






基础概念
- Host : cpu 和 ram
- Device : gpu
主机发送数据和指令给device, device计算完之后将计算结果发送给Host。
1、要注意自己此时处理的数据是位于cpu还是位于device。
2、数据的传输是通过CPU和GPU上的RAM进行的,数据的复制需要时间,常常会约束性能,要尽可能的减少数据的复制,在GPU上完成该有的计算之后,再将数据复制回CPU。
import cupy as cp
import numpy as np
array_cpu = np.random.randint(0, 255, size=(2000, 2000))
print(array_cpu)
print(array_cpu.nbytes) # 32000000
array_gpu = cp.asarray(array_cpu)
print(type(array_gpu), array_gpu.nbytes) # <class 'cupy._core.core.ndarray'> 32000000
from scipy import fft
print(fft.fftn(array_cpu).shape)
# when data in device need scipy, use the reimplement of the scipy
from cupyx.scipy import fft as fft_gpu
print(fft_gpu.fftn(array_gpu))
print(fft_gpu.fftn(array_gpu).shape) # (2000, 2000)
cupy库和numpy库类似。
在对数据进行操作之前要知道数据所处的位置。
scipy库的函数只能对host上面的数据进行操作,如果要对gpu上的数据进行处理,要导入重新实现的scipy库的函数。
组织形式
- grid 由 Block组成,而每个block又由thread组成, 每个核在一个或者多个thread上进行操作。
- 每一个Block中的thread共享内存

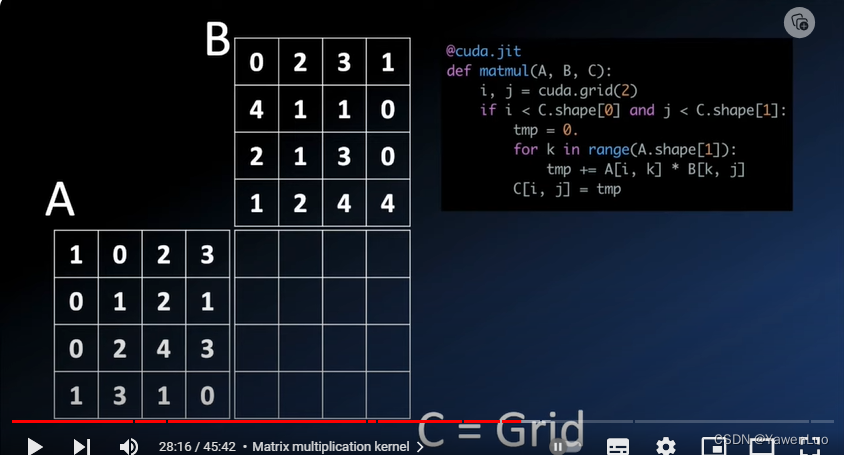
numba库
如果需要做一些循环,且该步骤并不适合使用cupy处理,可以考虑numba库来做循环。
比如对A中的元素逐个加1,传统的方式是进行循环+1.但是也可以采用numba库加速。
1、首先要检查thread是否在范围内,不要尝试访问不存在的元素。
2、核操作没有也不能有返回值, 因此该操作只能对每个位置处的元素进行原位置替换。
















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









