







前言
神经网络的概念本人之前已经写过适合小白看的博客,把链接也放在了这里。之所以会有卷积概念的提出,那他一定是在某个方面问题的解决比之前简单的神经网络更有优势,就像达尔文说的那样:“物竞天择,适者生存。”
卷积神经网络优势所在:专门处理具有类似网状结构的数据,例如序列数据(可以认为是是在时间轴上有规律地采样形成的一维网格)和图像数据(可以看作是二维的像素网格)……
卷积神经网络在于把万千个数据通过一系列操作使数据能够在反应问题的本质上进行了变形,使得用较少的数据来反应事物的特征,在一定程度上大大减少了数据的计算量
那CNN究竟能做什么呢???举个具体的图像识别栗子就是,我们拿到一张图,例如:
通过CNN的特征识别,我们就能知道图片里面有一个人,而不是牛马。
卷积神经网络
在这里还是先把卷积神经网络的主要组成列一下,让大家有个大局观:
(1) 卷积层
…… [1]卷积计算
……[2]非线性激活
(2)池化层
(3)全连接层
(4)训练与优化
(1)卷积的概念
卷积引自高数里的卷积运算,符号为
∗
*
∗,另外卷积也叫做滤波(filter),卷积是一种积分运算,为了得到更为光滑的数据,实现一种对信息处理的功能。
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
这里涉及到了光滑,那么何为光滑数据呢?举个栗子吧。比如信号强度抖动的太厉害,比如视频流中的bbox抖动的太厉害,比如光谱信号抖动的太厉害等等,这些数据就不具有光滑或者说平滑的特征,这时候就需要一些简单平滑处理。
【1】 卷积计算(卷积层)
本着“白话通篇”的原则,本人就自己看过的几篇博客了解到,还是图像来得比较真切可感。
从简单的例子讲起,
比如,我们要训练一个最简单的CNN,用来识别一张图片里的字母是X还是O。

人是智能的,可是计算机最不在行的就是人们一眼就能做的事情,那我们要告诉他这是一张字母为X的图像,也就是给图像加lable,lable=X。
但是并不是所有的X都长得这么标准,这和每个人的书写习惯有关,那么我们想要计算机也认识这样的X这么办呢???我们能不能取它关键的几个部位来当做判断标准呢?答案是肯定的,这也是CNN为什么是局部感受野。取得这部分也叫作特征(feature)或者卷积核,

我们应当了解到的图像在计算机里的存储是以像素值的方式存储的,也就是说,从计算机眼里看去,X的图像长这样:

如果我们严格按照逐个像素值去比较,那显然是不现实的,也是不可能的,像素值太多的时候,效率很低,结果不对,这样未免显得我们人工智能太笨拙了。
卷积核的选取
卷积核的选取自接影响着训练出的模型的识别能力强弱,这点不难理解。卷积核的选取一般遵循着“大同一致”什么意思呢?就是一个事物普遍具有的特征块,就像是人们都有鼻子,眼睛,嘴巴一样,X
也具有一定的模块是想通的。
那接下来我们就从标准的X图中提取出三个特征(feature)



说了那么多,终于讲到卷积计算了,之前提过,卷积是一种数学运算,在图像里边就是像素值对应位置的乘积。先放张动图给大家直观理解一下:
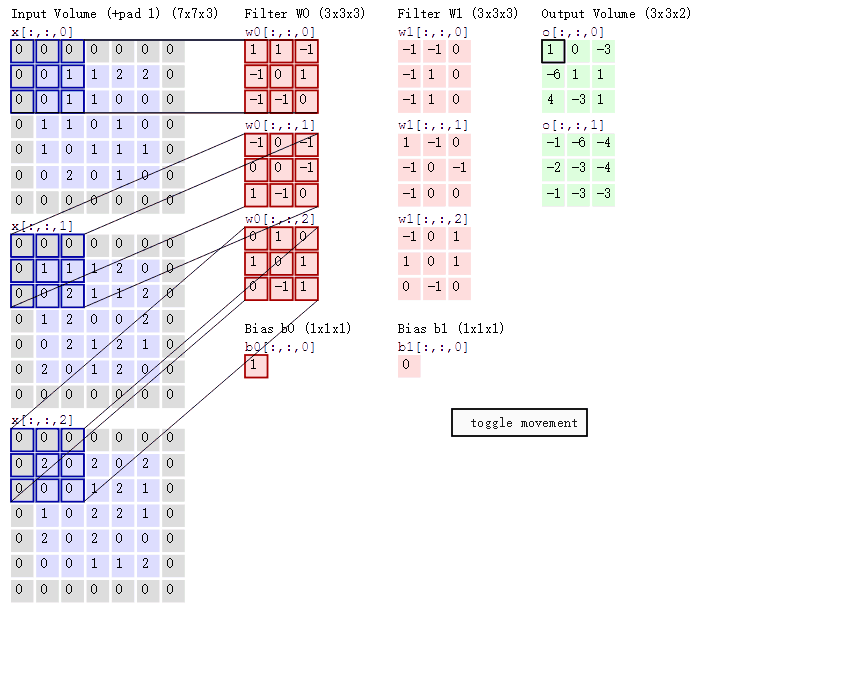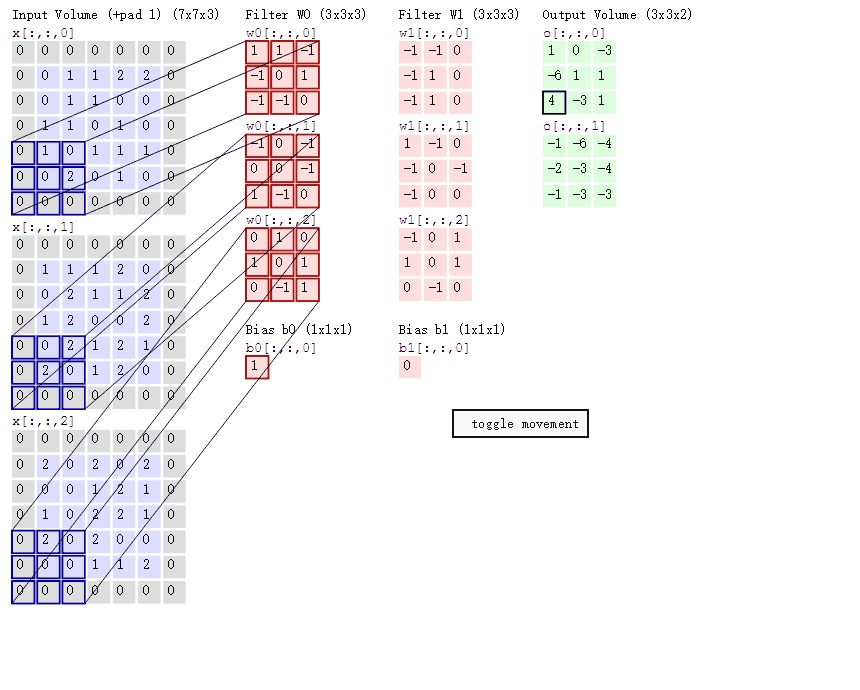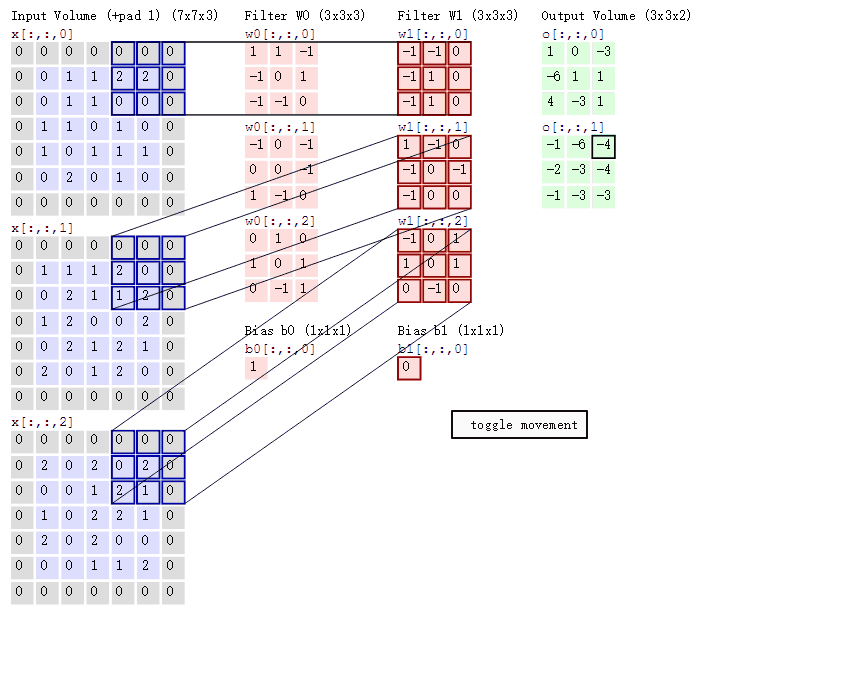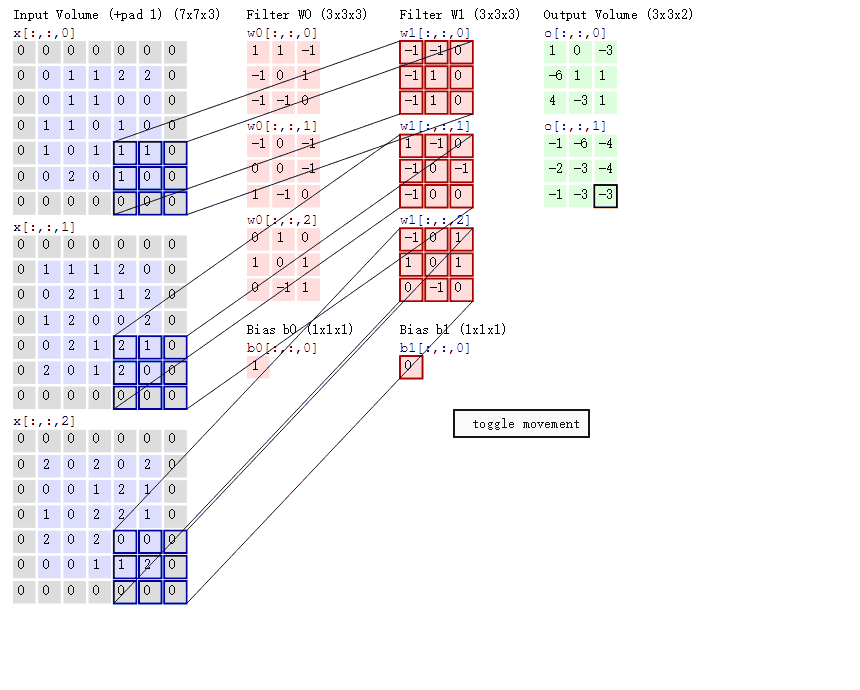
上图引自博客 CNN笔记:通俗理解卷积神经网络
注意
#(7x7x3)最后的“3”的含义是:三个RGB通道,基本色,如果是灰度图像其值就会是1。
**1,**原图边缘数值为补的0值,是为了更好的利用边缘数据,不浪费数据。
2, 滤波 的感觉在这里也得到了体现,由原来的77的矩阵通过“滤波”变成了一张33的矩阵。
3, 不同的 featuer 之间的卷积是相加的结果,比如第一次的作用(WO)计算遵循着之前我们学的神经网络的知识,类似y=w*x+b。(W0偏置b取1,W1取0)

4, 移动的步长,这关系着卷积的快慢,通过上面的动图不难看出,上面的计算是以步长 stride=2来移动的,当然根据需要我们也可以选取步长为1.
5, Filter 为其权重矩阵,权重简单点理解就是它这个位置的像素值对整体图案的影响大小。
【2】非线性激活
非线性激活函数:Relu函数 f(x)=max(0,x)
为什么要这么做呢?我们知道卷积后产生的特征图中的值(卷积过程中也可以加以求均值的操作),越靠近1表示与该特征越关联,越靠近-1表示越不关联,而我们进行特征提取时,为了使得数据更少,操作更方便,就直接舍弃掉那些不相关联的数据。
(2)池化层(pooling)
卷积操作后,我们得到了一张张有着不同值的卷积值矩阵,尽管数据量比原图少了很多,但还是过于庞大(比较深度学习动不动就几十万张训练图片),因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量。
【1】最大池化(Max Pooling)
……取池化尺寸内的最大值作为结果值
【2】平均池化(Average Pooling)
……取池化尺寸内的平均值最为结果值
以最大池化为例:

因为最大池化保留了每一个小块内的最大值,所以它相当于保留了这一块最佳匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一像素匹配的不聪明做法。
(3)全连接层
全连接层要做的事是把我们得到的池化后的矩阵与我们最终的目的建立对应关系,就像上面的栗子,我们最终的目的是判断得到的图是x还是o,那就要借助全连接层常用的softmax函数来作用。具体为将得到的特征图(就是经过前两个层,实际操作中不止两层)通过函数的作用,输出其概率值。
softmax函数:y=exp(x)

经过softmax函数的作用,一般我们就能根据概率值的大小来断定其类别。
由于这里的类别就两类,我们不妨把特征图变成一维的来研究,比如这样(这是三个特征图的例子):

由于这个栗子中只有两类,且取X图像为基,所以运算后的结果是图像X的概率总值
即:
P
(
X
)
=
(
1
+
0.55
+
0.55
+
1
+
1
+
0.55
+
0.55
+
0.55
+
0.55
+
1
+
1
+
0.55
)
/
12
=
0.7375
P(X)=(1+0.55+0.55+1+1+0.55+0.55+0.55+0.55+1+1+0.55)/12=0.7375
P(X)=(1+0.55+0.55+1+1+0.55+0.55+0.55+0.55+1+1+0.55)/12=0.7375
是图像O的概率是:
P
(
O
)
=
1
−
P
(
X
)
=
0.2625
P(O)=1-P(X)=0.2625
P(O)=1−P(X)=0.2625
综上该图像为X图像。
(4)训练与优化
前面只是介绍了一种思路,也可以说是一个模板,不过依然可以看出模型的关键所在,即卷积核的选取,也就是关于模型的训练与优化。
仿照以往构造损失函数的方法,结合梯度下降的趋近方法来达到优化的目的。
一种简单定义误差error的计算公式为 :
e
r
r
o
r
=
(
r
e
s
u
l
t
−
l
a
b
l
e
)
2
error=(result-lable)^{2}
error=(result−lable)2
用这种方法来改变卷积核里的参数W使得误差最小。
(((
多说一句,本篇博客是结合网上多篇博客学习给自己总结的,当然也希望志同道合的朋友能够一起学习,大牛们指正。
)))

















 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











