren ~]# blkid # 显示出目前系统被格式化的设备
/dev/nvme0n1p5: UUID="205e6436-c996-4e74-95c2-469e7359a8f2" TYPE="xfs" PARTUUID="18a2fc52-45c3-4432-91fe-3f39c83e98f7"
/dev/nvme0n1p3: UUID="a0af4b7c-a869-4878-af70-40226ede5b91" TYPE="xfs" PARTUUID="f2af498c-d9e3-4c3a-b4d5-06ae09dd18a9"
/dev/nvme0n1p4: UUID="df24e683-7e21-4ff3-91bc-e1c1f53234de" TYPE="swap" PARTUUID="a4af7b02-46ef-48cd-8b86-02503969f574"
/dev/sr0: UUID="2023-04-13-16-58-02-00" LABEL="RHEL-9-2-0-BaseOS-x86_64" TYPE="iso9660" PTUUID="d3d1f9a5" PTTYPE="dos"
/dev/nvme0n1p1: PARTUUID="27a8469a-5ffe-ff46-a679-30c0de080ed8"
/dev/nvme0n1p2: PARTUUID="1d0ca8ad-63d0-48b4-b8b2-2a84afd6c86f"
/dev/nvme0n2p1: UUID="e972e669-1de9-4a67-ac67-52c2a82e82f4" TYPE="ext4" PARTUUID="a0f96632-01"
[root@chenshiren ~]# dumpe2fs /dev/nvme0n2p1
dumpe2fs 1.46.5 (30-Dec-2021)
Filesystem volume name: <none> # 文件系统名称
Last mounted on: <not available> # 上一次挂载的目录位置
Filesystem UUID: e972e669-1de9-4a67-ac67-52c2a82e82f4
Filesystem magic number: 0xEF53 # 上方的UUID为Linux对设备的定义
Filesystem revision #: 1 (dynamic) # 下方的features为文件系统的特征数据
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # 默认挂载时会主动加上的挂载参数
Filesystem state: clean # 这块文件系统的状态是什么,clean是没问题
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 1310720 # inode的总数
Block count: 5242624 # 区块的总数
Reserved block count: 262131 # 保留的区块总数
Overhead clusters: 126316
Free blocks: 5116302 # 还有多少的区块可用数量
Free inodes: 1310709 # 还有多少的inode可用数量
First block: 0
Block size: 4096 # 单个区块的大小
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1024
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Sun Mar 3 00:21:35 2024
Last mount time: n/a
Last write time: Sun Mar 3 00:21:36 2024
Mount count: 0
Maximum mount count: -1
Last checked: Sun Mar 3 00:21:35 2024
Check interval: 0 (<none>)
Lifetime writes: 4158 kB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256 # inode容量大小,256了
Required extra isize: 32
Desired extra isize: 32
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 40599935-aec8-4f6d-9e82-640e6226c077
Journal backup: inode blocks
Checksum type: crc32c
Checksum: 0x3ee54802
Journal features: (none)
Total journal size: 128M
Total journal blocks: 32768
Max transaction length: 32768
Fast commit length: 0
Journal sequence: 0x00000001
Journal start: 0
组 0:(块 0-32767) 校验值 0x1817
主 超级块位于 0,组描述符位于 1-3
保留的GDT块位于 4-1027
块位图位于 1028 (+1028),校验值 0x3c0689a1
Inode 位图位于 1044 (+1044),校验值 0xf8836269
Inode表位于 1060-1571 (+1060)
23510 个可用 块,8181 个可用inode,2 个目录 ,8181个未使用的inodes
可用块数: 9258-32767
可用inode数: 12-8192
....
....
前半部分显示超级区块的内容,后面则是每个区块群组的信息,可以看到各区段数据所在的号,也就是说,基本上所有的数据还是与区块的号码有关
【dumpe2fs /dev/nvme0n2p1】区块群组信息:
- Group0所占用的区块号码由0-32767,超级区块则在第0号区块中
- 文件系统描述说明在1-3号区块中
- 区块对照表与inode对照表,则在1028及1040的区块中
- inode表区(inode table)分布于1060-1571的区块中
- 由于(1)一个inode占用256字节(2)总共由1571-1060+1=512个区块,(3)每个区块的大小为4096字节(4K)由这些数据可以算出inode的数量共有512*4096/256=8192个inode
- 这个Group 0 目前可用的区块有23510个,可用的inode有8181个
- 剩余的inode号码为12-8192
与目录树的关系
每个文件(不管是一般文件还是目录文件)都会占用一个inode,且可依据内容大小来分配多个区块给该文件使用,在文件系统中,目录和文件都是通过inode来管理的,但它们在文件系统中记录数据的方式稍有不同:
目录
当在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一个区块给目录。
inode记录该目录的相关权限与属性,并记录着分配的那块区块号码
区块记录该目录下的文件名与对应文件名占用的inode号码数据
如果想要观察root根目录内的文件所占用的inode号码时,可以使用【ls -li】
[root@chenshiren ~]# ls -li
51666757 -rw----r--. 1 root root 0 2月 28 00:31 abcdefg
51667283 -rw----r--. 1 root root 1437 2月 26 23:58 anaconda-ks.cfg
当你使用 【ll /】时,出现的几乎都是1024的倍数,因为每个区块的数量都是1K、2K、4K
[root@localhost ~]# ll -d /boot/ /usr/sbin/ /proc/ /sys
dr-xr-xr-x. 6 root root 4096 3月 3 18:01 /boot/ # 一个4K区块
dr-xr-xr-x. 368 root root 0 3月 3 18:03 /proc/ # 这两个位内存中数据,不占磁盘容量
dr-xr-xr-x. 13 root root 0 3月 3 18:03 /sys
dr-xr-xr-x. 2 root root 20480 3月 3 17:59 /usr/sbin/ # 五个4K区块
文件
当我们在Linux下的ext2建立一个一般文件时,ext2会分配一个inode与相对于该文件大小的区块数量给该文件。
例如:我的一个区块位4KB,而我要建立一个100KB的文件,那么Linux将分配一个inode与25个区块来存储该文件。由于inode仅有12个直接指向,因此还需要一个区块来记录该区块号码
目录树读取
当我们想要读取/etc/passwd这个文件时
[root@chenshiren ~]# ll -di / /etc/ /etc/passwd
128 dr-xr-xr-x. 17 root root 224 3月 3 18:39 /
33575041 drwxr-xr-x. 133 root root 8192 3月 3 18:25 /etc/
34873908 -rw-r--r--. 1 root root 2187 2月 27 23:28 /etc/passwd
读取流程为:
- /的inode
通过挂载点的信息找到inode号码为128的根目录inode,且inode规范的权限让我们可以读取该区块的内容(有r与x)
- /的区块
经过上个步骤取得区块的号码,并找到该内容由 etc/ 目录的inode号码(33575041)
- etc/的inode
读取33575041号inode得知csq(普通用户)具有rx的权限,因此可以读取etc/的区块内容
- etc/的区块
经过上个步骤取得区块号码,并找到该内容有passwd文件的inode号码(34873908)
- passwd的inode
读取34873908号inode得知csq具有r的权限,因此可以读取passwd的区块内容
- passwd的区块
最后将该区块内容的数据读取出来
文件系统大小与磁盘读取性能
- 如果文件写入的区块太分散,就会有所谓的
文件数据离散的问题 - 如果文件系统真的太大,那么当一个文件分别记录在这个文件系统的最前面与最后面的区块号码中,此时
会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的下降。而且磁头在查找整个文件系统时,也会花费比较多的时间去查找。因此,磁盘分区的规划并不是越大越好,而是要针对主机用途来进行规划。
ext2/ext3/ext4 文件的存取与日志式文件系统的功能
假设要新增一个文件,此时文件系统的操作是:
- 先确定用户对于欲新增文件的目录是否具有w与x的权限,若有的话才能新增
- 根据 inode 对照表找到没有使用的 inode 号码,并将新文件的权限/属性写入
- 根据区块对照表找到没有使用中的区块号码,并将实际的数据写入区块中,且更新inode 的区
块指向数据 - 将刚刚写入的 inode 与区块数据同步更新 inode 对照表与区块对照表,并更新超级区块的内容
因为超级区块、inode对照表及区块对照表的数据是经常变动的,每次新增、删除、编辑时都可能会影响这三个部分的数据,因此被称为元数据。
数据的不一致
当发生突然停电、系统崩溃等异常情况,可能导致数据写入过程中出现不一致的情况,即元数据与实际数据存放区不匹配。在早期的ext2文件系统中,这种情况会导致系统在重新启动时通过e2fsck程序进行数据一致性检查。 e2fsck程序主要用于检查ext2文件系统的一致性,并尝试修复发现的问题。它会遍历整个文件系统,对元数据区域和实际数据存放区进行比对,以确保它们的一致性。对于大容量的文件系统,特别是在提供网络服务的服务器主机上,这种检查可能会非常耗时,导致系统恢复时间延长,影响系统的可用性。
为了解决这一问题,日志式文件系统应运而生
日志式文件系统
通过在文件系统中设置专门的日志记录区块,记录文件系统的写入和修改操作过程,可以确保在发生意外情况时,能够快速恢复文件系统的一致性而无需对整个文件系统进行耗时的全面扫描。
- 预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息
- 实际写入:开始写入文件的权限与数据;开始更新metadata 的数据
- 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的记录
在这样的程序当中,万一数据的记录过程当中发生了问题,那么我们的系统只要去检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整个文件系统进行检查,这样就可以达到快速修复文件系统的目的
ext3和ext4是ext2文件系统的升级版本,同时也保留了向下兼容性,因此可以以较低的风险从ext2升级到ext3或ext4来获得日志式文件系统的优势
这里实验使用的是ext4,使用【dumpe2fs】查看超级区块信息
[root@chenshiren ~]# dumpe2fs -h /dev/nvme0n2p1
.....
Journal inode: 8 # 指定了文件系统日志使用的inode号码
Journal backup: inode blocks # 表示文件系统日志备份的方式
Journal features: journal_64bit journal_checksum_v3
# 描述了文件系统日志的一些特性
Total journal size: 128M # 指定了日志的总大小,这里是128M
Total journal blocks: 32768 # 指定了日志占用的总块数
Journal sequence: 0x00000002 # 日志序列号,用于标识不同的日志版本
Linux文件系统的运行
如果你常常编辑一个好大的文件,在编辑的过程中又频繁地要系统来写入到磁盘中,由于磁盘写入的速度要比内存慢很多,因此你会常常耗在等待磁盘的读写上真没效率。
Linux系统中的异步处理是一种提高系统性能的方式
当系统加载一个文件到内存后,如果该文件没有被修改过,则在内存区段的文件数据会被设置为【干净(clean)】。但如果内存中的文件数据被更改过了(例如你用 nano 去编辑过这个文件),此时该内存中的数据会被设置为【脏的(Dirty)】此时所有的操作都还在内存中执行,并没有写入到磁盘中,系统会不定时的将内存中设置为【Dirty】的数据写回磁盘,以保持磁盘与内存数据的一致性。也可以利用sync命令来手动强制写入磁盘
- 系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读写操作
- 承上,因此 Linux 的物理内存最后都会被用光,这是正常的情况,可加速系统性能
- 你可以手动使用 sync 来强制内存中设置为 Dirty 的文件回写到磁盘中
- 若正常关机时,关机命令会主动调用 sync 来将内存的数据回写入磁盘内
- 但若不正常关机(如断电、宕机或其他不明原因),由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘校验,甚至可能导致文件系统的损坏(非磁盘损坏)
挂载点的意义(mount point)
每个文件系统在计算机上都有独立的inode、区块、超级区块等信息,但要让文件系统可以被访问和使用,它需要连接到系统的目录结构中。这个将文件系统和目录结构结合起来的过程称为挂载。
在挂载过程中,文件系统会被连接到目录树中的一个特定目录作为入口点,这个目录被称为挂载点。通过挂载文件系统到特定目录,我们才能够对该文件系统进行访问和操作。
例如,观察inode号码
[root@chenshiren ~]# ll -di / /boot
128 dr-xr-xr-x. 17 root root 224 3月 3 18:39 /
128 dr-xr-xr-x. 5 root root 4096 2月 24 16:00 /boot
# inode号码均为128,表示它们是在同一个文件系统
其他Linux支持的文件系统与VFS
常见的支持文件系统有:
- 传统文件系统:ext2、minix、FAT、iso9660
- 日志式文件系统:ext3、ext4、NTFS、XFS、ZFS
- 网络文件系统:NFS、SMBFS
如果你想要知道Linux支持的文件系统有哪些,可以查看下面的这个目录
[root@chenshiren ~]# ls -l /lib/modules/$(uname -r)/kernel/fs
系统当前加载到内存中支持的文件系统:
[root@chenshiren ~]# cat /proc/filesystems
在Linux内核中,所有文件系统的管理都是通过一个名为Virtual Filesystem Switch(VFS)的内核功能进行的。VFS可以帮助Linux系统识别和管理各种不同的文件系统,使用户无需关心硬盘分区上使用的具体文件系统类型,VFS会自动处理文件读取等操作。
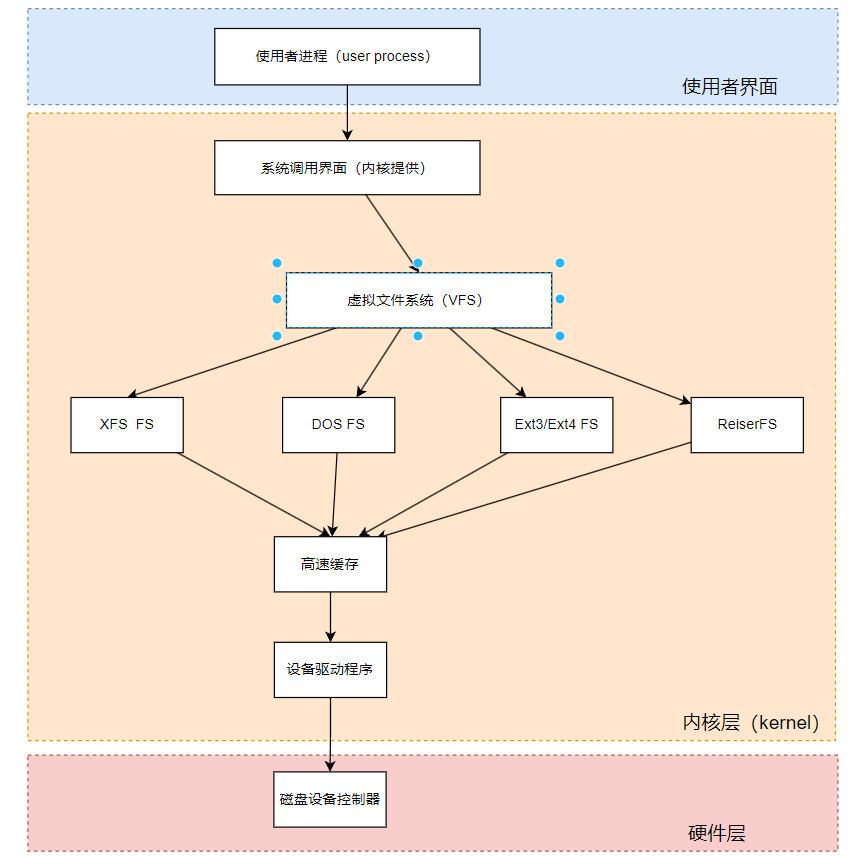
XFS文件系统简介
XFS文件系统是一种高性能的日志式文件系统,它拥有很多优点,因此成为了CentOS 7以后默认的文件系统选择。
ext文件系统:支持度最广,但格式化超慢
在选择将默认文件系统从ext4变更为XFS的原因中,一个主要因素是XFS对大容量磁盘的支持和处理能力更好。相比于ext文件系统系列采用的预先规划所有inode、区块和元数据的方式,XFS在处理大容量磁盘时更为高效。由于现代磁盘容量越来越大,如TB、PB甚至EB级别,传统的ext文件系统在格式化过程中预先分配inode和区块会耗费大量时间,而XFS在这方面表现得更出色。
从Centos 7.x 开始,文件系统已经由默认的ext4变成了xfs这一个较适合高容量磁盘与巨型文件,且性能较佳的文件系统
XFS文件系统的配置
几乎所有ext4文件系统有的功能,XFS都具备
XFS文件系统在数据的分布上,主要规划为三个部分,一个数据区(data section)、一个文件系统活动登录区(log section) 以及一个实时运行区(realtime section),这三个区域的数据内容如下:
- 数据区(Data Section)
在XFS文件系统中的功能类似于ext系列文件系统的数据块组,包括inode、数据块、超级块等数据的存储。数据区被分成多个存储区组(allocation groups),每个存储区组包含(1)整个文件系统的超级块、(2)剩余空间的管理机制、(3)inode的分配和跟踪。在格式化操作过程中,由于inode和数据块是在系统需要时才会动态配置生成,所以格式化的速度非常快
与ext系列不同的是,XFS的区块和inode具有多种可配置的容量选项
区块的容量可以设置在512字节到64KB之间
对于inode的容量,可以设置在256字节到2MB之间
- 文件系统活动登录区(log section)
文件系统活动登录区(log section)在该区域主要用于记录文件系统的变化,类似于一个日志区。文件的变化会首先被记录在这里,直到完整地写入数据区域后,该记录才会被标记为完成。
当文件系统因为突发情况(例如停电)而损坏时,系统会使用这个活动登录区来进行检验,查看在系统发生故障之前文件系统正在进行的操作,以便快速修复文件系统。由于系统的所有操作都会在这个区域进行记录,因此这个区域的磁盘活动非常频繁。
- 实时运行区(realtime section)
当创建新文件时,XFS会在实时运行区找到一个或多个extent区块,将文件放置在这些区块内,然后分配完毕后再写入到数据区的inode和区块中。在格式化阶段,需要预先指定extent区块的大小,最小为4KB,最大可达1GB。通常情况下,对于非磁盘阵列的磁盘,默认的extent大小为64KB;而在具有磁盘阵列的情况下,建议将extent的大小设置为与stripe相同大小,以获得最佳性能。
XFS文件系统的描述与数据观察
可以使用【xfs_info】去查看超级区块信息
[root@chenshiren ~]# xfs_info 挂载点|设备文件名
[root@chenshiren ~]# xfs_info / 或者 xfs_info /dev/nvme0n1p5
1 meta-data=/dev/nvme0n1p5 isize=512 agcount=4, agsize= blks
2 = sectsz=512 attr=2, projid32bit=1
3 = crc=1 finobt=1, sparse=1, rmapbt=0
4 = reflink=1 bigtime=1 inobtcount=1
5 data = bsize=4096 blocks=4386560, imaxpct=25
6 = sunit=0 swidth=0 blks
7 naming =version 2 bsize=4096 ascii-ci=0, ftype=1
8 log =internal log bsize=4096 blocks=2560, version=2
9 = sectsz=512 sunit=0 blks, lazy-count=1
10 realtime =none extsz=4096 blocks=0, rtextents=0
元数据(meta-data):
-
meta-data=/dev/nvme0n1p5:文件系统的元数据存储在/dev/nvme0n1p5 -
isize=512: 每个inode的大小为512字节 -
agcount=4, agsize=1096640 blks:总共有4个数据块组(agcount),每个数据块组具有1096640个区块,配合第四行的区块设置为4K,因此整个文件系统的容量应该是4*1096640*4K那么大。 -
sectsz=512:指逻辑扇区的容量设置为512B这么大
数据(data):
bsize=4096: 数据块的大小为4096字节4Kblocks=4386560: 文件系统总共有4386560个数据块。
日志(log):
internal log: 指的是这个登录区的位置在文件系统内,而不是外部设备bsize=4096: 日志块的大小为4096字节,4K
blocks=2560: 日志共有2560个区块。- 总共约:4K*2560个区块
实时运行区(realtime):
none: 未启用实时运行区。extsz=4096: extent的大小为4096字节,4K
文件系统的简单操作
磁盘与目录的容量:df、du
df:列出文件系统的整体磁盘使用量
[root@chenshiren ~]# df [-ahikHTm] [目录或文件名]
| 选项 | 作用 |
|---|---|
| -a | 列出所有文件系统,包括系统特有的/proc等文件系统 |
| -h | 以人类可读的方式显示磁盘空间大小,例如以K、M、G为单位 |
| -k | 以KBytes的容量显示各文件系统 |
| -H | 以M=1000K替换M=1024K的进位方式 |
| -T | 显示文件系统类型 |
| -m | 以MBytes的容量显示各文件系统 |
| -i | 不显示磁盘容量,以inode的数量来显示 |
# 示例1 将系统内的所有特殊文件格式及名称都列出来
[root@chenshiren ~]# df -aT
文件系统 类型 1K-块 已用 可用 已用% 挂载点
proc proc 0 0 0 - /proc
sysfs sysfs 0 0 0 - /sys
devtmpfs devtmpfs 4096 0 4096 0% /dev
securityfs securityfs 0 0 0 - /sys/kernel/security
tmpfs tmpfs 1992188 0 1992188 0% /dev/shm
devpts devpts 0 0 0 - /dev/pts
tmpfs tmpfs 796876 9680 787196 2% /run
cgroup2 cgroup2 0 0 0 - /sys/fs/cgroup
pstore pstore 0 0 0 - /sys/fs/pstore
bpf bpf 0 0 0 - /sys/fs/bpf
/dev/nvme0n1p5 xfs 17536000 6382148 11153852 37% /
selinuxfs selinuxfs 0 0 0 - /sys/fs/selinux
systemd-1 - - - - - /proc/sys/fs/binfmt_misc
debugfs debugfs 0 0 0 - /sys/kernel/debug
mqueue mqueue 0 0 0 - /dev/mqueue
hugetlbfs hugetlbfs 0 0 0 - /dev/hugepages
tracefs tracefs 0 0 0 - /sys/kernel/tracing
fusectl fusectl 0 0 0 - /sys/fs/fuse/connections
configfs configfs 0 0 0 - /sys/kernel/config
vmware-vmblock fuse.vmware-vmblock 0 0 0 - /run/vmblock-fuse
none ramfs 0 0 0 - /run/credentials/systemd-tmpfiles-setup-dev.service
none ramfs 0 0 0 - /run/credentials/systemd-sysctl.service
/dev/nvme0n1p3 xfs 1038336 263036 775300 26% /boot
none ramfs 0 0 0 - /run/credentials/systemd-tmpfiles-setup.service
tmpfs tmpfs 398436 52 398384 1% /run/user/42
tmpfs tmpfs 398436 36 398400 1% /run/user/0
binfmt_misc binfmt_misc 0 0 0 - /proc/sys/fs/binfmt_misc
# 示例2 列出Linux文件系统的整体磁盘使用量 将容量以易读的格式显现出来,以及显示文件系统类型
[root@chenshiren ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs tmpfs 779M 9.5M 769M 2% /run
/dev/nvme0n1p5 xfs 17G 6.1G 11G 37% /
/dev/nvme0n1p3 xfs 1014M 257M 758M 26% /boot
tmpfs tmpfs 390M 52K 390M 1% /run/user/42
tmpfs tmpfs 390M 36K 390M 1% /run/user/0
# 示例3 将目前各个硬盘分区可用的inode数量列出
[root@chenshiren ~]# df -ih
文件系统 Inodes 已用(I) 可用(I) 已用(I)% 挂载点
devtmpfs 479K 402 479K 1% /dev
tmpfs 487K 1 487K 1% /dev/shm
tmpfs 800K 846 800K 1% /run
/dev/nvme0n1p5 8.4M 126K 8.3M 2% /
/dev/nvme0n1p3 512K 357 512K 1% /boot
tmpfs 98K 53 98K 1% /run/user/42
tmpfs 98K 36 98K 1% /run/user/0
du:查看文件系统的磁盘使用量(常用于查看目录所占磁盘空间)
[root@chenshiren ~]# du [-ahskm] 文件或目录名称
| 选项 | 作用 |
|---|---|
| -a | 列出所有的文件与目录容量 |
| -h | 以人类可读的方式显示文件使用的磁盘空间大小,例如以K、M、G为单位。 |
| -s | 仅显示总和,不显示每个文件或目录的磁盘使用情况 |
| -k | 以KBytes为单位显示文件使用的磁盘空间大小 |
| -m | 以MBytes为单位显示文件使用的磁盘空间大小 |
# 示例1 列出目前目录下的所有文件容量
[root@chenshiren ~]# du
...
..
576 ./.local/share
576 ./.local
3556 .
# 每个目录都会列出来,包括隐藏文件的目录
# 实际显示时,仅会显示目录容量(不含文件)
# 示例2 同上示例 将文件容量列出来
...
..
12 ./.bash_history
4 ./.lesshst
4 ./anaconda-ks.cfg
# 示例3 检查根目录下面每个目录所占用的容量
[root@chenshiren ~]# du -sh /*
0 /bin
218M /boot
0 /dev
31M /etc
1.5M /home
0 /lib
0 /lib64
0 /media
0 /mnt
0 /opt
du: 无法访问 '/proc/2206/task/2206/fd/4': 没有那个文件或目录
du: 无法访问 '/proc/2206/task/2206/fdinfo/4': 没有那个文件或目录
du: 无法访问 '/proc/2206/fd/4': 没有那个文件或目录
du: 无法访问 '/proc/2206/fdinfo/4': 没有那个文件或目录
0 /proc
3.5M /root
9.6M /run
0 /sbin
0 /srv
0 /sys
1.5M /tmp
3.7G /usr
174M /var
# 利用*代表每个目录
硬链接与符号链接:ln
ln命令用于创建硬链接或符号链接。硬链接和符号链接是在文件系统中创建的两种不同类型的链接方式,它们之间有一些区别:
硬链接(Hard Link,硬式链接或实际链接)
-
硬链接是指向同一索引节点(inode)的多个目录项。
-
硬链接不占用额外的磁盘空间,因为它们只是多个文件名指向同一个数据块。
-
删除原始文件并不会影响硬链接文件,因为它们都指向相同的数据块。
-
硬链接不能跨越文件系统,即不能指向不同的硬盘分区
-
可以使用
ln命令创建硬链接,例如:ln source_file hard_link_name
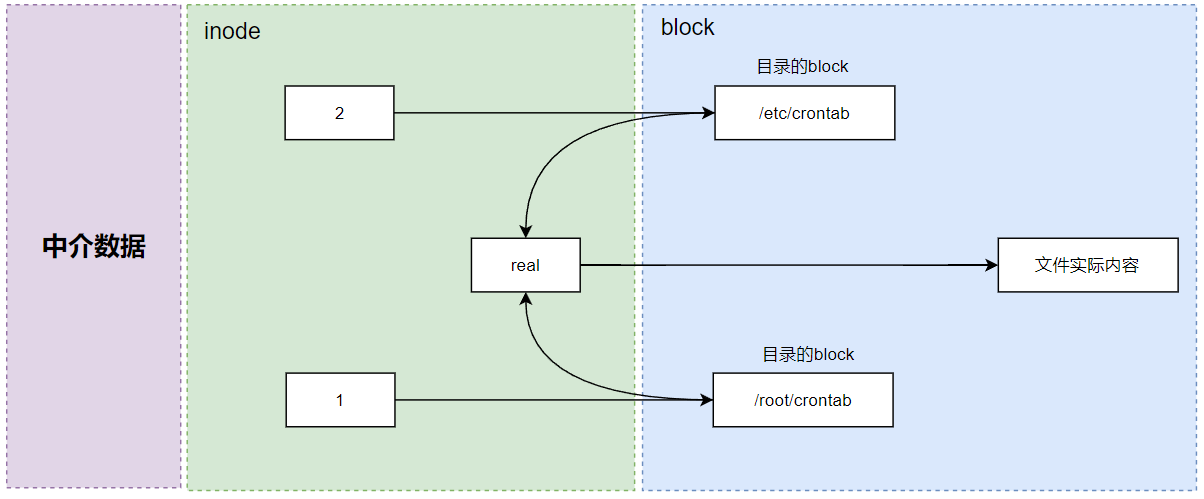
上图的意思是,你可以通过1或2的目录的inode 指定的区块找到两个不同的文件名,而不管用哪个文件名均可以指到那个 inode 去读取到最终数据。
这样做的好处是,如果你将任何一个文件名删除,其实 inode 与区块都还是存在的。此时你可以通过另个文件名来读取到正确的文件数据。此外,不论你使用哪个文件名来编辑,最终的结果都会写入到相同的inode 与区块中,因此均能进行数据的修改。
符号链接(Symbolic Link,就是快捷方式)
- 符号链接是一个特殊类型的文件,它包含指向另一个文件的路径或位置信息
- 符号链接占用磁盘空间,因为它们实际上是一个指向另一个文件的路径
- 如果原始文件被删除或移动,符号链接将失效
- 符号链接可以指向不同文件系统中的文件
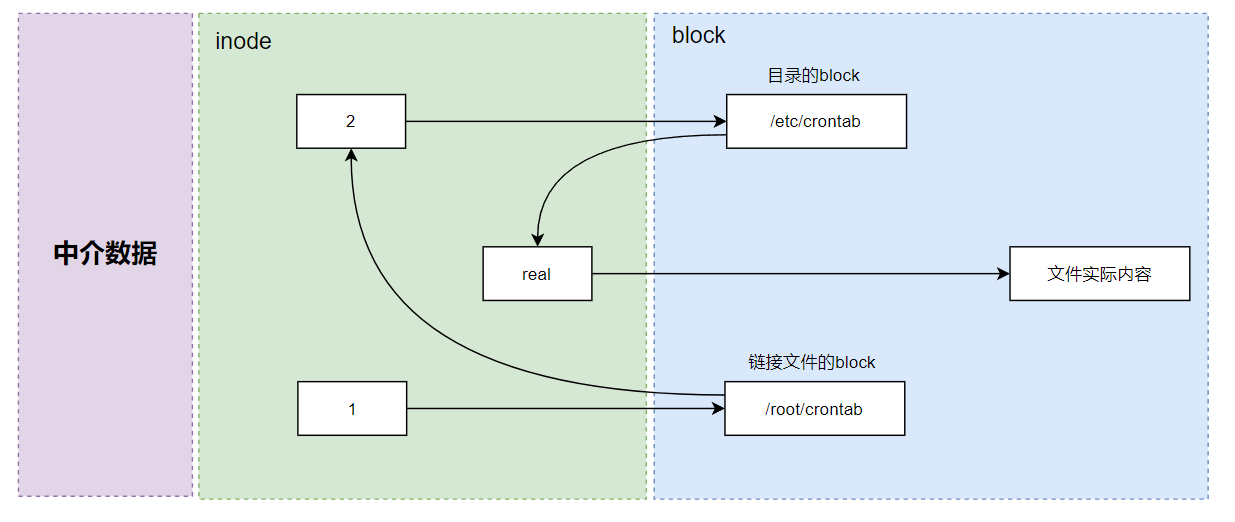
由1号inode 读取到链接文件的内容仅有文件名,根据文件名链接到正确的目录去取得目标文件的inode,最终就能够读取到正确的数据了。你可以发现的是,如果目标文件(/etc/crontab)被删除了,那么整个环节就会无法继续进行下去,所以就会发生无法通过链接文件读取的问题。
这个符号链接与 Windows 的快捷方式可以给它划上等号,由符号链接所建立的文件为一个独立的新的文件,所以会占用 inode 与区块。
ln:用于创建硬链接或符号链接
[root@chenshiren ~]# ln [-sf] 源文件 目标文件
选项:
-s:如果不加任何参数就进行链接,那就是硬链接,加上-s就是符号链接
-f:如果目标文件存在时,就主动的将目标文件直接删除后再建立
# 示例1 将/etc/passwd 复制到 /tmp 下面,并且观察inode与区块
[root@chenshiren ~]# cp -a /etc/passwd /tmp/
[root@chenshiren ~]# cd /tmp/
[root@chenshiren tmp]# du -sb; df -ih .
8494 .
文件系统 Inodes 已用(I) 可用(I) 已用(I)% 挂载点
/dev/nvme0n1p5 8.4M 126K 8.3M 2% /
# 示例2 将/tmp/passwd 制作硬链接成为 /tmp/passwd-csq,并查看文件与容量
[root@chenshiren tmp]# ln passwd passwd-csq
[root@chenshiren tmp]# du -sb; df -ih .
8494 . # 容量并没有改变
文件系统 Inodes 已用(I) 可用(I) 已用(I)% 挂载点
/dev/nvme0n1p5 8.4M 126K 8.3M 2% /
[root@chenshiren tmp]# ll -i passwd*
17688088 -rw-r--r--. 2 root root 2187 2月 27 23:28 passwd #指向了同一个inode
17688088 -rw-r--r--. 2 root root 2187 2月 27 23:28 passwd-csq
# 示例3 将/tmp/passwd 建立一个符号链接
[root@chenshiren tmp]# ln -s passwd passwd-zhw
[root@chenshiren tmp]# ll -i passwd*
17688088 -rw-r--r--. 2 root root 2187 2月 27 23:28 passwd
17688088 -rw-r--r--. 2 root root 2187 2月 27 23:28 passwd-csq
# 可以看到指向的inode不同了
17642940 lrwxrwxrwx. 1 root root 6 3月 4 16:46 passwd-zhw -> passwd
[root@chenshiren tmp]# du -sb; df -ih .
8500 . # 目录容量也变了
文件系统 Inodes 已用(I) 可用(I) 已用(I)% 挂载点
/dev/nvme0n1p5 8.4M 126K 8.3M 2% /
# 示例4 将原始文件/tmp/passwd 删除看看其他两个文件是否能查看
[root@chenshiren tmp]# cat passwd-csq # 可以查看
[root@chenshiren tmp]# cat passwd-zhw # 不可以查看
cat: passwd-zhw: 没有那个文件或目录
关于目录的链接数量
当我们以硬链接进行文件的链接时,可以发现,在【ls -l】所显示的第二个字段会增加一才对,那么,创建目录时,它默认的链接数量会是多少?还会是一
目录在Linux文件系统中会默认包含两个硬链接:一个指向该目录本身,一个指向该目录的父目录。
[root@chenshiren ~]# mkdir csq
[root@chenshiren ~]# ls -ld csq/
drwxr-xr-x. 2 root root 6 3月 4 16:53 csq/ # 两个链接
[root@chenshiren ~]# mkdir csq/zhw
[root@chenshiren ~]# ls -ld csq/ # 再创建目录只增加一个链接
drwxr-xr-x. 3 root root 17 3月 4 16:54 csq/
磁盘的分区、格式化、检验与挂载
如果我们想要在系统里面新增一块磁盘,应该有哪些操作需要做:
- 磁盘分区
- 磁盘格式化
- 文件系统检验
- 挂载磁盘
观察磁盘分区状态:lsblk、blkid、
lsblk:列出系统上的所有磁盘列表
lsblk是【list block device】的缩写
[root@chenshiren ~]# lsblk [-dfimpt] [device]
| 选项 | 作用 |
|---|---|
| -d | 用于显示整个磁盘而非分区的信息 |
| -f | 显示完整的信息,包括文件系统类型、UUID等 |
| -i | 使用ASCII的字符输出,不要使用复杂的编码 |
| -m | 同时输出该设备在/dev 下面的权限信息(rwx的数据) |
| -p | 以全路径显示设备节点路径 |
| -t | 列出该磁盘设备的详细数据,包括磁盘阵列机制,预读写的数据量大小 |
# 示例1 列出本系统下的所有磁盘与磁盘内的分区信息
[root@chenshiren ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 8.9G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 300M 0 part
├─nvme0n1p2 259:2 0 1M 0 part
├─nvme0n1p3 259:3 0 1G 0 part /boot
├─nvme0n1p4 259:4 0 2G 0 part [SWAP]
└─nvme0n1p5 259:5 0 16.7G 0 part /
nvme0n2 259:6 0 20G 0 disk
└─nvme0n2p1 259:7 0 20G 0 part
- NAME:就是设备的文件名,会省略/dev等前导目录
- MAJ:MIN:其实内核识别的设备都是通过这两个代码来实现的,分别是主要与次要设备代码
- RM:是否为可卸载设备(removable device ),如光盘、USB 磁盘等;
- SIZE:当然就是容量
- RO:是否为只读设备的意思
- TYPE:是磁盘(disk)、分区(part)还是只读存储器(rom)等输出
- MOUNTPOINT:就是挂载点
blkid:列出设备的UUID等参数
lsblk -f 也可以列出文件系统与设备的UUID数据
[root@chenshiren ~]# blkid
/dev/nvme0n1p5: UUID="205e6436-c996-4e74-95c2-469e7359a8f2" TYPE="xfs" PARTUUID="18a2fc52-45c3-4432-91fe-3f39c83e98f7"
/dev/nvme0n1p3: UUID="a0af4b7c-a869-4878-af70-40226ede5b91" TYPE="xfs" PARTUUID="f2af498c-d9e3-4c3a-b4d5-06ae09dd18a9"
/dev/nvme0n1p1: PARTUUID="27a8469a-5ffe-ff46-a679-30c0de080ed8"
/dev/nvme0n1p4: UUID="df24e683-7e21-4ff3-91bc-e1c1f53234de" TYPE="swap" PARTUUID="a4af7b02-46ef-48cd-8b86-02503969f574"
/dev/nvme0n1p2: PARTUUID="1d0ca8ad-63d0-48b4-b8b2-2a84afd6c86f"
/dev/sr0: UUID="2023-04-13-16-58-02-00" LABEL="RHEL-9-2-0-BaseOS-x86_64" TYPE="iso9660" PTUUID="d3d1f9a5" PTTYPE="dos"
/dev/nvme0n2p1: UUID="e972e669-1de9-4a67-ac67-52c2a82e82f4" TYPE="ext4" PARTUUID="a0f96632-01"
每一行代表一个文件系统,主要列出设备名称、UUID以及文件系统的类型
parted:列出磁盘的分区表类型与分区信息
[root@chenshiren ~]# parted /dev/nvme0n2 print
错误: /dev/nvme0n3: 无法辨识的磁盘卷标
型号:VMware Virtual NVMe Disk (nvme)
磁盘 /dev/nvme0n3:21.5GB
扇区大小 (逻辑/物理):512B/512B
分区表:unknown <==表示没有识别分区表,因为我这个是新硬盘没设置
磁盘标志:
磁盘分区:gdisk/fdisk
注意:MBR分区表使用fdisk分区,GPT分区表使用gdisk分区
gdisk
初次使用gdisk
[root@chenshiren ~]# gdisk 设备名称
# 示例 为新硬盘创建GPT分区表
[root@chenshiren ~]# gdisk /dev/nvme0n3
GPT fdisk (gdisk) version 1.0.7
Partition table scan:
MBR: not present
BSD: not present
APM: not present
GPT: not present
Creating new GPT entries in memory. # 没有识别到分区表
Command (? for help): ? # 输入?号查看可用命令
b back up GPT data to a file
c change a partition's name
d delete a partition # 删除分区
i show detailed information on a partition
l list known partition types # 列出已知的分区类型
n add a new partition # 添加新分区
o create a new empty GUID partition table (GPT) # 创建新的空GUID分区表(GPT)
p print the partition table # 打印分区表
q quit without saving changes # 不保存退出
r recovery and transformation options (experts only)
s sort partitions
t change a partition's type code. # 更改分区的类型
v verify disk
w write table to disk and exit # 保存分区操作后离开gdisk
x extra functionality (experts only)
? print this menu
Command (? for help): o # 按o 创建新的空GUID分区表(GPT)
This option deletes all partitions and creates a new protective MBR.
Proceed? (Y/N): y # 按y 同意删除所有分区
Command (? for help): w # 保存分区退出 gdisk
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y # 同意覆盖
OK; writing new GUID partition table (GPT) to /dev/nvme0n3.
The operation has completed successfully. # 操作完成
[root@chenshiren ~]# parted /dev/nvme0n2 print
型号:VMware Virtual NVMe Disk (nvme)
磁盘 /dev/nvme0n2:21.5GB
扇区大小 (逻辑/物理):512B/512B
分区表:gpt <== 设置完成
磁盘标志:
编号 起始点 结束点 大小 文件系统 名称 标志
[root@chenshiren ~]# gdisk /dev/nvme0n2
GPT fdisk (gdisk) version 1.0.7
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT. # 再次进入就自动识别了
Command (? for help):
用gdisk新增分区
分区需求:
- 1GB的xfs文件系统(Linux)
- 1GB的vfat文件系统(Windows)
- 1GB的swap(Linux swap)一会要删除这个分区
[root@chenshiren ~]# gdisk /dev/nvme0n2
Command (? for help): n # 新增分区
Partition number (1-128, default 1): # 默认为1号直接回车
First sector (34-41943006, default = 2048) or {+-}size{KMGTP}: # 回车
Last sector (2048-41943006, default = 41943006) or {+-}size{KMGTP}: +1G # 容量
# 这里直接回车的话会将所有的容量用光
Current type is 8300 (Linux filesystem)
Hex code or GUID (L to show codes, Enter = 8300): # 默认值回车
Changed type of partition to 'Linux filesystem'
Command (? for help): p # 打印分区信息
...
Number Start (sector) End (sector) Size Code Name
1 2048 2099199 1024.0 MiB 8300 Linux filesystem
# 如法炮制创建其他两个分区
Command (? for help): p
Disk /dev/nvme0n2: 41943040 sectors, 20.0 GiB
Model: VMware Virtual NVMe Disk
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): 35E07EB6-C028-4816-B425-7BDAD860D3D8
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 35651517 sectors (17.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 6293504 8390655 1024.0 MiB 8300 Linux filesystem
2 10487808 12584959 1024.0 MiB 0700 Microsoft basic data
3 8390656 10487807 1024.0 MiB 8200 Linux swap
# Number:分区编号
# Start:起始扇区
# End:结束扇区
# Size:大小
# Code:分区类型码,8300 (Linux 文件系统) swap为8200 windows为0700
# 如果忘了这些数字,可以通过 gdisk 按下L来显示
# Name:文件系统的名称
# 分区正常的话直接保存写入磁盘分区表
Command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y # 会警告你你得确定你分区是对的,然后按下y
OK; writing new GUID partition table (GPT) to /dev/nvme0n2.
The operation has completed successfully.
# 显示系统中所有磁盘和分区的信息
[root@chenshiren ~]# cat /proc/partitions
major minor #blocks name
259 0 20971520 nvme0n1
259 1 307200 nvme0n1p1
259 2 1024 nvme0n1p2
259 3 1048576 nvme0n1p3
259 4 2066432 nvme0n1p4
259 5 17546240 nvme0n1p5
259 6 20971520 nvme0n2
259 8 1048576 nvme0n2p1
259 9 1048576 nvme0n2p2
259 10 1048576 nvme0n2p3
259 7 20971520 nvme0n3
11 0 9371072 sr0
# 发现已经更新了 nvme0n2p1 nvme0n2p2 nvme0n2p3 这三个是新创建的
如果你分区的时候 Linux此时还在使用这块磁盘,因为担心系统出现问题,所以分区表并没有被更新,这个时候我们有两个方式可以来处理,一个是重新启动,另一个通过【partprobe】这个命令来处理
partprobe:更新Linux内核的分区表信息
[root@chenshiren ~]# partprobe
用gdisk删除分区
删除nvme0n2p3这个分区
[root@chenshiren ~]# gdisk /dev/nvme0n2
GPT fdisk (gdisk) version 1.0.7
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): p # 展示分区表
Disk /dev/nvme0n2: 41943040 sectors, 20.0 GiB
Model: VMware Virtual NVMe Disk
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): 35E07EB6-C028-4816-B425-7BDAD860D3D8
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 35651517 sectors (17.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 6293504 8390655 1024.0 MiB 8300 Linux filesystem
2 10487808 12584959 1024.0 MiB 0700 Microsoft basic data
3 8390656 10487807 1024.0 MiB 8200 Linux swap
Command (? for help): d # 删除这个分区
Partition number (1-3): 3
Command (? for help): w # 保存
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/nvme0n2.
The operation has completed successfully.
[root@chenshiren ~]# lsblk # nvme0n2p3这个分区没了
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 8.9G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 300M 0 part
├─nvme0n1p2 259:2 0 1M 0 part
├─nvme0n1p3 259:3 0 1G 0 part /boot
├─nvme0n1p4 259:4 0 2G 0 part [SWAP]
└─nvme0n1p5 259:5 0 16.7G 0 part /
nvme0n2 259:6 0 20G 0 disk
├─nvme0n2p1 259:7 0 1G 0 part
└─nvme0n2p2 259:8 0 1G 0 part
fdisk
处理MBR分区表,就得要使用fdisk
fdisk和gdisk使用方式几乎一样
fdisk 设置分区类型 需要分区完成 按l才能设置
# 这里我创建了一个新的硬盘来演示创建MBR分区表
[root@chenshiren ~]# parted /dev/nvme0n3 print
错误: /dev/nvme0n3: 无法辨识的磁盘卷标
型号:VMware Virtual NVMe Disk (nvme)
磁盘 /dev/nvme0n3:21.5GB
扇区大小 (逻辑/物理):512B/512B
分区表:unknown
磁盘标志:
[root@chenshiren ~]# fdisk /dev/nvme0n3
欢迎使用 fdisk (util-linux 2.37.4)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
设备不包含可识别的分区表。
创建了一个磁盘标识符为 0xf9b43f98 的新 DOS 磁盘标签。 # 自动创建了MBR分区表
命令(输入 m 获取帮助):m # 输入m显示帮助信息
帮助:
DOS (MBR)
a 开关 可启动 标志
b 编辑嵌套的 BSD 磁盘标签
c 开关 dos 兼容性标志
常规
d 删除分区
F 列出未分区的空闲区
l 列出已知分区类型
n 添加新分区
p 打印分区表
t 更改分区类型
v 检查分区表
i 打印某个分区的相关信息
杂项
m 打印此菜单
u 更改 显示/记录 单位
x 更多功能(仅限专业人员)
脚本
I 从 sfdisk 脚本文件加载磁盘布局
O 将磁盘布局转储为 sfdisk 脚本文件
保存并退出
w 将分区表写入磁盘并退出
q 退出而不保存更改
新建空磁盘标签
g 新建一份 GPT 分区表
G 新建一份空 GPT (IRIX) 分区表
o 新建一份的空 DOS 分区表
s 新建一份空 Sun 分区表
命令(输入 m 获取帮助):w # 保存并退出
分区表已调整。
将调用 ioctl() 来重新读分区表。
正在同步磁盘。
[root@chenshiren ~]# parted /dev/nvme0n3 print
型号:VMware Virtual NVMe Disk (nvme)
磁盘 /dev/nvme0n3:21.5GB
扇区大小 (逻辑/物理):512B/512B
分区表:msdos # msdos通常表示使用的是MBR分区表
磁盘标志:
编号 起始点 结束点 大小 类型 文件系统 标志
磁盘格式化(创建文件系统):mkfs.xfs、mkfs.ext4
XFS文件系统mkfs.xfs
常常听到的格式化文件系统,其实应该称为创建文件系统(make filesystem)才合适,所以使用的命令是【mkfs】拿我们创建的是xfs文件系统,因此使用的是【mkfs.xfs】命令
[root@chenshiren ~]# mkfs.xfs [-b bsize] [-d parms] [-i parms] [-L label] [-f] [-r parms] 设备名称
选项:
-b bsize:指定文件系统的区块容量,由512~64K,Linux最大容量限制为4k
-d parms:后面接的是重要的data section的相关数值,主要的值有:
agcount=数值 :设置需要几个存储群组的意思(AG),通常与CPU有关
agsize=数值 :每个AG设置为多少容量的意思,通常agcount/agsize只选一个设置即可
file :指的是【格式化的设备是个文件而不是设备】的意思
size=数值 :data section的容量,就是你可以不将全部的设备容量用完的意思
su=数值 :当有RAID时,那个stripe数值的意思,与下面的sw搭配使用
sw=数值 : 当有RAID时,用于保存数据的磁盘数量(须扣除备份盘与备用盘)
sunit=数值 :与su相当,不过单位使用的是【几个sector(512Bytes大小)】的意思
swidth=数值 :就是su*sw的数值,但是以【几个sector(512Bytes大小)】来设置
-f :如果设备内已经有文件系统,则需用-f来强制格式化才行
-i parms:与inode有较相关的设置,主要设置有:
size=数值 :最小是256Bytes最大是2k,一般保留256就足够用了
internal=[0|1]:log设备是否为内置?默认1为内置,如果要用外部设置,使用下面设置
logdev=device :log设备为后面接的那个设备上面的意思,需设置 internal=0 才可
size=数值 :指定这块登录区的容量,通常最小得要有512个区块,大约2M以上才行
-L label:后面接这个文件系统的标头名称 Label name 的意思。
-r parms:指定 realtime section 的相关设置值,常见的有:
extsize=数值 :就是那个重要的 extent数值,一般不需设置,但有RAID时
最好设置与 swidth的数值相同较佳。最小为4K最大为 1G。
示例
# 示例1将前面小节分出来的/dev/nvme0n2p1格式化为xfs文件系统
[root@chenshiren ~]# mkfs.xfs /dev/nvme0n2p1
meta-data=/dev/nvme0n2p1 isize=512 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@chenshiren ~]# blkid /dev/nvme0n2p1
/dev/nvme0n2p1: UUID="9d846c66-fb9a-4be0-9e94-ec182f79ec7a" TYPE="xfs" PARTLABEL="Linux filesystem" PARTUUID="8b8009b4-6247-43a5-8f93-bbb79cf3c19b"
# 创建好了xfs文件系统,使用的默认数值
举例来说,因为 xfs 可以使用多个数据流来读写系统,以增加速度,因此那个 agcount 可以跟 CPU 的内核数来做搭配。举例来说,如果我的服务器仅有4个物理内核,但是使用 Intel超线程技术,则系统会模拟出8个CPU 时,那个 agcount 就可以设置为 8。举个例子来看看:
# 示例2 找出系统的CPU数,并据以设置你的agcount值
[root@chenshiren ~]# grep 'processor' /proc/cpuinfo
processor : 0
processor : 1
processor : 2
processor : 3
# 4块CPU
# 因为agcount本来默认就是4 这次改一下2看看
[root@chenshiren ~]# mkfs.xfs -f -d agcount=2 /dev/nvme0n2p1
meta-data=/dev/nvme0n2p1 isize=512 agcount=2, agsize=131072 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# agcount已经设置为了2
ext4文件系统 mkfs.ext4
[root@chenshiren ~]# mkfs.ext4 [-b size] [-L label] 设备名称
选项:
-b:设置区块大小,有1k、2k、4K的容量
-L:后面接这个设备的标头名称
# 示例1 将/dev/nvme0n2p2格式化为ext4文件系统
[root@chenshiren ~]# mkfs.ext4 /dev/nvme0n2p2
mke2fs 1.46.5 (30-Dec-2021)
创建含有 262144 个块(每块 4k)和 65536 个inode的文件系统
文件系统UUID:d4897005-cdd0-472b-9401-988d42090ed3
超级块的备份存储于下列块:
32768, 98304, 163840, 229376
正在分配组表: 完成
正在写入inode表: 完成
创建日志(8192 个块)完成
写入超级块和文件系统账户统计信息: 已完成
[root@chenshiren ~]# blkid /dev/nvme0n2p2
/dev/nvme0n2p2: UUID="4ca867ef-3ee5-45a0-a22e-9990b6806641" TYPE="ext4" PARTLABEL="Microsoft basic data" PARTUUID="db5f1de1-8510-40cc-88f2-36193bd7c170"
其他文件系统mkfs
mkfs其实是一个综合命令,当我们使用 【mkfs -t xfs】,它就会去找【mkfs.xfs】相关参数给我们使用
[root@chenshiren ~]# mkfs [tab] [tab]
mkfs mkfs.ext2 mkfs.ext4 mkfs.minix mkfs.vfat
mkfs.cramfs mkfs.ext3 mkfs.fat mkfs.msdos mkfs.xfs
将/dev/nvme0n2p2重新格式化为 VFAT文件系统
[root@chenshiren ~]# mkfs -t vfat /dev/nvme0n2p2
[root@chenshiren ~]# blkid /dev/nvme0n2p2
/dev/nvme0n2p2: UUID="5D91-4D51" TYPE="vfat" PARTLABEL="Microsoft basic data" PARTUUID="db5f1de1-8510-40cc-88f2-36193bd7c170"
[root@chenshiren ~]# mkfs.ext4 /dev/nvme0n2p2
[root@chenshiren ~]# blkid /dev/nvme0n2p2
/dev/nvme0n2p2: UUID="2e8ea289-516e-4e6a-bab9-3a0978b5d3ac" TYPE="ext4" PARTLABEL="Microsoft basic data" PARTUUID="db5f1de1-8510-40cc-88f2-36193bd7c170"
文件系统检验:xfs_repair 、fsck.ext4
xfs_repair 处理XFS文件系统
当有XFS文件系统错乱才需要使用这个命令
[root@chenshiren ~]# xfs_repair [-fnd] 设备名称
选项:
-f:后面的设备其实是个文件而不是实体设备
-n:单纯检查并不修改文件系统的任何数据
-d:通常用在单人维护模式下,针对根目录(/)进行检查与修复的操作,很危险,不要随便使用
# 示例1 检查一下刚刚建立的 /dev/nvme0n2p1 XFS文件系统
[root@chenshiren ~]# xfs_repair /dev/nvme0n2p1
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- zero log...
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 1
- agno = 0
Phase 5 - rebuild AG headers and trees...
- reset superblock...
Phase 6 - check inode connectivity...
- resetting contents of realtime bitmap and summary inodes
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify and correct link counts...
done
# 使用 man xfs_repair 查看详细检查流程
xfs_repair 可以检查/修复文件系统,不过,因为修复文件系统是个很庞大的任务。因此,修复时该文件系统不能被挂载。
Linux 系统有个设备无法被卸载,那就是根目录。如果你的根目录有问题怎么办?这时要进入单人维护或恢复模式,然后通过-d 这个选项来处理。加入-d 这个选项后,系统会强制检验该设备检验完毕后就会自动重新启动。
fsck.ext4 处理 ext4 文件系统
[root@chenshiren ~]# fsck.ext4 [-pf] [-b 超级区块] 设备名称
选项:
-p:当文件系统在修复时,若有需要回覆y的操作时,自动回覆y来继续进行修复操作
-f:强制检查,一般来说,如果fsck没有发现任何unclean的标识,不会主动进入
详细检查的,如果您想要强制 £sck详细检查,就得加上-f标识
-D:针对文件系统下的目录进行最佳化配置。
-b:后面接超级区块的位置,一般来说这个选项用不到但是如果你的超级区块因故损坏时
通过这个参数即可利用文件系统内备份的超级区块来尝试恢复,一般来说,超级区块备份在:
1K区块放在8193,2K区块放在16384,4K区块放在32768。
# 示例1 找出刚刚创建的/dev/nvme0n2p2 的另一块超级区块,并据以检测系统
[root@chenshiren ~]# dumpe2fs -h /dev/nvme0n2p2 |grep 'Blocks per group'
dumpe2fs 1.46.5 (30-Dec-2021)
Blocks per group: 32768
# 看起来每个区块群组会有32768个区块,因此第二个超级区块一个就在32768上
# 因为block号码从0号开始编的
[root@chenshiren ~]# fsck.ext4 -b 32768 /dev/nvme0n2p2
e2fsck 1.46.5 (30-Dec-2021)
/dev/nvme0n2p2 未被彻底卸载,强制进行检查。
第 1 步:检查inode、块和大小
删除inode 1841 的删除时间为零。 处理<y>? 是
第 2 步:检查目录结构
第 3 步:检查目录连接性
第 4 步:检查引用计数
第 5 步:检查组概要信息
块位图的差异: +(32768--32896) +(98304--98432) +(163840--163968)
处理<y>? 是
Inode位图末尾的填充值未设置。 处理<y>? 是
/dev/nvme0n2p2:***** 文件系统已修改 *****
/dev/nvme0n2p2:11/65536 文件(0.0% 为非连续的), 12955/262144 块
# 文件系统状态正常,它并不会进入强制检查,会告诉你文件系统没问题
[root@chenshiren ~]# fsck.ext4 -f /dev/nvme0n2p2
e2fsck 1.46.5 (30-Dec-2021)
第 1 步:检查inode、块和大小
第 2 步:检查目录结构
第 3 步:检查目录连接性
第 4 步:检查引用计数
第 5 步:检查组概要信息
/dev/nvme0n2p2:11/65536 文件(0.0% 为非连续的), 12955/262144 块
[root@chenshiren ~]#
无论是 xfs_repair 或 fsck.ext4,这都是用来检查与修正文件系统错误的命令。`注意:通常只有身为root且你的文件系统有问题的时候才使用这个命令,否则在正常状况下使用此命令、可最会造成对系统的危害。
执行xfs_repair 或 fsck.ext4时,被检查的硬盘分区不可挂载到系统上
文件系统挂载与卸载:mount、umount
挂载点是目录,而这个目录是进入磁盘分区(就是文件系统)的入口。
挂在前要确定的事情:
- 单一文件系统不应该被重复挂载在不同的挂载点(目录)中
- 单一目录不应该重复挂载多个文件系统
- 要作为挂载点的目录,理论上应该都是空目录才行,如果目录里面不是空的,那么挂载了文件系统后,原目录下的东西就会暂时地消失,当分区被卸载,原本的内容才会再次显现
mount
[root@chenshiren ~]# mount -a
[root@chenshiren ~]# mount [-l]
[root@chenshiren ~]# mount [-t 文件系统] LABEL='' 挂载点
[root@chenshiren ~]# mount [-t 文件系统] UUID='' 挂载点
[root@chenshiren ~]# mount [-t 文件系统] 设备文件名 挂载点
选项:
-a:依照配置文件/etc/fstab的数据将所有未挂载的磁盘都挂载上来
-l:单纯输入mount会显示目前挂载信息,加上-l可增列Label名称
-t:以加上文件系统种类来指定欲挂载的类型,常见的inux支持类型有:xfs、ext3、ext4、reiserfs、
vfat、iso9660(光盘格式)、nfs、cifs、smbfs(后三种为网络文件系统类型)。
-n:在默认的情况下,系统会将实际挂载的情况即时写入/etc/mtab中,以利其他程序的运行
在某些情况下(例如单人维护模式)为了避免问题会刻意不写入,此时就得要使用-n选项
-o:后面可以接一些挂载时额外加上的参数。比如账号、密码、读写权限等:
async,sync :此文件系统是否使用同步写入(sync)或非同步(async)的
内存机制,请参考文件系统运行方式,默认为async。
atime,noatime:是否修改文件的读取时间(atime)。为了性能,某些时刻可使用 noatime
ro,rw :挂载文件系统改成ro(只读),rw(可读可写)
auto,noauto :允许此文件系统被以mount-a自动挂载(auto)
dev,nodev :是否允许此文件系统可建立设备文件?dev为可允许
suid, nosuid :是否允许此文件系统含有 suid/sgid的文件格式?
exec,noexec :是否允许此文件系统上拥有可执行的二进制文件
user,nouser :是否允许此文件系统让任何使用者执行mount?
一般来说,mount仅有root可以进行
defaults :默认值为:rw、suid、dev、exec、auto、nouser、and async
remount :重新挂载
在挂载时 不需要加上 -t这个选项,系统会自动分析最恰当的文件系统来尝试挂载你需要的设备,会自动分析最适当的文件系统来尝试挂载设备,而不需要手动指定文件系统类型。系统会通过分析设备的超级块信息,结合Linux内核的驱动程序来测试挂载,如果测试成功,系统就会自动使用该类型的文件系统进行挂载操作。
系统会参考两个文件来确定需要进行挂载测试的文件系统类型:
-
/etc/filesystems:这个文件包含了系统指定要进行测试挂载的文件系统类型的优先级。
-
/proc/filesystems:这个文件列出了Linux系统已加载的文件系统类型。
挂载 xfs/ext4文件系统
[root@chenshiren ~]# mkdir -p /data/{xfs,ext4}
[root@chenshiren ~]# mount /dev/nvme0n2p1 /data/xfs/
[root@chenshiren ~]# mount /dev/nvme0n2p2 /data/ext4/
[root@chenshiren ~]# df -hT /data/*
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/nvme0n2p2 ext4 974M 24K 907M 1% /data/ext4
/dev/nvme0n2p1 xfs 1014M 40M 975M 4% /data/xfs
挂载CD或DVD光盘
# 将你用来安装Linux的光盘镜像拿出来挂载到/data/cdrom
[root@chenshiren ~]# mount /dev/sr0 /data/cdrom/
mount: /data/cdrom: WARNING: source write-protected, mounted read-only.
[root@chenshiren ~]# df -hT /data/*
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/sr0 iso9660 9.0G 9.0G 0 100% /data/cdrom
/dev/nvme0n2p2 ext4 974M 24K 907M 1% /data/ext4
/dev/nvme0n2p1 xfs 1014M 40M 975M 4% /data/xfs
# 已用100%因为他是DVD,已经无法写入了
# 光驱挂载后就无法退出光盘了,除非你将他卸载才能退出
挂载U盘
# 插上U盘并挂载
[root@chenshiren ~]# mkdir /data/USB/
[root@chenshiren ~]# mount -o vfat /dev/sda4 /data/USB/
[root@chenshiren ~]# ls /data/USB/
[root@chenshiren ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs tmpfs 779M 9.6M 769M 2% /run
/dev/nvme0n1p5 xfs 17G 4.2G 13G 25% /
/dev/nvme0n1p3 xfs 1014M 257M 758M 26% /boot
tmpfs tmpfs 390M 52K 390M 1% /run/user/42
tmpfs tmpfs 390M 36K 390M 1% /run/user/0
/dev/sda4 fuseblk 30G 22G 7.5G 75% /data/USB
/dev/sr0 iso9660 9.0G 9.0G 0 100% /data/cdrom
/dev/nvme0n2p2 ext4 974M 24K 907M 1% /data/ext4
/dev/nvme0n2p1 xfs 1014M 40M 975M 4% /data/xfs
重新挂载根目录与挂载不特定目录
整个目录树最重要的地方就是根目录,所以根目录根本就不能够被卸载。
如果你的挂载参数要改变或者根目录出现【只读】状态时,可以使用如下命令来【重新挂载】根目录,并将其挂载为读写模式
[root@chenshiren ~]# mount -o remount rw,auto /
另外,也可以使用mount命令将一个目录挂载到另一个目录,而不是挂载文件系统
[root@chenshiren ~]# mkdir /data/var
[root@chenshiren ~]# mount --bind /var/ /data/var/
[root@chenshiren ~]# ll -id /var/ /data/var/
133 drwxr-xr-x. 20 root root 4096 2月 26 00:08 /data/var/
133 drwxr-xr-x. 20 root root 4096 2月 26 00:08 /var/
# 内容一模一样,因为挂载目录的缘故
[root@chenshiren ~]# mount |grep var
/dev/nvme0n1p5 on /data/var type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,noquota)
# 可以通过mount --bind 的功能,可以将某个目录挂载到其他目录,而不是整个文件系统
# 进入 /data/var 相当于进入了 /var
umount:将设备文件卸载
[root@chenshiren ~]# umount [-fn] 设备文件或挂载点
选项:
-f:强制卸载
-n:不更新/etc/mtab 的情况下卸载
-l:立刻卸载文件系统
umount就是将已经挂载的文件系统卸载,卸载之后,可以使用df或mount看看是否还存在于目录树中
[root@chenshiren ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs tmpfs 779M 9.6M 769M 2% /run
/dev/nvme0n1p5 xfs 17G 4.2G 13G 25% /
/dev/nvme0n1p3 xfs 1014M 257M 758M 26% /boot
tmpfs tmpfs 390M 52K 390M 1% /run/user/42
tmpfs tmpfs 390M 36K 390M 1% /run/user/0
/dev/sr0 iso9660 9.0G 9.0G 0 100% /data/cdrom
/dev/nvme0n2p2 ext4 974M 24K 907M 1% /data/ext4
/dev/nvme0n2p1 xfs 1014M 40M 975M 4% /data/xfs
[root@chenshiren ~]# umount /data/cdrom
[root@chenshiren ~]# umount /data/ext4
[root@chenshiren ~]# umount /data/xfs
[root@chenshiren ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs tmpfs 779M 9.6M 769M 2% /run
/dev/nvme0n1p5 xfs 17G 4.2G 13G 25% /
/dev/nvme0n1p3 xfs 1014M 257M 758M 26% /boot
tmpfs tmpfs 390M 52K 390M 1% /run/user/42
tmpfs tmpfs 390M 36K 390M 1% /run/user/0
磁盘/文件系统参数自定义:mknod、xfs_admin、tune2fs
mkond:创建设备文件
Linux下所有的设备都以文件表示,设备节点文件是用来代表设备的接口,它们位于/dev/目录下。每个设备节点文件都有一个对应的主设备号(major number)和次设备号(minor number),这些数值是用来唯一标识设备的。
-
主设备号(major number):用于指示设备所属的设备驱动程序。
-
次设备号(minor number):用于指示同一类型设备的不同实例。
查看/dev/nvme0n1的相关设备代码
[root@chenshiren ~]# ll /dev/nvme0n1*
brw-rw----. 1 root disk 259, 0 3月 5 13:53 /dev/nvme0n1
brw-rw----. 1 root disk 259, 1 3月 5 13:53 /dev/nvme0n1p1
brw-rw----. 1 root disk 259, 2 3月 5 13:53 /dev/nvme0n1p2
brw-rw----. 1 root disk 259, 3 3月 5 13:53 /dev/nvme0n1p3
brw-rw----. 1 root disk 259, 4 3月 5 13:53 /dev/nvme0n1p4
brw-rw----. 1 root disk 259, 5 3月 5 13:53 /dev/nvme0n1p5
# 259为主要设备代码(major),而0~5则为次要设备代码
设备代码
| 磁盘文件名 | major | minor |
|---|---|---|
| /dev/sda | 8 | 0 |
| /dev/sdb | 8 | 16 |
| /dev/loop0 | 7 | 0 |
| /dev/loop1 | 7 | 1 |
| /dev/nvme0 | 259 | 0 |
语法
[root@chenshiren ~]# mknod 设备文件名 [-bcp] [major] [minor]
选项:
-b:设置设备名称成为一个外接存储设备文件,例如:磁盘
-c:设置设备名称成为一个外接输入设备文件,例如:鼠标/键盘等
-p:设置设备名称成为一个FIFO文件
major:主设备代码
minor:次设备代码
# 示例:
# 创建块设备文件
[root@chenshiren ~]# mknod /dev/nvme0n4 b 259 0
[root@chenshiren ~]# ls -l /dev/nvme0n4
brw-r--r--. 1 root root 259, 0 3月 5 15:58 /dev/nvme0n4
# 测试完毕后删除
xfs_admin:修改XFS文件系统的UUID与Label name
[root@chenshiren ~]# xfs_admin [-lu] [-L label] [-U uuid] 设备文件名
选项:
-l:列出这个设备的Label name
-u:列出这个设备的UUID
-L:设置这个设备的Label name
-U:设置这个设备的UUID
# 示例1 设置 /dev/nvme0n2p1 的label name 为 chenshiren_xfs
[root@chenshiren ~]# xfs_admin -L csr_xfs /dev/nvme0n2p1
writing all SBs
new label = "csr_xfs"
[root@chenshiren ~]# xfs_admin -l /dev/nvme0n2p1
label = "csr_xfs"
# 示例2 利用 uuidgen产生新UUID来设置/dev/nvme0n2p1
# 如果/dev/nvme0n2p1被挂载了,需要卸载
[root@chenshiren ~]# uuidgen
ca71bc18-7601-499f-b7bc-904e8ec3d7ec
[root@chenshiren ~]# xfs_admin -u /dev/nvme0n2p1
UUID = 2444c140-1199-4fa4-876f-5e786650d256
[root@chenshiren ~]# xfs_admin -U ca71bc18-7601-499f-b7bc-904e8ec3d7ec /dev/nvme0n2p1
Clearing log and setting UUID
writing all SBs
new UUID = ca71bc18-7601-499f-b7bc-904e8ec3d7ec
[root@chenshiren ~]# xfs_admin -u /dev/nvme0n2p1
UUID = ca71bc18-7601-499f-b7bc-904e8ec3d7ec
[root@chenshiren ~]# mount UUID=ca71bc18-7601-499f-b7bc-904e8ec3d7ec /mnt/
为什么要使用UUID挂载?
-
跨系统兼容性:不同的Linux系统在识别磁盘时可能会赋予不同的设备文件名,导致在不同系统上挂载时需要不同的命令。而UUID是独一无二的,不会因为系统不同而发生变化,使得跨系统挂载更加简单和方便。
-
唯一性:UUID是全局唯一标识符,几乎不会出现冲突,可以确保不同设备拥有不同的标识。
-
精准性:与使用LABEL相比,UUID更加精准,不存在因为重命名或其他操作而导致的问题,使用UUID可以帮助系统管理员更加方便地管理和识别不同设备,降低挂载出错的可能性。
设备启动挂载
启动挂载/etc/fstab及/etc/mtab
系统挂载的一些限制:
-
根目录 /是必须挂载的,而且一定要先于其他挂载点(mount point)被挂载进来。
-
其他挂载点必须为已建立的目录,可任意指定,但一定要遵守必需的系统目录架构原则(FHS)
-
所有挂载点在同一时间之内,只能挂载一次
-
所有硬盘分区在同一时间之内,只能挂载一次
-
如若进行卸载,必须先将工作目录移到挂载点(及其子目录)之外
/etc/fstab文件的内容
[root@chenshiren ~]# cat /etc/fstab
...
UUID=205e6436-c996-4e74-95c2-469e7359a8f2 / xfs defaults 0 0
UUID=a0af4b7c-a869-4878-af70-40226ede5b91 /boot xfs defaults 0 0
UUID=df24e683-7e21-4ff3-91bc-e1c1f53234de none swap defaults 0 0
# 其实/etc/fstab(filesystem table)就是利用mount命令挂载时
# 将所有的选项与参数写入的文件
-
第一栏:磁盘设备文件名 /UUID/LABEL name
这个字段可以填写的数据主要有三个项目:
- 文件系统或磁盘的设备文件名,如/dev/nvme0n2p1
- 文件系统的UUID名称,如 UUID=xxx
- 文件系统的LABEL名称,如 LABEL=xxx
-
第二栏:挂载点
挂载点一定是目录
-
第三栏:磁盘分区的文件系统
在手动挂载时可以让系统自动测试挂载,在这个文件中必须要手动写入文件系统才行,如 xfs ext4等
-
第四栏:文件系统参数
参数 作用 async/sync
异步/同步设置磁盘是否以异步方式运行,默认为async(性能较佳) auto/noauto
自动/非自动当执行mount -a时,此时文件系统是否会被主动测试挂载,默认为auto rw/ro
可读可写/只读让该分区以可读可写或只读的状态挂载上来
如果你想要分享的数据是不给用户随意变更可以设置为只读
则不论文件系统的文件是否设置w权限,都无法写入exec/noexec
可执行/不可执行限制在此文件系统内是否可以进行【执行】的工作 user/nouser
允许/不允许用户挂载是否允许用户使用mount命令来挂载 suid/nosuid
具有/不具有suid权限该文件系统是否允许SUID的存在 defaults 同时具有 rw、suid、dev、exec、auto、nouser、async等参数 -
第五栏:能否被dump备份命令作用
dump是一个用来做为备份的命令,不过现在有太多备份的方案,直接输入0即可
-
第六栏:是否以fsck检验扇区
早期启动的流程中,会有一段时间去检验本机的文件系统,看看文件系统是否完整。不过这个阶段主要是通过fsck去完成,现在用的xfs文件系统就没有办法适用,因为xfs会自己进行检验,不需要额外进行这个操作,填0即可
# 示例1
# 首先用nano将下面这一行写入 /etc/fstab 最后面中
/dev/nvme0n2p1 /data/xfs xfs defaults 0 0
# 再来看看/dev/nvme0n2p1是否被挂载,如被挂载需要给他卸载了
[root@chenshiren ~]# df
# 测试/etc/fstab的语法有没有错误,这点很重要。因为这个文件如果写错了
# 你得Linux很可能无法顺利启动完成
[root@chenshiren ~]# mount -a
[root@chenshiren ~]# df /data/xfs/
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/nvme0n2p1 1038336 40164 998172 4% /data/xfs
# /dev/nvme0n2p1成功挂载,而且以后每次启动都会顺利地将此文件系统挂载起来
# 可以reboot重新启动,检查看看
/etc/fstab是启动时的配置文件,不过,实际文件系统的挂载是记录到 /etc/mtab与 /proc/mounts 这两个文件中的。每次我们在修改文件系统的挂载时,也会同时修改这两个文件。
当发生/etc/fstab输入错误导致无法启动成功而进入单人维护模式中,可以使用以下方法来修改/etc/fstab并更新/etc/mtab
[root@chenshiren ~]# mount -n -o remount,rw /
特殊设备loop挂载(镜像文件不刻录就挂载使用)
挂载CD/DVD镜像文件
当我们在其他地方下载了CD/DVD镜像文件后,并不一定需要将其刻录成光盘才能使用其中的数据。实际上,我们可以使用loop设备来挂载这些镜像文件。
# 这里使用Rocky来演示
[root@chenshiren ~]# ll -h
-rw-r--r--. 1 root root 9.8G 2月 22 01:17 Rocky-9-latest-x86_64-dvd.iso
# 这个文件就是镜像文件,非常大
[root@chenshiren ~]# mkdir /data/rocky-dvd
[root@chenshiren ~]# mount -o loop Rocky-9-latest-x86_64-dvd.iso /data/rocky-dvd/
mount: /data/rocky-dvd: WARNING: source write-protected, mounted read-only.
[root@chenshiren ~]# df /data/rocky-dvd/
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/loop0 10267282 10267282 0 100% /data/rocky-dvd
# 这个rocky.iso镜像文件内的所有数据可以在 /data/rocky-dvd 看到
[root@chenshiren ~]# ls /data/rocky-dvd/
AppStream BaseOS EFI images isolinux LICENSE media.repo
# 测试完成卸载
[root@chenshiren ~]# umount /data/rocky-dvd
建立大文件以制作loop设备文件
既然能够挂载 DVD 的镜像文件,同样地,可以创建一个大文件,并为其添加一个文件系统,然后将其挂载到一个目录上。这个过程可以模拟出额外的分区的效果。
在/srv下建立一个700MB左右的大文件,然后将这个大文件格式化并且实际挂载
建立大型文件
使用dd可以用来建立空文件,假设我要在 /srv/loopdev建立一个空的文件
[root@chenshiren ~]# dd if=/dev/zero of=/srv/loopdev bs=1M count=700
记录了700+0 的读入
记录了700+0 的写出
734003200字节(734 MB,700 MiB)已复制,0.182871 s,4.0 GB/s
# if :是input file,输入文件,那个/dev/zero是会一直输出0的设备
# of :是output file,将一堆零写入到后面接的文件中
# bs :是每个block大小,就像文件系统那样的block意义
# count:则是总共几个bs的意思,bs*count就是文件的容量
[root@chenshiren ~]# ll -h /srv/loopdev
-rw-r--r--. 1 root root 700M 3月 6 10:17 /srv/loopdev
大型文件的格式化
默认xfs是不能格式化文件的,所以要格式化文件得要加入特别的参数才行
[root@chenshiren ~]# mkfs.xfs -f /srv/loopdev
[root@chenshiren ~]# blkid /srv/loopdev
/srv/loopdev: UUID="27b462ae-6d9c-4c46-9702-839e5694c84b" TYPE="xfs"
挂载
[root@chenshiren ~]# mount -o loop /srv/loopdev /mnt/
[root@chenshiren ~]# df -hT /mnt/
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/loop0 xfs 694M 38M 657M 6% /mnt
# 测试成功设置启动挂载
[root@chenshiren ~]# umount /mnt
设置启动自动挂载
[root@chenshiren ~]# nano /etc/fstab # 写入如下内容
/srv/loopdev /data/file xfs defaults,loop 0 0
[root@chenshiren ~]# mkdir /data/file
[root@chenshiren ~]# mount -a
[root@chenshiren ~]# df /data/file/ -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/loop0 xfs 694M 38M 657M 6% /data/file
内存交换分区(swap)创建
内存交换分区(swap)是操作系统中的一种机制,用于在物理内存不足时提供额外的虚拟内存支持。当系统内存不足以容纳当前正在运行的进程时,操作系统将部分数据从内存移出,并存储到交换分区中,以释放内存空间供其他进程使用
使用物理分区创建内存交换分区
建立内存交换分区的步骤:
- 分区:先使用 gdisk 在你的磁盘中划分出一个分区给系统作为内存交换分区,由于 Linux 的gdisk 默认会将分区的 ID 设置为 Linux 的文件系统,还要设置一下 system lD
- 格式化:利用建立内存交换分区格式的【
mkswap 设备文件名】就能够格式化该分区成为内存交换分区格式 - 使用:最后将该 swap 设备启动,方法为【swapon 设备文件名】
- 观察:最终通过
free与swapon -s这个命令来观察一下内存的使用量
第一步:分区
[root@chenshiren ~]# gdisk /dev/nvme0n2
GPT fdisk (gdisk) version 1.0.7
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): n # 创建分区
Partition number (3-128, default 3):
First sector (34-41943006, default = 12584960) or {+-}size{KMGTP}:
Last sector (12584960-41943006, default = 41943006) or {+-}size{KMGTP}: +2G
Current type is 8300 (Linux filesystem)
Hex code or GUID (L to show codes, Enter = 8300): 8200 # 这里要写8200 swap
Changed type of partition to 'Linux swap'
Command (? for help): p # 展示分区
...
Number Start (sector) End (sector) Size Code Name
...
3 12584960 16779263 2.0 GiB 8200 Linux swap
Command (? for help): w
...
Do you want to proceed? (Y/N): y
...
[root@chenshiren ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
....
└─nvme0n2p3 259:10 0 2G 0 part # 这个是我们刚刚创建的swap分区
第二步:格式化
[root@chenshiren ~]# mkswap /dev/nvme0n2p3
正在设置交换空间版本 1,大小 = 2 GiB (2147479552 个字节)
无标签,UUID=2d513817-45fa-4bc0-8cac-4b9587f7f5e3
[root@chenshiren ~]# blkid /dev/nvme0n2p3
/dev/nvme0n2p3: UUID="2d513817-45fa-4bc0-8cac-4b9587f7f5e3" TYPE="swap" PARTLABEL="Linux swap" PARTUUID="8c4bc053-fa3e-4a66-9d3b-df5c9df58e38"
# 确定格式化成功,且blkid可以识别到这个设备
第三步:观察和使用
[root@chenshiren ~]# free -h
total used free shared buff/cache available
Mem: 3.8Gi 949Mi 109Mi 15Mi 3.0Gi 2.9Gi
Swap: 2.0Gi 0.0Ki 2.0Gi
# total:物理内存总量
# used:已使用的物理内存量
# free:空闲物理内存量
# shared:被多个进程共享的内存量
# buffers:缓存的内存量
# cache:缓存的文件系统的内存量
# available:可用的物理内存量
# Swap:交换空间总量、已使用的交换空间量、空闲交换空间量
[root@chenshiren ~]# swapon /dev/nvme0n2p3
[root@chenshiren ~]# free -h
total used free shared buff/cache available
Mem: 3.8Gi 950Mi 108Mi 15Mi 3.0Gi 2.9Gi
Swap: 4.0Gi 0.0Ki 4.0Gi # 这里swap容量增加了
[root@chenshiren ~]# swapon -s
Filename Type Size Used Priority
/dev/nvme0n1p4 partition 2066428 256 -2
/dev/nvme0n2p3 partition 2097148 0 -3
# Filename:交换分区的文件名或设备路径
# Type:交换分区的类型
# Size:交换分区的大小,以字节为单位
# Used:交换分区当前已使用的空间,以字节为单位
# Priority:交换分区的优先级,较低的数字表示较高的优先级
使用swapoff关闭swap file,并设置自动启用
[root@chenshiren ~]# nano /etc/fstab
# 添加如下行信息
/dev/nvme0n2p3 swap swap defaults 0 0
[root@chenshiren ~]# swapoff /dev/nvme0n2p3 # 关闭swap
[root@chenshiren ~]# free -h # 查看
total used free shared buff/cache available
Mem: 3.8Gi 937Mi 166Mi 15Mi 3.0Gi 2.9Gi
Swap: 2.0Gi 0.0Ki 2.0Gi
# 重启自动挂载
[root@chenshiren ~]# reboot
[root@chenshiren ~]# free -h
total used free shared buff/cache available
Mem: 3.8Gi 960Mi 2.7Gi 15Mi 375Mi 2.9Gi
Swap: 4.0Gi 0B 4.0Gi
使用文件创建内存交换文件
第一步:使用dd命令在/tmp下面新增一个500MB的文件
[root@chenshiren ~]# dd if=/dev/zero of=/tmp/swap bs=1M count=500
记录了500+0 的读入
记录了500+0 的写出
524288000字节(524 MB,500 MiB)已复制,0.257303 s,2.0 GB/s
[root@chenshiren ~]# ll -h /tmp/swap
-rw-r--r--. 1 root root 500M 3月 6 10:56 /tmp/swap
第二步:使用mkswap将/tmp/swap这个文件格式为swap
[root@chenshiren ~]# mkswap /tmp/swap
mkswap: /tmp/swap: insecure permissions 0644, fix with: chmod 0600 /tmp/swap
正在设置交换空间版本 1,大小 = 500 MiB (524283904 个字节)
无标签,UUID=e617afb4-d7b7-4c5b-9976-d0438082438b
第三步:使用swapon将/tmp/swap启动
[root@chenshiren ~]# swapon /tmp/swap
[root@chenshiren ~]# swapon -s
Filename Type Size Used Priority
/dev/nvme0n1p4 partition 2066428 0 -2
/dev/nvme0n2p3 partition 2097148 0 -3
/tmp/swap file 511996 0 -4
[root@chenshiren ~]# free -h
total used free shared buff/cache available
Mem: 3.8Gi 932Mi 2.3Gi 15Mi 877Mi 2.9Gi
Swap: 4.5Gi 0B 4.5Gi
第四步:使用swapoff关闭 swap file,并设置自动启用
[root@chenshiren ~]# swapoff /tmp/swap
[root@chenshiren ~]# swapon -s
Filename Type Size Used Priority
/dev/nvme0n1p4 partition 2066428 0 -2
/dev/nvme0n2p3 partition 2097148 0 -3
[root@chenshiren ~]# nano /etc/fstab
/tmp/swap swap swap defaults 0 0
[root@chenshiren ~]# swapon -a
# swapon -a是一个用于激活(启用)所有已定义的交换分区的命令
# 当您执行swapon -a命令时,系统将扫描系统配置文件(例如/etc/fstab)
# 中定义的所有交换分区,并将它们逐个启用
[root@chenshiren ~]# swapon -s
Filename Type Size Used Priority
/dev/nvme0n1p4 partition 2066428 0 -2
/dev/nvme0n2p3 partition 2097148 0 -3
/tmp/swap file 511996 0 -4
文件系统的特殊观察与操作
磁盘空间浪费问题
我们在前面的 ext2 数据区块一个区块只能放置一个文件,因此太多小文件将会浪费非常多的磁盘容量。但你有没有注意到,整个文件系统中的超级区块、inode 对照表与其他中介数据等其实都会浪费磁盘容量。所以当我们在 /dev/nvme0n2p1、/dev/nvme0n2p2 建立 xfs 或 ext4 文件系统时,一挂载就立刻有很多容量被使用。
另外,当你使用【ls -l】去查询某个目录下的数据时,第一行会出现一个【总用量/total】的字样,那就是该目录下的所有数据所好用的实际区块数量
# 使用dd创建4个不一样大小的文件分别是
# test1 2k test2 3k test3 4k test4 5k
# 分别看看占用多少内存
[root@chenshiren ~]# dd if=/dev/zero of=/root/test1 bs=1K count=2
记录了2+0 的读入
记录了2+0 的写出
2048字节(2.0 kB,2.0 KiB)已复制,0.000120091 s,17.1 MB/s
[root@chenshiren ~]# dd if=/dev/zero of=/root/test2 bs=1K count=3
记录了3+0 的读入
记录了3+0 的写出
3072字节(3.1 kB,3.0 KiB)已复制,0.000108499 s,28.3 MB/s
[root@chenshiren ~]# dd if=/dev/zero of=/root/test3 bs=1K count=4
记录了4+0 的读入
记录了4+0 的写出
4096字节(4.1 kB,4.0 KiB)已复制,0.00011416 s,35.9 MB/s
[root@chenshiren ~]# dd if=/dev/zero of=/root/test4 bs=1K count=5
记录了5+0 的读入
记录了5+0 的写出
5120字节(5.1 kB,5.0 KiB)已复制,0.000129199 s,39.6 MB/s
[root@chenshiren ~]# ll -sh
# -s:表示显示文件或目录的大小
总用量 24K
4.0K -rw----r--. 1 root root 1.5K 2月 26 23:58 anaconda-ks.cfg
4.0K -rw-r--r--. 1 root root 2.0K 3月 6 11:09 test1
4.0K -rw-r--r--. 1 root root 3.0K 3月 6 11:09 test2
4.0K -rw-r--r--. 1 root root 4.0K 3月 6 11:09 test3
8.0K -rw-r--r--. 1 root root 5.0K 3月 6 11:10 test4
# 可以看到每个文件使用掉的区块的容量
# test1只有2k 不过却占用了整个数据区块(4K),test4只有5K却占用了2个数据区块
# 浪费了很多容量
Windows也可以看到浪费的现象

可以看到这个快捷方式实际大小是 722字节,但是占用了4KB空间















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









