







12.卷积神经网络CNN
Network的一个架构 Convolutional Neural Network,专门被用在影像
注:在下面的讨论中,我们都假设我们的模型输入的图片大小固定。

模型的输入是一个图片,模型的目标是分类,输入是一个向量,向量的长度就决定了你现在的模型可以辨识出多少不同种类的东西。
接下来的问题是怎么把一个图像当做一个模型的输入呢?
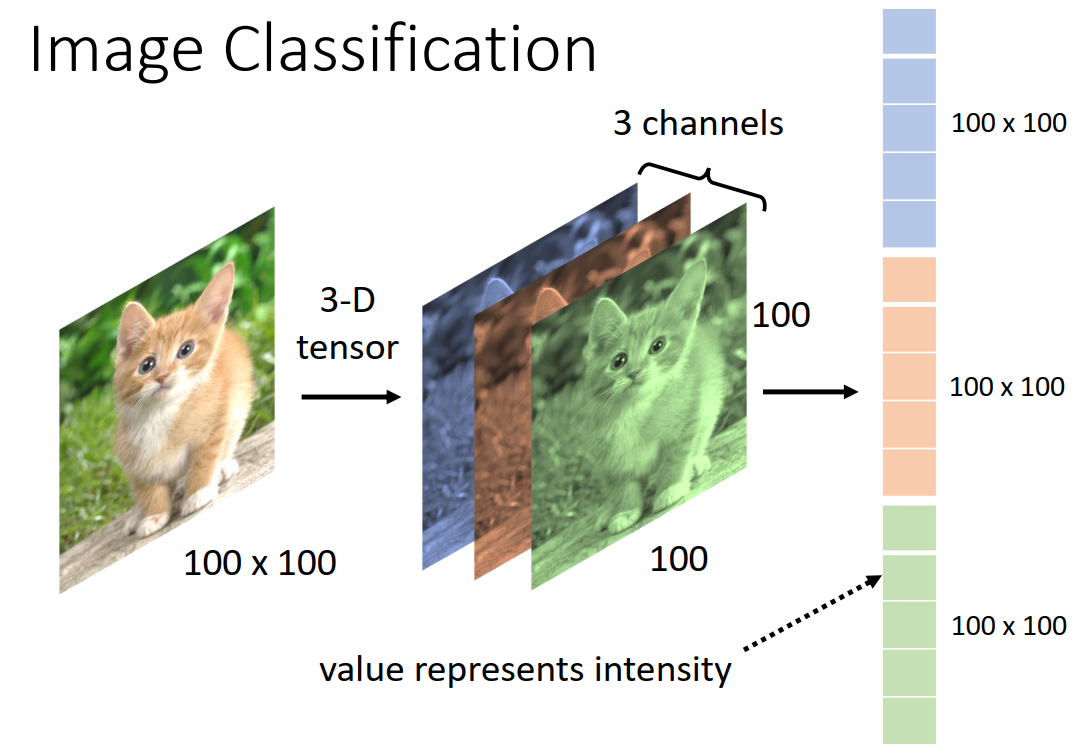
对电脑来说一张图片是一个三维的Tensor(维度大于2的矩阵就是Tensor)
我们只要把图片变成一个向量,我们就可以把他当做是network的输入。
每一个neuron 它跟输入的向量的每一个数值都会有一个weight,所有如果输入的向量长度是100 x 100 x 3,有1000个 neuron,那我们现在第一层的 weight 就有 3 x 107 个。
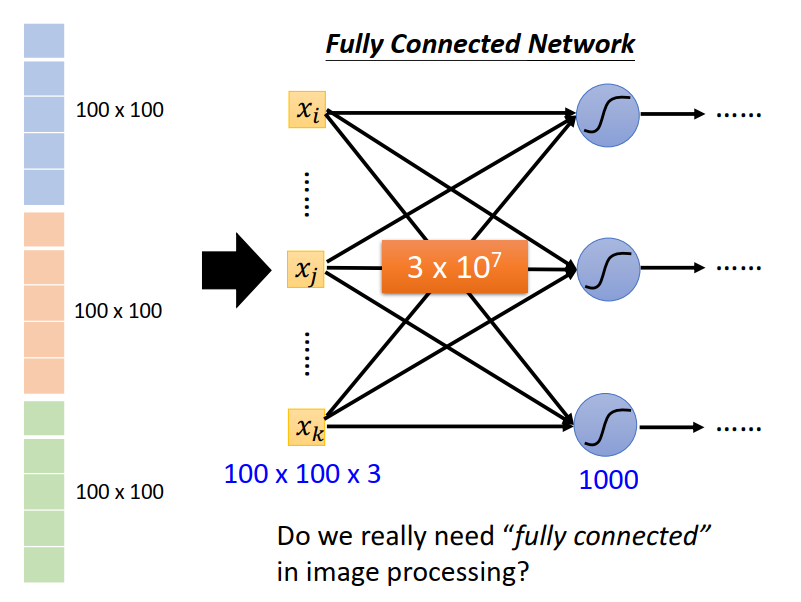
随着参数的增加,我们可以增加模型的弹性,增加它的能力,但是我们也增加了Overfitting的风险。
如何避免使用这么多的参数?
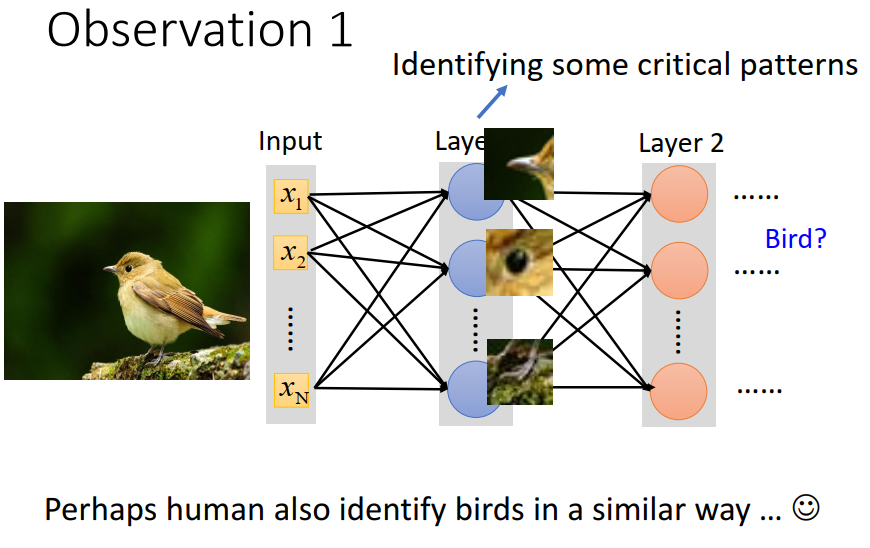
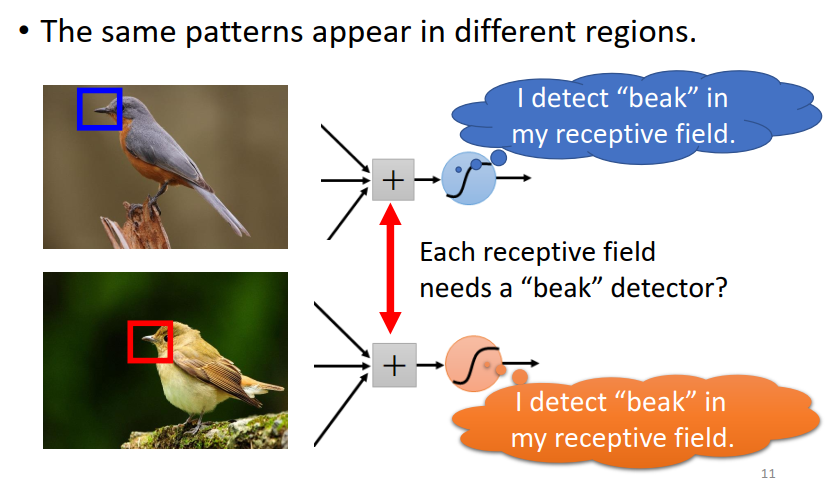
对一个影像辨识的神经网络里面的神经而言,它要做的急速侦测现在这张图片里面有没有出现一些特别重要的 pattern。而这些 pattern 是代表了某种物件的。
简化1 每个neuron 只需要看图片的一小部分即可。
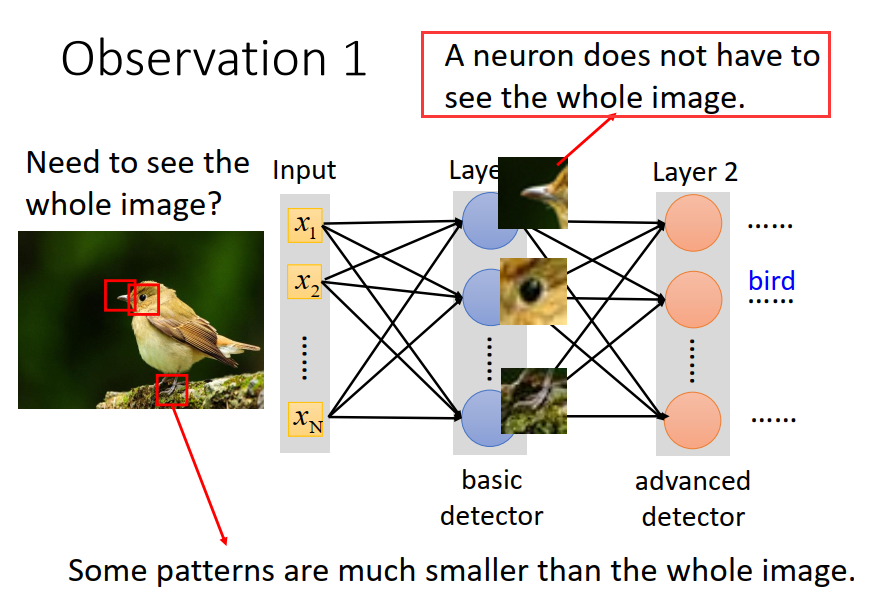
在CNN中设定一个Receptive field 区域。每个neuron只需要关心自己receptive field里面发生的事情就好了。
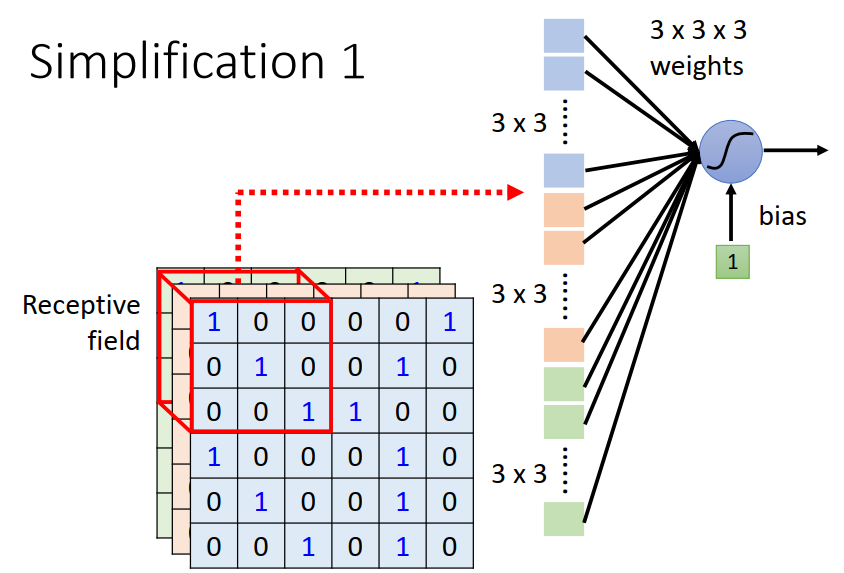
注:Receptive field 彼此之间可以重叠,两个neuron看到一个Receptive field也是可以的。
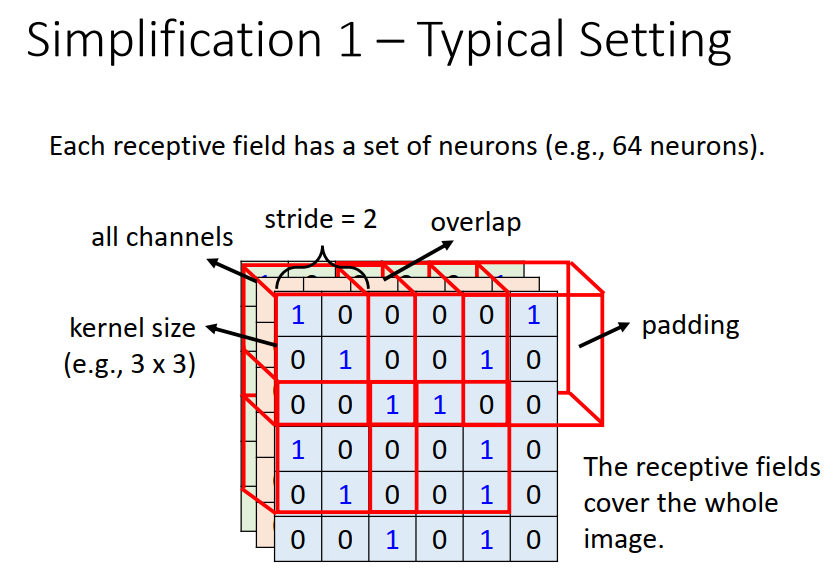
把你在最左上角的这个Receptive field往右移一点,然后制造一个新的范围。
这个移动的量叫做Stride(Hyper Parameter),往往设为1 或 2(使相邻的区域有高度的重合,防止错过pattern) 。
超出范围后,需要padding(填充信息)。
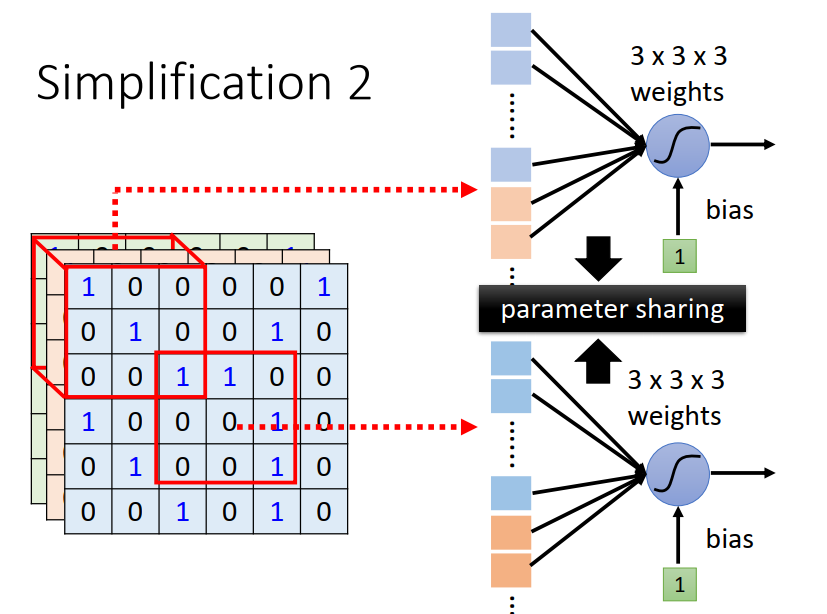
简化2:共享参数
总结:
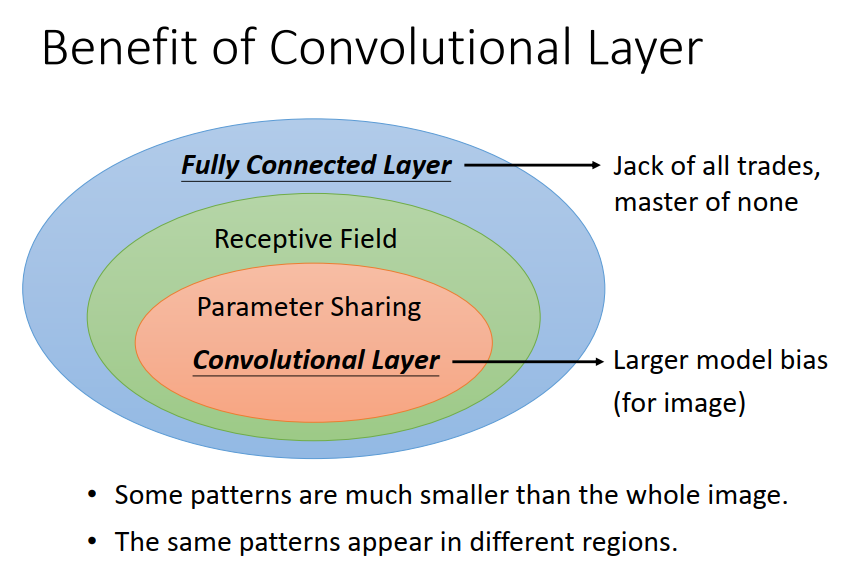
蓝色:Fully Connected 的Network 弹性最大
绿色:我们说不需要看整张图片,只需要看一小部分,所以有了Receptive Field 的概念,弹性变小。
橙色:参数共享,又更进一步限制了Network的弹性。
Receptive Field + Parameter Sharing 就是Convolutional Layer。
有用 Convolutional Layer 的 network就叫Convolutional Neural Network。
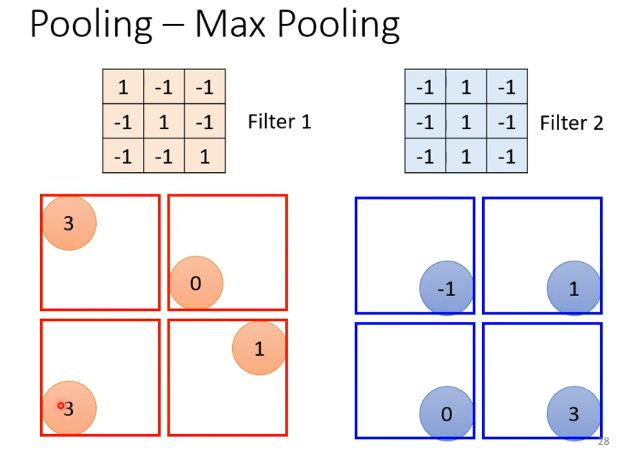
简化3: pooling
pooling能有效减少运算量。
(一些CNN中可能不会用到pooling)

一个经典的影像辨识的network例子
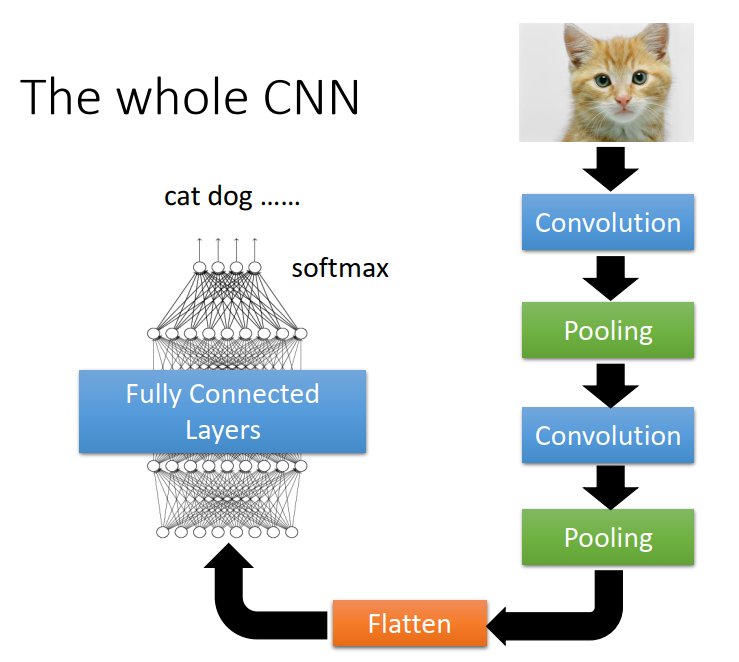
Flatten:把这个影像里面本来排成矩阵的样子拉直
















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











