







2021年电影市场票房波动的模型分析
Q
-
电影票房预测建模的背景
随着人们文化消费需求的增加,影院和银幕的数量不断增加,我国的电影产业继续呈现出繁荣景象。2019年,全国电影票房642.66亿元。电影票房不仅直接反映了电影为投资公司创造的经济价值,也从侧面反映了电影的艺术品质和经营策略。它是衡量一部电影成功与否的重要指标。这自然反映了电影作品的市场需求和投资吸引力的程度。。如果能够提前预测电影产品在市场上的接受度和盈利能力,将对电影产业链各个环节的决策产生巨大影响。因此,准确预测电影票房无疑对风险控制和决策具有重要的现实意义。
影响电影票房的因素很多,比如电影本身的质量、上映时间、广告、社会环境、上映电影院的数量,甚至上映期间的天气。根据预测阶段的不同,票房预测分为前期预测和后期预测,即电影发行前后的票房预测。根据预测阶段的不同,票房预测分为前期预测和后期预测。对于电影的预预测,目前的研究成果包括:基于网络文本的电影类型与电影票房关系研究;基于明星效应、演员性别和导演级别,研究了等级对票房的影响;基于神经网络算法研究电影发行日期、时间、季节等因素与票房的关系;训练多层感知器MLP神经网络,对电影质量、人气等变量进行预发布数据处理,并根据预期收入对电影进行分类。电影后期票房预测采用反馈神经网络电影票房预测模型;票房预测考虑了导演、演员和时间表等因素;研究观众在社交网络、网络信息传播和网络搜索中的口碑传播对电影票房的积极影响。 -
电影在线舆情评分对票房的影响
随着我国互联网技术的不断发展,互联网已经成为电影营销的核心宣传媒介。目前,豆瓣、猫眼等电影评价平台大多不实行实名制,参与者具有多样性和复杂性。再加上互联网本身的特点,电影网络评价行为具有很强的匿名性和隐蔽性。这也使得雇佣“互联网海军”来不恰当地评估电影、购买票房和锁定电影业的情况变得罕见。首先,网络的隐蔽性往往使被害人难以准确识别“网络海军”。其次,我国现行法律在识别和规范“网络水军”对电影的不当评价方面还存在不完善之处。基于此,如何识别和管理网络电影收视率已成为我国电影产业发展中亟待解决的问题。 -
突发事件对电影票房的影响
电影是一种公共娱乐,道德和法律形式的突发事件对电影的票房产生了巨大的影响。2020年新冠病毒的突然爆发几乎摧毁了公众聚集的电影市场;如何运用模型分析各种突发事件对电影票房的影响显然是非常重要的。
建模中需要解决的主要问题有:
-
电影票房早期预测的核心是选择有效的预测特征。影响电影票房的因素是复杂的,衡量方法也各不相同。功能包括:电影持续时间、演员、导演、电影类型、电影格式(2D、3D、IMAX)、电影是否续集、发行日期、制作公司和发行公司等。根据电影分类的特点,考虑电影分类、电影类型、导演和其他分类特征、导演等级等分类特征,对所提供的数据集中的电影进行聚类和分类,并验证分类的有效性。
-
常用的票房预测模型包括多元回归、神经网络等,一些学者通过研究观众口碑传播、网络信息传播和社交网络中的网络搜索来预测票房(见参考文献),并建立对电影票房有正面影响的电影票房预测模型,对于电影市场的票房,根据提供的数据给出分类模型(标题1的结果),并提前给出各类别的预计票房预测和整体票房预测。
-
从豆瓣、猫眼等平台收集电影在线舆情评价数据,建立识别在线舆情正负分的算法(标准化为[-1,1]);建立模型提取主题词、主题分类等重要指标;建立模型分析网络舆情与票房的相关性及对票房的影响程度;根据问题和现状,设计思路和具体方法,确定电影评分中的水军。该方法需要具有逻辑上的自一致性和可行性。
-
为应对新冠病毒的突然爆发,国家关于电影院流行病预防和控制的指导方针开放:考虑到流行病对模型的影响,每个场馆的入场率不得超过30%、50%、75%等,并分析其对电影票房的影响、现实影响和未来预测。利用提供的数据,该模型分析了在疫情稳定后,不同观众需求(30%、50%、75%)对电影票房预测的影响。
参考:
[1] 韩忠明,原碧鸿,陈炎,等.一个有效的基于GBRT的早期电影票房预测模型[J] 。计算机应用研究, 2018
[2]郑坚,周尚波.基于神经网络的电影票房预测建模[J] 。计算机应用,2014,034(003):742-748.
[3]王炼, 贾建民.基于网络搜索的票房预测模型——来自中国电影市场的证据[J] 。系统工程理论与实践, 2014
[4]周杰、梁佳雯、何加豪. 居民对国产科幻电影的消费舆情分析及票房预测——以《流浪地球》为例[J] 。中国集体经济, 2020年,第654(34)号:146-148。
[5]叶芳. 基于数据挖掘的电影水军识别技术与应用[D] 。北京大学, 2014
数据说明:
https://piaofang.maoyan.com/dashboard
A
Q1 系统聚类法 斯皮尔曼相关系数
- 系统聚类法
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。
算法流程如下图所示:

我们用欧几里得距离来计算两类数据点间的距离,用类平均法来衡量类与类之间的距离,并用SPSS软件对15部电影的票房数据进行聚类分析。
15部电影的票房聚合系数如下表所示:

根据聚合系数画出聚合系数折线图,如下图所示:
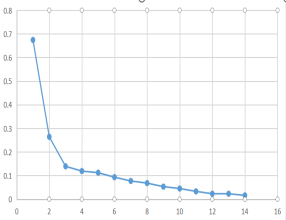


根据聚类谱系图,我们对近期正在上映的15部电影进行分类,结果如下表所示:

- 利用斯皮尔曼相关系数检验分类的有效性

Q2 python-crawler 灰色神经网络预测 时间序列
- GNNM模型
针对小样本数据神经网络预测。

我们可用下图来表示上述步骤:

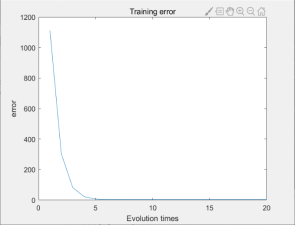
训练误差图如下所示:
4.1三类电影的预计票房预测结果如图所示:
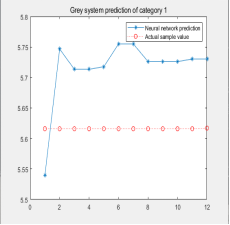
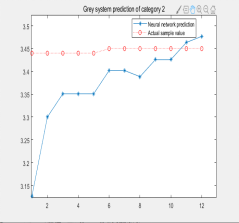
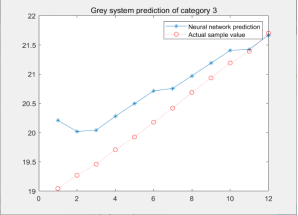
实际上变数巨大,每一次模拟的结果大相径庭,GNNM具有过强的随机性,并非稳定的预测模型。
matlab实现GNNM:
% Prediction algorithm based on Grey Neural Network
%Take the category 3 as an example
clear all
clc
X =[0.14431 0.297 0.007 0.266
0.14435 0.297 0.007 0.266
0.14439 0.297 0.007 0.266
0.14444 0.297 0.007 0.266
0.14453 0.297 0.007 0.266
0.14469 0.298 0.007 0.266
0.14482 0.298 0.007 0.266
0.14497 0.297 0.007 0.266
0.1451 0.297 0.007 0.266
0.14525 0.296 0.007 0.266
0.14548 0.295 0.007 0.266
0.14591 0.297 0.008 0.265
0.14621 0.297 0.008 0.266
0.14659 0.296 0.008 0.266
0.14696 0.294 0.008 0.266
0.14741 0.293 0.008 0.266
0.14829 0.295 0.008 0.266
0.1494 0.299 0.008 0.266
0.15024 0.299 0.009 0.266
0.15093 0.299 0.009 0.266
0.15149 0.297 0.009 0.266
0.15212 0.295 0.009 0.266
0.15271 0.293 0.009 0.266
0.15367 0.295 0.010 0.266
0.15443 0.295 0.010 0.266
0.15521 0.294 0.010 0.266
0.15593 0.293 0.010 0.266
0.15691 0.293 0.011 0.266
0.15699 0.292 0.011 0.266
0.15782 0.292 0.011 0.266
0.15814 0.288 0.011 0.266
0.15884 0.286 0.012 0.266
0.1595 0.284 0.012 0.266
0.16038 0.281 0.012 0.266
0.16128 0.278 0.012 0.266
0.16298 0.281 0.013 0.266
0.1648 0.283 0.013 0.266
0.16666 0.284 0.014 0.266
0.16801 0.284 0.014 0.266
0.16948 0.284 0.015 0.266
0.17096 0.284 0.015 0.266
0.17285 0.287 0.016 0.266
0.17467 0.289 0.016 0.266
0.17677 0.291 0.017 0.266
0.17834 0.292 0.017 0.266
0.18023 0.294 0.018 0.266
0.18194 0.295 0.019 0.266
0.18416 0.298 0.019 0.266
0.18613 0.300 0.020 0.266
0.18845 0.302 0.021 0.266
0.19045 0.304 0.021 0.266
0.19271 0.306 0.022 0.266
0.19461 0.307 0.022 0.266
0.19709 0.310 0.023 0.266
0.19926 0.312 0.024 0.266
0.20178 0.314 0.025 0.266
0.20419 0.316 0.025 0.266
0.20687 0.318 0.026 0.266
0.20936 0.320 0.027 0.266
0.21191 0.322 0.028 0.266
0.21392 0.323 0.028 0.266
0.21702 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
0.000 0.326 0.029 0.266
];
[xa,bb]=size(X);
aa=xa-10;
[xn,m]=size(X);
n=xn-10;
for i=1:n
y(i,1)=sum(X(1:i,1));
y(i,2)=sum(X(1:i,2));
y(i,3)=sum(X(1:i,3));
y(i,4)=sum(X(1:i,4));
end
a=0.3+rand(1)/4;
b1=0.3+rand(1)/4;
b2=0.3+rand(1)/4;
b3=0.3+rand(1)/4;
u1=0.0015;
u2=0.0015;
u3=0.0015;
t=1;
w11=a;
w21=-y(1,1);
w22=2*b1/a;
w23=2*b2/a;
w24=2*b3/a;
w31=1+exp(-a*t);
w32=1+exp(-a*t);
w33=1+exp(-a*t);
w34=1+exp(-a*t);
theta=(1+exp(-a*t))*(b1*y(1,2)/a+b2*y(1,3)/a+b3*y(1,4)...
/a-y(1,1));
kk=1;
cc=50;
for j=1:20
E(j)=0;
for i=1:cc
t=i;
LB_b=1/(1+exp(-w11*t)); %LB
LC_c1=LB_b*w21; %LC
LC_c2=y(i,2)*LB_b*w22; %LC
LC_c3=y(i,3)*LB_b*w23; %LC
LC_c4=y(i,4)*LB_b*w24; %LC
LD_d=w31*LC_c1+w32*LC_c2+w33*LC_c3+w34*LC_c4; %LD
theta=(1+exp(-w11*t))*(w22*y(i,2)/2+w23*y(i,3)/2+w24*y(i,4)/2-y(1,1));
ym=LD_d-theta;
yc(i)=ym;
error=ym-y(i,1);
E(j)=E(j)+abs(error);
error1=error*(1+exp(-w11*t));
error2=error*(1+exp(-w11*t));
error3=error*(1+exp(-w11*t));
error4=error*(1+exp(-w11*t));
error7=(1/(1+exp(-w11*t)))*(1-1/(1+exp(-w11*t)))*(w21*error1+w22*error2+w23*error3+w24*error4);
w22=w22-u1*error2*LB_b;
w23=w23-u2*error3*LB_b;
w24=w24-u3*error4*LB_b;
w11=w11+a*t*error7;
end
end
figure(1)
plot(E)
title('Training error');
xlabel('Evolution times');
ylabel('error');
for i=(cc+1):aa
t=i;
LB_b=1/(1+exp(-w11*t)); %LB
LC_c1=LB_b*w21; %LC
LC_c2=y(i,2)*LB_b*w22; %LC
LC_c3=y(i,3)*LB_b*w23; %LC
LC_c4=y(i,4)*LB_b*w24; %LC
LD_d=w31*LC_c1+w32*LC_c2+w33*LC_c3+w34*LC_c4; %LD
theta=(1+exp(-w11*t))*(w22*y(i,2)/2+w23*y(i,3)/2+w24*y(i,4)/2-y(1,1));
ym=LD_d-theta;
yc(i)=ym;
end
yc=yc*1000;
y(:,1)=y(:,1)*100;
for j=aa:-1:2
ys(j)=(yc(j)-yc(j-1))/10;
end
figure(2)
plot(ys((cc+1):aa),'-*');
hold on
plot(X((cc+1):aa,1)*100,'r:o');
legend('Neural network prediction','Actual sample value')
title('Grey system prediction of category 3')
xderror=0;
for i=aa:-1:cc
xderror=xderror+abs(ys(i)-X(i,1))/yc(i);
end
xderror=xderror/(aa-cc)
python crawler:
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 猫眼票房:https://piaofang.maoyan.com/dashboard
import datetime
import os
import time
import requests
import re
import xlwt
import csv
import xlrd
from xlutils.copy import copy
global xls_file
xls_file = xlwt.Workbook()
class PF(object):
def __init__(self):
self.url = 'https://piaofang.maoyan.com/dashboard-ajax?orderType=0&uuid=173d6dd20a2c8-0559692f1032d2-393e5b09-1fa400-173d6dd20a2c8&riskLevel=71&optimusCode=10'
self.headers = {
"Referer": "https://piaofang.maoyan.com/dashboard",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
}
def main(self):
'''
主程序,打印最终结果
:return:
'''
flag=True
while True:
# 需在dos命令下运行此文件,才能清屏
os.system('cls')
result_json = self.get_parse()
if not result_json:
break
results = self.parse(result_json)
# 获取时间
calendar = result_json['calendar']['serverTimestamp']
t = calendar.split('.')[0].split('T')
t = t[0] + " " + (datetime.datetime.strptime(t[1], "%H:%M:%S") + datetime.timedelta(hours=8)).strftime(
"%H:%M:%S")
print("北京时间:", t)
x_line = '-' * 155
# 总票房
total_box = result_json['movieList']['data']['nationBoxInfo']['nationBoxSplitUnit']['num']
# 总票房单位
total_box_unit = result_json['movieList']['data']['nationBoxInfo']['nationBoxSplitUnit']['unit']
print(f"今日总票房: {total_box} {total_box_unit}", end=f'\n{x_line}\n')
# print("{:^10}\t{:^23}".format("企业ID", "企业名称"))
print('电影名称'.ljust(14), '综合票房'.ljust(11), '票房占比'.ljust(13), '场均上座率'.ljust(11), '场均人次'.ljust(11),
'排片场次'.ljust(12),
'排片占比'.ljust(12), '累积总票房'.ljust(11), '上映天数', sep='\t', end=f'\n{x_line}\n')
path='maoyan_data.xls'
origin_name="movie"
num=0
col=('电影名称','票房占比','场均上座率','场均人次','排片场次','排片占比','累积总票房','上映天数','北京时间')
for result in results:
num=num+1
temp='%d' %num
noname=origin_name+temp
print(noname)
if num==1 and flag==True:
workbook=xls_file
sheet=workbook.add_sheet(noname)
for i in range(0,9):
sheet.write(0,i,col[i])#列名
sheet.write(1, 0, result['movieName'][:10])
sheet.write(1, 1, result['boxRate'][:8])
sheet.write(1, 2, result['avgSeatView'][:8])
sheet.write(1, 3, result['avgShowView'][:8])
sheet.write(1, 4, result['showCount'][:8])
sheet.write(1, 5, result['showCountRate'][:8])
sheet.write(1, 6, result['sumBoxDesc'][:8])
sheet.write(1, 7, result['releaseInfo'][:8])
sheet.write(1, 8, t)
workbook.save(path)
flag=False
else:
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
print(len(sheets))
print("调试")
print(num)
if len(sheets)>=num:
worksheet = workbook.sheet_by_name(sheets[num-1]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(num-1) # 获取转化后工作簿中的第一个表格
new_worksheet.write(rows_old, 0, result['movieName'][:10])
new_worksheet.write(rows_old, 1, result['boxRate'][:8])
new_worksheet.write(rows_old, 2, result['avgSeatView'][:8])
new_worksheet.write(rows_old, 3, result['avgShowView'][:8])
new_worksheet.write(rows_old, 4, result['showCount'][:8])
new_worksheet.write(rows_old, 5, result['showCountRate'][:8])
new_worksheet.write(rows_old, 6, result['sumBoxDesc'][:8])
new_worksheet.write(rows_old, 7, result['releaseInfo'][:8])
new_worksheet.write(rows_old, 8, t)
new_workbook.save(path) # 保存工作簿
else:
rb = xlrd.open_workbook(path, formatting_info=True)
new_workbook = copy(rb)
new_worksheet = new_workbook.add_sheet(noname) # 在工作簿中新建一个表格
for i in range(0,9):
new_worksheet.write(0,i,col[i])#列名
new_worksheet.write(1, 0, result['movieName'][:10])
new_worksheet.write(1, 1, result['boxRate'][:8])
new_worksheet.write(1, 2, result['avgSeatView'][:8])
new_worksheet.write(1, 3, result['avgShowView'][:8])
new_worksheet.write(1, 4, result['showCount'][:8])
new_worksheet.write(1, 5, result['showCountRate'][:8])
new_worksheet.write(1, 6, result['sumBoxDesc'][:8])
new_worksheet.write(1, 7, result['releaseInfo'][:8])
new_worksheet.write(1, 8, t)
new_workbook.save(path) # 保存工作簿
)
time.sleep(600)
def get_parse(self):
'''
网页是否成功获取,频繁操作会有验证
:return:
'''
try:
response = requests.get(self.url, headers=self.headers)
if response.status_code == 200:
# print("success!")
return response.json()
except requests.ConnectionError as e:
print("ERROR:", e)
return None
def parse(self, result_json):
'''
获取数据
:return:
'''
if result_json:
movies = result_json['movieList']['data']['list']
# 场均上座率, 场均人次, 票房占比, 电影名称,
# 上映信息(上映天数), 排片场次, 排片占比, 综合票房,累积总票房
ticks = ['avgSeatView', 'avgShowView', 'boxRate', 'movieName',
'releaseInfo', 'showCount', 'showCountRate', 'boxSplitUnit', 'sumBoxDesc']
for movie in movies:
self.piaofang = {}
for tick in ticks:
# 数字和单位分开需要join
if tick == 'boxSplitUnit':
movie[tick] = ''.join([str(i) for i in movie[tick].values()])
# 多层字典嵌套
if tick == 'movieName' or tick == 'releaseInfo':
movie[tick] = movie['movieInfo'][tick]
if movie[tick] == '':
movie[tick] = '此项数据为空'
self.piaofang[tick] = str(movie[tick])
yield self.piaofang
if __name__ == '__main__':
pf = PF()
pf.main()
- 时间序列
我们收集了从10月11日至11月10日近一个月的日总票房并作出单日总票房的一阶差分时间序列图,发现这组数据具有明显的周期性波动(可以理解为人们通常在周末时间看电影),且这样的周期性波动随着时间的推移逐渐变小,因此我们考虑采用时间序列分解。
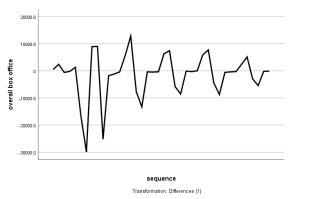
时间序列分析方法,主要用来解决具有随机性、季节性以及平稳性的时间序列问题的,它是由博克斯-詹金斯(BoxJenkins)发现的。对于平稳的时间序列,一般采用ARMA模型,我们的计算步骤如下:

(1)模型识别
我们利用SPSS专家建模器进行模型识别。SPSS专家建模器会自动查找每个相依序列的最佳拟合模型。适当时,使用差分和/或平方根或自然对数转换对模型变量进行转换,缺省情况下,专家建模器既考虑指数平滑法模型也考虑ARIMA模型。
(2)参数估计
通常采用极大似然估计法来估计出来的模型为ARIMA(0,0,1)模型。
(3)模型检验
模型对时间的拟合效果我们用平稳的R方来判断。模型检验既要对参数的估计值进行检验,又要对残差序列进行检验。从残差的ACF和PACF图形中可以看出,所有滞后阶数的自相关系数和偏自相关系数均和0没有显著的差异;另外,Ljung and Box 在1978年提出的Q检验能帮助我们检验残差是否为白噪声。从表中可以看出,对残差进行Q检验得到的p值为0.684,即我们无法拒绝原假设,认为残差就是白噪声序列,因此ARIMA(0,0,1)模型能很好地识别本题中的总票房数据。

 (4)模型预测
(4)模型预测
在95%的置信水平下,我们继续使用该模型对未来三天的总票房进行预测。

由图表可以看出,预测值总体来说是符合其变化规律及周期性的,且通过了残差的白噪声检验,具有一定的可信度。
Q3 情感分析
我们使用Python从豆瓣影评平台抓取电影007:NoTime to die的在线评估数据,并对这些评估数据进行预处理,步骤如下:
(1) 清除文本中的噪音,例如删除Web链接、空格等。
(2) 使用分词技术处理电影评论,统计词性、位置和出现频率。
(3) 删除文本中高频和无意义的词,如“嗯”、“啊”等。
(4) 分词后动词、名词、形容词和其他单词的词性标注。
- 构建倾向性计算算法识别在线舆情
(1)在线舆情评论分类
我们从预处理过后的评论中以情感识别为依据,筛选出带有用户主观性评价的文本。
(2)构建基于语义的情感词典
情感词典的构建在实际使用中,可将其归为4 类:通用情感词、程度副词、否定词、领域词。利用语义相似度计算方法,包括词向量与分词的处理,计算词语与基准情感情感词典。

(3)构建倾向性计算算法识别在线舆情
我们利用基于语义的情感词典来分析主观性评论语句的特殊结构及情感倾向,采用权值算法进行情感分类。积极情感我们赋正值,负面情感赋负值。同时给情感强度不同的情感词赋予不同权值,以便区分情感等级。最后我们进行加权求和,公式为:

基于深度学习的情感分类,首先
对语句进行分词、停用词、简繁转换等预处理,然后进行词向量编码,再利用LSTM网络进行特征提取,最后通过全连接层和softmax输出每个分类的概率,从而得到情感分类。
将所得加权计算结果标准化,若结果在[0,1]之间,则该在线舆情的评价是正面的,反之则是负面的舆情评价。
- 基于情感词典提取指标
由于电影评论复杂化、多样化,主题词等关键信息无法有效提取,因此我们建立情感词典模型,从中提取领域词、主题分类等重要指标,使其对影评文本分析更加高效。提取步骤为:
(1)使用TF-IDF算法确定重要指标
我们利用词频和反文档频率的权值来计算词的权重数值,权重数值越大,成为重要指标的概率越大,公式如下所示:

(2)词性
词语的词性也是它能否成为重要指标的关键。我们使用4.3.1中构建的基于语义的情感分析词典中的词语进行分析,借助微词云软件统计词性,制定了重要指标统计表格。

(3)重要指标的确定
根据上述两个特征来提取评论中的重要指标,计算公式如下:
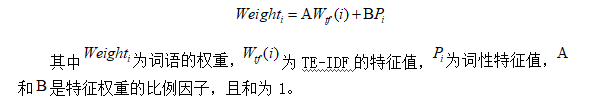

(4)word2dev词向量工具
2013年Google开源了word2vec工具,它可以进行词向量训练,加载已有模型进行增量训练,求两个词向量相似度,求与某个词接近的词语等等。我们在分词的基础上,使用word2dev处理词语,一方面解决了词语的编码问题,另一方面也解决了词的同义关系。
词向量可以通过使用大规模语料进行无监督学习训练得到,我们这里word2vec模型训练时采用skip-gram模型。skip-gram利用中心词来预测上下文,适合大规模训练语料,可以基于滑窗随机选择上下文词语。
Q4
- 无突发事件的总票房的预测
我们在中国电影数据信息网上搜集到了2019年第一周(01.07-01.13)至2019年第45周(11.18-11.24)的每周总票房数目以及每个影厅的平均人数。假设2019年第45周至2020年第4周我国没有爆发新冠病毒,则我们对其进行时间序列分析,分别预测出这两类数据。
利用SPSS软件中的专家建模器自动识别出最适合每周总票房数目以及每场平均人数的模型是ARIMA(0,0,1)模型,按照与第二题中相同的办法进行模型检验,其白噪声检验效果如下:
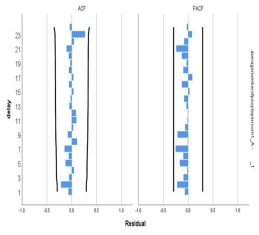
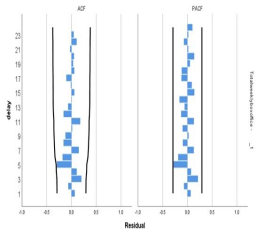

从残差的ACF和PACF图形中可以看出,所有滞后阶数的自相关系数和偏自相关系数均和0没有显著的差异;从表中可以看出,对残差进行Q检验得到的p值分别为0.37和0.967,即我们无法拒绝原假设,认为残差就是白噪声序列,因此ARIMA(0,0,1)模型能很好地识别本题中的每周总票房数据和每场平均人数。
接下来在95%的置信水平下,我们继续使用该模型对未来9周的每周总票房以及每场平均人数做预测,结果如下(具体数值见附录):


对比预测的数值和实际的数值进行误差分析,总体来说是符合其变化规律及周期性的,且通过了残差的白噪声检验,具有一定的可信度。
- 受突发事件影响的调整后的模型
为了有效应对新冠病毒的爆发,国家发布关于电影院流行病预防和控制的指导方针:每个场馆的入场率不得超过一定比率,分别考虑30%、50%、75%的情况。
从目前全国各院线配置来说,一个影厅的平均座位数为104。根据我们前面对每个影厅的平均人数的预测,可以按照疫情防控需要对影厅人数做出调整,并按照其与原人数的比例求出控制入场率后的总票房:

由此我们可以计算出控制入场率后的每周总票房,与控制入场率前的每周总票房对比如下:

结合图表信息,可以看出控制入场率对电影票房的影响是巨大的,且随着入场率的降低,票房损失逐渐增多。计算可得,当控制入场率分别为30%、50%、75%时,每周电影票房的损失为424507.4万、147354.8万和8510.381万,这也从侧面反映出疫情对我国经济发展的负面影响。
- 不同观众需求对电影票房的影响
猫眼研究院层曾对观影消费情绪的影响发起持续性调查,期望反映电影观众未来疫情结束后进影院观影的意愿,帮助行业更高效地做好复工准备。我们设置75%,50%,30%的三种不同的观众需求,来分析疫情稳定后观众需求对电影票房的影响。其中75%是解封初期,50%是缓和期,30%是稳定期。
此处,我们不妨设当观众需求为30%时就是4.4.1中无突发事件的电影票房的预测情况。
当观影需求达到75%、50%时,属于突发事件影响电影票房。我们用4.4.2中的模型对电影票房进行预测。

最后,我们可根据预测结果得出,观众的观影需求越高,电影票房也会相应增加。
大部分电影的上映短,数据量不足,所以选用了GNNM。然而GNNM的效果不尽人意,模型随机性太强,几次优秀的拟合都是基于多次的模拟得到的。
情感分析短时间内没法掌握与实操,语料库的建立也非一朝一夕的事,虽然了解了点皮毛,却也只是皮毛,无法使用。
在情感分析上耗费的时间过长,现在想来这种显然最终需要语文建模的部分大可以放弃搞明白,把更多的精力放在预测上。
















 2609
2609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









