










文章目录
- 前言
- 一、 欢迎来到Python的国度
- 二、玩转Python语法(一):面向过程
- 三、玩转Python语法(二):面向对象
- 四、学生管理系统
- 跋文
前言
你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你是Python小白亦或者是有一定Python基础的同学,这篇Python文章都不会让你失望,本篇博客是 [AIoT阶段一] 的内容:Python 语法基础,关于所有的AIoT的详细介绍,详见博客:AIoT(人工智能+物联网)知识总结+实战项目,本文仅为上篇,下篇见博文:数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解),先来简单介绍一下本文,学完本文,你可以掌握以下技能:
1️⃣数据类型
2️⃣循环控制
3️⃣切片操作
4️⃣集合操作
5️⃣常用内建函数
6️⃣函数式编程
7️⃣类与对象
8️⃣继承
当然,你也可以只选择其中的几项技能进行学习,后续可能还会更新【爬虫】【数据分析】【办公自动化】【大数据】等基于Python的系列文章,但这都是后话了,有需求的读者也可以私信或评论出来,目前博主主要更新方向还是围绕 AIoT(人工智能+物联网)知识总结+实战项目 展开,但也会根据大家的需求适时调整更新的方向以及节奏,最后请让我自夸一下:本篇博客写于2021/12/3,结束于2022/1/14,本文与网上教程以及其他关于Python的博文区别有如下几点:
1️⃣新,可以说是至2022/1/14最新的Python相关博文(使用 Python 3.10);
2️⃣配图详细,所有的配图均是博主一步一步实践过程中的配图,配图中需要强调的地方用红圈圈出;
3️⃣结构条理清晰 (这里吐槽一下我们学校Python的教材,很多后面章节才学的东西在很前面的章节就很频繁的使用,自学起来十分的费力,本篇博客不会出现这种问题);
4️⃣配套练习题目多 所有题目支持网络在线评测,我为此专门设置了一个专门的小节:Python程序设计训练场,习题均为博主从题库中筛选得到,比起一些课本中陈旧的习题,更能锻炼读者的程序设计能力;
5️⃣对重点与非重点有着明确的区分,几乎市面上所有的教材为了体现知识结构的完整性都写的十分的 详尽,有时候详细并不是好的体现,很多知识我们只需要会查着用即可,完全没必要去记和学所有的知识点,本文要重点突出也在这里,为做到同时具备工具书(知识结构完整)和有价值的学习书(知识点主次分明)两者兼备,博文采取以下形式展开:
🎯必备的知识会在每篇的开头给出
🎯所有目录标题中带 *(星号)的,均代表不需掌握,只需做到眼熟,在需要的时候查着用即可
关于本篇博客的质量:不夸张的说这篇博客将是我写文至今(2021/12/3)的 最高水准,如果你拿本博客的目录与书上的目录进行对比,那么你会发现,博客对于 Python 的讲解顺序和书上有很大的差别,博主花了大量的时间和精力去思考如何的排序知识点的学习顺序才能让文章具有最佳的条理性。一直想出一本属于自己的书,本篇博客将尽我可能向市面上书的水平看齐,闲话就先扯这么多,如果你看到了这里,那么 “欢迎来到Python的国度”
一、 欢迎来到Python的国度
1.搭建Python的开发环境
🚩安装Python解释器,网址:https://www.python.org/,打开后界面如下图所示:
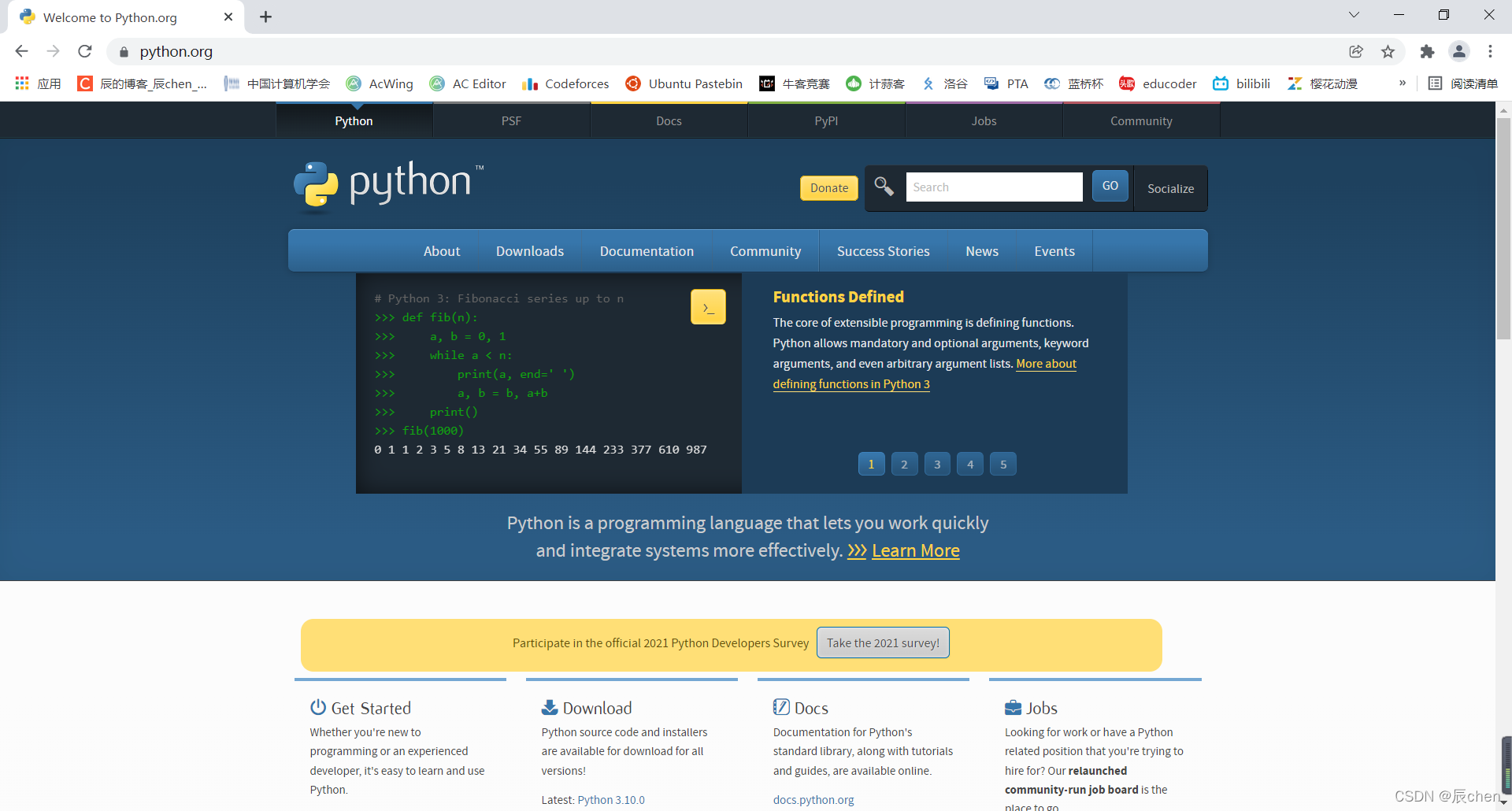
鼠标滑至 Downloads,注意,我的电脑是 Windows 系统,这里默认也是 Windows 系统,读者应根据自己的电脑版本选择不同的Python解释器版本下载
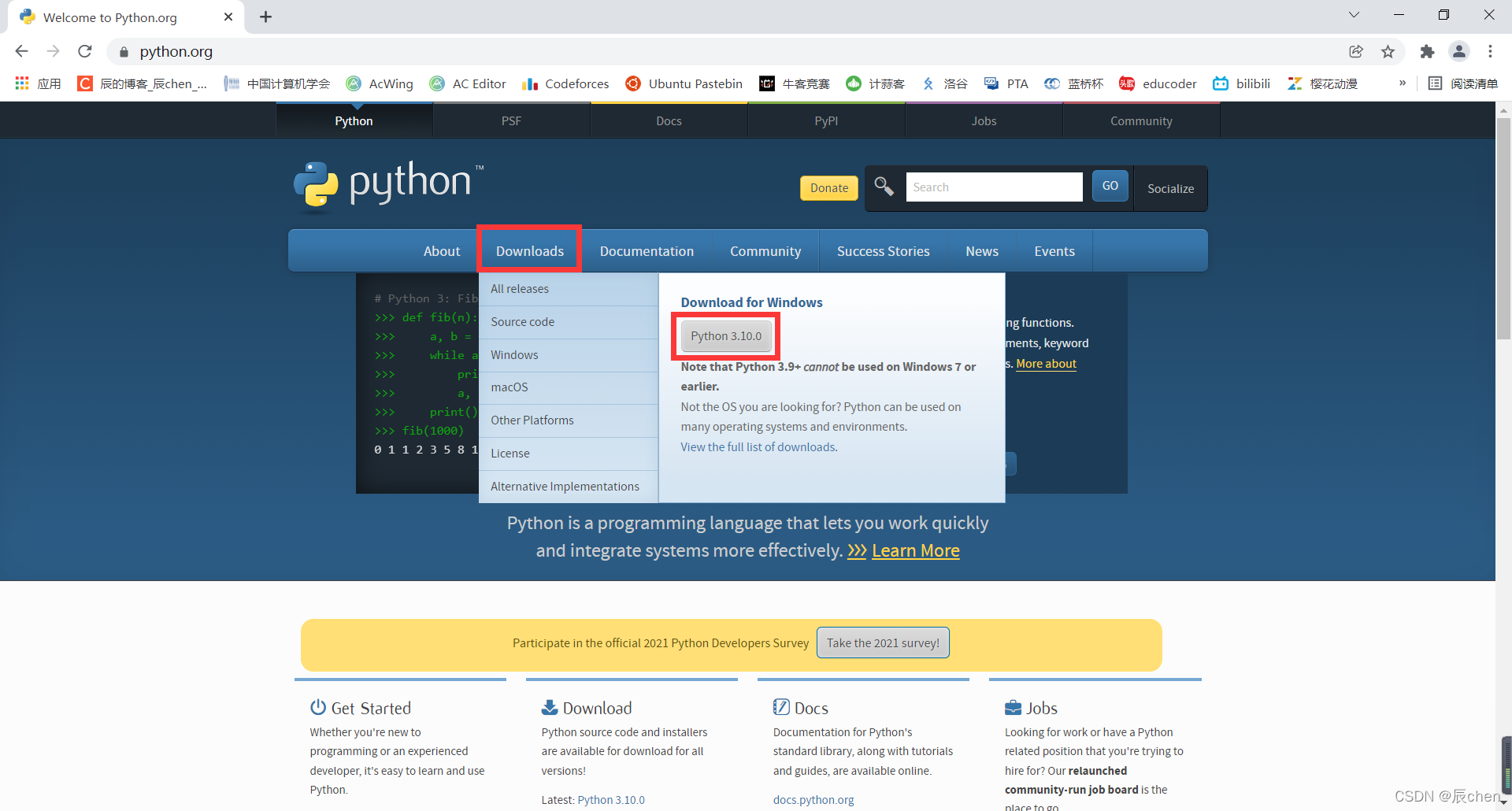
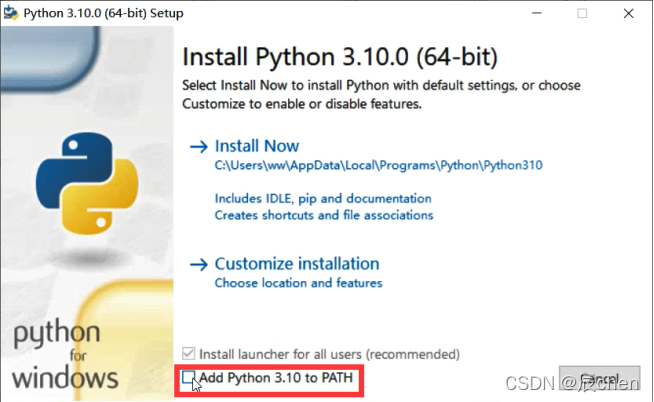
下载完成之后会显示如下的界面,这时我们要点击 Add Python 3.10 to PATH
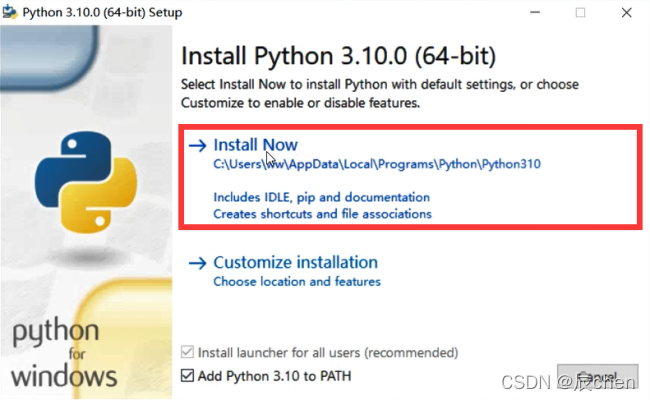
然后紧接着单击 Install Now
出现等待加载的界面~
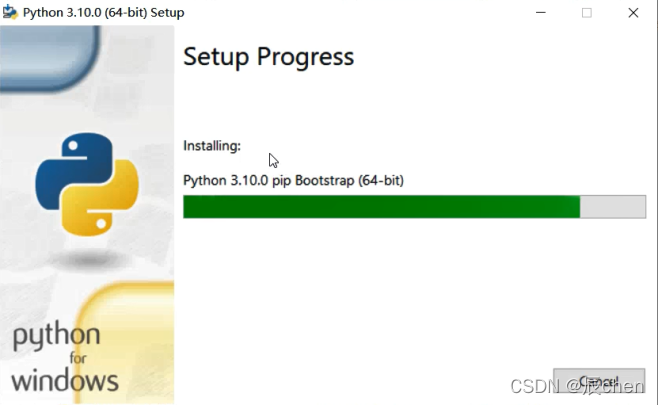
加载完成后,单击 Close,关闭即可,至此,我们的 Python 开发环境配置成功,Congratulation~🎈
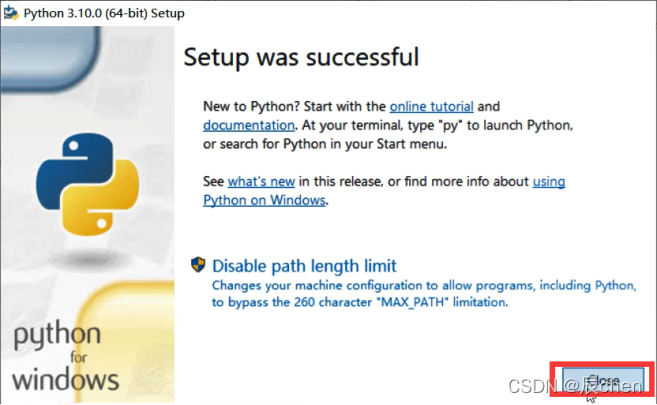
*2.相关程序介绍
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️让我们来简单的看一下我们到底安装了个什么东西
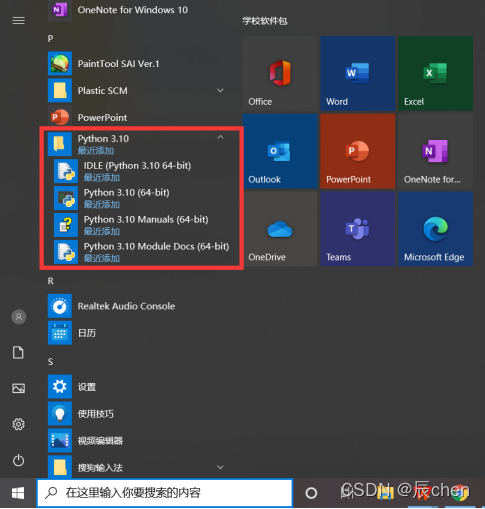
大家可以在自己的 开始菜单 中找到我们下载好的 Python 3.10,它主题上分为四个部分:

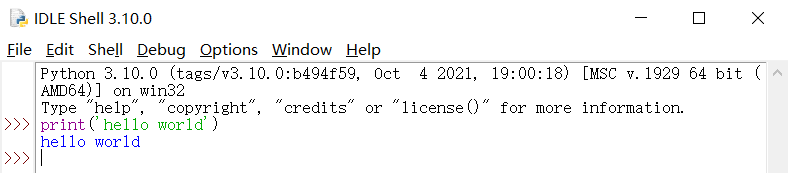
我们可以使用Python自带的简单开发环境 IDLE 或者是交互式命令行程序去写一写很简单的 Python代码,譬如我们最为经典的:输出‘hello world’
⛲️交互式命令行程序:

⛲️使用Python自带的简单开发环境 IDLE 输出 hello world:
❗️ 注:输出函数为 print,这里读者只需要跟着博客写的代码自己跟着写一遍即可,后续会对 print 进行讲解
3.搭建第三方开发环境:PyCharm
🚩安装PyCharm:官网下载地址:https://www.jetbrains.com/pycharm/download/#section=windows,打开后如下图所示:
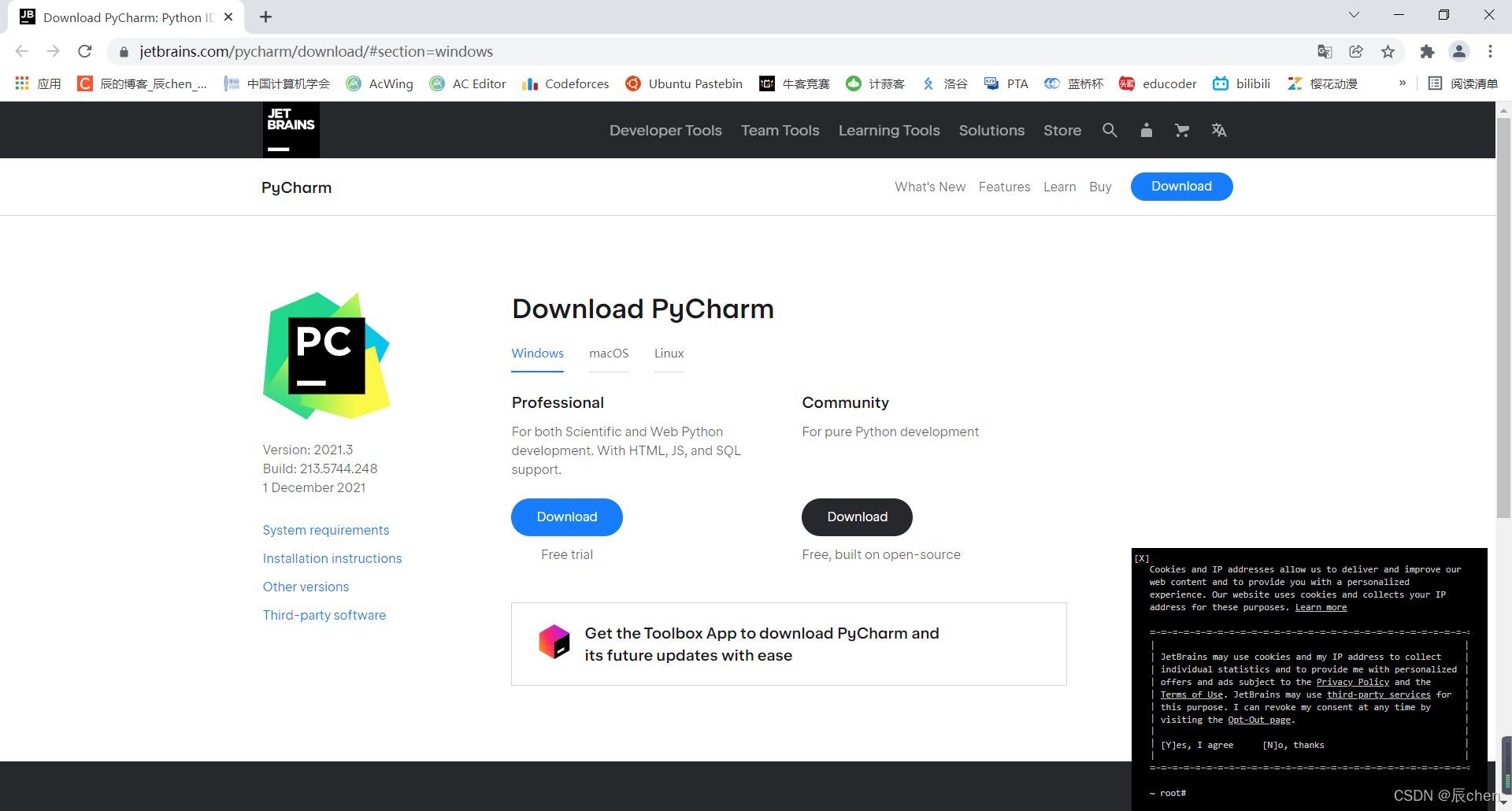
❗️ 博主的电脑为 Windows 操作系统,读者要根据自己电脑不同的系统选择自己的版本,这里注意有两个版本,一个为 Professional 版本(俗称付费版),一个为 Community 版本(俗称免费版),如果你是跟着博主学习 AIoT 的小伙伴,这里建议你去下载付费版(付费版有30天的试用时间),其他的小伙伴建议去下载免费版,博主这里下载的是付费版:
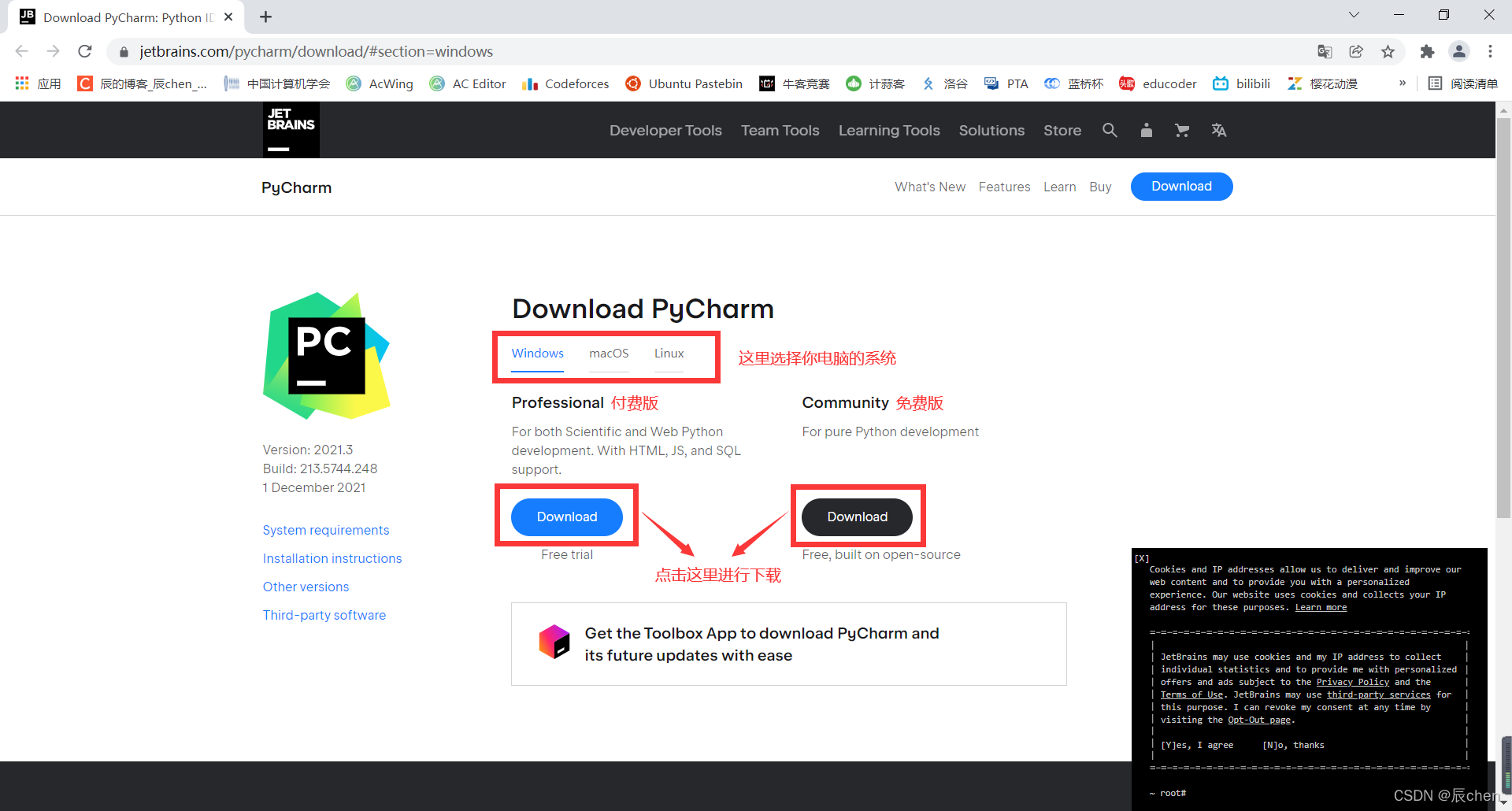
下载完成后会跳出如下界面,点击 Next
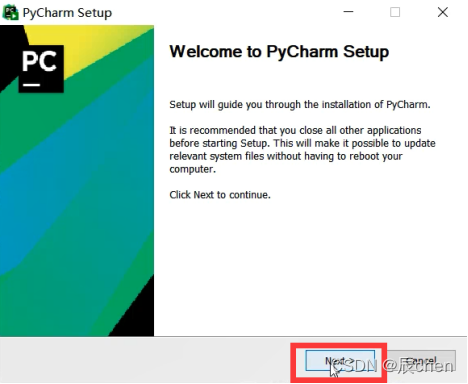
紧接着来到如下界面,这里的默认安装路径为 C盘,非常不建议安装到C盘,可以选择在 D盘 新建一个文件夹安装到 D盘
❗️ 注:文件夹的名字中不要带中文,否则未来容易出现各种奇奇怪怪的问题
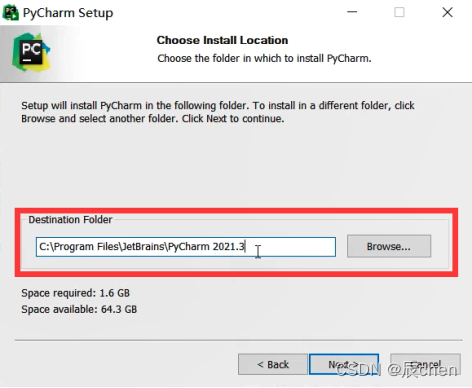
修改好路径之后点击 Next
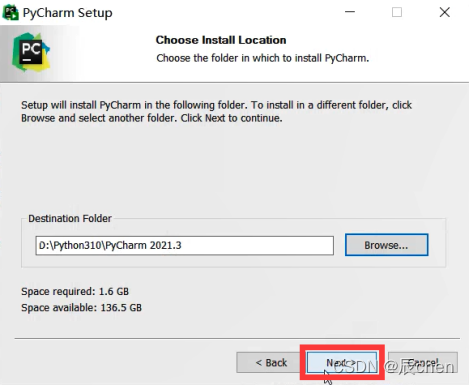
这些全点上✔️,然后点击 Next
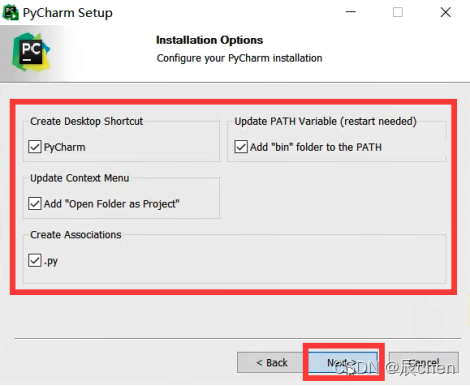
点击 Install
出现等待加载的界面~
❗️ 这里注意,Reboot now 是立即重启电脑,I want to manually reboot later 代表的是需要你等等自己手动重启电脑,这里建议在确认电脑没有未保存的文档之后点击立即重启 Reboot now
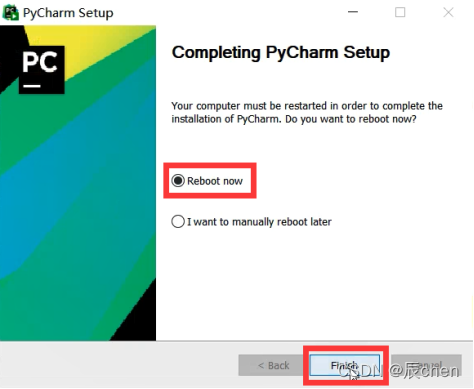
重启之后,Pycharm 就已安装成功,Congratulation~🎈
4.PyCharm的使用
4.1 Professional版本
🚩初次点击 PyCharm 会显示如下界面,不用管,点击 OK
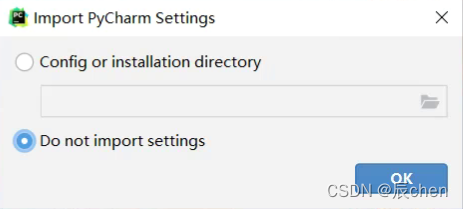
紧接着来到这个界面,这里需要我们登录我们的 JET BRAINS 账号,点击 Log in… 就可以进入官网界面,没有账号的同学同样可以在官网注册我们的 JET BRAINS 账号
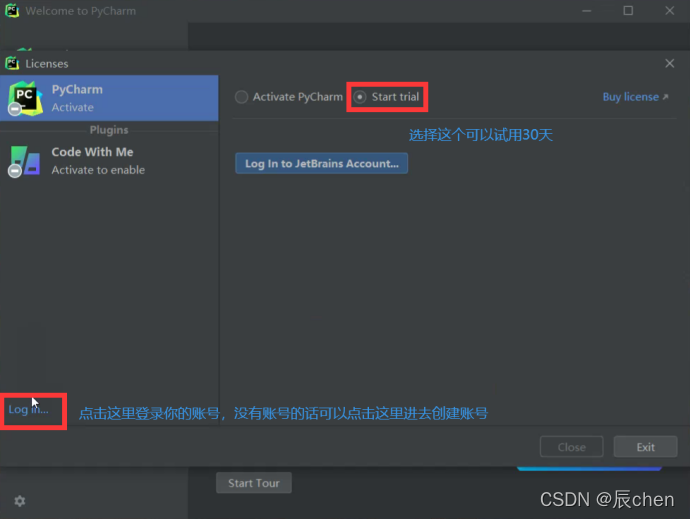
点开时候,界面如下图所示,这时即可输入你的账号以及密码,没有的同学可以点击 Create Account 用电子邮箱即可创建属于你的账号
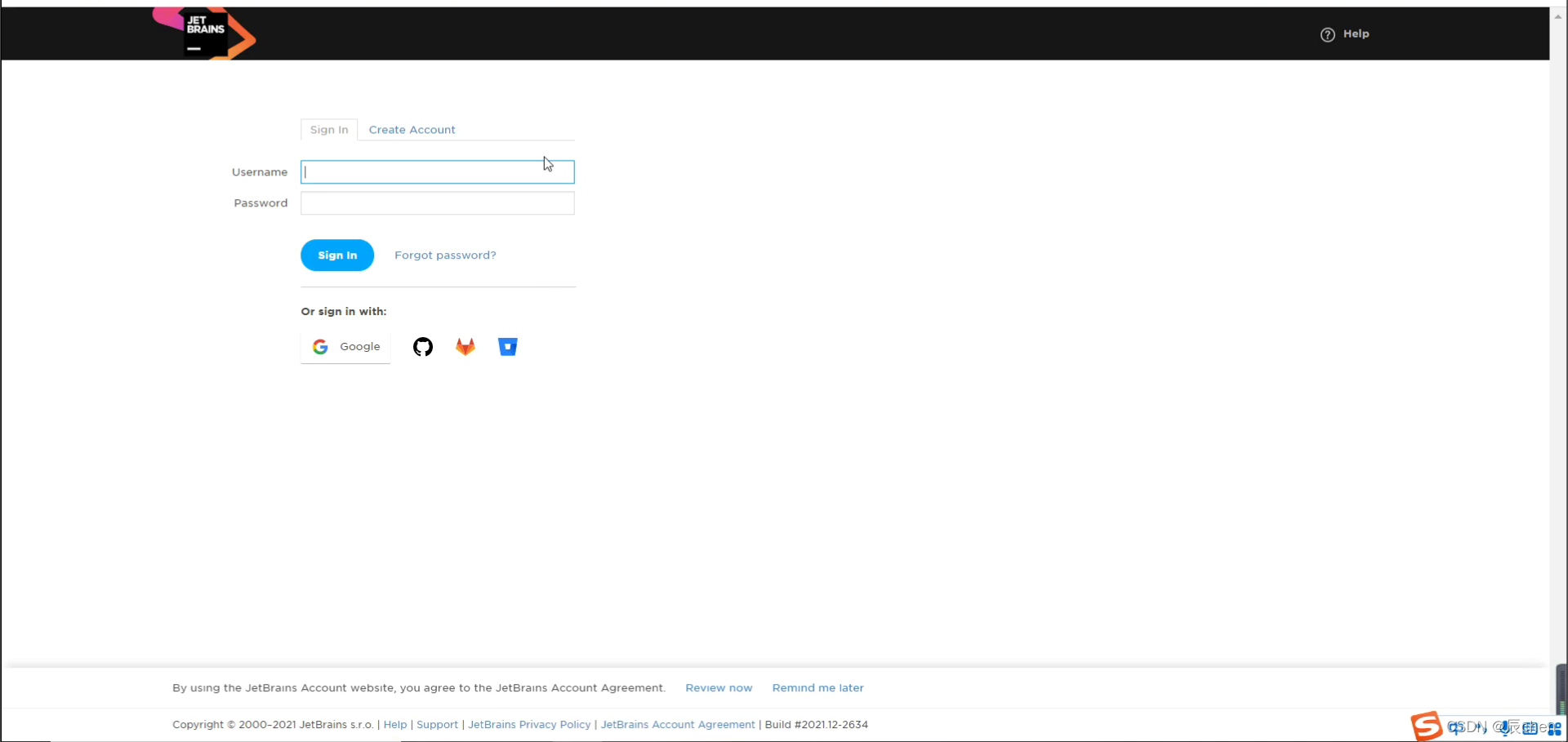
登录/注册 成功之后出现这个界面,这个时候直接返回 Pycharm 即可
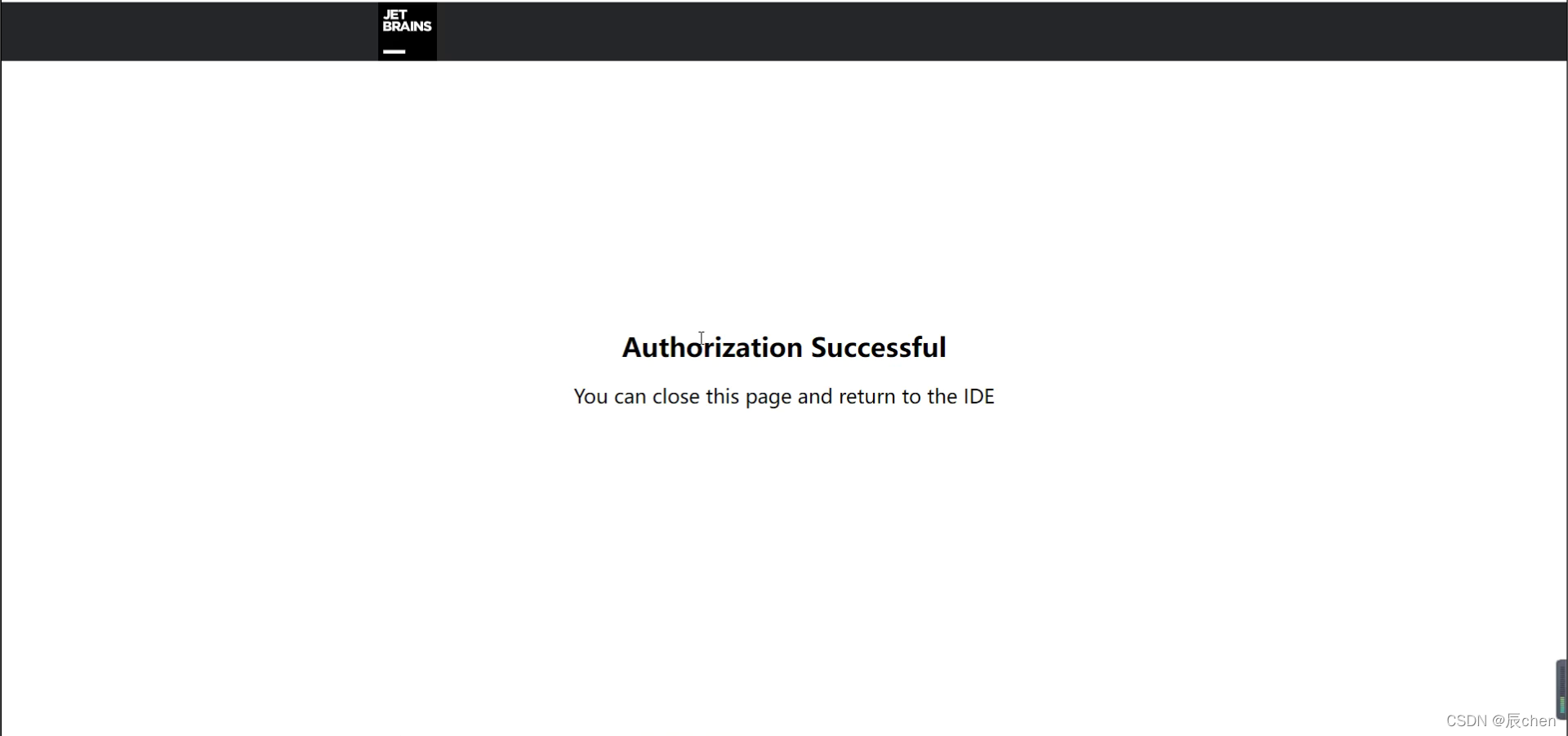
返回之后,点击 Start Trial,即可开启试用啦~
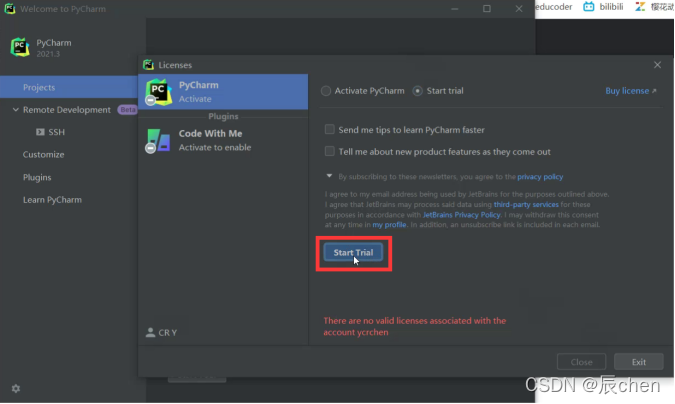
点击 Close关闭即可
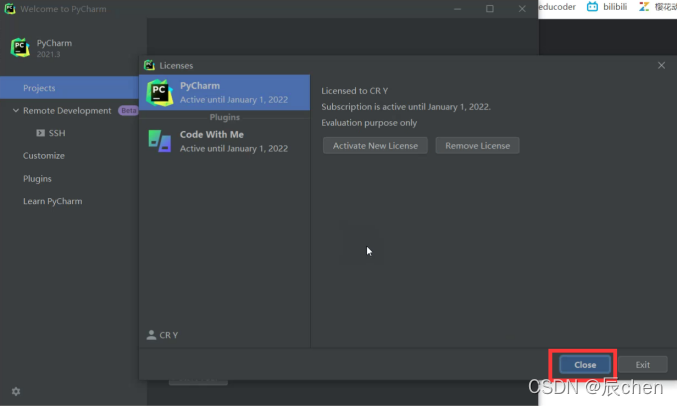
点击 New Project,开始我们正式的 Python之旅
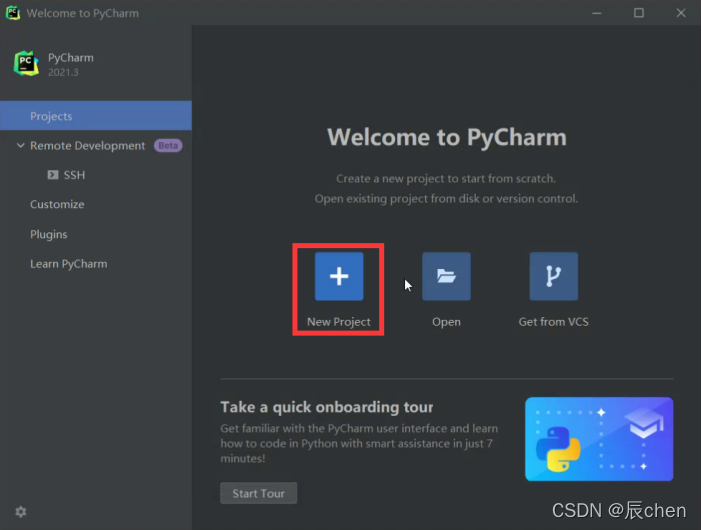
点开之后长下图这个样子,我们更改一下 Location,这是我们存我们以后写好的代码的地方,默认安装在 C盘,不建议安装至 C盘,可以在 D盘或E盘 重新创建一个文件夹,用来存储我们以后写好的代码
❗️ 注:我们的文件夹不能是中文
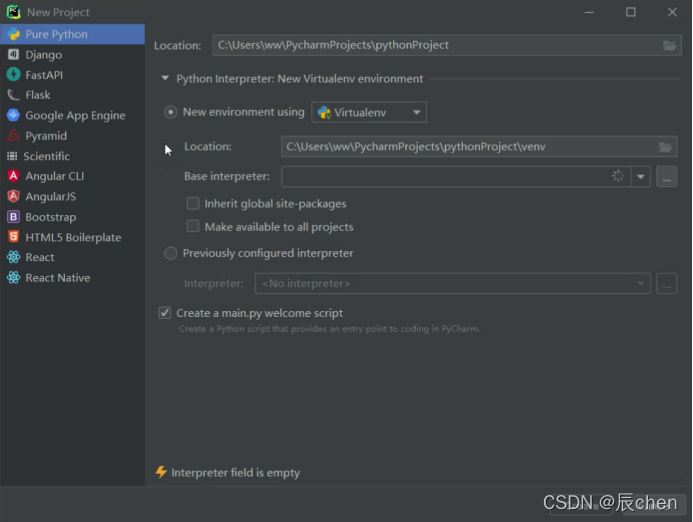
注意这里取消 Create a main.py welcome.script,然后点击 Create
出现如下窗口,点击 This Window
稍微等待后点击这里
点开之后,右键点击如下位置
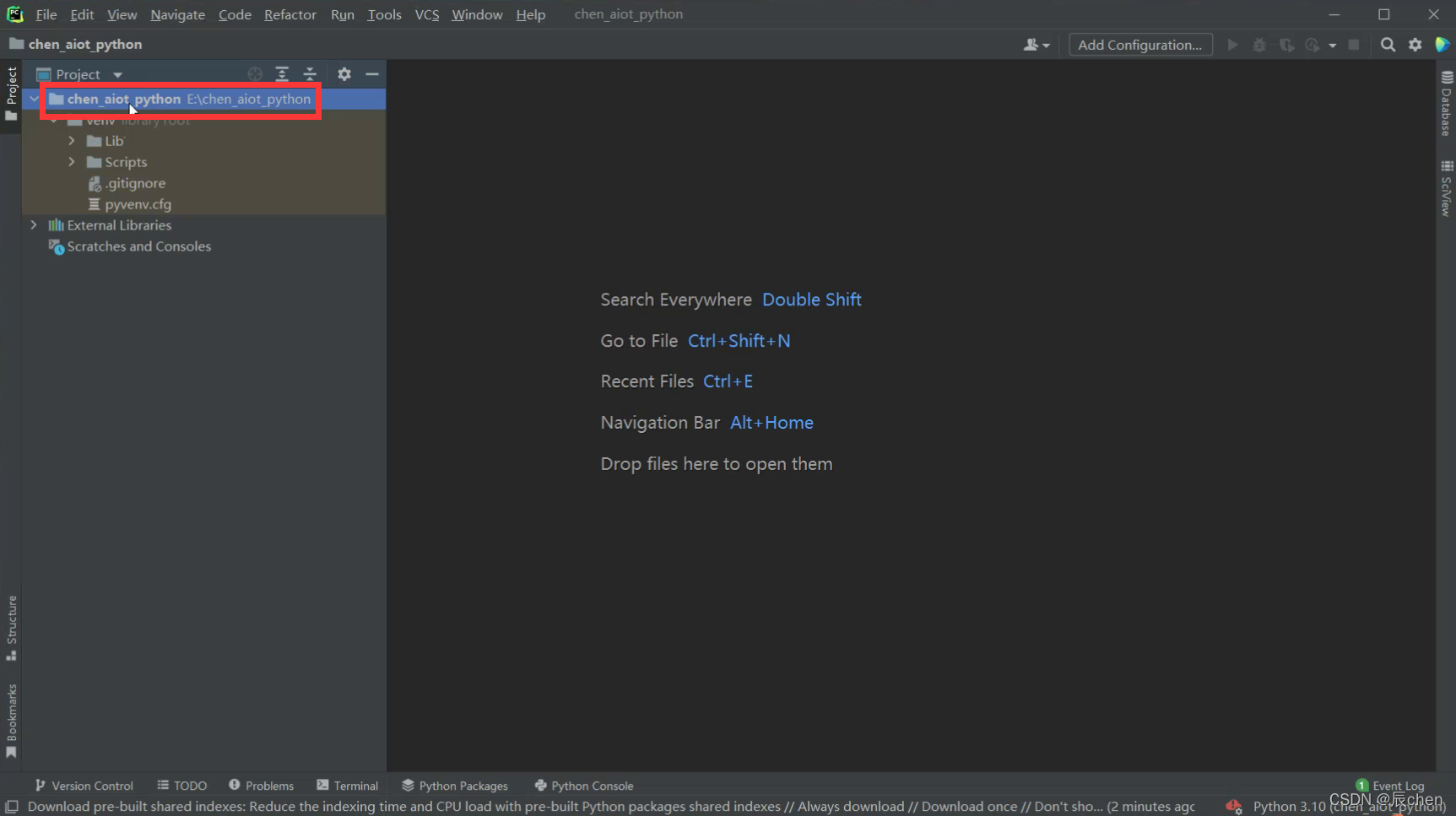
点击 Python File
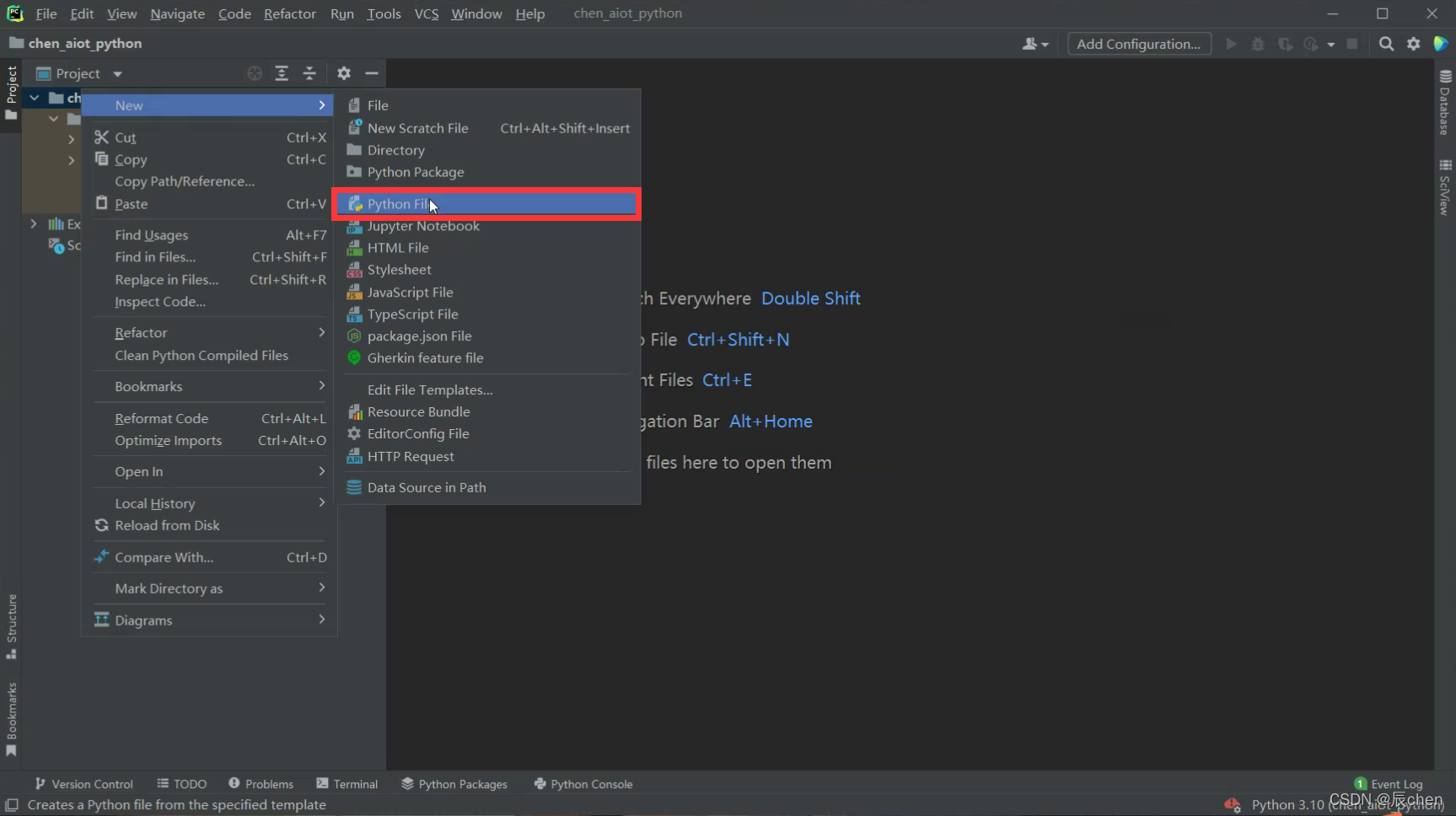
这里,我们可以给我们写的代码起一个名字,这里我起名为 demo1,大家也可以自己起名
❗️ 注:名字中不可以有中文
至此,在 Professional版本 你已经成功 新建工程 以及 新建 Python 文件,Congratulation~🎈
4.2 Community版本
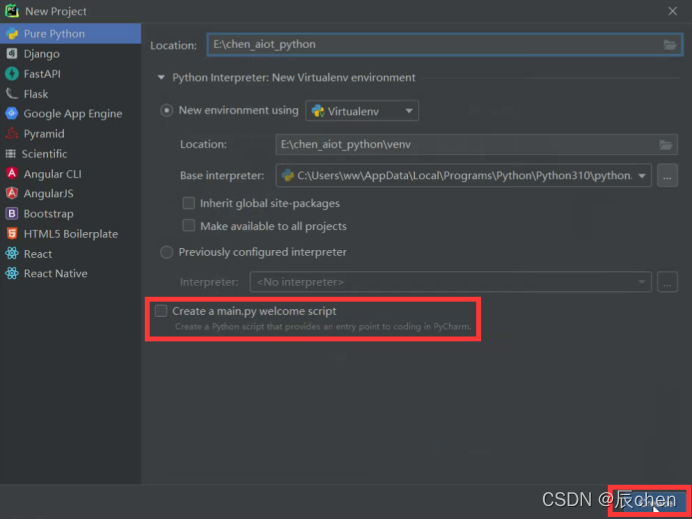
点击 New Project,开始我们正式的 Python之旅
点开之后长下图这个样子,我们更改一下 Location,这是我们存我们以后写好的代码的地方,默认安装在 C盘,不建议安装至 C盘,可以在 D盘或E盘 重新创建一个文件夹,用来存储我们以后写好的代码
❗️ 注:我们的文件夹不能是中文
❗️ 注意这里取消 Create a main.py welcome.script,然后点击 Create
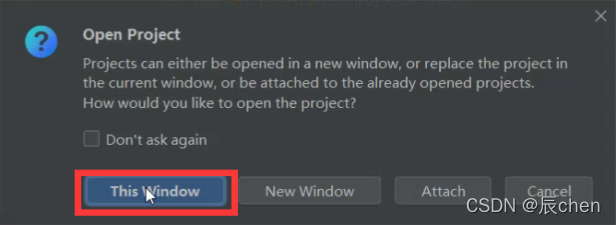
出现如下窗口,点击 This Window
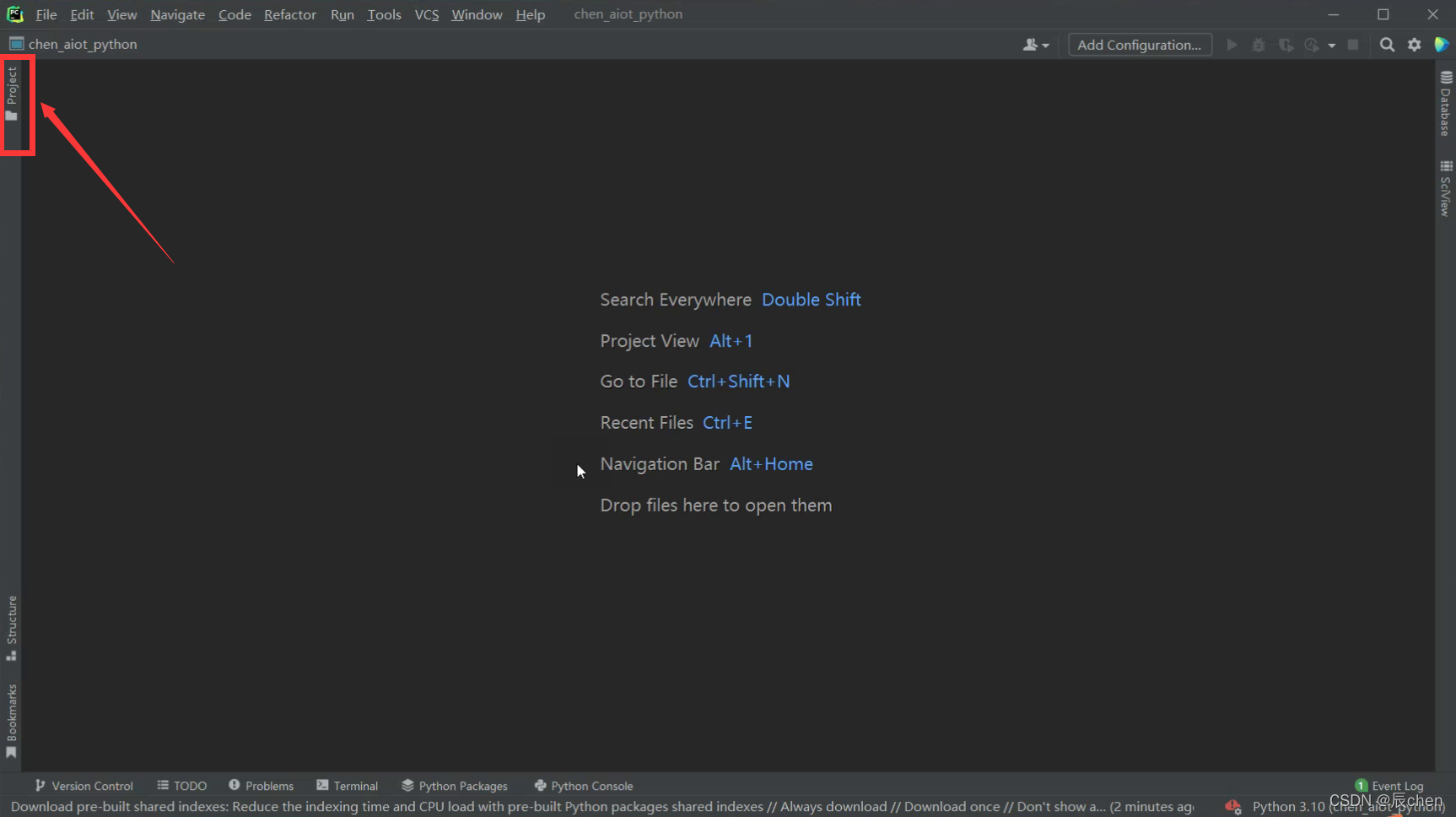
稍微等待后点击这里
点开之后,右键点击如下位置
点击 Python File
这里,我们可以给我们写的代码起一个名字,这里我起名为 demo1,大家也可以自己起名
❗️ 注:名字中不可以有中文
至此,在 Community版本 你已经成功 新建工程 以及 新建 Python 文件,Congratulation~🎈
4.3 第一个Python代码:hello world
🚩历来经典的代码:输出 hello world,在这里,我们会使用一个函数:print(),去输出,在后面我们会去讲解这个函数,现在大家要做的就是和博主一起打印如下的代码,然后右键,点击 Run demo1,运行我们编写的代码
print('hello world')
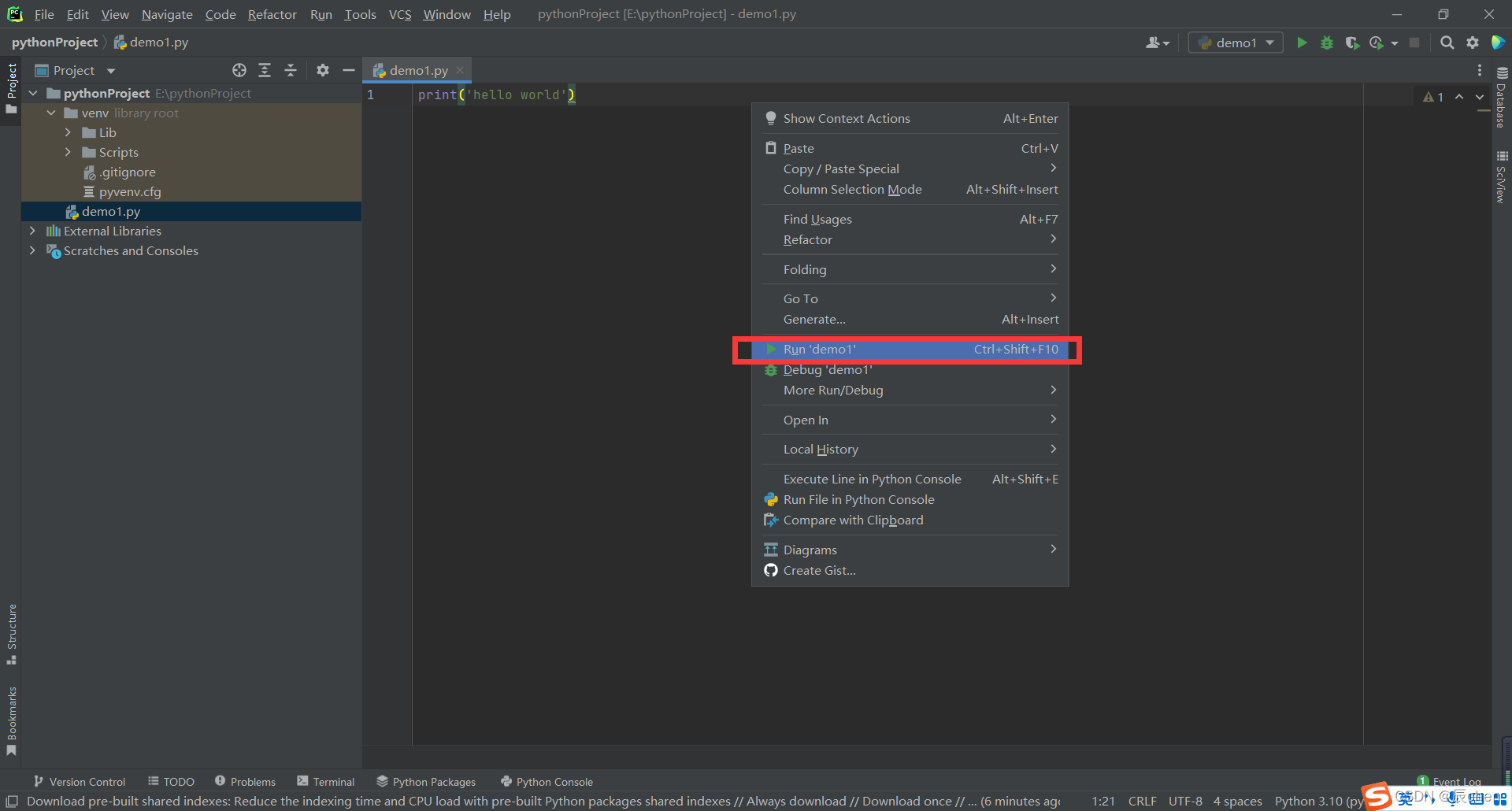
最终答案会呈现在下方。

🚩这里再额外说一下,建议大家在以后写代码的时候,要先建一个目录,然后把一类相关性强的代码放入同一个目录,比如我们后续的学习,你可把每一节的代码放入到同一个目录中,像这样:
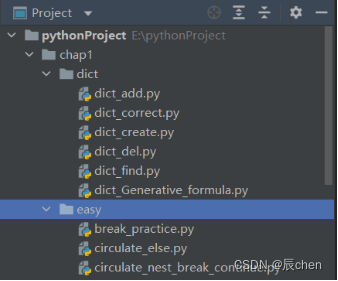
建立目录的方法是:右键我们刚刚设置的存代码的文件夹(亦可以是其他地方),点击 New,点击 Directory,然后起好名称即可.
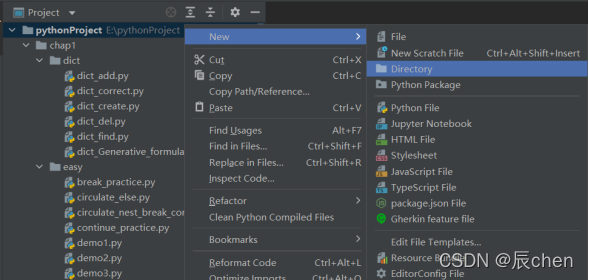

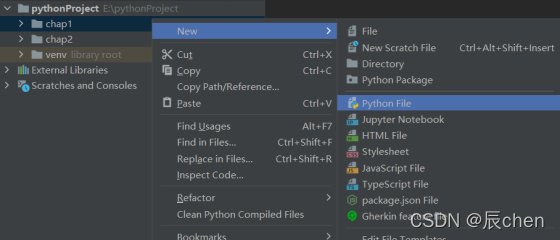
此后,我们写代码就选择我们的目标目录,然后右键选择 New,点击 Python File 即可创建一个.py 文件写我们的 Python 代码
至此我们已经可以说已经正式踏入了 Python 这个未知的国家,接下来,就让博主带领你在这片未知的国度玩个开心!
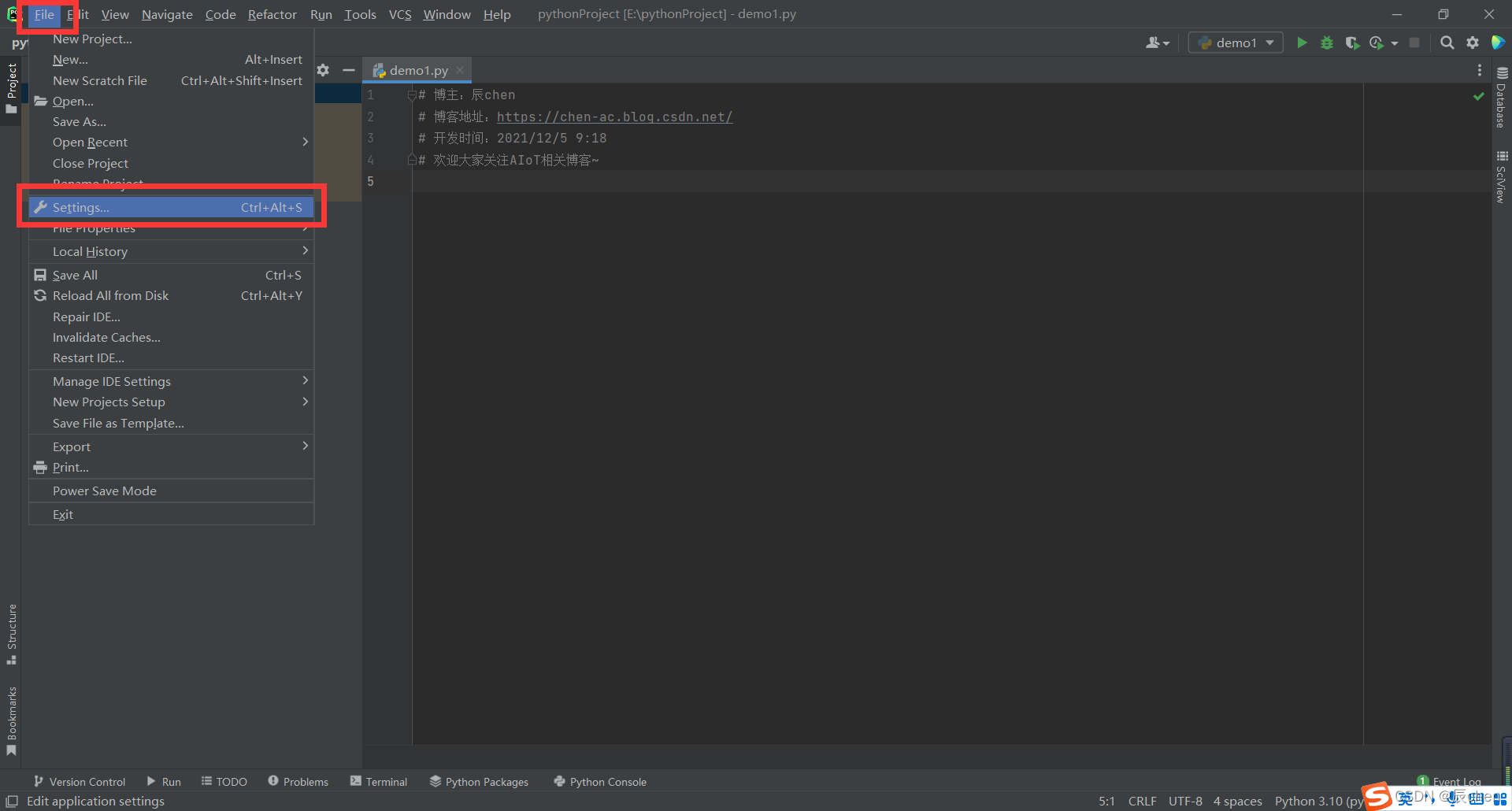
*4.4 PyCharm的一些配置
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️我们可以对PyCharm进行一些简单的修改,可以使我们的编译界面显得更加的优美
在博主后续的写代码的文章中,你会看到每个代码之前都会有如下字样:
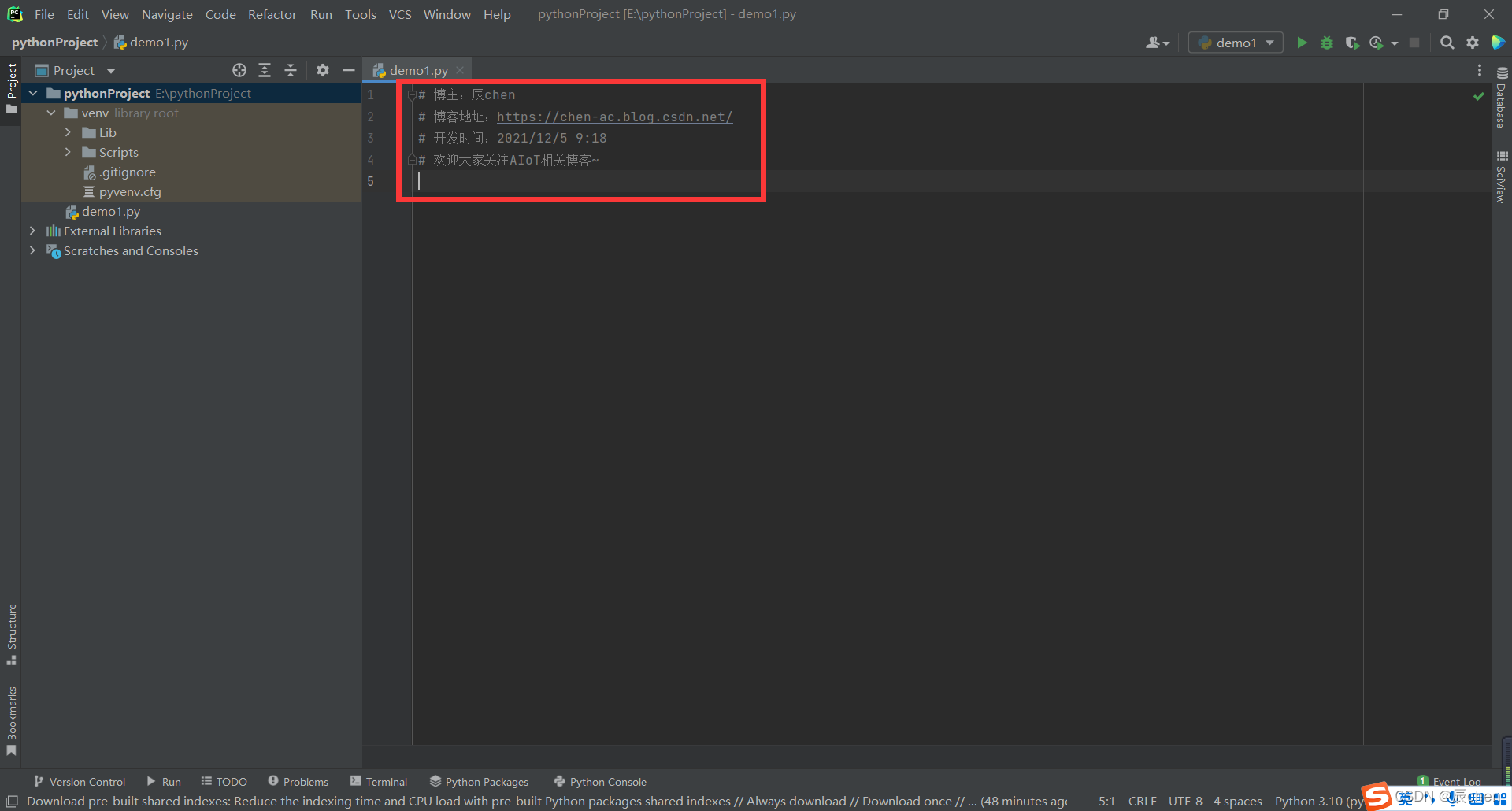
这个我们可以自己设定,具体设置路径为:File -> Settings… -> Editor -> File and Code Templates -> Python Script ,然后就可以输入自己每次代码最前方想显示的东西即可
❗️ 注:写之前的每一行都需要用 # 作为每一行的开头,后续我们会讲解这个知识点
然后写好之后点击 Apply 即可
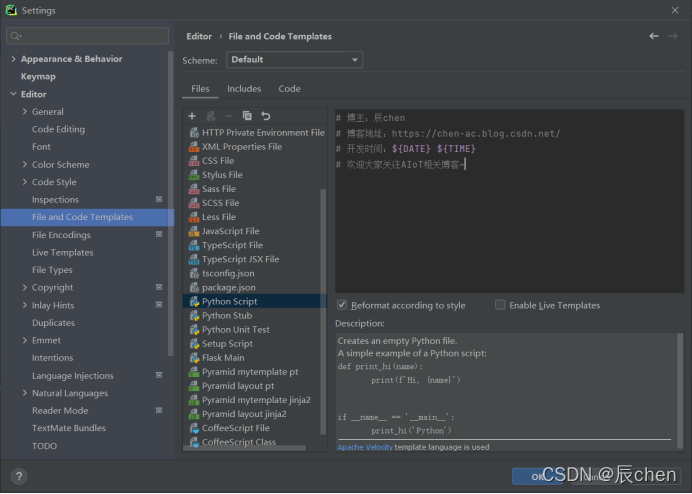
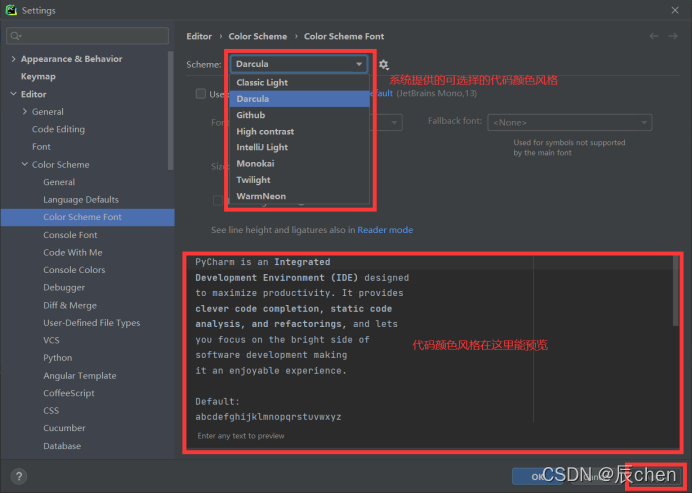
当然啦,你可能会觉得黑色的界面亦或者是这个代码的颜色我不喜欢,我们也是可以更改的,具体设置路径为:File -> Settings… -> Editor -> Color Scheme -> Color Scheme Font ,在这里,可以更改我们的代码颜色以及背景颜色,选择一个你喜欢的颜色,点击 Apply 即可
⛲️注意,如果你选择的代码背景颜色是白色的,如你选择了 GitHub,那么会出现下图窗口,这里点 Yes 和 No 会有如下区别:
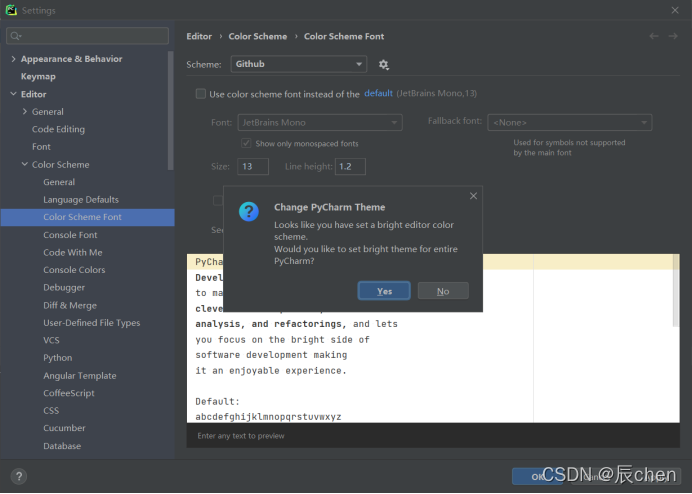
点击 Yes

点击 No:
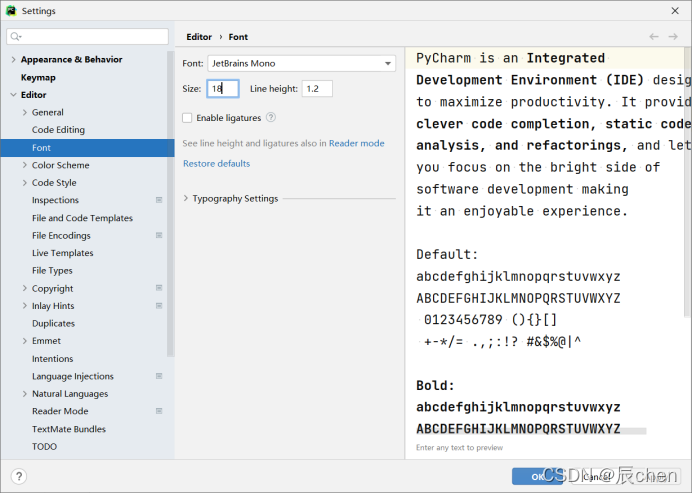
⛲️接下来我们来调节一下字体的大小,具体操作路径为:File -> Settings… -> Editor -> Font,在这里我们修改 Size 的值即可
综上就是就是我们的一些关于 Pycharm 的基础配置的修改,我们会发现 Settings 中海油很多的配置我们是可以进行修改的,这里就不进行赘述,我们会以上的修改就已经足够啦
4.5 面向过程和面向对象
🚩编程界的两大阵营:面向过程和面向对象:
| 面向过程 | 面向对象 | |
| 共同点 | 面向过程和面向对象都是解决实际问题的一种思维方式 | |
| 二者相辅相成,并不是互相独立的 解决复杂问题,通过面向对象方式便于我们从宏观上把握事物之间复杂的关系,方便我们分析 整个系统;具体到微观操作,仍然使用面向过程方式来处理 | ||
下面,我在正式讲解 Python 的时候,就会分成面向过程和面向对象两个方向去讲解,对于初学者而言,我们需要在面向过程部分熟练掌握 Python 语法,掌握基本编程思维逻辑。
*4.6 PyCharm 常用快捷键
注:本小节带 *,不需要进行学习,可以简单进行了解
| 序号 | 快捷键 | 描述 |
|---|---|---|
| 1 | Ctrl + / | 注释选中行 |
| 2 | Ctrl + Alt + Enter | 向上插入 |
| 3 | Shift + Enter | 向下插入 |
| 4 | Ctrl + D | 复制、粘贴一行 |
| 5 | Ctrl + Y | 删除一行 |
| 6 | Shift + F6 | 重命名 |
| 7 | Ctrl + O | 复写代码(方法重写) |
| 8 | Ctrl + Alt + T | 添加 try/catch |
| 9 | Ctrl + Alt + M | 抽取代码(提取函数等) |
| 10 | Ctrl + Alt + F | 变量抽取全局变量(局部变量变属性) |
| 11 | Ctrl + Alt + V | 方法体内值抽取成变量 |
| 12 | Shift + Tab | 方向退格 |
| 13 | Tab | 进行退格 |
| 14 | Alt + Shift + 上下键 | 选中代码移动 |
| 15 | Ctrl + Shift + 上下键 | 移动当前方法体 |
| 16 | Ctrl + Shift + Enter | 补全代码 |
| 17 | Ctrl + Shift + U | 代码大小写 |
| 18 | Ctrl + B | 进入代码 |
| 19 | Ctrl + Shift + F12 | 最大化窗口 |
| 20 | Ctrl + F | 查找 |
| 21 | Ctrl + R | 替换 |
| 22 | Ctrl + Shift + F | 全局查找 |
| 23 | Ctrl + Shift + R | 全局替换 |
| 24 | Ctrl + Shift + I | 快捷查看方法实现的内容 |
| 25 | Ctrl + P | 查看参数 |
| 26 | Ctrl + Q | 查看文档描述 |
| 27 | Shift + F1 | 查看 API 文档 |
| 28 | Ctrl + F12 | 查看类的方法 |
| 29 | Ctrl + H | 查看类的继承关系 |
| 30 | Ctrl + Alt + H | 查看哪里调用了方法 |
| 31 | Ctrl + {} | 定位查看方法体的括号 |
| 32 | F3 | 查看选中的内容 |
| 33 | Shift + F3 | 反向查看内容 |
| 34 | Ctrl + Alt + B | 查询类实现光标所在接口的类 |
| 35 | Ctrl + U | 查看父类 |
| 36 | Ctrl + E | 最近编辑的文件列表 |
| 37 | Ctrl + Alt + Home | 查看布局与对应的类 |
| 38 | Alt + Insert | 新建文件及工程 |
| 39 | Ctrl + Alt + S | 打开软件设置 |
| 40 | Ctrl + Alt + Shift + S | 打开 module 设置 |
| 41 | Ctrl + Tab | 切换目录及视频 |
| 42 | Alt + Shift + C | 查看工程最近更改的地方 |
| 43 | Ctrl + J | livetemp 模块查看 |
| 44 | Ctrl+ F9 | 构建 |
| 45 | Shift + F10 | 运行 |
| 46 | F11 | 定义书签 |
| 47 | Shift + F11 | 查看书签 |
| 48 | Ctrl + J | 快速调出模板 |
| 49 | Alt + 点击断点 | 禁用断点 |
| 50 | F2 | 定位错误 |
| 51 | Alt + Enter | 修正错误 |
| 52 | Alt + 鼠标 | 进行列编辑模式 |
| 53 | Ctrl + W | 选中单词 |
| 54 | Ctrl + Alt+ 左右键 | 定位到编辑的位置 |
二、玩转Python语法(一):面向过程
1.Python的七十二变
1.1 Python中的注释
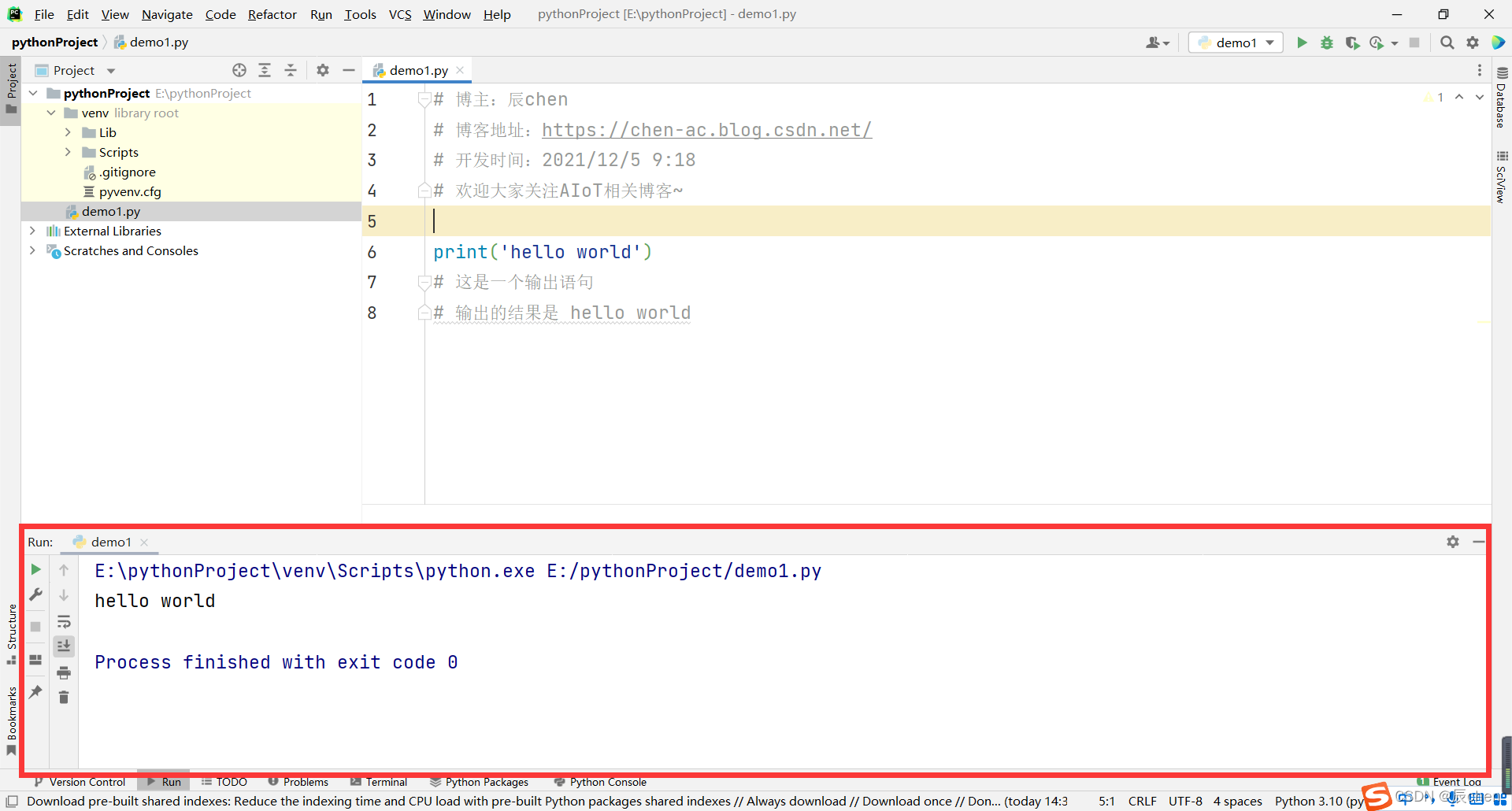
🚩代码的注释:显然,对于咋们大多数人而言,看中文要比看英文舒服的多,注释的作用就是:给别人简明扼要的翻译一下你写的代码的含义,注释由 # 开头,具体的注释内容写在后面,比如我们给我们写的demo1加上注释:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 9:18
# 欢迎大家关注AIoT相关博客~
print('hello world')
# 这是一个输出语句
# 输出的结果是 hello world
至此我们也知道了为什么在 *4.4 PyCharm的一些配置 中说的必须加上 #,说白了 # 的作用就是使 # 后的这一行的所有内容 失效,即我们的 PyCharm 在进行运行代码的时候会自动 屏蔽 掉 # 后本行的内容,故对于 # 后本行的内容只有我们程序员看源码的时候才能看到,我们的计算机是不会看到的,这就是所谓的 注释
⁉️读者可能有疑惑:什么情况下需要加注释呢?如果每一条语句都需要加注释的话,那么我们写代码的速度不就被大大降低了么?而且我自己写的代码我肯定能看的懂啊,如此来说,加注释不就显得很多余了么?
🎯确实,对于每一行代码都需要加上注释的话,那么我们写代码的速度会被大大降低,而且会很没必要,就如我们的第一个代码:输出hello world,其实作为程序员的我们都知道这个语句的含义,那么这就完全没必要加注释了,同学们需明确一点,在我们现在或者未来的工作中,我们写代码首先是写给自己看,其次是写给同事或者是后人去看,为了在未来我们写的代码易被维护,故我们需要在一些必要的位置加上注释,而且千万不要认为自己写过的代码一定能看懂,随着以后代码量的不断加大,很有可能今天写的代码过一两天再看就很难看懂含义,故学会加注释,是一个很好的习惯,这里拿下述代码去举例:
❗️ 注:下述代码是为了让大家理解注释的作用,不需要看懂
while (n != 0):
if sever!= h and server != '*':
if type != 'REQ':
continue
if type != 'DIS' and type != 'REQ':
continue
if (server == '*' and type != 'DIS') or (server == h and type == 'DIS'):
continue
update_ips_state(tc)
if type == 'DIS':
k = get_ip_by_owner(client)
if not k:
k = k=get_ip_by_state(0)
if not k:
k = k=get_ip_by_state(3)
if not k:
continue
ip[k].state = 1
ip[k].owner = client
if not te:
ip[k].t = tc + t_def
这段代码不论是给谁去看都会觉得很是头大😡,在这里,就体现出注释的重要性了,我们给下面代码加上注释:
while (n != 0):
if sever!= h and server != '*':
if type != 'REQ':
continue
if type != 'DIS' and type != 'REQ': # 发*一定对应dis,但是给服务器发一定不与DIS对应
continue
if (server == '*' and type != 'DIS') or (server == h and type == 'DIS'):
continue
# 更新ip地址池的状态
update_ips_state(tc) # 传入当前时刻
# 处理DIS
if type == 'DIS':
# 检查是否有占用者为发送主机的 IP 地址:
# 如果有,选取该 IP 地址;
k = get_ip_by_owner(client)
# 若无,则选最小的状态为未分配的 IP 地址;
if not k:
k = k=get_ip_by_state(0) # 0代表未分配
if not k:
k = k=get_ip_by_state(3) # 3代表过期
# 若无,则不处理该报文
if not k:
continue
# 占用者设置为发送主机;
ip[k].state = 1 # 该 IP 地址状态设置为待分配
ip[k].owner = client # 占用者设置为发送主机;
# 报文中过期时刻为 0 ,则设置过期时刻为 t + t_def;
if not te:
ip[k].t = tc + t_def
这样看来,复杂的代码一下就显得十分的直观易读了,这就是注释的作用
能看出,在 Python 中 # 可以进行单行注释,下面来简单介绍多行注释,我们将一对三引号之间的代码称为多行注释
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 9:18
# 欢迎大家关注AIoT相关博客~
'''
在三引号之间的内容均为注释内容
这部分内容同样会被Python解释器忽略掉
我们可以在三个引号之间写任意多的东西
'''
print('hello world')
1.2 Python中变量的定义
*1.2.1 标识符和保留字
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️保留字:有一些特殊的单词被我们赋予了特殊的含义,我们在给对象进行命名的时候不可以使用这些名字,我们可以使用如下函数去查看我们的保留字有哪些:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 15:05
# 欢迎大家关注AIoT相关博客~
import keyword
print(keyword.kwlist)
'''
输出结果(保留字)如下列出
['False', 'None', 'True', 'and', 'as', 'assert', 'async',
'await', 'break', 'class', 'continue', 'def', 'del', 'elif',
'else', 'except', 'finally', 'for', 'from', 'global', 'if',
'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or',
'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
'''
以上这些完全没必要去记,我们只需要明白一点:在 Python 中我们命名对象的时候有些字符是不能作为对象名的,这些特殊的名字只要我们使用其实 PyCharm 就会自动给我们报错
⛲️标识符:
变量、函数、类、模块和其它对象的起的名字就叫标识符,我们对标识符有如下命名的规则:
标识符可由:字母、数字、下划线_,以上三部分任意排列组合去组成
不能以数字开头
不能是保留字
标识符是严格区分大小写的
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 15:05
# 欢迎大家关注AIoT相关博客~
# 由数字,字母,下划线_ 组成
a_b = 1
a1 = 2
_a = 3
# 不能以数字开头
2_a = 4 # 会报错
# 不能是保留字
if = 2 # 会报错
# 严格区分大小写,以下是两个不同的标识符
b = 1
B = 1
1.2.2 变量的定义和使用
我们可以理解变量为:在内存中带有标签的小盒子,变量的使用规则为:变量名 = 值,其中=被我们称为赋值运算符,它的作用为:把=右边的值付给左边的变量名,变量名的命名就是我们上述的标识符的命名规则:
标识符可由:字母、数字、下划线_,以上三部分任意排列组合去组成
不能以数字开头
不能是保留字
标识符是严格区分大小写的
如下就是一个简单的变量的赋值:
❗️ 注:下面的代码使用了 print() 函数,后续会有讲解,读者这里只需要知道 print() 的含义是输出的意思即可
name = '辰chen' # 把字符串'辰chen'赋值给 name
print(name)
运行结果就是输出了辰chen,当然我们还可以有很多的赋值(比如把一个整数赋值给一个变量,亦或者把一个小数赋值给一个变量),下面我们再学习了 Python 中的数据类型后读者可以自行尝试
关于变量名,虽然我们可以任意的去取名,但我们尽量在命名的时候做到见名知意,比如我们如果用一个变量记录最终的答案结果的话,我们建议命名为res,即单词result的缩写,如上代码,在表示一个人的名字的时候,我们建议使用name去当变量名
如果对同一个变量连续的赋值,那么我们最终输出的时候只会输出最后一次赋值的结果:
a = 2
a = 3
a = 5
print(a)
即对于如上代码,我们对于变量a依次赋值为2 3 5,最终我们输出a的值只有5,读者可以自行验证
1.3 Python中的数据类型
1.3.1 常用的数据类型
我们常用的数据类型如下表格所示,接下来我们来一一去讲解这些数据类型的使用方法
| 数据类型 | 表达 | 例子 |
|---|---|---|
| 整数类型 | int | 666 |
| 浮点数类型 | float | 3.1415926 |
| 布尔类型 | bool | True |
| 字符串类型 | str | ‘hello world’ |
1.3.2 type() 函数的使用
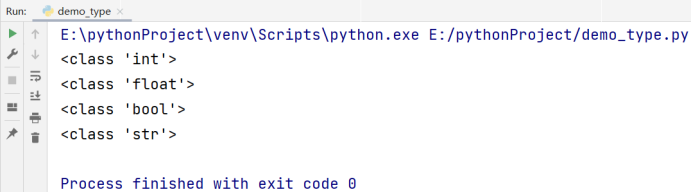
我们在 1.3.1 中给大家罗列出来了在 Python 中常用的数据类型,显然对于每一个不同的数据类型都有只属于它的用法和用处,所以在使用之前我们需要判断题目中给出的到底是什么样的数据类型,为此,我们可以使用 type() 函数,去让计算机告诉我们到底是什么数据类型:type()函数具有查看类型的作用,直接把我们想查看的东西的类型放入()即可:
❗️ 注:下面的代码使用了 print() 函数,后续会有讲解,读者这里只需要知道 print() 的含义是输出的意思即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 14:30
# 欢迎大家关注AIoT相关博客~
# type() 函数的用法
# 用print() 函数输出我们的数据类型
print(type(666))
print(type(3.1415926))
print(type(True))
print(type('hello world'))
1.3.3 整数类型
🚩整数类型的英文名为:integer,简写为int,包括:正整数,负整数,0
❗️ 注:如果你学过 C语言/C++,在C/C++中整数int是有范围的,只能表示-231 - 231-1,超过这个范围的数是无法表示的,但是在 Python 中没有这个问题,Python 中的整数范围可以理解为是无限大的,这里多说一句,如果读者打算法竞赛,那么在处理高精度的问题的时候,C++只能开数组去处理,具体操作可见本人博客:高精度运算,亦可以直接使用 Python
下面通过一个代码去演示:
❗️ 注:下面的代码使用了 print() 函数,后续会有讲解,读者这里只需要知道 print() 的含义是输出的意思即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 14:47
# 欢迎大家关注AIoT相关博客~
a = 1
b = -1
c = 0
print(a)
print(type(a))
print(b)
print(type(b))
print(c)
print(type(c))
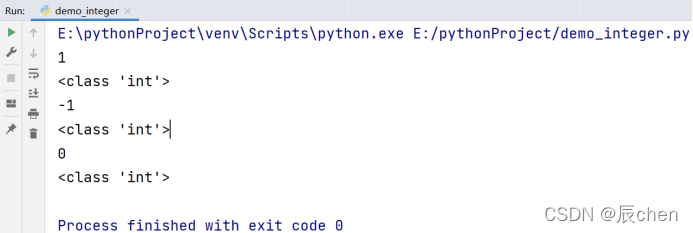
我们的 PyCharm 默认是十进制,但是我们的整数是不仅仅有十进制,常用的还有二进制,八进制,十六进制,我们可以按照下述代码表示:
| 整数的进制 |
|---|
| 进制 | 基本数 | 逢几进一 | 表示形式 |
|---|---|---|---|
| 十进制 | 0,1,2,3,4,5,6,7,8,9 | 10 | 666 |
| 二进制 | 0,1 | 2 | 0b1010011010 |
| 八进制 | 0,1,2,3,4,5,6,7 | 8 | 0o1232 |
| 十六进制 | 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F | 16 | 0x29A |
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 14:47
# 欢迎大家关注AIoT相关博客~
# 十进制
print(666)
# 二进制
print(0b1010011010)
# 八进制
print(0o1232)
# 十六进制
print(0x29A)
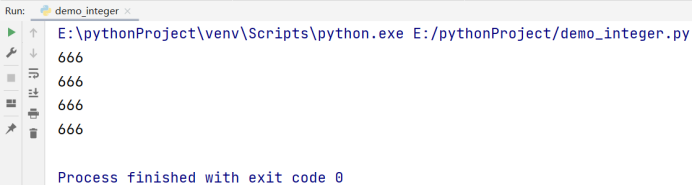
1.3.4 浮点数类型
🚩浮点数由整数部分和小数部分组成,比如:3.14 就是一个浮点数,我们用float去表示浮点数,关于浮点数的计算我们必须知道的第一个点就是:浮点数的存储是不精准的,下面我们拿代码去说明:
❗️ 注:下面的代码使用了 print() 函数,后续会有讲解,读者这里只需要知道 print() 的含义是输出的意思即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 16:34
# 欢迎大家关注AIoT相关博客~
print(1.1 + 2.2)

神奇的事情发生了,答案居然不等于3.3,这是因为计算机底层实现是利用二进制去实现的(感兴趣的同学可以简单了解 *1.4 二进制与字符编码),利用二进制去存储浮点数的时候是不精准的,但并不是所有的数都是不精准的,如下述代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 16:34
# 欢迎大家关注AIoT相关博客~
print(1.1 + 2.1)

所以,大家在这里不需要钻牛角尖,只需要知道,在进行浮点数的运算的时候,其值可能会有问题即可,当然,我们也可以准确的去计算,如下述代码:
❗️ 注:下述代码大家只要看就可以,不需要掌握
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 16:34
# 欢迎大家关注AIoT相关博客~
from decimal import Decimal
print(Decimal('1.1') + Decimal('2.2'))

1.3.5 布尔类型
🚩布尔类型的英文为:boolean,英文缩写为bool,布尔类型用来表示:真(True)和假(False),下面用代码去演示:
❗️ 注:下面的代码使用了 print() 函数,后续会有讲解,读者这里只需要知道 print() 的含义是输出的意思即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 18:39
# 欢迎大家关注AIoT相关博客~
a = True
b = False
print(a)
print(type(a))
print(b)
print(type(b))
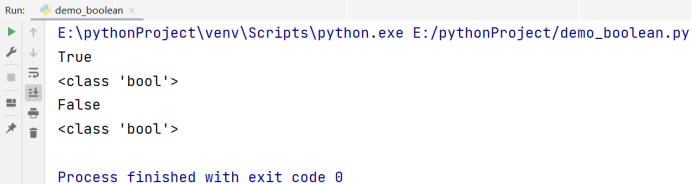
1.3.6 简单字符串介绍
🚩在 Python 中,我们把两个单引号,或者两个双引号,亦或者是两个三引号中的东西称为字符串,注意,单引号和双引号的内容只能在一行表示,三引号的话可以写在多行,字符串的类型我们写为:str,如下均是字符串:
# 单引号
'1'
'123'
# 双引号
"a"
"abcd"
# 三引号
'''我是辰chen
辰chen 666'''
你可以简单的把字符串理解成为我们汉语中的一句话,目前理解到这种程度就已经足够啦,字符串是 Python 基础语法中的一个重点,后续会再仔细的去介绍字符串
*1.4 二进制与字符编码
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 计算机为什么能够认识我呢?
其实,我们的计算机没有我们想象中的那般智能,计算机其实只能认识0和1,那么对于0和1这两个字符,显然是只能表示两种状态的,可是我们的状态成千上万,显然是不够的,怎么去进一步包涵所有的状态呢?
答案就是:加位,如果只用一位数,那么显然只能是0和1这两种情况了,那么如果我们用两位数的话,就可以表示出:00,01,10,11四种不同的状态,那么如果我们用八位数去表示的话,就会有28即256种不同的状态,这就形成了我们的 ASCII 码表:
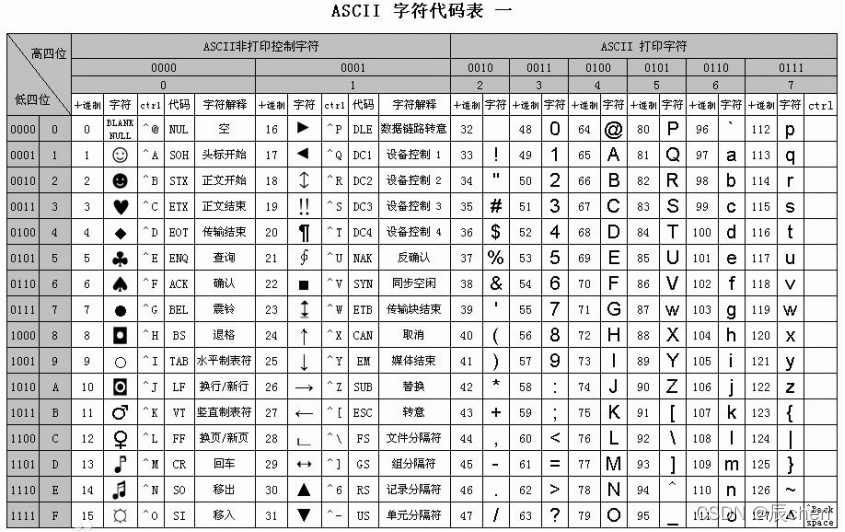
❗️ 这里多说一句:我们用 8 位就可以表示出来 256 种不同的状态,在 算法竞赛中,这样的思想叫做状态压缩,动态规划中常用的一种思想就是 状态压缩DP,对算法竞赛感兴趣的同学可以看我写过的一些算法文章,如:状态压缩DP
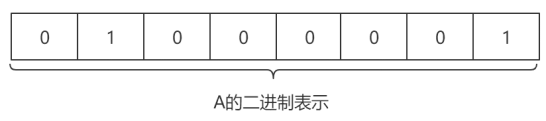
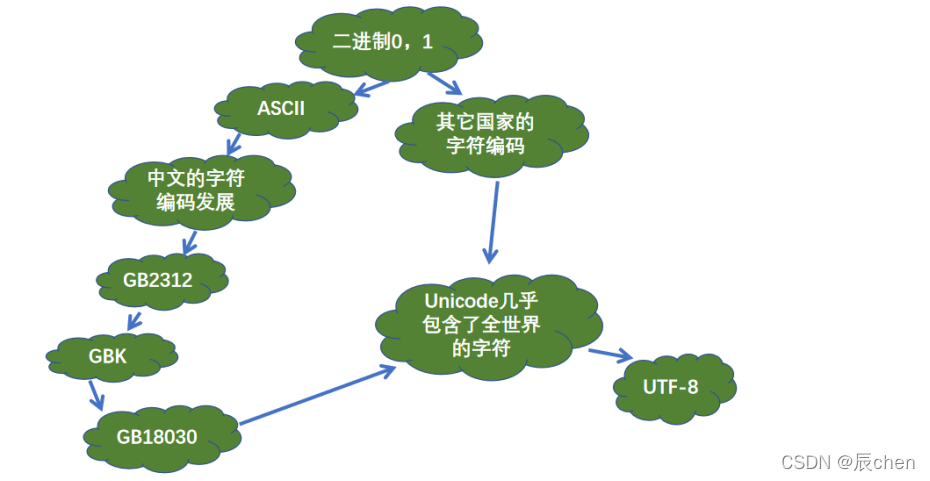
显然对于现实生活中,256个状态也是完全不够用的,至今,汉字已有90000多个,每一个汉字都对应一种状态,那么我们现在如何去把汉字甚至是各个国家的语言都成功的表达翻译到计算机中的呢?对此,世界上有如下图所示的规定:
1.5 类型转换
| 函数 | 作用 | 注意事项 | 举例 |
|---|---|---|---|
| int() | 将其他数据类型转为整型 | 文字和浮点型字符串不能转,浮点型转整型采用去尾法 | int(‘666’) |
| str() | 将其他数据类型转为字符串类型 | str(666) | |
| float() | 将其他数据类型转为浮点型 | 带文字的字符串不能转,整型转浮点型末尾补.0 | float(666) |
下面用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 19:17
# 欢迎大家关注AIoT相关博客~
# int()函数的使用:
print(int(19.8))
print(int(True))
# print(int('hello world')) 这行代码会报错
# float()函数的使用:
print(float(74))
print(float('12.8'))
# print(float('hello 辰chen')) 这行代码会报错
# str()函数的使用:
print(str(666))
print(type(str(666)))
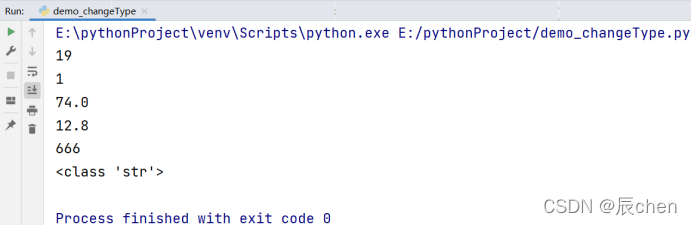
这里有一个小细节,我们发现 int(True) 的结果是 1,读者可以下去自己实践一下 int(False) 的结果
🚩这里还有一个特殊的小知识点,就是我们的bool() 函数,它的用法和上面所介绍的强制转换其实不一样,并不是把一个东西的值强制转换为 bool 类型,它的作用是获取对象的 bool 值,在 Python 中一切皆对象,所有的对象都有一个布尔值,我们可以采用 bool() 函数去获取 bool 值,使用方法就是把想求的对象放到 () 中即可,下面还是通过代码去演示一下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 11:59
# 欢迎大家关注AIoT相关博客~
'''
我们规定以下对象的bool值为False:
False
0
None
以下的对象bool值也为False,我们后续会逐个去讲解
现在不需要掌握:
空字符串
空列表
空元组
空字典
空集合
'''
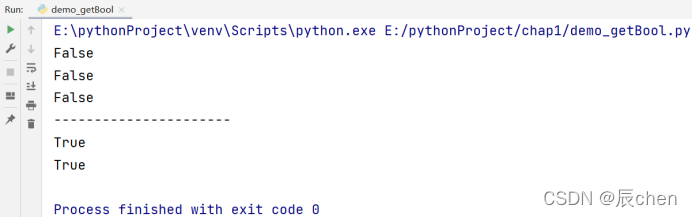
# 下面代码只演示我们学过的对象的bool
print(bool(None))
print(bool(0))
print(bool(False))
print('----------------------')
print(bool(666))
print(bool(-1))
2.和Python来一场对话
2.1 print()函数
🚩print()函数为输出函数,它的作用为将我们想展示的东西或要求的东西在标准的控制台上显示,标准控制台就是下图所示的区域:
接下来我们由几个问题作为入口来讲解 print()函数:
🎯问题一:print()函数可以输出哪些内容?
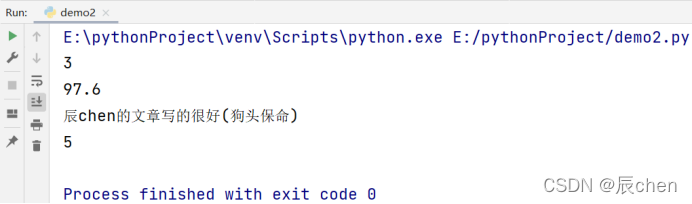
print()函数可以1️⃣输出数字;2️⃣输出字符串;3️⃣输出含有运算符的表达式:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 16:20
# 欢迎大家关注AIoT相关博客~
# 可以输出数字
print(3)
print(97.6)
# 可以输出字符串
print('辰chen的文章写的很好(狗头保命)')
# 可以输出含有运算符的表达式
print(2 + 3)
❗️ 这时有同学提出来了:你怎么保证你输出的3和5不是字符串格式而是属于数字呢?
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 16:20
# 欢迎大家关注AIoT相关博客~
# 可以输出数字
print(3)
print(97.6)
# 可以输出字符串
print('辰chen的文章写的很好(狗头保命)')
# 可以输出含有运算符的表达式
print(2 + 3)
# 使用type() 函数查看数据类型:
print(type(3))
print(type(97.6))
print(type('辰chen的文章写的很好(狗头保命)'))
print(type(2 + 3))
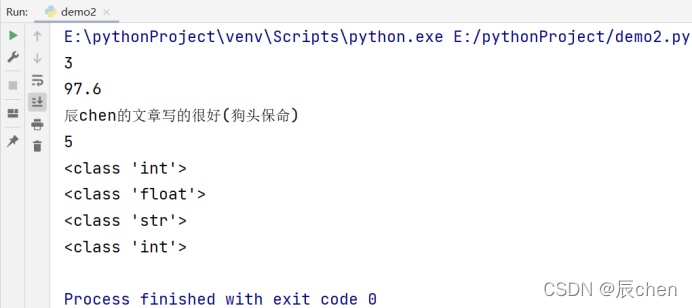
可以看出,结果分别对应类型:int float str int
📝通过上述代码的分析,我们可以知道,首先,print() 函数不会改变我们传入的数据类型,如传入 3 打印后的结果仍然是 3,数据类型为int,同时,可以直接在()中传入一个运算符表达式,如传入 2 + 3,会打印出 5,数据类型为int
🎯问题二:print()函数可以将内容输出的目的地有哪些?
可以输出的目的地有:1️⃣控制台;2️⃣文件
这里输出到控制台就不再进行赘述了,这里来讲解一下怎么把我们的结果输出到我们的目标文件之中:
❗️ 注:这一部分内容只需要现在看一下即可,后续会对文件读写有详细的讲解,这里只需要知道 print() 函数可以输出到一个文件之中
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 16:56
# 欢迎大家关注AIoT相关博客~
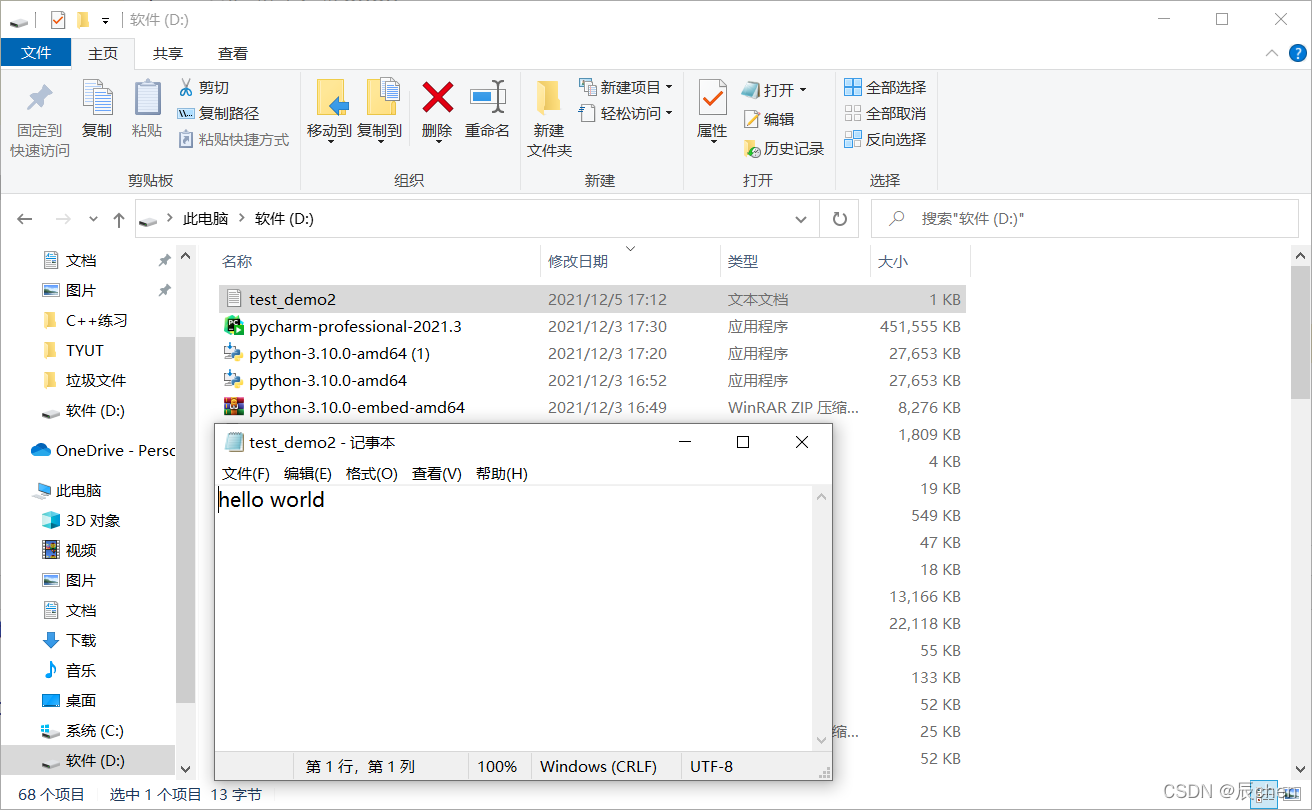
# 将文件输出到文件之中:
fp = open('D:/test_demo2.txt', 'a+') # a指的是以读写的方式打开文件
# 如果文件不存在,则创建文件,如果文件存在,就在原有文件的基础上追加
print('hello world', file = fp)
fp.close()
然后我们去我们的 D盘 查找一下我们刚创建的文件,结果如下图所示:Congratulation~🎈
🎯问题三:print()函数的输出形式
从上述代码中我们其实可以看出来一个东西,print函数其实是在输出完我们要输出的东西之后会输出一个换行,那么我们是否能改变print()的输出格式呢?比如不希望它进行换行,而是希望输出完之后空一格:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 17:29
# 欢迎大家关注AIoT相关博客~
print('hello','world','hello','python')

我们会发现,上述代码实际上的操作就是以,为分界线,依次输出用,隔开的东西,故我们用type()进行检测数据类型的时候也可以写成:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 17:29
# 欢迎大家关注AIoT相关博客~
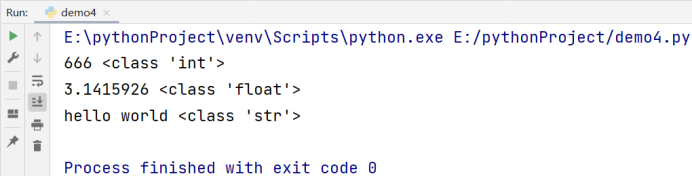
print(666, type(666))
print(3.1415926, type(3.1415926))
print('hello world', type('hello world'))
我们不仅可以按上述中改变 print() 的输出格式,还有如下方法,我们可以自定义输出完目标后输出的东西:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 17:29
# 欢迎大家关注AIoT相关博客~
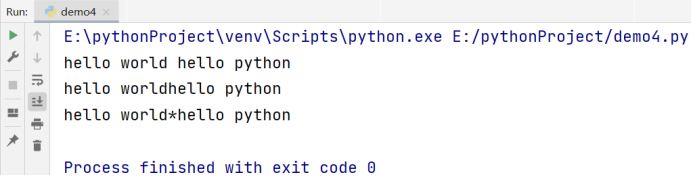
print('hello world', end = ' ')
print('hello python')
print('hello world', end = '')
print('hello python')
print('hello world', end = '*')
print('hello python')
2.2 转义字符
接下来我们由几个问题作为入口来讲解转义字符:
🎯问题一:什么是转义字符?
转义字符其实就是反斜杠+想要实现的转义功能首字母,举几个常见的例子:
| 要表示的字符 | 转义字符 | 备注 |
|---|---|---|
| 换行 | \n | newline 光标移动到下一行的开头 |
| 回车 | \r | return 光标移动到本行的开头 |
| 水平制表符 | \t | 光标移动到下一组4个空格的开始处 |
| 退格 | \b | 键盘上的backspace键,回退一格 |
❗️ 注意这个水平制表符的备注:下一组4个空格的开始处,拿hello world举例,第一组4个空格对应为hell,第二组对应o wo,第三组对应rld(缺一),故如果我们写成hello world\t,其实无非就是在末尾加了一格空格。
❗️ 回车其实就是把回车之前的字符串全部清除掉
下面用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 19:31
# 欢迎大家关注AIoT相关博客~
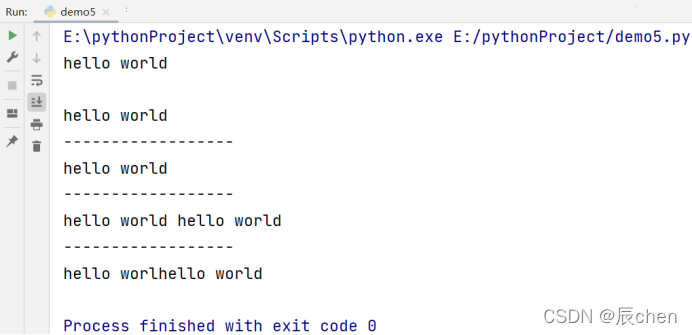
# 使用\n换行:
print('hello world\n')
print('hello world')
print('------------------')
# 使用\r回车:
print('hello world\rhello world')
print('------------------')
# 使用\t创造四个空格:
print('hello world\thello world')
print('------------------')
# 使用\b回退:
print('hello world\bhello world')
🎯问题二:为什么需要转义字符?
当我们的字符串中含有 换行,水平制表,退格,回车 等无法直接表示的特殊字符的时候,就可以使用我们的转义字符
亦或者是当我们的字符串中想出现 \,'," 这些有特殊作用的字符的时候,也可以使用转义字符:
| 要表示的字符 | 转义字符 |
|---|---|
| 反斜杠 | \\ |
| 单引号 | \’ |
| 双引号 | \" |
下面用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/5 21:23
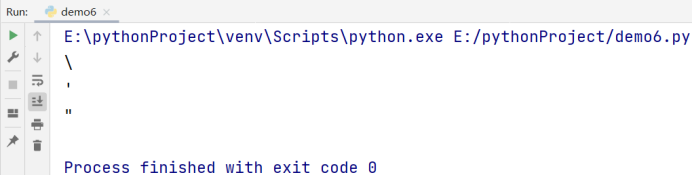
# 欢迎大家关注AIoT相关博客~
print('\\')
print('\'')
print('\"')
2.3 input()函数
我们知道,光有输出是不够的,要想实现真正意义上的人机交互,我们还需要向我们的计算机去输入一些东西,想要实现输入的功能,就设计了我们的 input() 函数
🚩input() 的作用:接受来自用户的输入,注意这里不管输入的是什么,计算机都会自动把它转换为字符串类型,我们可以把输入的字符串用一个变量去接受,具体代码如下图所示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 20:06
# 欢迎大家关注AIoT相关博客~
f = input()
print(f, type(f))
点击运行后会发现我们的控制台好像卡在了这里,这是因为计算机在等待着我们的输入,我们把光标移至控制台,输入我们想输入的东西

比如我们输入:请给辰chen一键三连,然后按下键盘上的回车键,会显示:

那么如果我们在input()类似print()一样输入一段字符串会发生什么呢:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 20:06
# 欢迎大家关注AIoT相关博客~
f = input('辰chen希望大家多多点赞支持一下他:')
print(f, type(f))

我们会发现,其实 input() 在这里还充当了一个 print() 的作用,不同的是,print() 默认输出完之后换行,而 input() 不会换行,接下来和最开始的那个代码一样,我们可以输入一个字符串:

⭐️ 有读者可能会有这样的疑问:无论输入什么都会转为字符串的话,那么我想把它当成数字去使用应该怎么办呢?
这就要用到我们在 1.5 类型转换 的知识啦
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 20:06
# 欢迎大家关注AIoT相关博客~
f = int(input())
print(f, type(f))

❗️ 注:如果我们要输入多个数据,我们用回车把他们分隔开,比如我们要求输出两个整数,那么我们在控制台的输入为:

绝对不可以写成如下的形式:

其实上面两个写法都是正确的,但是就目前为止,写成第二种是错误的形式,等到后面讲到字符串的时候,你就会知道第二种写法如何用代码进行实现了
2.4 Python中的运算符
2.4.1 算数运算符
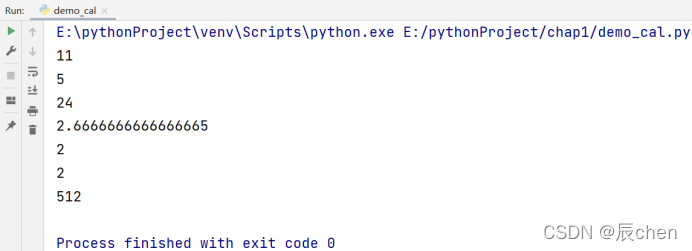
我们最常用的运算符莫过于加减乘除了,在 Python 中表示的算数运算符有:加(+)、减(-)、乘(*)、除(/)、整除(//)、取余(%)、幂(**)。整除的意思就是舍去小数位,取余的意思就是取两个数相除的余数,幂就是求a的b次幂。下面,我们用代码去一一介绍这些运算符:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 21:22
# 欢迎大家关注AIoT相关博客~
a = 8
b = 3
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a // b)
print(a % b)
print(a ** b)
2.4.2 赋值运算符
其实在之前的篇目中我们就用过赋值运算符,这里相当于是给大家总结一下赋值运算符的用法:不同于我们在以往数学中的从左往右进行运算,赋值运算符的执行顺序其实是 从右往左,而且赋值运算符支持链式赋值如:a = b = c = 20,其作用为同时给a b c均赋值20,那么读者可能有这样的疑惑:我如果想把a b c 分别赋给不同的值,这应该如何操作呢?比如我们想给a b c分别赋值10 20 30,我们当然可以写成三行如:
a = 10
b = 20
c = 30
我们还可以用这样的写法:a, b, c = 10, 20, 30,下面附上代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 22:10
# 欢迎大家关注AIoT相关博客~
a = b = c = 20
print(a, b, c)
a, b, c = 10, 20, 30
print(a, b, c)

这里我们还可以进行简写,以后的代码我们经常见到如下的简写:
| 简写 | 原型 |
|---|---|
| a -= b | a = a - b |
| a += b | a = a + b |
| a *= b | a = a * b |
| a /= b | a = a / b |
| a //= b | a = a // b |
| a %= b | a = a % b |
2.4.3 比较运算符
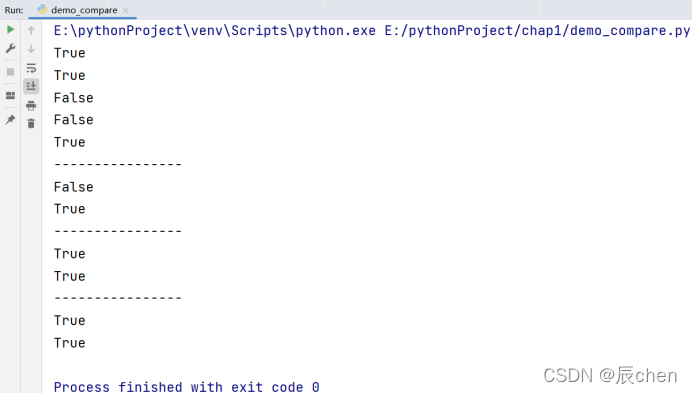
比较运算符有以下几种需要我们掌握:<,>,<=,>=,==,!= ,is,not is,比较运算符其实就是对变量或者表达式的结果进行大小、真假的比较,比较得到的结果为 bool 类型。下面我们通过代码去展示它们的用途:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 23:43
# 欢迎大家关注AIoT相关博客~
a, b = 1, 2
print(a < b)
print(a <= b)
print(a > b)
print(a == b)
print(a != b)
print('----------------')
flag1, flag2 = True, False
print(flag1 == flag2)
print(flag1 != flag2)
print('----------------')
a, b, c= 1, 2, 3
print(a < b < c)
# 等价于:
print(a<b and b<c)
print('----------------')
a = 10
b = 20
c = 10
print(a is c)
print(a is not b)
# is 和 is not 我们可以理解成比较的是在内存地址是否相等
# 注:不可以理解成如果两个对象表示的值一样,对应内存地址就相等
# is 和 is not 用的并不多,大家不必钻牛角尖
2.4.4 布尔运算符
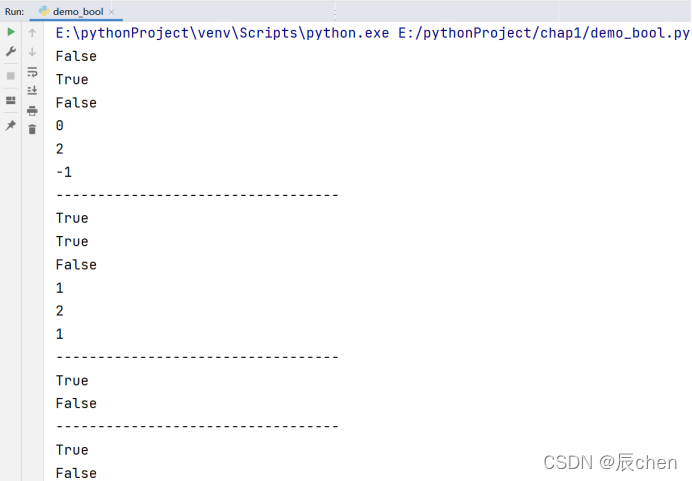
我们的布尔运算符有以下几种需要我们掌握:and,or,not,in,not in.其实我们通过它的名字就可以知道它的含义,and就是且,or就是或,not就是否定,in就是在,not in表示不在,下面我们还是通过代码去展示它们的用途:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 22:30
# 欢迎大家关注AIoT相关博客~
'''
and 的用法:
1.如果and左右为bool类型:
只有当两边同时为True,执行and操作结果才为True
如果两边只要有一边为False,操作结果就为False
2.如果两边为int类型:
两边只有有一边等于0,操作结果就为0
如果两边都不为0,如 1 and 2,操作结果为and后面的数:2
'''
flag1,flag2,flag3,flag4 = True, False, True, False
print(flag1 and flag2) # True and False
print(flag1 and flag3) # True and True
print(flag2 and flag4) # False and False
a, b, c, d = 0, 1, 2, -1
print(a and b) # 0 and 1
print(b and c) # 1 and 2
print(b and d) # 1 and -1
print('----------------------------------')
'''
or 的用法:
1.如果or左右为bool类型:
只有当两边同时为False,执行or操作结果才为False
如果两边只要有一边为True,操作结果就为True
2.如果两边为int类型:
只有两边同时等于0,执行or操作结果才为0
如果左边不为0,如 1 or 0,操作结果为1
如果右边不为0,如 0 or 2,操作结果为2
如果两边都不为0,如 1 or 2,那么操作结果为1(左边的数)
从上述中可以看出,我们可以理解or为只要碰到了第一个为True或不为0的数的时候就会停止后续的判断
我们把这种性质称为惰性求值的特点
'''
flag1,flag2,flag3,flag4 = True, False, True, False
print(flag1 or flag2) # True or False
print(flag1 or flag3) # True or True
print(flag2 or flag4) # False or False
a, b, c, d = 0, 1, 2, -1
print(a or b) # 0 or 1
print(c or b) # 2 or 1
print(b or d) # 1 or -1
print('----------------------------------')
'''
or 的用法:
1.如果not后接bool类型:
直接取反,True取反为False,False取反为True
2.如果not后接int类型:
如果int类型的数为0,输出结果为True
如果int类型的数为1,输出结果为False
'''
print(not 0)
print(not 666)
print('----------------------------------')
'''
in 和 not in 的用法:
1.in表示判断我们的目标串是否在我们的模板串中
如果在,返回True
如果不在,返回False
2.not in表示判断我们的目标串是否不在我们的模板串中
如果不在,返回False
如果在,返回True
'''
s1 = 'o' #这里的s1就是目标串
s2 = 'hello world' #这里的s2就是模板串
print(s1 in s2) #判断s1 在 s2 中
print(s1 not in s2) #判断s1 不在 s2中
2.4.5 位运算符
❗️ 注:所有的位运算都是先把数转为二进制之后的运算
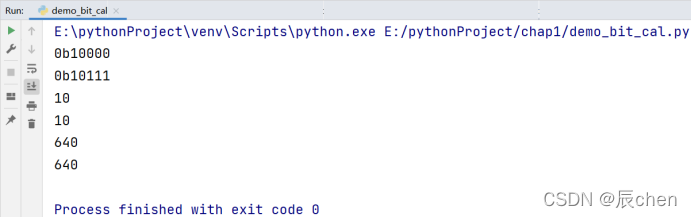
位运算包涵运算符:位与(&),位或(|),左移运算符(<<),右移运算符(>>)
| 运算符 | 作用 |
|---|---|
| & | 对应数位都是1,结果数位才是1,否则为0 |
| | | 对应数位都是0,结果数位才是0,否则为1 |
| << | 相当于 * 2k |
| >> | 相当于 // 2k |
这里补充一个函数:bin(),其函数的作用为,把一个十进制的数放入()中,bin()函数会把这个数转为二进制的数,二进制的数以0b开头,这一点我们在 1.Python的七十二变—*1.4 二进制与字符编码 中有提到,下面来用代码进行演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 23:24
# 欢迎大家关注AIoT相关博客~
a = 0b10010
b = 0b10101
print(bin(a & b)) # 二进制一位一位比较,只有同时为1才为1
print(bin(a | b)) # 二进制一位一位比较,只有同时为0才为0
c = 80
print(c // 2 ** 3) # ** 的运算优先级高于 *
print(c >> 3)
print(c * 2 ** 3) # ** 的运算优先级高于 *
print(c << 3)
2.4.6 运算符的优先级
我们在之前学习的时候都听过一句话:先乘除后加减,这的意思就是乘除的优先级是大于加减的,我们上述提到的所有运算符也都有它们的优先级顺序,我们按 优先级从高到低进行排序,排序结果如下:
** *,/,//,% +,- <<,>> & | <,>,==,!=,<=,>= and or =
当然,这不是绝对的,我们在以前同样学过,当我们遇到(),应该先算()里面的,这一点在 Python 代码中同样适用,下面给代码演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/6 23:17
# 欢迎大家关注AIoT相关博客~
print(3 * (2 + 3))

*2.4.7 关于 ++ 和 –
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 如果你学过 C/C++,你知道,在 C/C++中有一种常用的运算符,那就是 ++和–运算符,特此声明:在 Python 语言中不存在 ++运算符和 --运算符,如果你没有学过 C/C++,那么你可以忽略本小节.
3.下一站是何方?
3.1 顺序结构
🚩抛开代码而言,我们在读文章的时候,我们的顺序是怎样的呢?是不是从上到下去读的呢,在我们的 Python 程序中其实也是这么一个道理,我们的 PyCharm 在翻译 Python 语言的时候的顺序也是从上至下的顺序:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 11:50
# 欢迎大家关注AIoT相关博客~
print('我是辰chen')
print('在这里求一个一键三连~')
print('谢谢各位啦')
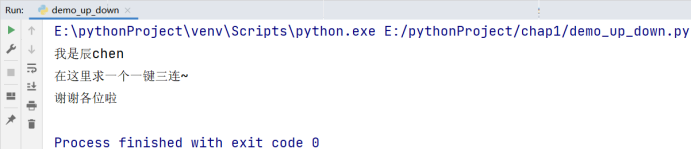
可以看到,在控制台上输出的顺序是对应我们 Python 代码中的上至下的顺序
3.2 选择结构
在 Python 这片广袤无边的国度,我们会面临诸多的选择,究竟下一站在哪?我们在 Python 中遇到交叉路口的时候,究竟哪一条道路才是阳光大道呢?下面,就让我们介绍选择结构:
3.2.1 单分支选择结构
🚩我们的日常生活中经常会说这样的句子:如果今天不下雨,那么我就出去玩;如果明天放假,那么我明天就睡一个懒觉,这其实对应了一个流程图:
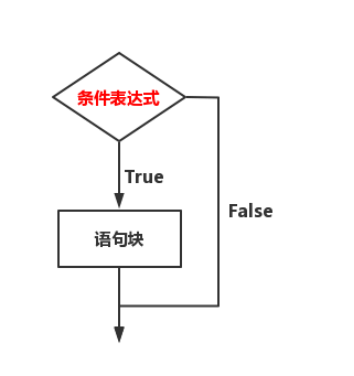
我们把上面的流程图变现为 Python 代码::
if 条件表达式:
语句块
单分支选择结构语法如上述所示,其中条件表达式后面的:是绝对不可以省略的,:表示的是语句块的开始,并且语句块必须进行相应的缩进(一个Tab键的距离【4个空格】),代码所表达的意思就是,如果 语句表达式成立【bool值为True】,就执行语句块的内容
3.2.2 双分支选择结构
🚩我们的日常生活中经常会说这样的句子:如果今天不下雨,那么我就出去玩;否则,我就待在家;如果明天放假,那么我明天就睡一个懒觉,否则我就不得不按时去上班。这其实对应了一个流程图:
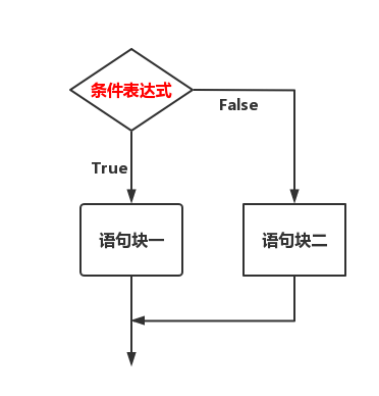
我们把上面的流程图变现为 Python 代码::
if 条件表达式:
语句块一
else :
语句块二
双分支选择结构语法如上述所示,其中条件表达式后面的:以及else后面的:是绝对不可以省略的,:表示的是语句块的开始,并且语句块必须进行相应的缩进(一个Tab键的距离【4个空格】),代码所表达的意思是,如果语句表达式成立【bool值为True】,就执行语句块一后面的内容,否则,就执行语句块二后面的内容
3.2.3 多分支选择结构
🚩我们按照一个实例去讲解多分支结构,比如有题目有如下诉求:输入你的分数,如果你的分数在90分以上,输出 A,如果你的分数在 80 ~ 89,输出 B,如果你的分数在 70 ~ 79,输出C,如果你的分数在 60 ~ 69,输出 D,否则输出 E,这个题目,你会发现,如果我们只有一个 if 是显然不够用的,我们需要多个 if,那么你可能会写出如下代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 18:26
# 欢迎大家关注AIoT相关博客~
score = int(input())
if score >= 90:
print('A')
if 80 <= score < 90:
print('B')
if 70 <= score < 80:
print('C')
if 60 <= score < 70:
print('D')
else:
print('E')
对么?读者可以自己思考一下
答案是不对的,我们不妨运行输入一个数字:90,按照我们题目所规定的的,应该输出:A;我来运行一下:
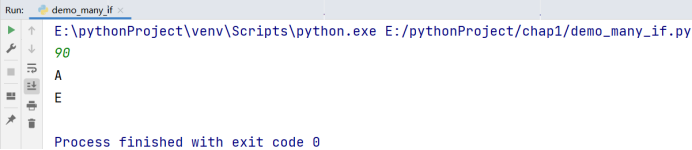
显然是不对的,问题就出在 if 和 else 上,if 和 else 是一一对应的,else 仅代表与它最近的一个 if 不成立的时候,会执行 else 语句,故对于上述代码,只要我们输入的分数不在 60 ~ 69,就睡输出 E,为此,我们介绍一个新的语句:elif,我们用代码去介绍:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 18:26
# 欢迎大家关注AIoT相关博客~
score = int(input())
if score >= 90:
print('A')
elif 80 <= score < 90:
print('B')
elif 70 <= score < 80:
print('C')
elif 60 <= score < 70:
print('D')
else:
print('E')
图示表达如下:
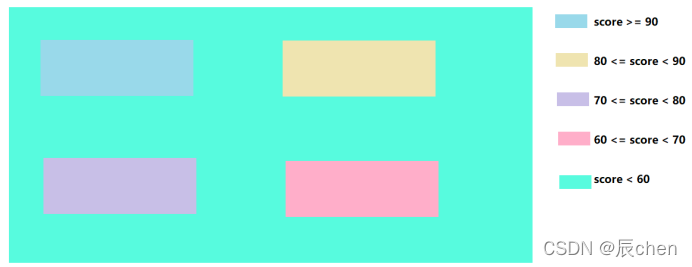
多分支选择结构的语法如下:
if 条件表达式1:
语句块1
elif 条件表达式2:
语句块2
elif 条件表达式3:
语句块3
...
else:
语句块n
3.2.4 选择结构的嵌套
选择结构的嵌套语法格式如下:
if 条件表达式1:
语句块1
if 条件表达式2:
语句块2
else:
语句块3
else:
if 表达式4:
语句块4
这里还是和 3.2.3 多分支选择结构 一样用例子去讲解,我们需要输入一个百分制的数字,如果输入的数字不合法,就输出:输入的数据不合法,否则的话,我们输出一个对该分数的评级:如果你的分数在90分以上,输出 A,如果你的分数在 80 ~ 89,输出 B,如果你的分数在 70 ~ 79,输出C,如果你的分数在 60 ~ 69,输出 D,否则输出 E。表示代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 19:18
# 欢迎大家关注AIoT相关博客~
score = int(input())
if score > 100 or score < 0:
print('输入的数据不合法')
else:
if score >= 90:
print('A')
elif 80 <= score < 90:
print('B')
elif 70 <= score < 80:
print('C')
elif 60 <= score < 70:
print('D')
else:
print('E')
*3.2.5 条件表达式
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 所谓的条件表达式,其实就是对 if else 的一个简写,其语法结构如下所示:
a if 判断条件 else b
# 如果判断条件为 True,那么会返回 a 的值,否则会返回 b 的值
下面还是通过一个例子去说明:比如我们要输入两个整数 a 和 b,如果 a > b 则输出 a,否则输出 b,写出 Python 代码如下,首先是不采用条件表达式的代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 19:41
# 欢迎大家关注AIoT相关博客~
a = int(input())
b = int(input())
if a > b:
print(a)
else:
print(b)
我们说条件表达式其实就是对 if else 的一个简写,那么简写后的代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 19:41
# 欢迎大家关注AIoT相关博客~
a = int(input())
b = int(input())
print(a if a > b else b)
*3.2.6 pass语句
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ pass 语句其实就是一个占位符,我们知道,我们的 PyCharm 是在我们写的过程中实时给我们检查代码是否有错误的,如果当我们在写 if 的时候还没有构思好 if 后面的执行语句,又不想看到代码报错,我们可以先用 pass 顶替执行语句,这样代码就不会报错,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/7 20:12
# 欢迎大家关注AIoT相关博客~
a = int(input())
if a < 10:
pass
else:
pass
我们可以在如下情况下使用 pass:
1.if语句的执行语句
2.for循环的循环体
3.函数体的定义
⛲️ 现在我们只介绍了第一条,关于函数和循环后续会有专门的讲解
3.3 循环结构
3.3.1 range()函数
🚩我们在介绍循环结构之前,首先介绍一个函数:range(),这个函数的作用是可以用它来生成一个整数的序列,range() 函数的返回对象是一个迭代器对象 (这里无须知道什么是迭代器对象,知道range()函数可以产生一连串的整数序列即可),关于range() 函数,这里介绍其使用的三种方法:
| range的使用 | 具体解释说明 |
|---|---|
| range(strop) | 创造一个[0, stop)的整数序列,序列中相邻两数的差为1 |
| range(start, stop) | 创造一个[start, stop)的整数序列,序列中相邻两数的差为1 |
| range(start, stop, step) | 创造一个[start, stop)的整数序列,序列中相邻两数的差为step |
我们把序列中相邻两数之间的差称为:步长,注意以上的范围均是左闭右开型,下面我们用代码去讲解我们的range():
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 15:36
# 欢迎大家关注AIoT相关博客~
a = range(10)
print(a)

我们可以看到输出的结果为:range(0, 10),这就是所谓的迭代器,我们知道,range返回的应该是一连串的数,但我们不可能把这一连串的数全部存到一个变量a之中,故我们可以调用 list(),就可以查看我们的rang()产生的这一连串的数字,关于 list(),后续会重点进行讲解,读者此时把它理解成为一个可以把 range() 中产生的数全部显示出来即可:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 15:36
# 欢迎大家关注AIoT相关博客~
# range() 的第一种用法: range(stop)
a = range(10)
print(list(a))
# range() 的第二种用法: range(start, stop)
b = range(5, 10)
print(list(b))
# range() 的第三种用法: range(start, stop, step)
c = range(2, 10, 2)
print(list(c))
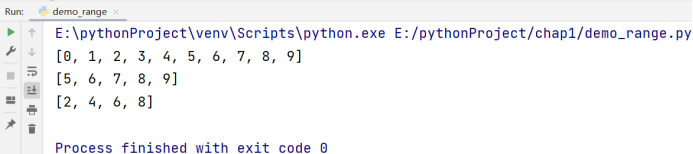
我们还可以使用 2.4.4 布尔运算符 中所讲过的 in 和 not in 去判断序列中是否存在我们规定的整数,代码如下:
print(1 in range(1, 10, 2))
print(2 not in range(1, 10, 2))
这里再来介绍一下 range() 的优点,我们知道,我们在创建变量的时候,对应的是创造的过程,一旦有东西被创造出来了,那么它一定是占用了一定的资源空间的,我们人类的出生占用的是地球的资源和空间,那么一个变量创造就会占用计算机内存的空间,故如果我们想要创造一个 [10, 100) 这个范围内的所有偶数的话,我们可以开辟很多个变量,然后每一个变量都对应一个值,这显然会占用很大的内存空间,我们还可以采用 range() 函数,我们在用a = range(10, 100, 2)的时候,相当于是创造了一个 range() 的迭代器,或者你可以理解成,我们创造了 [10, 100) 内的所有偶数的一个压缩文件,并用 a 指向这个文件,我们的压缩文件其实只是存储了start, stop, step 三个值,并没有存储所有的偶数,对应到这个例子之中相当于我们在进行a = range(10, 100, 2)这个操作的时候,只存储了10, 100, 2这三个数,这样显然是比开一堆变量分别存储偶数是要省空间的,那么什么时候 “解压” 这个 range() 呢?当我们要用它的时候,才会对它 “解压”,就单独说存储而言,我们在调用 range() 函数的时候只存储了start stop step
3.3.2 while循环
🚩什么是循环?反复的做着相同的任务就叫做循环,我们如果要打印一行hello world,那么只需要写出print('hello world')即可,但是如果我们要打印 10 行hello world 怎么办呢?你可能会回答到:在原有的代码基础上直接 Ctrl c + Ctrl v 九次不就好啦嘛,那么打印 100 次,1000 次呢?你可能会回答到:没有人会闲到打印 1000 次的 hello world,咳咳咳,你真是个小聪明😒 (不管你,反正我就要讲while循环!!!
while循环的语法结构如下:
while 条件表达式:
执行语句(循环体)
while循环的语法如上述所示,条件表达式后面的:不可以省略,它是循环开始的象征,并且执行语句必须进行相应的缩进(一个Tab键的距离【4个空格】),代码所表达的意思就是,如果 条件表达式成立【bool值为True】,就执行语句的内容
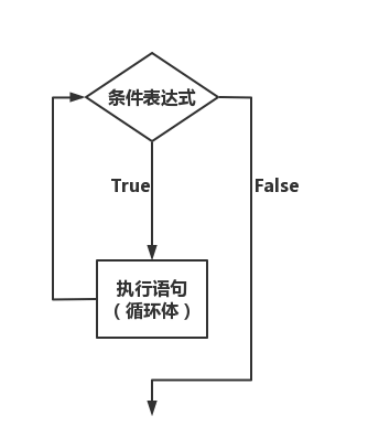
while 循环和 if 的区别:if 循环如果条件表达式为 True 的话,会执行一次执行语句,while 循环的话,当条件表达式为 True 后会执行一次执行语句,执行完成之后再次返回条件表达式,如果还为 True,那么会再次执行执行语句,直至条件表达式的值为 False,从这里我们也可以看出,如果执行语句执行了 n 次的话,那么我们的条件表达式会执行 n+1 次(最后一次执行表达式值为False,不执行执行语句而是退出循环)
为了强化大家对while的理解,这里讲一个例题:经典高斯求和问题:求出 1 + … + 100 的值
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 16:26
# 欢迎大家关注AIoT相关博客~
a, res = 1, 0
while a <= 100:
res += a
a += 1
print(res)
3.3.3 for循环
🚩for 循环和 while 循环的思想是一样的,可以理解成循环的又一种表达形式,for循环的语法结构如下:
for 自定义的变量 in 可迭代对象:
循环体
for循环的语法如上述所示,条件表达式后面的:不可以省略,它是循环开始的象征,并且执行语句必须进行相应的缩进(一个Tab键的距离【4个空格】),代码所表达的意思就是,如果 条件表达式成立【bool值为True】,就执行语句的内容
我们来依次介绍几个知识点:
可迭代对象:对于现在而言,我们的可迭代对象只有两个:range() 以及字符串,后续我们还会介绍更多的可迭代对象;
自定义的变量:说白了就是给起一个变量名,然后把可迭代对象里面的值依次逐个赋值给自定义的变量
遍历:我们以后会常见到遍历这个名词,它的意思就是我们依次从可迭代对象中取值,直至取值操作结束为止
下面我们来用代码去介绍for循环,还是和while循环中一样的问题:高斯求和
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 16:59
# 欢迎大家关注AIoT相关博客~
res = 0
for item in range(1, 101):
res += item
print(res)
根据代码去理解for循环:我们可以看到,对于上述代码,for循环所遍历的对象为:range(1, 101),即当我们遍历到 100 的时候,for 循环就会停止,在遍历的过程中,我们把 range 中产生的数依次赋值给了 item(当然我们可以任意去给它取名,一般习惯起名为 item),我们根据上述也可以看出,在我们计算 1 + … + 100 的时候,既可以使用while也可以使用for,故其实我们的 for 和 while 没有本质上的区别,它们之间是可以相互转换的
3.3.4 break,continue,else
🚩流程控制语句 break:break 就是打破的意思,那么我们把 break 和循环如果放在一起,直观上的翻译是:打破循环,什么叫打破循环呢:那就是退出循环的意思,我们的while循环正常退出循环的条件为条件表达式为 False,我们的for循环退出循环的条件为遍历完我们的可迭代对象,在这里,我们新增了一个退出循环体的条件:那就是如果循环运行过程中遇到了break,那么就直接退出循环,我们的break一般与if一起连用,即:
for 自定义的变量 in 可迭代对象:
语句1
...
if 条件表达式:
break
while 条件表达式:
语句1
...
if 条件表达式:
break
下面我们用一个例子去强化大家对 break 的理解:输出 100 ~ 200 之间第一个可以被 17 整除的数
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 17:24
# 欢迎大家关注AIoT相关博客~
for item in range(100, 201):
if item % 17 == 0:
print(item)
break
简单来说一下上述代码,因为我们只要求输出第一个可以被 17 整除的数,所以当我们输出完之后应该立刻退出循环,但是我们循环是遍历 100 ~ 200之间所有的整数,按照常理而言,我们只有遍历完这100个数之后才可以退出循环,故我们这里使用 break,在第一次输出之后立即退出循环
🚩流程控制语句 continue:continue的作用与 break 类似,都是能结束循环,只不过,执行 break 操作后,我们的循环相当于彻底结束,即跳出了循环,而我们的 continue 是结束本次循环,直接进入条判断,我们的break一般与if一起连用,即:
for 自定义的变量 in 可迭代对象:
语句1
...
if 条件表达式:
continue
语句k
...
while 条件表达式:
语句1
...
if 条件表达式:
continue
语句k
...
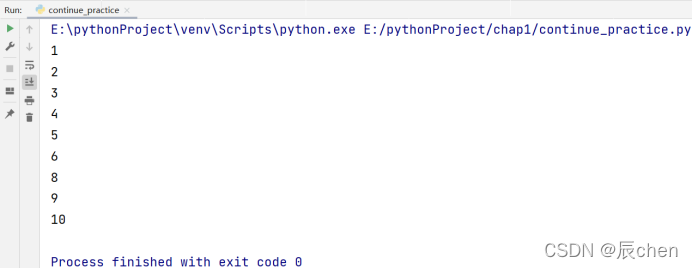
就拿上述语法结构来说,我们执行完continue语句之后,相当于本次循环中的语句k包括语句k往下的所有语句都不执行了,直接进入条件表达式或者可迭代对象,我们用一个例子去说明:我们输出 1 ~6, 8 ~ 10,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 18:13
# 欢迎大家关注AIoT相关博客~
for item in range(1, 11):
if item == 7:
continue
print(item)
🚩循环中的 else 语句: 不仅我们的 if 可以和 else 进行搭配,我们的 while 和 for 同样也可以和 else 进行搭配:在 if else 语句当中,只有我们的 if 后面的条件表达式的值为 False的时候,才会执行 else 语句,而我们的 while else 语句和 for else 语句则为没有碰到 break 的时候执行 else,即如果我们的循环是正常退出的(不是遇到 break 退出的循环),那么我们就会执行 else 语句,具体语法结构如下:
while 条件表达式:
循环体
else:
语句块
for 自定义的变量 in 可迭代对象:
循环体
else:
语句块
只有正常退出循环,才会执行 else 语句,这里举一个例子去强化我们的概念:输入一个数,判断这个数是否为素数,如果不是素数输出:“不是素数”,否则输出:“是素数”。(质数(素数)是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数),如果输入不合法,输出“输入不合法”
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 18:46
# 欢迎大家关注AIoT相关博客~
n = int(input())
if n < 1: # 位置一
print('输入不合法')
else: # 位置二
for item in range(2, n): # 位置三
if n % item == 0: # 位置四
print('不是素数')
break
else: # 位置五
print('是素数')
❗️ 注:如何看else和哪一个 if 或 while(for)配套呢?
我们在 Python 中用严格的缩进规则进行配套,如上述代码中,位置一处的 if 缩进与位置二处的 else 缩进是相同的,故他们俩是配对的,虽然离位置五处的 else 最近的未配对 if 是位置四处的 if,但是因为它们俩的缩进是不相同的,故他们不是配对的 if-else 结构, 位置五处的 else 和位置三处的 for 循环缩进是相同的,故位置三和位置五组成 for-else 结构,即如果位置三处的 for 循环是正常终止的,那么就会执行位置五处的 else 结构,如果位置三处的 for 循环不是正常终止(因为 break 退出循环),那么就不会执行位置五处的 else.
3.3.5 循环嵌套
🚩我们在 3.2.4 学过了选择结构的嵌套,同样,在循环这里也有循环的嵌套,循环的嵌套的思想和选择结构的嵌套其实没有什么区别,当我们发现一层循环解决不了我们的问题的时候,我们就需要两层循环,或者更多层的循环,其语法结构为:
while 条件表达式: # 位置一
# 外层循环的起点
语句块1
...
for 自定义的变量 in 可迭代对象: # 位置二
语句块k
...
else: # 位置三
语句块p
...
语句块m
...
# 外层循环的终点
else: # 位置四
语句块n
...
我们说过,Python控制一个判断语句或者循环语句的开始和结束靠的是其严格的缩进,我们可以把相同的缩进看成同一级的东西,故上述代码,位置一和位置四是配套的,位置二和位置三是配套的,由位置一和位置二构成了循环的嵌套
还是拿题目来举例:输出九九乘法表:
我们先来分析一下我们应该怎么去写:我们可以用一层循环去控制行,一层循环去控制列,如果我们用for i in range(1, 10)去代表行,i用来表示行数,我们不难想到,在第i行,共有i列,故我们的第二层循环可以写为:for j in range(1, i + 1),然后对于每一次,都输出一下 i * j的值,得到代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 19:15
# 欢迎大家关注AIoT相关博客~
for i in range(1, 10):
for j in range(1, i + 1):
print(j, '*', i, '=', j * i, end = ' ')
if i == j: # 即枚举到了如 1 * 1,2 * 2,3 * 3的时候
print('') # 输出一个换行
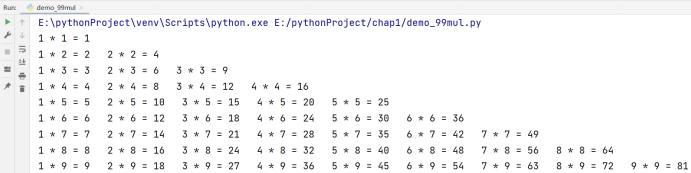
❗️ 注:上述代码有一定的难度,读者不必追求学习的速度,反复推敲一下上述代码,直至理解并可以自己打出和博主一样的代码后再继续向后学习
循环嵌套中的 break 和 continue:
我们知道,break 的作用是退出此循环,continue 的作用是跳过本次循环,那么如果发生了循环的嵌套,在内层循环中如果执行了 break 语句和 continue 语句,是只对内层循环起影响呢还是会对外层循环也起到影响呢?我们不如写个代码自己手动去尝试一下,毕竟:实践是检验真理的唯一标准
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/8 19:33
# 欢迎大家关注AIoT相关博客~
for i in range(3):
for j in range(3):
if j == 1:
break
print('i=', i, 'j=', j)
print('----------------')
for i in range(3):
for j in range(3):
if j == 1:
continue
print('i=', i, 'j=', j)
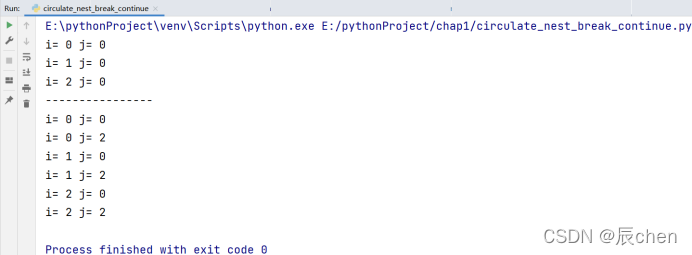
从上述代码以及运行结果我们可以看出,不论是 break 还是 continue,都只用于控制本层循环,对外层循环不会有任何影响
4.背上我的行囊
有关列表,字典,元组,集合,字符串;我把它们归到了 4.背上我的行囊 我们可以把它们理解成存储数据的容器,它们类似我们行囊的功能,都是具备存储的功能,如果你学过 C/C++,你可以把它们理解成数组,我们在之前的学习中知道,如果我们连续的去给一个变量不断的进行赋值操作,那么最终结果就是我们变量的值被不断的覆盖(只存储最后一次赋值的结果),如果它们每次赋值的结果我们都想进行存储的话,那么我们当然可以设多个变量每次存储,我们也可以借助列表这些容器去实现存储它们.
4.1 列表
🚩列表是包涵若干元素的 有序连续 内存空间,其中元素被放在 [] 中,每个元素之间用 , 进行隔开,每个元素可以是不同的类型:它既可以是整数,浮点数,字符串,亦可以是我们后续会讲到的:列表,元组,字典,集合甚至函数以及其他对象;在这里你不需要理解这么多,你简单直接的理解成:列表中的元素可以是各种各样的类型即可,下述的列表都是合法的:
[1, 2, 3, 4, 5]
[0.3, 2, 2.1, 3.7]
['hello', 'world', 2, 3.14, 666]
4.1.1 列表的创建,删除与遍历
🚩列表的创建:我们可以直接使用赋值运算符 “=”,直接把一个列表常量(用[]表示列表,列表的元素之间用,隔开)赋值给变量,如果我们想建立一个列表但是不给它赋任何的值,我们直接让变量 “=” 一个空列表([]),即:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:02
# 欢迎大家关注AIoT相关博客~
a = ['hello', 'world', 2, 3.14, 666]
b = [] # 建立一个空列表
print(a)
print(b)

我们还可以调用 list() 函数进行列表的创建,具体操作如下所示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:02
# 欢迎大家关注AIoT相关博客~
a = list(['hello', 'world', 2, 3.14, 666])
b = list() # 建立一个空列表
print(a)
print(b)

当然,你可能觉得 list() 函数很没用嘛,写起来还多,但是 list() 函数最主要的功能就是它可以把元组,字符串,字典,集合,range() 等转成列表,我们下面只介绍把字符串和 range() 转为列表,其余等读者学完相应内容之后自行实验:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:02
# 欢迎大家关注AIoT相关博客~
a = list('hello world')
b = list(range(10))
print(a)
print(b)

🚩当一个列表不再使用的时候,我们可以使用 del 把它删除:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:02
# 欢迎大家关注AIoT相关博客~
a = list('hello world')
del a
print(a)
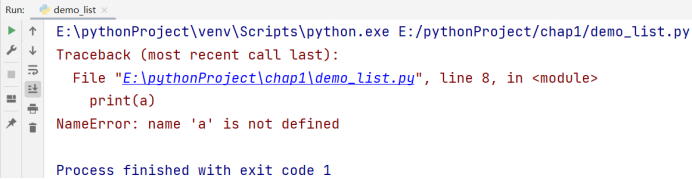
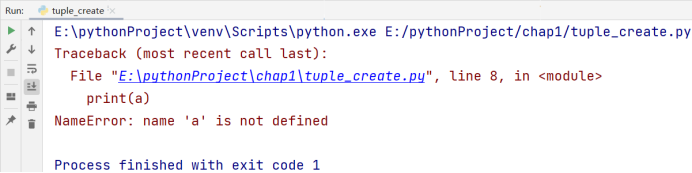
出现:NameError: name ‘a’ is not defined,意思是名称错误:a 未被定义,并不是它未被定义,而是因为我们用 del 操作把它删除了
🚩列表的遍历语法格式如下:
for 迭代变量 in 列表名:
操作语句
比如我们建立一个列表,并打印所有的列表元素可以如下述代码所示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:02
# 欢迎大家关注AIoT相关博客~
a = list(range(10))
for item in a:
print(item, end = ' ')

4.1.2 列表元素的查询
🚩对于一个我们已经创建好的列表,我们如何去快速的访问列表中的元素呢?这里我们介绍一个新的知识:索引,如果你学过 C/C++,你可以把索引理解成数组的下标,但是又略有不同:

如上图所示,其中红色的数字和蓝色的数字对应的就是该列表的索引(蓝色的数字和红色的数字对应的列表位置是一一对应相匹配的),下面我们用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:44
# 欢迎大家关注AIoT相关博客~
a = list(['hello', 'world', 2, 3.14, 666])
print(a[0], a[-5], a[4], a[-1])

index() 方法用来返回指定元素在列表中 首次 出现的位置(索引),如果列表中不存在该元素则会显示 ValueError:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:44
# 欢迎大家关注AIoT相关博客~
a = list(['hello', 'world', 2, 3.14, 666])
print(a.index(3.14))
print(a.index(4))
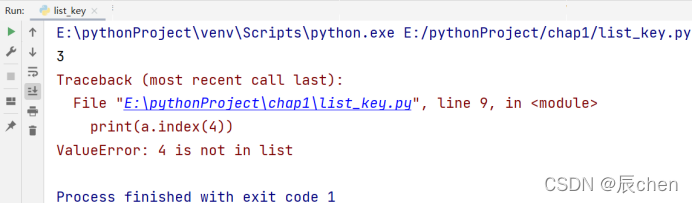
可以看出,列表 a 中存在元素 3.14,返回了它的索引 3,列表 a 中不存在元素 4,显示:ValueError
对于列表中的元素查询,我们还可以使用 in 和 not in,返回值为 True 或 False,True 代表在列表中存在你查找的值,False 则代表不存在,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 10:44
# 欢迎大家关注AIoT相关博客~
a = list(['hello', 'world', 2, 3.14, 666])
print('hello' in a)
print('2' not in a) # 注意这里是字符串 '2',并非数字 2

4.1.3 列表元素的增删改
🚩首先介绍一个 特别重要 的操作:切片,切片的语法格式为:
列表名[start : stop : step]
切片的结果是对原列表序列的拷贝,切片的范围是 [start, stop)【左闭右开】,虽然参数列表为三个:start,stop,step,但是和 range() 一样,我们可以只传入其中的一个或者两个,其余有如下默认值:
[start:stop] # step 默认为1
# step 为正数,从 start 开始往后切片
[:stop:step] # 切片的第一个元素默认为列表第一个元素
[start::step] # 切片的最后一个元素默认为列表最后一个元素
# step 为负数,从 start 开始往前切片
[:stop:step] # 切片的第一个元素默认为列表最后一个元素
[start::step] # 切片的最后一个元素默认为列表第一个元素
说白了,step的作用就是决定是正向切片还是反向切片,step为负代表为反向切片,反之如果step为正,那么就代表正向切片,切片的步长为 step 绝对值的大小
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 11:19
# 欢迎大家关注AIoT相关博客~
a = list([1, 2, 3, 4, 5, 6])
print(a[:: 2]) # 从下标0开始隔一个取一个
print(a[:: -1]) # 反向切片,其实就是让列表反转

我们除了可以通过切片获取列表中的值,还可以利用切片增加,替换或修改,删除列表元素,下面依次去介绍
1️⃣ 增加元素:可以使用切片操作在列表的任意位置插入元素,这里我们会使用len() 函数,读者只需知道 len(L) 可以返回列表 L 的长度即可,具体操作用代码的形式给出:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/9 11:19
# 欢迎大家关注AIoT相关博客~
a = list(range(10))
print(a)
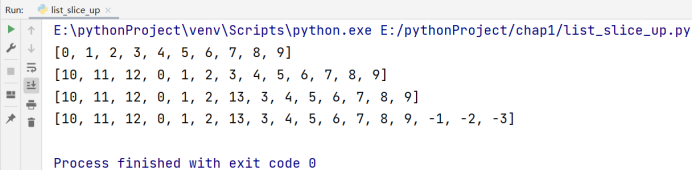
# 在列表头部(索引为0)的位置上插入一段 [10, 11, 12] 的列表
a[:0] = [10, 11, 12] # 可以理解为在0的位置之前插入了[10, 11, 12]
print(a)
# 在索引为6的位置上插入一个元素 13
a[6:6] = [13]
print(a)
# 在列表的末尾插入一段 [-1, -2, -3] 的列表
a[len(a):] = [-1, -2, -3]
print(a)
我们还可以通过以下方法给我们的列表添加元素:
| 方法 | 介绍 |
|---|---|
| append(x) | 在列表尾追加一个元素x |
| extend(L) | 将列表L中所有的元素追加至列表尾 |
| insert(index, x) | 在列表的index位置插入一个元素x |
下面我们通过代码去演示上述函数的用法:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 12:26
# 欢迎大家关注AIoT相关博客~
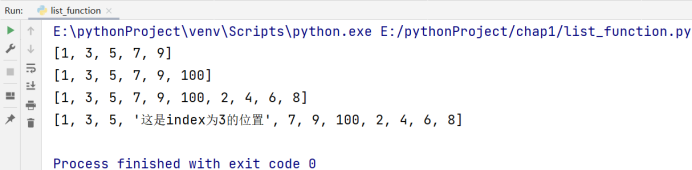
# 创建一个 [1, 3, 5, 7, 9] 的列表
a = list(range(1, 10, 2))
print(a)
# 将 100 追加至列表a尾
a.append(100)
print(a)
# 将 [2, 4, 6, 8] 追加至列表a尾
a.extend(list(range(2, 10, 2)))
print(a)
# 在 index = 3 的地方插入一个元素 '这是index为3的位置'
a.insert(3, '这是index为3的位置')
print(a)
2️⃣ 删除元素:和增加元素一样,我们在删除列表中的元素的时候同样有切片和调用函数(方法)两种方法,我们的相关函数如下:
| 函数(方法) | 介绍 |
|---|---|
| remove(x) | 删除第一个值为x的元素,如果不存在值为x的元素则会抛出ValueError |
| pop(index) | 删除并返回列表中索引为index的元素,index默认为-1(最后一个元素) |
| clear(L) | 清空列表L |
下面关于切片以及相关函数的操作我们利用代码进行讲解:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 13:34
# 欢迎大家关注AIoT相关博客~
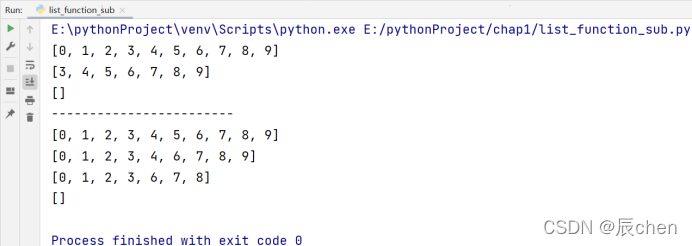
a = list(range(10))
print(a)
# 利用切片删除元素
a[:3] = [] # 删除列表的前三项
print(a)
a[:] = [] # 删除列表的所有元素(清空列表)
print(a)
del a
print('------------------------')
a = list(range(10))
print(a)
# remove()函数:
a.remove(5) # 看列表中是否有元素5,有则删除,没有抛出ValueError
print(a)
# pop()函数:
a.pop(4) # 删除索引为4的元素(第5个元素)
a.pop() # 默认索引为-1(最后一个元素)
print(a)
# clear()函数:
a.clear() # 清空列表中的所有元素
print(a)
'''
注意辨析 clear()和del
del是删除列表,clear()是清空列表中的元素
del a 操作的结果为列表a不存在
clear(a) 操作的结果为列表a中的元素都消失
'''
3️⃣ 修改元素:我们修改元素有两种方法:切片以及为指定索引赋值,下面我们用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 14:03
# 欢迎大家关注AIoT相关博客~
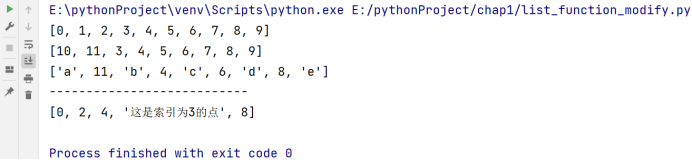
a = list(range(10))
print(a)
# 切片
# 如删除原列表的前三个元素[0, 1, 2],并修改为[10, 11]
a[:3] = [10, 11]
print(a)
# 切片连续(step == 1)不要求等号两边列表长度相等
# 切片不连续(step != 1)要求等号两边列表长度相等
'''
运行会报错:
a[::2] = [2] # 因为切片不连续,故必须要求等号两边列表长度相等
print(a)
'''
# 隔一个改一个(切片不连续,必须要求等号两边列表长度相等)
a[::2] = ['a', 'b', 'c', 'd', 'e']
print(a)
del a
print('---------------------------')
# 利用索引去修改:
a = list(range(0,10,2))
a[3] = '这是索引为3的点'
print(a)
4.1.4 列表元素的排序
🚩在列表排序之前先来介绍另一个方法:reverse(),它的作用是可以对列表所有元素进行逆序操作,即首位互换,具体操作如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 14:26
# 欢迎大家关注AIoT相关博客~
a = list(range(10))
print('reverse()操作前:', a)
a.reverse()
print('reverse()操作后:', a)

接下来就是我们的排序方法:sort(reverse=False),一样,我们用代码去理解方法:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 14:26
# 欢迎大家关注AIoT相关博客~
a = [5, 9, 4, 6, 0, 1, 8, 3, 2, 7]
# 升序排列
a.sort() # 等价于 a.sort(False)
print(a)
a = [9, 3, 4, 2, 0, 5, 7, 8, 1, 6]
# 降序排列
a.sort(reverse = True)
print(a)

*4.1.5 列表常用函数(方法)汇总
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数/方法(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 函数(方法) | 用法介绍 |
|---|---|
| list() | 把一连串对象转为列表 |
| del L | 删除列表L |
| index(x) | 返回列表中第一个值等于x的索引,如果列表中不存在值为x的元素,则显示 ValueError |
| append(x) | 在列表尾追加一个元素x |
| extend(L) | 将列表L中所有的元素追加至列表尾 |
| insert(index, x) | 在列表的index位置插入一个元素x |
| remove(x) | 删除第一个值为x的元素,如果不存在值为x的元素则会抛出ValueError |
| pop(index) | 删除并返回列表中索引为index的元素,index默认为-1(最后一个元素) |
| clear(L) | 清空列表L |
| reverse() | 对列表所有元素原素逆序排序 |
| sort(reverse=False) | 对列表中的元素进行排序,默认 reverse=False 表示升序,reverse=True 表示降序 |
4.1.6 列表生成式
🚩列表生成式可以用非常简洁的格式对列表进行遍历,可以快速生成满足要求的列表,比如我们要生成一个含有[2, 4, 6, 8]的列表,我们可以如下去写:
a = [i * 2 for i in range(1, 5)]
我们可以这么去理解列表推导式,后面的 for 循环为我们的遍历对象,即在上述中我们的遍历对象为 range(1, 5),其实就是把 i 从1 到 4 枚举一遍,枚举过程中把 i * 2 的值加入到列表之中,我们其实可以对上式写成:
for i in range(1, 5):
a.append(i * 2)
下面再来举几个例子:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 19:39
# 欢迎大家关注AIoT相关博客~
# 生成 [2, 4, 6, 8]
a = [i * 2 for i in range(1, 5)]
print(a)
# 生成 i * i(i ∈ [1, 9])
a.clear() # 清空队列
a = [i * i for i in range(1, 10)]
print(a)
# 生成九九乘法表的值(支持for的嵌套)
a.clear()
a = [i * j for i in range(1, 10) for j in range(1, 10)]
'''
上面这行代码等价于:
for i in range(1, 10):
for j in range(1, 10):
a.append(i * j)
'''
print(a)
# 支持循环和选择结构的嵌套:
a.clear()
a = [i for i in range(10) if i % 2 == 0]
'''
上面这行代码等价于:
for i in range(10):
if i % 2 == 0:
a.append(i)
'''
print(a)
# 来一个比较有难度的:
a.clear()
a = [i for i in range(5) if i % 2 == 0 for j in range(5)]
'''
上面这行代码等价于:
for i in range(5):
if i % 2 == 0:
for j in range(5):
a.append(i)
'''
print(a)
4.2 字典
字典也是 Python 内置的数据结构之一,字典是包含若干“键:值”元素的无序可变序列,字典中的每一个元素都有两个值,它们之间用:隔开,第一个代表键,你可以理解成列表中的 索引,只不过列表中的索引只能是数字,而字典中的键可以是很多东西,字典中的值和列表中的元素值类似,在字典中,不同元素之间用,隔开,这一点和列表是一样的,列表中的所有元素均放在[]之中,字典中的所有元素放在{}中,不同于列表中的元素索引是唯二的(一个为正一个为负),字典中的键是唯一的,是不可重复的,而字典的值是可以重复的,比如,我们可以设置一个字典用来表示人物和年龄之间的关系:
{'张三':18, '李四':19, '王五':18}
显然,对于不同的人来说,我们是允许他们的年龄是相同的(字典的值相同),但是我们不允许他们的名字相同(字典的键不同),字典(Python)的实现原理其实和我们日常生活中的查字典是类似的,查字典是利用部首或者拼音找到目标字的页数,在字典(Python)中则是利用我们的键(key),去找到我们的值(value)。以上就是简单的认识一下字典,那么接下来,就让我们细致的去了解字典这个数据结构:
4.2.1 字典的创建,删除与遍历
🚩字典的创建:我们可以直接使用赋值运算符 “=”,直接把一个字典常量(用{}表示字典,字典的元素之间用,隔开)赋值给变量,如果我们想建立一个字典但是不给它赋任何的值,我们直接让变量 “=” 一个空字典({}),即:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = {'张三':18, '李四':19, '王五':18}
b = {}
print(a)
print(b)

我们还可以使用 dict() 函数创造一个字典,我们用=去对应键和值,=左边为键,=右边为值,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
b = dict()
print(a)
print(b)

🚩当一个字典不再使用的时候,我们使用 del 将其删除
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
del a
print(a)
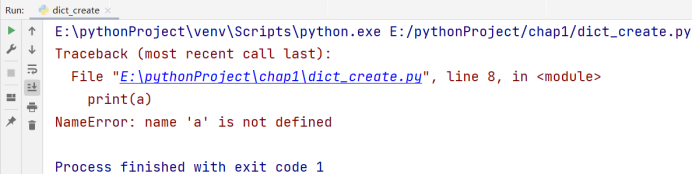
🚩字典的遍历默认遍历的是键(key)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
for item in a:
print(item)
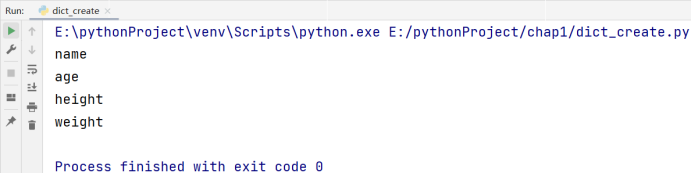
如果我们想要遍历字典的值,需要调用 values() 方法:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
for item in a.values():
print(item)
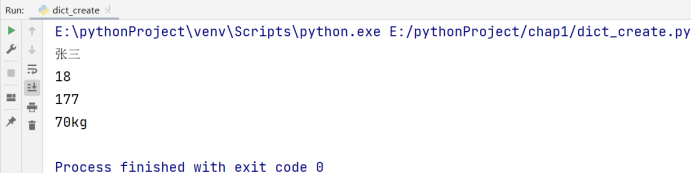
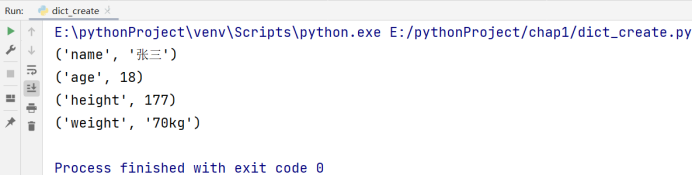
如果我们同时访问键和值的话(即访问字典),需要调用 items() 方法:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:12
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
for item in a.items():
print(item)
4.2.2 字典元素的查询与访问
🚩字典中的键和值之间其实可以理解成通过映射的关系相连,如果你学过 C,你可以把键当成特殊的数组下标(这个下标可以是很多的数据类型),如果你学过 C++,你可以把字典理解成 map,对于 Python 初学者而言,我们可以把字典和列表对比,我们通过索引访问列表元素,索引必是整数,对于字典而言,我们用键去访问字典的值,每一个键对应一个值,且字典中的键和列表中的索引最大区别就是,键可以是很多的数据类型,但是索引只能是整数,获取字典中的值我们有两种方法,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:35
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
print(a['name'])
print(a['height'])

如果我们访问的键(key)在我们的列表中不存在的话,会显示 KeyError:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:35
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
print(a['location'])
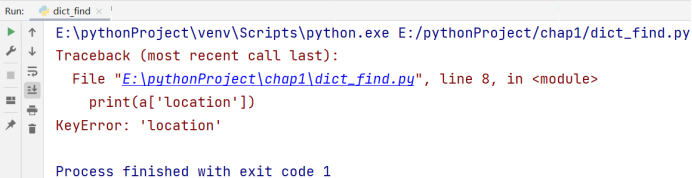
我们还可以使用 get() 方法用来返回我们指定的键(key)所对应的值(value),和上述不存在会显示 KeyError 不同的是,如果我们要访问的键(key)不存在的话,会显示 None(代表无),我们也可以修改当不存在指定键(key)时,get() 方法返回的值,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:35
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
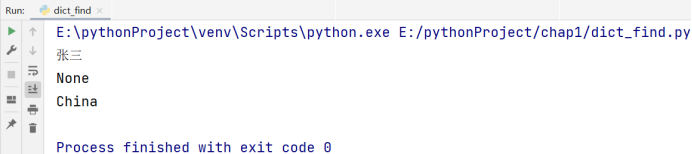
print(a.get('name'))
print(a.get('location'))
print(a.get('location', 'China'))
# China 为执行get(key)方法时,当key不存在时返回的值
🚩我们还可以通过 in 和 not in 判断一个键(key)是否在字典中存在,如果使用 in,那么存在返回 True,不存在返回 False,如果使用 not in,那么存在返回 False,不存在返回True,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/11 23:35
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
print('name' in a)
print('name' not in a)

4.2.3 字典元素的增删改
1️⃣字典元素的增:我们可以直接设置我们的目标键和目标值,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/12 22:13
# 欢迎大家关注AIoT相关博客~
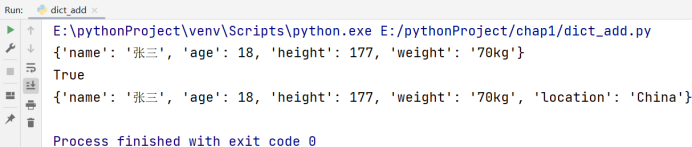
a = dict(name='张三', age=18, height=177, weight='70kg')
print(a)
a['location'] = 'China'
print('location' in a)
print(a)
对于增减字典元素,我们还可以使用 update() 方法,可以直接将另一个字典的“键:值”全部添加到当前字典中,如果两个字典中存在相同的键(key),那么会以另一个字典中的“值”为准,即修改当前字典的“值”,具体代码如下
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/12 22:13
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
print(a)
a.update({'location':'China', 'sex':'male'})
print(a)
# 注意,此时字典a中已经有名为 sex 的键了,这时再执行 update 操作其实是修改
a.update({'sex':'female'})
print(a)

2️⃣字典元素的删除:删除字典元素,我们在这里介绍两种方法:popitem(),pop(),下面用代码去讲解:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/12 22:35
# 欢迎大家关注AIoT相关博客~
a = {'name': '张三', 'age': 18, 'height': 177, 'weight': '70kg'}
a.popitem() # 删除字典中的最后一个元素,字典为空则显示 KeyError
print(a)
a.pop('age') # pop通过传入我们想要删除的键值对的键(key)来删除键值对
print(a)

3️⃣字典元素的改:和增的操作一样,我们可以直接修改我们的目标键所对应的值,代码如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/12 22:23
# 欢迎大家关注AIoT相关博客~
a = dict(name='张三', age=18, height=177, weight='70kg')
print(a, 'weight' in a)
a['weight'] = '65kg'
print(a)

*4.2.4 字典常用函数(方法)汇总
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数/方法(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 函数(方法) | 用法介绍 |
|---|---|
| dict() | 将一连串的对象转为字典 |
| del | 删除字典 |
| values() | 遍历字典的值(value),默认遍历字典的键(key) |
| items() | 遍历字典的元素【键值对】(key:values),默认遍历字典的键(key) |
| get(key) | 返回我们指定的键(key)所对应的值(value),不存在键(key)则返回 None |
| update(dict) | 将令一个字典中的全部元素全部添加至目标字典 |
| popitem() | 删除字典中的最后一个元素,字典为空显示 KeyError |
| pop(key) | 删除键(key)所对应的键值对 |
4.2.5 字典生成式
🚩在介绍字典生成式之前,我们先介绍一个函数 zip(),zip() 可以将多个可迭代对象(如列表)中对应位置的元素压缩在一起,返回一个可迭代的 zip 对象,如果传入的两个可迭代对象长度不相同,则返回的结果以短的为准,下面用代码去演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 12:35
# 欢迎大家关注AIoT相关博客~
a = [1, 2, 3, 4, 5]
b = ['h', 'e', 'l', 'l', 'o']
print(list(zip(a, b))) # 转为列表输出
# 当两个列表元素个数不相等时:
a = [1, 2, 3, 4, 5, 6, 7, 8]
b = ['h', 'e', 'l', 'l', 'o']
print(list(zip(a, b))) # 转为列表输出
# 当然,字符串也是可以迭代的,故:
a = [1, 2, 3, 4, 5]
b = 'hello'
print(list(zip(a, b))) # 转为列表输出

我们从代码中其实可以理解,zip() 函数会将两个元素压缩在一起,这非常像我们字典中的键值对,故我们可以利用 zip() 函数去生成我们的字典,其代码格式非常像我们的列表推导式:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 12:35
# 欢迎大家关注AIoT相关博客~
a = [1, 2, 3, 4, 5]
b = ['h', 'e', 'l', 'l', 'o']
c = {item:value for item, value in zip(a, b)}
print(c)

4.3 元组
什么是元组?答:元组是 Python 中内置的数据结构之一,是一个不可变的序列,所谓不可变就是不支持增删改的操作;字符串,元组都是不可变序列,可变序列有如列表,字典.
4.3.1 元组的创建与删除
🚩元组的创建:我们可以直接使用赋值运算符 “=”,直接把一个元组常量(用()表示元组,元组的元素之间用,隔开)赋值给变量,这里需要注意,如果只想创建一个元组的元素,需要加,即:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 16:41
# 欢迎大家关注AIoT相关博客~
a = ('hello', 3, '辰chen')
print(a)
# 如果元组中只有一个元素,需要加一个 , :
b = ('AIoT', )
print(b)

我们还可以调用 tuple() 函数进行元组的创建,具体操作如下所示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 16:41
# 欢迎大家关注AIoT相关博客~
a = tuple(('hello', 3, '辰chen'))
print(a)

和列表与字典一样,删除元组用的是 del:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 16:41
# 欢迎大家关注AIoT相关博客~
a = tuple(('hello', 3, '辰chen'))
del a
print(a)
4.3.2 元组的遍历
🚩对元组的遍历,遍历的方法其实和遍历列表是一样的,都是通过索引去遍历的,对于索引的定义与列表也是一致的,代码演示如下:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 18:16
# 欢迎大家关注AIoT相关博客~
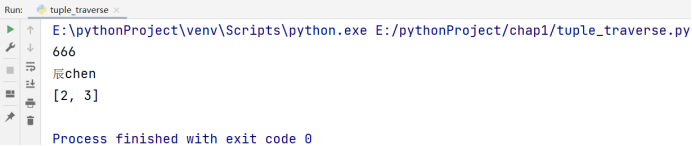
a = (666, '辰chen', [2, 3])
print(a[-1])
print(a[0])

当然,我们可以用 for 循环去遍历整个元组:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 18:16
# 欢迎大家关注AIoT相关博客~
a = (666, '辰chen', [2, 3])
for item in a:
print(item)
*4.4.3 深入理解元组不可变
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 什么叫不可变:即其元素是不可以进行增删改的,强制执行增删改会报错 TypeError,那么这样一种不可以改变的数据结构有什么意义呢?就面向过程这一大章节而言,它确实没有什么实际的作用,但是在面向对象以及现实生活中,它具有很强的现实意义,我们可以这么去想,比如我们开发一个程序(王者荣耀),我们允许用户去改变自己的游戏名称,但是我们是不允许去修改英雄名称,故这个时候我们就可以用元组
其实元组中的元素如果是可变类型的(列表),我们是可以改变它的,其余则不可以改变:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 18:16
# 欢迎大家关注AIoT相关博客~
a = (666, '辰chen', [2, 3])
print(a)
'''
a[2] 代表的是元组a的第三个元素即列表
列表是可以修改的,但是如下的修改是不可以的:
a[2] = [1, 2, 3]
print(a)
你可以理解为,上述的修改为先删除掉[2, 3]
然后再加入一个新的列表[1, 2, 3]这种做法是不允许的
我们这里的修改列表中的值为,在原列表的基础上增加或减少元素
所以下述的做法是正确的:
'''
a[2].append(1)
print(a)

4.4 集合
集合也是 Python 的数据结构之一,集合是无序可变序列,和字典一样,使用一对大括号{}作为界定符,元素之间通过,相隔,并且集合中的每一个元素都是唯一的,你可以理解为集合为没有值(value),只有键(key)的字典,字典中的元素只能为不可变的数据类型,如:数字,字符串,元组;像列表,字典,集合这种可变的数据类型不可以作为集合的元素
4.4.1 集合的创建与删除
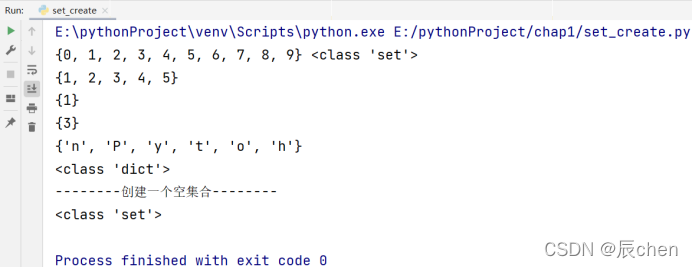
🚩字典的创建:我们可以直接使用赋值运算符 “=”,直接把一个集合常量(用{}表示集合,字典的元素之间用,隔开)赋值给变量,即:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 19:28
# 欢迎大家关注AIoT相关博客~
a = {1, 2, (3, 4), '567'}
print(a, type(a))

我们还可以使用 set() 函数去创建一个集合:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 19:28
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a, type(a))
print(set([1, 2, 3, 4, 5])) # 把列表转为集合
# 如果列表中有重复的元素:
print(set([1, 1, 1])) # 自动去重
print(set((3,))) # 把元组转为结合
print(set('Python')) # 将字符串转为集合
# 因为集合是无序的,故输出结果不一定是 Python 的顺序
'''
创建一个空集合:
我们如果按照以往的思维的话,会发现我们创建的其实是一个字典
'''
b = {}
print(type(b))
print(('--------创建一个空集合--------'))
c = set()
print(type(c))
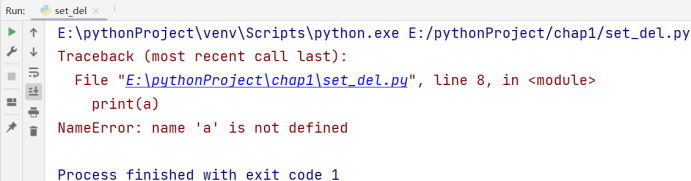
我们用 del 指令可以删除集合:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 19:43
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
del a
print(a)
4.4.2 集合元素的增加与删除
1️⃣ 判断元素是否在集合中可以用 in 和 not in:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 22:31
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(0 in a)
print(0 not in a)

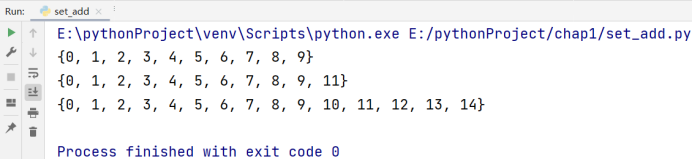
2️⃣ 集合元素增加:我们可以使用 add() 方法增加新的元素,如果元素已经存在则忽略这次操作;update() 方法可以将另一个集合中的元素到当前的集合之中,并且有自动去重的功能
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/13 22:31
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a)
a.add(11)
print(a)
b = set(range(5, 15))
a.update(b)
print(a)
3️⃣ 集合对象的删除:删除集合的对象我们介绍四个方法:remove(),discard(),pop(),clear(),我们用代码去逐个讲解:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 12:33
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a)
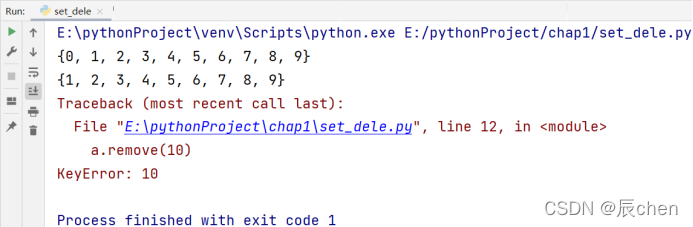
a.remove(0)
print(a)
a.remove(10)
print(a)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 12:33
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a)
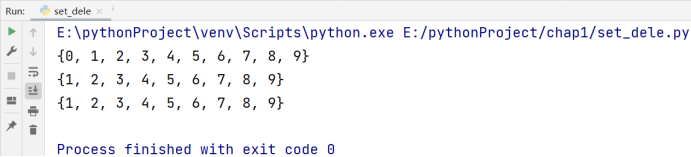
a.discard(0)
print(a)
a.discard(10)
print(a)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 12:33
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a)
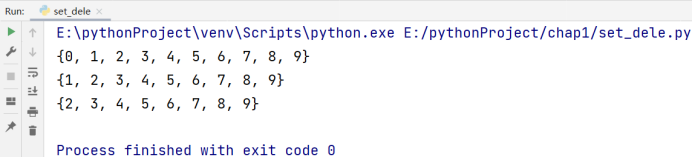
# pop() 中不可以传参数,pop()删除的是第一个元素
a.pop()
print(a)
a.pop()
print(a)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 12:33
# 欢迎大家关注AIoT相关博客~
a = set(range(10))
print(a)
a.clear()
print(a)
for i in range(10):
print(i in a, end = ' ')

4.4.3 集合之间的关系
🚩关于集合,我们给出这么几种关系:
1️⃣ 集合A和集合B相等:如果集合A中的元素和集合B中的元素是一模一样的,那么称集合A和集合B相等。❗️ 注意:我们之前说过,集合是无序的,故对于集合{1, 2, 3, 4}其实和集合{4, 3, 2, 1}是相等的,判断两个集合相等,我们使用 != == 去判断:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 13:18
# 欢迎大家关注AIoT相关博客~
a = {1, 2, 3, 4}
b = {4, 1, 3, 2}
c = {1, 2, 3}
print(a == b)
print(a != c)

2️⃣ 集合A是集合B的子集:在集合A中的元素都存在于集合B之中,集合A是集合B的子集,我们也称集合B是集合A的超集,如果集合A是集合B的子集,且集合A不等于集合B,那么称集合A是集合B的真子集:
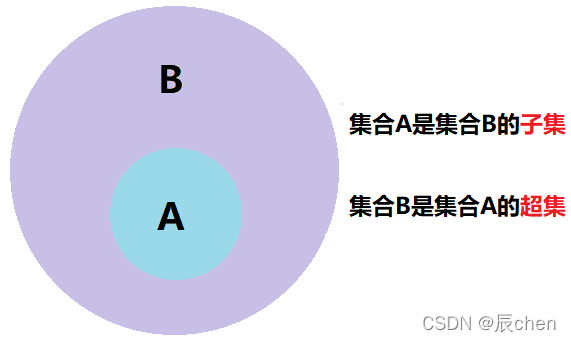
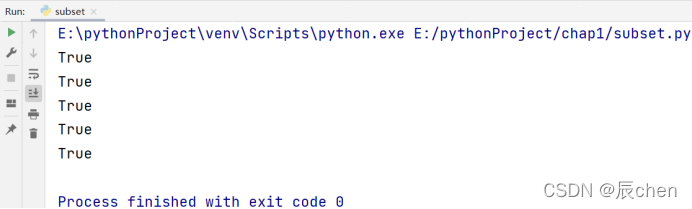
我们在代码中可以用 issubset() 和 issuperset() 分别判断子集和超集,也可以使用 < <= >= 去判断两个集合之间的关系:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 13:20
# 欢迎大家关注AIoT相关博客~
a = {1, 2, 3}
b = {1, 2, 3, 4}
# 用 issubset() 判断a是否为b的子集:
print(a.issubset(b))
# 用 <= 判断a是否为b的子集:
print(a <= b)
# 用 < 判断a是否为b的真子集:
print(a < b)
# 用 issuperset() 判断b是否为a的超集:
print(b.issuperset(a))
# 用 >= 判断b是否为a的超集:
print(b >= a)
3️⃣ 判断两个集合是否有交集:使用方法 isdisjoint() 判断两个集合是否 没有交集,如果两个集合有交集返回 False,如果两个集合没有交集返回 True:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 13:28
# 欢迎大家关注AIoT相关博客~
a = {1, 2, 3, 4}
b = {4, 5, 6}
c = {7, 8, 9}
# isdisjoint() 有交集返回False,没有交集返回True
# 判断a和b是否没有交集:
print(a.isdisjoint(b))
# 判断a和c是否没有交集:
print(a.isdisjoint(c))

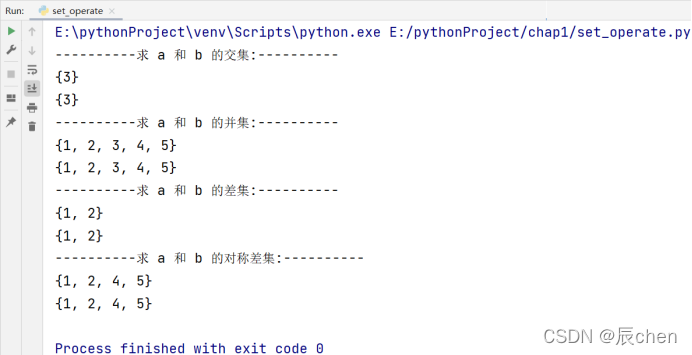
4️⃣ 交集、并集、差集、对称差集:
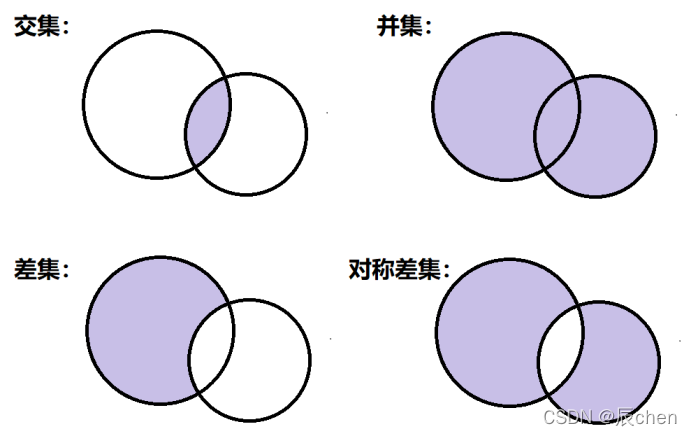
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 17:54
# 欢迎大家关注AIoT相关博客~
a = {1, 2, 3}
b = {3, 4, 5}
print('----------求 a 和 b 的交集:----------')
print(a.intersection(b))
print(a & b)
print('----------求 a 和 b 的并集:----------')
print(a.union(b))
print(a | b)
print('----------求 a 和 b 的差集:----------')
print(a.difference(b))
print(a - b)
print('----------求 a 和 b 的对称差集:----------')
print(a.symmetric_difference(b))
print(a ^ b)
*4.4.4 集合常用函数(方法)汇总
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数/方法(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 函数(方法) | 用法介绍 |
|---|---|
| set() | 将一连串的对象转为集合 |
| del | 删除集合 |
| add() | 将集合中加入一个新的元素,如果原集合中已有该元素则忽略此操作 |
| update() | 将另一个集合中的元素加入到该集合中,并自动去重 |
| remove(x) | 删除指定的元素x,如果x不存在则显示KeyError |
| discard(x) | 删除指定的元素x,如果x不存在则忽略本操作 |
| pop() | 删除集合中的第一个元素 |
| clear() | 清空集合 |
| issubset() | 判断一个集合是否为另一个集合的子集 |
| issuperset() | 判断一个集合是否为另一个集合的超集 |
| isdisjoint() | 判断两个集合是否没有交集,没有交集返回True,有交集返回False |
| intersection() | 求两个集合的交集 |
| union() | 求两个集合的并集 |
| difference() | 求两个集合的差集 |
| symmetric_difference() | 求两个集合的对称差集 |
4.4.5 集合生成式
🚩集合生成式其实和列表生成式是一模一样的,只是把[]换成了{},注意列表,集合,字典都有属于自己的生成式,只有元组没有元组生成式。
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 18:36
# 欢迎大家关注AIoT相关博客~
a = {i * i for i in range(10)}
print(a)

我们可以看到集合 a 中的元素其实是乱序的,这也印证了最开始提到的集合是无序的
4.5 字符串
字符串是 Python 中的一个基本数据类型,我们曾经在 1.3.6 简单字符串介绍 中简单的提到过这个知识点,那时我们刚刚接触 Python,并且字符串较难且尤为重要,故只在那里进行简单的介绍,从本节开始,我们将系统的给大家介绍这个重要的数据类型,它理解起来并不难,因为我们自第一个程序就用到了字符串:hello world,本节涉及众多的与字符串相关的方法,大家没必要去记忆(应付期末除外),我在 *4.5.7 字符串常用函数(方法)汇总 进行了大汇总,大家只需要在需要的时候进行查询即可.字符串是包含若干字符的容器,属于不可变有序序列,我们使用''(单引号) ""(双引号) ''' '''(三引号)为定界符,不同的定界符之间可以相互嵌套:
print('Marry said,"hello 辰chen"')
# 运行结果为:Marry said,"hello 辰chen"
*4.5.1 字符串的驻留机制
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 字符串的驻留机制其实就是仅保存一份相同且不可变的字符串的方式,即对于同一个字符串,它们所指的 id 地址是同一个地点,我们可以使用 id() 函数去查看内存地址:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 12:56
# 欢迎大家关注AIoT相关博客~
a = '辰chen'
b = "辰chen"
c = '''辰chen'''
print(a, id(a))
print(b, id(b))
print(c, id(c))

我们发现,虽然我们定义了三个变量,但是只要它们指向的字符串是相同的,三个变量在内存中的地址就是相同的,这就是字符串的驻留机制
4.5.2 字符串的常用操作
1️⃣ 字符串的查询操作:使用函数 index() rindex() find() rfind(),下面举例子去说明,比如我们有模板串:abababa,我们要查找子串aba的位置,索引如下图所示:

# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 13:23
# 欢迎大家关注AIoT相关博客~
s = 'abababa'
s1 = 'aba'
# index() 查找第一次出现的索引,如果不存在该子串显示 ValueError
print(s.index(s1))
# rindex() 查找最后一次出现的索引,如果不存在该子串显示 ValueError
print(s.rindex(s1))
# find() 查找第一次出现的索引,如果不存在则返回 -1
print(s.find(s1))
# find() 查找最后一次出现的索引,如果不存在则返回 -1
print(s.rfind(s1))
print(s.find('k'))
print(s.index('k'))

2️⃣ 我们使用 upper() lower() swapcase() capitalize() title(),去进行大小写的转换,具体函数给出代码和运行结果,读者根据代码去理解函数
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 13:38
# 欢迎大家关注AIoT相关博客~
s1 = 'hello, my name is chen.'
s2 = 'HELLO, MY NAME IS CHEN.'
s3 = 'Hello. My naMe Is ChEn'
s4 = 'HEllO, my NaME iS chEn'
s5 = 'HELlo, My nAme Is CHeN'
print('----upper() 将所有的字符都转成大写字母----')
print(s1)
print(s1.upper())
print('----lower() 将所有的字符都转成小写字母----')
print(s2)
print(s2.lower())
print('----swapcase() 将小写字母转为大写字母,大写字母转为小写字母----')
print(s3)
print(s3.swapcase())
print('----capitalize() 把第一个字符转为大写,其余转为小写----')
print(s4)
print(s4.capitalize())
print('----title() 把每个单词的第一个字符换为大写,其余换为小写----')
print(s5)
print(s5.title())

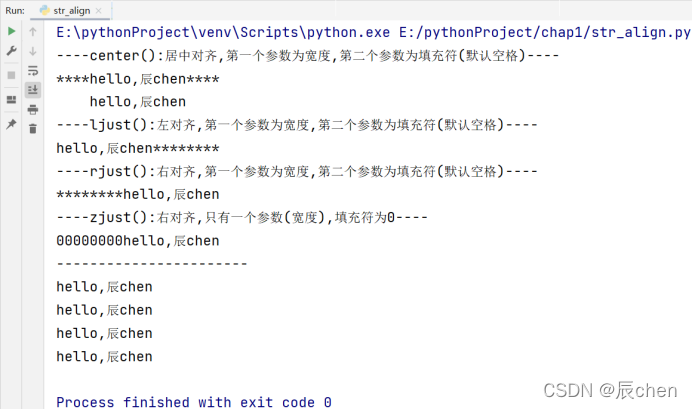
3️⃣ 字符串的对齐操作:我们使用 center() ljust() rjust() zjust(),去进行字符串的居中对齐,左对齐与右对齐,具体函数给出代码和运行结果,读者根据代码去理解函数
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 14:39
# 欢迎大家关注AIoT相关博客~
s = 'hello,辰chen'
# 宽度就是指在进行对齐操作后,所展示的字符个数,如s的宽度为:11
print('----center():居中对齐,第一个参数为宽度,第二个参数为填充符(默认空格)----')
print(s.center(19, '*'))
print(s.center(19))
print('----ljust():左对齐,第一个参数为宽度,第二个参数为填充符(默认空格)----')
print(s.ljust(19, '*'))
print('----rjust():右对齐,第一个参数为宽度,第二个参数为填充符(默认空格)----')
print(s.rjust(19, '*'))
print('----zjust():右对齐,只有一个参数(宽度),填充符为0----')
print(s.zfill(19))
print('-----------------------')
# 如果我们传入的宽度是要小于我们的原字符串宽度,则不会对字符串有任何修改:
print(s.center(5, '*'))
print(s.ljust(5, '*'))
print(s.rjust(5, '*'))
print(s.zfill(5))
4️⃣ 字符串的分割:我们使用 split() 和 rsplit() 两个方法,分别实现从左劈分字符串以及从右分割字符串
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 15:15
# 欢迎大家关注AIoT相关博客~
# 使用 split() 和 rsplit() 进行划分,返回值为列表
s1 = 'hello 辰chen, your blog is really good'
s2 = 'hello|辰chen|your|blog|is|really|good'
print('---------使用 split() 进行划分---------')
# 默认按照空格进行划分
print(s1.split())
# 按照传入的参数进行划分
print(s2.split(sep='|'))
# 按照传入的参数进行划分,设置最大划分次数为maxsplit
print(s2.split(sep='|', maxsplit=2))
print('---------使用 rsplit() 进行划分---------')
# 默认按照空格进行划分
print(s1.rsplit())
# 按照传入的参数进行划分
print(s2.rsplit(sep='|'))
# 按照传入的参数进行划分,设置最大划分次数为maxsplit
print(s2.rsplit(sep='|', maxsplit=2))

5️⃣ 判断字符串的操作:我们可以利用方法 isidentifier() 去判断一个字符串是否由合法标识符组成,判断合法标识符我们在 *1.2.1 标识符和保留字 有过介绍,还可以利用 isspace() 方法判断是否字符串是由空格所组成的,也有判断是否由数字数字组成的方法:isdecimal() isnumeric();判断是否由字母组成的方法:isalpha();判断是否由数字和字母组成的方法:isalnum()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 15:53
# 欢迎大家关注AIoT相关博客~
s='a,b,c'
s1='hello辰chen'
# isidentidier() 用来判断字符串是否由合法标识符组成:
print('1.', s.isidentifier()) # False
print('2.',s1.isidentifier()) # True
# isspace() 用来判断字符串是否全由空格(回车,换行,水平制表)组成:
print('3.','\t'.isspace()) # True
print('4.', ' '.isspace()) # True
# isalpha() 用来判断字符串字符串是否全由字母组成
print('5.','abc'.isalpha()) # True
print('6.','abc1'.isalpha()) # False
print('7.','辰chen'.isalpha()) # True
# isdecimal() 用来判断字符串是否全部由十进制数组成
print('8.','123'.isdecimal()) # True
print('9.','123四'.isdecimal()) # False
# isnumeric() 用来判断字符串是否全部由数字组成(罗马数字不可以)
print('10.','123'.isnumeric()) # True
print('11.','123四'.isnumeric()) # True
print('12.','IIV'.isnumeric()) # False
# 判断字符串是否全部由数字和字母组成
print('13.','abc123'.isalnum()) # True
print('14.','123辰chen'.isalnum()) # True
print('15.','123辰chen!'.isalnum()) # False

6️⃣ 字符串的替换与合并:我们使用 replace() 去对字符串进行替换,使用 join() 对字符串进行合并,replace(obj1, obj2, frequency):将字符串 obj1 替换为 obj2,一共替换 frequency 次(默认全部替换),使用 join() 方法进行字符串的合并时,我们可以选择合并过程中字符串之间通过什么进行连接.
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 16:46
# 欢迎大家关注AIoT相关博客~
# 使用 replace() 方法对字符串进行替换操作:
s = 'hello Python'
# 把 Python 替换为 辰chen
print(s.replace('Python', '辰chen'))
s = 'hello Python Python Python'
# 把 Python 替换为 辰chen,一共替换2次
print(s.replace('Python', '辰chen', 2))
# 使用 join() 方法把列表(元素为字符串类型)或元组(元素为字符串类型)连接为字符串
l = ['hello', '辰chen', 'Python']
print(' '.join(l)) # 连接的地方用' '隔开
t = ('hello', '辰chen', 'Python')
print('*'.join(l)) # 连接的地方用'*'隔开
# 使用 join() 方法操作于字符串:
print('*'.join('Python'))
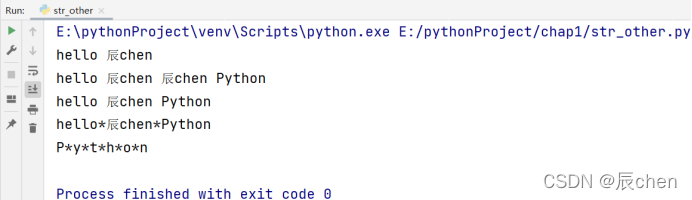
这里额外说一点,我们经过以上的学习知道,我们连接两个字符串可以使用 join() 方法,我们在这里还可以直接使用+去把两个字符串连接称为一个新的字符串:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 19:40
# 欢迎大家关注AIoT相关博客~
a = 'hello'
b = '辰chen'
c = a + ',' + b
print(c)

但是我们并不建议使用这种方法,我们使用 join() 对字符串拼接的效率要远高于使用+去拼接.
4.5.3 字符串的比较
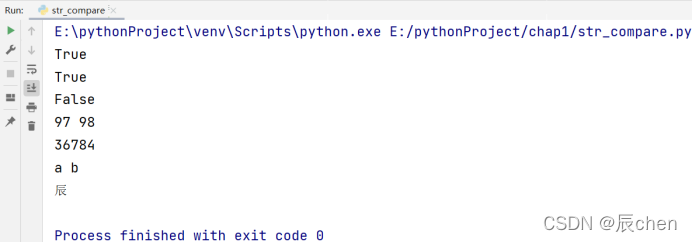
🚩我们使用比较运算符 <,<=,>,>=,==,!=,比较的规则是我们逐位去对比两个字符串的 ordinal value(原始值),我们使用函数 ord() 就可以获取字符的 ordinal value(原始值),这里还有一个逆操作,我们可以使用函数 chr() 获取 ordinal value 所对应的字符,其实对于我们而言,直接理解成比较两个字符的 ASCII码即可,ASCII码表见 *1.4 二进制与字符编码
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 19:09
# 欢迎大家关注AIoT相关博客~
print('aba' > 'ab') # True
print('aba' >= 'aba') # True
print('apple' > 'banana') # False
print(ord('a'), ord('b'))
print(ord('辰'))
print(chr(97), chr(98))
print(chr(36784))
4.5.4 字符串的切片
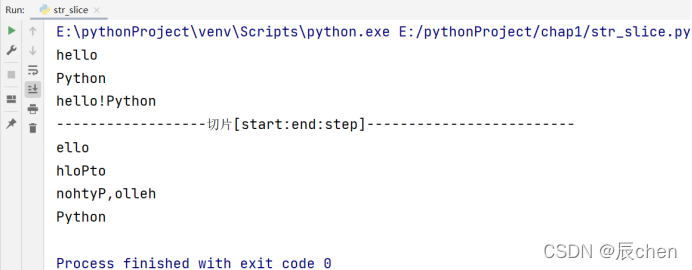
🚩字符串的切片和列表的切片其实是一模一样的规则,关于切片操作,在 4.1.3 列表元素的增删改 已经说的很详尽,这里就不做过多赘述,直接上代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 19:52
# 欢迎大家关注AIoT相关博客~
s='hello,Python'
s1=s[:5] # 没有指定起始位置,所以从0开始切
s2=s[6:] # 没有指定结束位置,所以切到字符串的最后一个元素
s3='!'
newstr=s1+s3+s2
print(s1)
print(s2)
print(newstr)
print('------------------切片[start:end:step]-------------------------')
print(s[1:5:1]) # 从1开始截到5(不包含5),步长为1
print(s[::2]) # 从0开始,默认到字符串的最后一个元素,步长为2
print(s[::-1]) # 从字符串的最后一个元素开始,到字符串的第一个元素结束
print(s[-6::1]) # 从索引为-6开始,到字符串的最后一个元素结束,步长为1
4.5.5 格式化字符串
1️⃣ 使用 % 作占位符,举个例子去介绍:'我的名字是%s,年龄为%d' % (name, age),name 会替代 %s,age 会替代%d.
| 格式字符 | 说明 |
|---|---|
| %s | 对应字符串 |
| %d | 对应十进制整数 |
| %o | 对应八进制整数 |
| %x | 对应十六进制整数 |
| %f | 对应浮点数 |
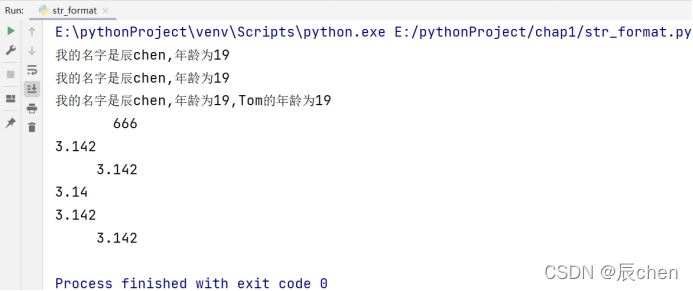
2️⃣ 使用 {} 作占位符,这里使用了 format() 方法,举个例子去介绍:'我的名字是{0},年龄为{1}'.format(name, age),name 会替代{0},age 会替代{1},如果你还是觉得十分懵逼,下面附上代码去进行说明:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 20:10
# 欢迎大家关注AIoT相关博客~
name = '辰chen'
age = 19
print('我的名字是%s,年龄为%d' % (name, age))
print('我的名字是{0},年龄为{1}'.format(name, age))
print('我的名字是{0},年龄为{1},Tom的年龄为{1}'.format(name, age))
# 设置宽度为10:
print('%10d' % 666)
# 设置保留3位小数:
print('%.3f' % 3.1415926)
# 设置宽度为10,并保留3位小数:
print('%10.3f' % 3.1415926)
# 保留3位数:
print('{0:.3}'.format(3.1415926))
# 保留3位小数:
print('{0:.3f}'.format(3.1415926))
# 设置宽度为10,保留3位小数:
print('{0:10.3f}'.format(3.1415926))
3️⃣ 使用 f-string 格式化字符串:f'我的名字是{name},年龄为{age}'
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 20:10
# 欢迎大家关注AIoT相关博客~
name = '辰chen'
age = 19
print(f'我的名字是{name},年龄为{age}')

*4.5.6 字符串的编码转换
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️本文涉及的内容其实在爬虫上才会真正使用到,这里大家只需要进行简单的了解即可。
为什么要进行编码转换:其实我们在计算机与计算机交流的过程中,比如把我的计算机中的数据传入至你的计算机之中,就需要使用字节进行传输。这个时候就需要将我们的字符串转为二进制,然后你的电脑再将二进制转为字符串,最终呈现在你的眼前。编码是将字符串转为二进制数据(bytes),解码就是将二进制数据(bytes)转为字符串类型。注意我们得先进行编码再进行解码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/15 22:16
# 欢迎大家关注AIoT相关博客~
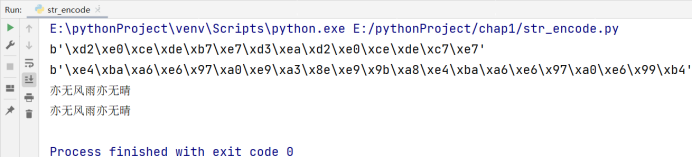
s='亦无风雨亦无晴'
#编码
print(s.encode(encoding='GBK')) #在GBK这种编码格中 一个中文占两个字节
print(s.encode(encoding='UTF-8')) #在UTF-8这种编辑格式中,一个中文占三个字节
#解码
#byte代表就是一个二进制数据(字节类型的数据)
byte=s.encode(encoding='GBK') #编码
print(byte.decode(encoding='GBK')) #解码
byte=s.encode(encoding='UTF-8')
print(byte.decode(encoding='UTF-8'))
*4.5.7 字符串常用函数(方法)汇总
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数/方法(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 函数(方法) | 用法介绍 |
|---|---|
| index() | 查找子串第一次出现的位置,如果不存在子串则显示ValueError |
| rindex() | 查找子串最后一次出现的位置,如果子串不存在则显示ValueError |
| find() | 查找子串第一次出现的位置,如果不存在子串则返回-1 |
| rfind() | 查找子串最后一次出现的位置,如果不存在子串则返回-1 |
| upper() | 将字符串中所有的字母都转为大写字母 |
| lower() | 将字符串中所有的字母都转为小写字母 |
| swapcase() | 将字符串中所有的大写字母转为小写字母,所有的小写字母转为大写字母 |
| capitalize() | 把第一个字母转为大写字母,其他字母转为小写字母 |
| title() | 把每一个单词的第一个字母转为大写字母,其他字母转为小写字母 |
| center() | 居中对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| ljust() | 左对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| rjust() | 右对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| zfill() | 右对齐,只有一个参数:宽度,用 0 去填充 |
| split() | 从字符串左边开始分割,默认分隔符为空格,可用 sep 指定分隔符,可用 maxsplit 指定最大分割次数 |
| rsplit() | 从字符串右边开始分割,默认分隔符为空格,可用 sep 指定分隔符,可用 maxsplit 指定最大分割次数 |
| isidentifier() | 判定字符串是否由合法标识符组成 |
| isspace() | 判断字符串是否全部由空格字符组成(回车,换行,水平制表符) |
| isalpha() | 判断字符串是否全部由字母组成 |
| isdecimal() | 判断字符串是否全部由十进制的数字组成 |
| isnumeric() | 判断字符串是否全部由数字组成 |
| isalnum() | 判断字符串是否全部由字母和数字组成 |
| replace() | 第一个参数为被替换的子串,第二个参数为替换子串的字符串,第三个参数为最大替换次数(默认全部替换) |
| join() | 把列表和元组中的字符串合并成一个字符串,可设置字符串之间的连接符(默认无连接符) |
| format() | 将字符串进行格式化 |
4.6 列表、字典、元组、集合、字符串总结
*4.6.1 相关函数大汇总
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数/方法(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 数据类型 | 函数(方法) | 用法介绍 |
|---|---|---|
| 列表(list) | list() | 把一连串对象转为列表 |
| 列表(list) | del L | 删除列表L |
| 列表(list) | index(x) | 返回列表中第一个值等于x的索引,如果列表中不存在值为x的元素,则显示 ValueError |
| 列表(list) | append(x) | 在列表尾追加一个元素x |
| 列表(list) | extend(L) | 将列表L中所有的元素追加至列表尾 |
| 列表(list) | insert(index, x) | 在列表的index位置插入一个元素x |
| 列表(list) | remove(x) | 删除第一个值为x的元素,如果不存在值为x的元素则会抛出ValueError |
| 列表(list) | pop(index) | 删除并返回列表中索引为index的元素,index默认为-1(最后一个元素) |
| 列表(list) | clear(L) | 清空列表L |
| 列表(list) | reverse() | 对列表所有元素原素逆序排序 |
| 列表(list) | sort(reverse=False) | 对列表中的元素进行排序,默认 reverse=False 表示升序,reverse=True 表示降序 |
| 字典(dict) | dict() | 将一连串的对象转为字典 |
| 字典(dict) | del | 删除字典 |
| 字典(dict) | values() | 遍历字典的值(value),默认遍历字典的键(key) |
| 字典(dict) | items() | 遍历字典的元素【键值对】(key:values),默认遍历字典的键(key) |
| 字典(dict) | get(key) | 返回我们指定的键(key)所对应的值(value),不存在键(key)则返回 None |
| 字典(dict) | update(dict) | 将令一个字典中的全部元素全部添加至目标字典 |
| 字典(dict) | popitem() | 删除字典中的最后一个元素,字典为空显示 KeyError |
| 字典(dict) | pop(key) | 删除键(key)所对应的键值对 |
| 集合(set) | set() | 将一连串的对象转为集合 |
| 集合(set) | del | 删除集合 |
| 集合(set) | add() | 将集合中加入一个新的元素,如果原集合中已有该元素则忽略此操作 |
| 集合(set) | update() | 将另一个集合中的元素加入到该集合中,并自动去重 |
| 集合(set) | remove(x) | 删除指定的元素x,如果x不存在则显示KeyError |
| 集合(set) | discard(x) | 删除指定的元素x,如果x不存在则忽略本操作 |
| 集合(set) | pop() | 删除集合中的第一个元素 |
| 集合(set) | clear() | 清空集合 |
| 集合(set) | issubset() | 判断一个集合是否为另一个集合的子集 |
| 集合(set) | issuperset() | 判断一个集合是否为另一个集合的超集 |
| 集合(set) | isdisjoint() | 判断两个集合是否没有交集,没有交集返回True,有交集返回False |
| 集合(set) | intersection() | 求两个集合的交集 |
| 集合(set) | union() | 求两个集合的并集 |
| 集合(set) | difference() | 求两个集合的差集 |
| 集合(set) | symmetric_difference() | 求两个集合的对称差集 |
| 字符串(str) | index() | 查找子串第一次出现的位置,如果不存在子串则显示ValueError |
| 字符串(str) | rindex() | 查找子串最后一次出现的位置,如果子串不存在则显示ValueError |
| 字符串(str) | find() | 查找子串第一次出现的位置,如果不存在子串则返回-1 |
| 字符串(str) | rfind() | 查找子串最后一次出现的位置,如果不存在子串则返回-1 |
| 字符串(str) | upper() | 将字符串中所有的字母都转为大写字母 |
| 字符串(str) | lower() | 将字符串中所有的字母都转为小写字母 |
| 字符串(str) | swapcase() | 将字符串中所有的大写字母转为小写字母,所有的小写字母转为大写字母 |
| 字符串(str) | capitalize() | 把第一个字母转为大写字母,其他字母转为小写字母 |
| 字符串(str) | title() | 把每一个单词的第一个字母转为大写字母,其他字母转为小写字母 |
| 字符串(str) | center() | 居中对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| 字符串(str) | ljust() | 左对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| 字符串(str) | rjust() | 右对齐,第一个参数为宽度,第二个参数为填充符(默认为空) |
| 字符串(str) | zfill() | 右对齐,只有一个参数:宽度,用 0 去填充 |
| 字符串(str) | split() | 从字符串左边开始分割,默认分隔符为空格,可用 sep 指定分隔符,可用 maxsplit 指定最大分割次数 |
| 字符串(str) | rsplit() | 从字符串右边开始分割,默认分隔符为空格,可用 sep 指定分隔符,可用 maxsplit 指定最大分割次数 |
| 字符串(str) | isidentifier() | 判定字符串是否由合法标识符组成 |
| 字符串(str) | isspace() | 判断字符串是否全部由空格字符组成(回车,换行,水平制表符) |
| 字符串(str) | isalpha() | 判断字符串是否全部由字母组成 |
| 字符串(str) | isdecimal() | 判断字符串是否全部由十进制的数字组成 |
| 字符串(str) | isnumeric() | 判断字符串是否全部由数字组成 |
| 字符串(str) | isalnum() | 判断字符串是否全部由字母和数字组成 |
| 字符串(str) | replace() | 第一个参数为被替换的子串,第二个参数为替换子串的字符串,第三个参数为最大替换次数(默认全部替换) |
| 字符串(str) | join() | 把列表和元组中的字符串合并成一个字符串,可设置字符串之间的连接符(默认无连接符) |
| 字符串(str) | format() | 将字符串进行格式化 |
4.6.2 有序,无序;可变,不可变
1️⃣ 有序序列,即可以说出序列的第一个元素,第二个元素,元素在序列中的位置是固定的,我们可以通过索引去直接访问指定位置上的元素,并且支持切片操作:列表,元组,字符串
无序序列,即其元素在序列中的位置不是固定的,我们不可以通过索引去访问这些元素,不支持切片操作:字典,集合
2️⃣ 可变序列,即我们可以去修改其中元素的值,并且可以为其自由的增加元素和删除已有的元素:列表,字典,集合
不可变序列,即其中的元素值是固定的,我们不可以随意的去增删改其中的元素:元组,字符串
4.7 序列解包
🚩序列解包是对多个对象同时赋值的简洁形式,我们其实在 2.4.2 赋值运算符 中就用过这个知识点,只不过当时没有介绍它的名字,序列解包可以把一个序列或者一个可迭代对象中的多个元素同时赋值给多个变量,但是要求赋值运算符左侧变量的数量和右侧的数值是一致的.
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/14 19:00
# 欢迎大家关注AIoT相关博客~
print('-----多个变量同时赋值:-----')
a, b, c = 1, [1, 2, 3], '辰chen'
print(a, type(a))
print(b, type(b))
print(c, type(c))
print('-----用range()产生一系列数并逐个赋值-----')
n, m, t = range(3)
print(n, m, t)
print('-----用map()进行序列解包-----')
a, b, c = map(str, range(3))
'''
map()函数后续会详细讲解
这里只需要知道 map(int, range(3))
是将 range(3) 产生的三个数转为 str 类型即可
'''
print(a, type(a))
print(b, type(b))
print(c, type(c))
print('-----将列表中的元素逐个赋值-----')
l = [6.66, True, '辰chen']
x, y, z = l
print(x, y, z)
print('-----将元组中的元素逐个赋值-----')
t = (6.66, True, '辰chen')
x, y, z = t
print(x, y, z)
print('-----将集合中的元素逐个赋值-----')
s = {6.66, True, '辰chen'}
x, y, z = s
print(x, y, z)
print('-----将字典中的元素逐个赋值-----')
s = {1:6.66, 2:True, 3:'辰chen'}
x, y, z = s # 默认赋值的是键(key)
print(x, y, z)
# 赋值为值(value):
x, y, z = s.values()
print(x, y, z)
# 赋值为元素(key:value):
x, y, z = s.items()
print(x, y, z)
print(type(x)) # 对字典的元素解包后为元组类型
print('-----将字符串进行解包-----')
x, y, z = 'XYZ'
print(x, y, z)
print('-----利用序列解包进行多个赋值-----')
s = {'a':1, 'b':2, 'c':3}
for k, v in s.items():
print('The key is {0},The value is {1}'.format(k, v))
key = ['a', 'b', 'c']
value = [1, 2, 3]
for k, v in zip(key, value): # 使用zip()进行解包,后续会介绍这个函数
print(k, v)

5.Python国的一国多治
什么是函数?函数其实就是执行特定任务和完成特定功能的一段代码,我们在 Python 中可以自己书写函数,如我们可以用 def,lambda 来告诉编译器这是我们自己写的函数,也可以使用系统中已经写好的函数:内置函数,这些函数你可以理解为因为在使用 Python 开发的过程中,一直在频繁的进行使用,故开发者为了方便,把这些代码打包成一个又一个函数,可供大家一直调用。在本章节学习中,*5.1 Python中常用的内置函数 会给大家介绍一部分的内置函数,这些函数我们会经常的使用,必须学会它们的使用规则,本章节标题为 Python 国的一国多制,那是因为我们可以把每一个函数都当成一种政体,它们一起相互作用组成了 Python 这个伟大的国度,并且函数与函数之间相互独立(函数内可以调用其他函数)。接下来,就让我们进入面向过程最后一节的学习。
*5.1 Python中常用的内置函数
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可
| 函数 | 功能说明 |
|---|---|
| len(obj) | 返回对象 obj 中包含的元素个数 |
| max(…) | 返回一个序列元素的最大值 |
| min(…) | 返回一个序列元素的最小值 |
| abs(x) | 返回数字 x 的绝对值或复数 x 的模 |
| sum(x, start=0) | 求一个序列中所有元素的和 |
| reversed(seq) | 返回seq中所有元素逆序的结果 |
| sorted(iterable, key=None, reverse=False) | 返回排序后的列表,iterable为要排序的对象,key指定排序规则,reverse用来指定升降序 |
| bin(x) | 把整数x转为二进制串 |
| oct(x) | 把整数x转为八进制串 |
| hex(x) | 把整数x转为十六进制串 |
| zip() | 将对应位置上的元素压缩在一起 |
| id(obj) | 返回 obj 的内存地址 |
| range(start, end, step) | 返回一个左闭右开[start, end),步长为 step 的对象 |
| type(obj) | 返回 obj 的类型 |
| map(func, *iterables) | 返回若干个map对象,函数func参数来自iterables指定的迭代对象 |
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/16 12:45
# 欢迎大家关注AIoT相关博客~
# len():返回元素的长度
a = [1, 2, 3, 4, 5]
print('a的长度是:', len(a))
# max():返回元素的最大值
print('a中的最大值是:', max(a))
# min():返回元素的最小值
print('a中的最小值是:', min(a))
# abs():返回绝对值
print('-3的绝对值是:', abs(-3))
# sum():返回序列中全部元素的和
print('[1, 2, 3, 4, 5]的和为:', sum(a))
# reversed():返回一个序列的逆序
b = reversed(a)
print('a逆序的结果为:', end = '')
for item in b:
print(item, end = ' ')
print()
# sorted():返回排序后的列表
c = [3, 2, 5, 1, 4]
c = sorted(c)
print('c排序的结果为:', end = '')
for item in c:
print(item, end = ' ')
# bin():把整数转为二进制
print('8的二进制为:', bin(8))
# oct():把整数转为八进制
print('10的八进制为:', oct(10))
# hex():把整数转为十六进制
print('30的十六进制为:', hex(30))
# zip():将对应位置的元素压缩在一起
a = [1, 2, 3, 4, 5]
b = ['h', 'e', 'l', 'l', 'o']
print(list(zip(a, b)))
# id():返回内存地址
d = 666
print('666的内存地址是:', id(666))
# range():产生一个[start, end),步长为step的对象
a = range(10)
print(a)
# type():返回对象的类型
print('数字7的类型为:',type(7))
# map():把原序列的元素经过func操作
print(list(map(str, range(5)))) # 把[0 ~ 5)转为字符串存入列表
# 在同一行输入两个数并赋值
a,b = map(int,input('输入两个数(数字之间用空格隔开):').split())
print(a, b)
5.2 函数的创建与调用
🚩为什么需要函数?
1️⃣ 复用代码:有一些代码我们可能会频繁的进行使用,故我们可以把这些代码打包成函数,我们在需要的时候调用函数即可.
2️⃣ 隐藏实现细节:拿榨汁机举例子,我们在使用榨汁机的时候,只需要掌握基本的开关即可,完全没必要去了解其内部是如何组装,电路板之间怎么链接的问题,函数也是一样的,我们可以把具体代码封装起来,只需要会调用即可
3️⃣提高可维护性,可读性,便于调试:我们以后写工程代码可能会特别长,一个成千上万行的代码我们去找 bug 是十分困难的,读懂这种代码也是十分的困难的,如果我们把代码转为一个又一个函数,只需要找到具体的函数进行更改即可,并且看起来会更加的直观。
函数的创建语法格式:
def 函数名(参数1, 参数2, ...):
函数体
return xxx
我们还是用榨汁机去理解这个语法格式,def 函数名 为定义这是一个机器,并给他命名;这里函数的命名满足标识符的命名原则,详见:*1.2.1 标识符和保留字,具体它什么机器我们还得去看它的执行功能是什么(即函数体),比如我们的榨汁机实现榨汁功能,那么它的函数体就是实现榨汁这个操作,我们榨汁当然还要有原料,比如榨胡萝卜汁,榨西瓜汁等,胡萝卜,西瓜就是我们传入给函数的参数;最后我们榨汁肯定是要给人喝的,return xxx 的含义就是把操作完的值返回给调用函数的地方,函数的调用的语法格式为:
函数名(参数1, 参数2, ...)
下面我们举例子来让大家理解,比如我们实现一个 cal 函数,其函数的目的是接收两个参数,并把它们的值相加并返回相加后的值:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/17 23:02
# 欢迎大家关注AIoT相关博客~
def cal(a, b):
c = a + b
return c
a, b = map(int, input().split())
res = cal(a, b)# 调用函数 cal,并把函数的返回值赋值给c
print(res)

5.3 函数的参数传递
🚩形式参数与实际参数:我们把定义函数中的参数称为形式参数,把调用函数的位置的参数称为实际参数,如下述代码:
def cal(a, b): # 这里的 a, b
c = a + b
return c
res = cal(1, 2) # 这里的 1, 2 称为实际参数
print(res)
函数的参数传递有两种方法:
1️⃣ 位置传参:按照位置进行传参,比如在这个代码中:
def cal(a, b):
c = a + b
return c
res = cal(1, 2)
print(res)
在这个代码中,1 会传给 a,2 会传给b,位置传参其实就是把实际参数中的位置和形式参数中的位置一一进行对应赋值
2️⃣ 关键字传参:按照关键字的命名进行传参,如下述代码:
def cal(a, b):
c = a + b
return c
res = cal(b = 1, a = 2)
print(res)
在这个代码中,我们在调用函数的时候已经规定了 b = 1, a = 2;故对于这样的调用,在给形式参数赋值时就不会执行位置传参,而会执行关键字传参,在形式参数中 b = 1, a = 2
5.4 函数的返回值
🚩我们知道,函数的返回值即 return 后面所跟的值,返回的位置为调用函数的位置,就比如简单的实现两数相加:
def cal(a, b):
c = a + b
return c
a, b = map(int, input().split())
res = cal(a, b) # 调用函数 cal,并把函数的返回值赋值给c
print(res)
调用函数的位置为 cal(a, b),在 cal 函数中不难看出有 return 语句,意思为把 c 的值返回给调用函数的地方,你可以粗暴的理解为 cal(a, b) = c,即删掉 cal(a, b) 语句,换上一个 c,即 res = cal(a, b) 变成了 res = c.
如果你学过 C/C++,你知道,函数至多返回一个值,不可能返回两个值或者更多的值,我们的 Python 则不然,Python 可以同时返回多个函数值:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 8:38
# 欢迎大家关注AIoT相关博客~
def find(num):
odd = [] # 用来存奇数
even = [] # 用来存偶数
for i in num:
if i % 2 == 0:
even.append(i)
else:
odd.append(i)
return odd, even
print(find([2, 83, 71, 42, 26, 99]))

我们可以看出,Python 支持返回多个值,且当函数有多个返回值的时候,返回结果为元组
5.5 函数的参数定义
1️⃣ 函数定义默认值参数,函数在定义的时候,我们可以给形式参数设置默认值,只有当默认值不符的时候才需要传递实参:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 10:22
# 欢迎大家关注AIoT相关博客~
def fun(a, b = 10): # 给b设置默认值为10
print('a =', a)
print('b =', b)
fun(1) # 只传入一个参数,只给a赋值
fun(1, 10) # 传入两个参数,但是传给b的参数等于b的默认参数
fun(1, 2) # 传入两个参数,传给b的参数不等于b的默认参数
我们知道,类似 print() 这类函数是系统为我们准备好的,不妨想一下,pint() 是默认输出后换行的,我们可以修改 end 使 print() 不是默认换行,这是否意味着系统的 print() 函数具体实现中是给 end 默认赋值为 \n 呢?
我们可以在 PyCharm 中打出一个 print(),然后按下键盘中的 Ctrl 键同时鼠标指向 print(),点击 print() 就可以查看 print() 实现代码:

从这里我们确确实实可以看出,系统实现 print() 函数的时候,设置默认参数 end='\n',故当我们不传入 end 的时候,默认输出换行,我们当然也可以自行设置 end 的值,达到我们想要的输出结构
2️⃣ 个数可变的位置参数,我们在写函数的时候,我们可能有时候不能确定我们到底有几个位置参数,这个时候,我们就可以采取*参数名的方式,最终返回的是一个元组:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 10:22
# 欢迎大家关注AIoT相关博客~
def printf(*a):
print(a)
printf(10)
printf(10, 20)
printf(10, 20, 30, 40)
3️⃣ 个数可变的关键字形参,和位置参数一样,我们同样可以按照类似的方式去定义个数可变的关键字形参,语法格式为**参数名,最终的返回值是一个字典
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 10:22
# 欢迎大家关注AIoT相关博客~
def printf(**a):
print(a)
printf(a = 10)
printf(a = 10, b = 20)
printf(a = 10, b = 20, c = 30, d = 40)
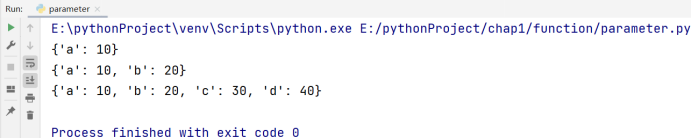
4️⃣ 同时有个数可变的关键字形参和个数可变的位置形参,要求个数可变的位置形参放在个数可变的关键字形参之前,否则报错
def act(*a, **b):
pass
5.6 变量的作用域
🚩变量的作用域其实就是指程序代码能访问该变量的区域,我们根据变量的有效范围可以把变量划分为:
1️⃣ 局部变量:在函数内定义使用的变量,只在函数内有效,局部变量可以使用 global 声明,声明后的变量就会变成全局变量
2️⃣ 全局变量:函数体外定义的变量,可用于函数内外
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 16:53
# 欢迎大家关注AIoT相关博客~
def add(a,b):
c = a + b
# c 就称为局部变量,因为c在是函数体内进行定义的变量
# a, b为函数的形参,作用范围也是函数内部,相当于局部变量
print(c)
#print(c) 报错,因为 a, c超出了起作用的范围(超出了作用域)
#print(a)
name='辰chen' #name的作用范围为函数内部和外部都可以使用 -->称为全局变量
print(name)
def func1():
print(name)
#调用函数
func1()
def func2():
global age #函数内部定义的变量称为局部变量
# 局部变量使用global声明,这个变量实际上就变成了全局变量
age=19
print(age)
func2()
print(age)
5.7 递归函数
🚩递归函数其实就是指在函数内部自己调用自己的这么一类函数,当然,自己调用自己也是有一个度的,否则就会:爱的魔力转圈圈,出不来可不行,所以,递归函数最重要的一部分就是递归终止的条件,比如我们要计算 n 的阶乘,我们知道 n 的阶乘等于 n * n-1 的阶乘,上述思想其实就是递归的思想,退出递归的条件则是当 n = 1 的时候,返回 1
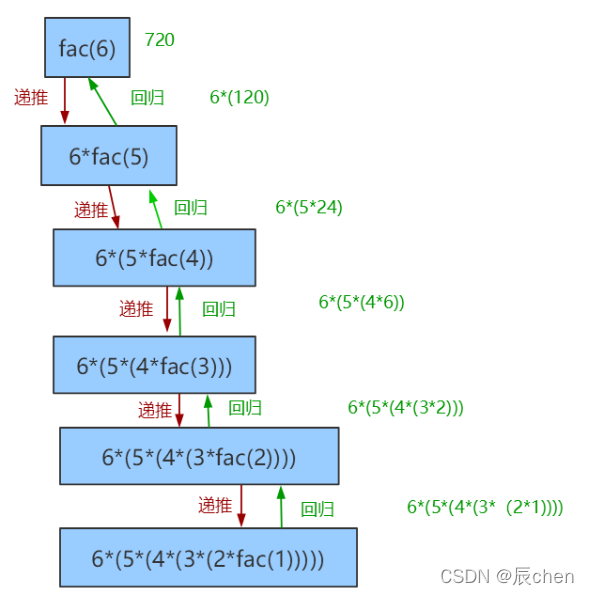
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 17:18
# 欢迎大家关注AIoT相关博客~
def fac(n):
if n == 1: # 当n=1,退出递归
return 1
else:
return n * fac(n - 1) # n的阶乘等于n * n-1的阶乘
print(fac(6))
递归的调用过程 :
每递归调用一次函数,都会在栈内存分配一个栈帧,每执行完一次函数,都会释放相应的空间(这一点不需要理解,学完数据结构后,会自然理解这句话的含义)
递归的优缺点:
缺点:占用内存多,效率低下,
优点:思路和代码简单
5.8 lambda 表达式
🚩lambda 表达式用来声明匿名函数,即一些我们没有命名的,临时需要调用的小函数,lambda 表达式常用在我们临时需要一个类似函数的功能但又不想定义函数的场合,当然,我们也可以使用 lambda 表达式定义具名函数。
lambda 表达式只可以包含一个表达式,不允许包含复杂语句和结构,但是我们可以在表达式中调用其他的函数,lambda 表达式的计算结果相当于函数的返回值.
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/17 18:56
# 欢迎大家关注AIoT相关博客~
# 我们可以给我们的 lambda 表达式起一个名字
add = lambda x, y, z: x + y + z
print(add(1, 2, 3))
# lambda 表达式支持默认参数
add = lambda x, y = 2, z = 3: x + y + z
print(add(1))
# lambda 表达式可作为函数参数
l = [item for item in range(5)]
print(l)
print(list(map(lambda x: x + 5, l)))
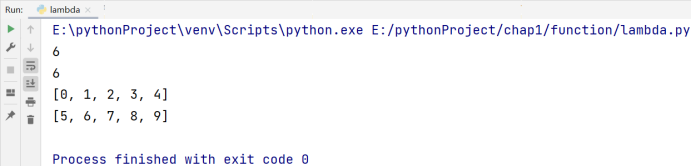
*5.9 生成器函数
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 包涵 yield 语句的函数可用来创建生成器对象,我们称这样的函数为生成器函数,yield 语句与 return 语句作用类似,都用来返回函数的值。与 return 语句不同的是,return 语句一旦执行就会立刻结束函数的运行,而每次执行到 yield 语句并返回一个数之后会暂停或挂起后面代码的执行,下次通过生成器对象的 __next__() 方法、内置函数 next()、for 循环遍历生成器对象元素或其他方式显示“索要”数据时恢复执行。生成器具有惰性求值的特点,适合大数据处理。
例:编写并使用能够生成斐波那契数列的生成器函数
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/17 15:27
# 欢迎大家关注AIoT相关博客~
def f():
a, b = 1, 1
while True:
yield a
a, b = b, a + b
a = f() # 创建生成器对象
for i in range(10): # 斐波那契数列中前10个元素
print(a.__next__(), end = ' ')
print()
for i in f(): # 斐波那契数列中第一个大于100的元素
if i > 100:
print(i, end = ' ')
break
6.Python程序设计训练场
如果你学到现在,那么恭喜,面向过程部分的知识你已经全部掌握了,你已经具备了初级的编程能力,我个人认为,虽然我们未来的工作使必然会大量涉及面向对象的知识点的,但我们更应该注重面向过程的程序设计的思维,下面的文章,我分为了:新手村,打怪刷级,进阶之道三个模块,分别对应题目难度:简单,中等,较难;以及最后一小节是对算法竞赛的一个大致科普.
6.1 新手村
6.1.1 差
题目描述:
读取四个整数 A,B,C,D,并计算 (A×B−C×D) 的值。
输入格式:
输入共四行,第一行包含整数 A,第二行包含整数 B,第三行包含整数 C,第四行包含整数 D。
输出格式:
输出格式为 DIFERENCA = X,其中 X 为 (A×B−C×D) 的结果。
输入样例:
5
6
7
8
输出样例:
DIFERENCA = -26
在线评测环境:AcWing 608. 差
代码:
A = int(input())
B = int(input())
C = int(input())
D = int(input())
print('DIFERENCA =', A * B - C * D)
6.1.2 圆的面积
题目描述:
计算圆的面积的公式定义为 A=πR2。
请利用这个公式计算所给圆的面积。
π的取值为 3.14159。
输入格式:
输入包含一个浮点数,为圆的半径 R。
输出格式:
输出格式为 A=X,其中 X为圆的面积,用浮点数表示,保留四位小数。
输入样例:
2.00
输出样例:
A=12.5664
在线评测环境:AcWing 604. 圆的面积
代码:
R = float(input())
print('A=%.4f' % (3.14159 * R * R))
6.1.3 平均数1
题目描述:
读取两个浮点数 A 和 B的值,对应于两个学生的成绩。
请你计算学生的平均分,其中 A的成绩的权重为 3.5,B 的成绩的权重为 7.5。
输入格式:
输入占两行,每行包含一个浮点数,第一行表示 A,第二行表示 B。
输出格式:
输出格式为 MEDIA = X,其中 X为平均分,结果保留五位小数。
成绩的取值范围在 0 到 10 之间,且均保留一位小数。
输入样例:
5.0
7.1
输出样例:
MEDIA = 6.43182
在线评测环境:AcWing 606. 平均数1
代码:
A = float(input())
B = float(input())
print('MEDIA = %.5f' % (A * 3.5 / 11 + B * 7.5 / 11))
6.1.4 时间转换
题目描述:
读取一个整数值,它是工厂中某个事件的持续时间(以秒为单位),请你将其转换为小时:分钟:秒来表示。
输入格式:
输入一个整数 N。
输出格式:
输出转换后的时间表示,格式为 hours:minutes:seconds。
输入样例:
556
输出样例:
0:9:16
在线评测环境:AcWing 654. 时间转换
代码:
a = int(input())
print("%d:%d:%d" % (a // 3600, a % 3600 // 60, a % 60))
6.1.5 天数转换
题目描述:
读取对应于一个人的年龄(以天为单位)的整数值,并转化为年,月和日表示方式输出,年、月、日分别对应 ano(s), mes(es), dia(s)。
注意:为了方便计算,假设全年 365天,每月 30 天。 数据保证,不会出现 12 个月和几天的情况,例如 360,363 或 364。
输入格式:
输入一个整数 N。
输出格式:
参照输出样例,输出转换后的天数表达。
输入样例:
400
输出样例:
1 ano(s)
1 mes(es)
5 dia(s)
在线评测环境:AcWing 655. 天数转换
代码:
a = int(input())
ano = a // 365
a -= ano * 365
mes = a // 30
a -= mes * 30
dia = a
print('%d ano(s)' % ano)
print('%d mes(es)' % mes)
print('%d dia(s)' % dia)
6.1.6 A + B
题目描述:
输入两个整数,求这两个整数的和是多少。
输入格式:
输入两个整数A,B,用空格隔开
输出格式:
输出一个整数,表示这两个数的和
输入样例:
3 4
输出样例:
7
在线评测环境:AcWing 1. A + B
代码:
a, b = map(int, input().split())
print(a + b)
6.1.7 倍数
题目描述:
读取两个正整数值 A 和 B。
如果其中一个是另一个的整数倍,则输出 Sao Multiplos,否则输出 Nao sao Multiplos。
输入格式:
共一行,两个整数 A 和 B。
输出格式:
按题目所述,输出结果。
输入样例:
6 24
输出样例:
Sao Multiplos
在线评测环境:AcWing 665. 倍数
代码:
a, b = map(int, input().split())
if a % b == 0 or b % a == 0:
print("Sao Multiplos")
else:
print("Nao sao Multiplos")
6.1.8 三角形
题目描述:
读取三个浮点数 A,B 和 C 并验证是否可以用它们形成三角形。
如果可能,则计算并输出三角形的周长:
Perimetro = XX.X
如果不可能,则计算并输出以 A 和 B 为底以 C 为高的梯形面积:
Area = XX.X
输入格式:
共一行,包含三个浮点数 A,B,C。
输出格式:
按题目描述格式,输出答案,答案保留一位小数。
输入样例1:
6.0 4.0 2.0
输出样例1:
Area = 10.0
输入样例2:
6.0 4.0 2.1
输出样例2:
Perimetro = 12.1
在线评测环境:AcWing 664. 三角形
代码:
a, b, c = map(float, input().split())
if a + b > c and abs(a - b) < c:
print("Perimetro = {0:.1f}".format(a + b + c))
else:
print("Area = {0:.1f}".format(((a + b) * c) / 2))
6.1.9 游戏时间
题目描述:
读取两个整数 A 和 B,表示游戏的开始时间和结束时间,以小时为单位。
然后请你计算游戏的持续时间,已知游戏可以在一天开始并在另一天结束,最长持续时间为 24 小时。
如果 A 与 B 相等,则视为持续了 24 小时。
输入格式:
共一行,包含两个整数 A 和 B。
输出格式:
输出格式为 O JOGO DUROU X HORA(S),其中 X 为游戏持续时间。
输入样例1:
16 2
输出样例1:
O JOGO DUROU 10 HORA(S)
输入样例2:
0 0
输出样例2:
O JOGO DUROU 24 HORA(S)
输入样例3:
2 16
输出样例3:
O JOGO DUROU 14 HORA(S)
在线评测环境:AcWing 667. 游戏时间
代码:
a, b = map(int, input().split())
if a == b:
print("O JOGO DUROU 24 HORA(S)")
else:
print("O JOGO DUROU {0} HORA(S)".format((24 - a + b) % 24))
6.1.10 连续奇数的和 1
题目描述:
给定两个整数 X 和 Y,输出在他们之间(不包括 X 和 Y)的所有奇数的和。
输入格式:
第一行输入 X,第二行输入 Y。
输出格式:
输出一个整数,表示所有满足条件的奇数的和。
输入样例1:
6
-5
输出样例1:
5
输入样例2:
15
12
输出样例2:
13
输入样例3:
12
12
输出样例3:
0
在线评测环境:AcWing 714. 连续奇数的和 1
代码:
l = int(input())
r = int(input())
if l > r:
l, r = r, l
res = 0
for i in range(l + 1, r):
if abs(i) % 2:
res += i
print(res)
6.1.11 递增序列
题目描述:
读取一系列的整数 X,对于每个 X,输出一个 1,2,…,X 的序列。
输入格式:
输入文件中包含若干个整数,其中最后一个为 0,其他的均为正整数。
每个整数占一行。
对于输入的正整数,按题目要求作输出处理。
对于最后一行的整数 0,不作任何处理。
输出格式:
对于每个输入的正整数 X,输出一个从 1 到 X 的递增序列,每个序列占一行。
输入样例:
5
10
3
0
输出样例:
1 2 3 4 5
1 2 3 4 5 6 7 8 9 10
1 2 3
在线评测环境:AcWing 721. 递增序列
代码:
while True:
n = int(input())
if not n:
break
for i in range(n):
print(i + 1, end=' ')
print()
6.1.12 PUM
题目描述:
输入两个整数 N 和 M,构造一个 N 行 M 列的数字矩阵,矩阵中的数字从第一行到最后一行,按从左到右的顺序依次为 1,2,3,…,N×M。
矩阵构造完成后,将每行的最后一个数字变为 PUM。
输出最终矩阵。
输入格式:
共一行,包含两个整数 N 和 M。
输出格式:
输出最终矩阵,具体形式参照输出样例。
输入样例:
7 4
输出样例:
1 2 3 PUM
5 6 7 PUM
9 10 11 PUM
13 14 15 PUM
17 18 19 PUM
21 22 23 PUM
25 26 27 PUM
在线评测环境:AcWing 723. PUM
代码:
m, n = map(int, input().split())
tot = 0
for i in range(m):
s = ''
for j in range(n):
tot += 1
if tot % n:
s += str(tot) + ' '
else:
s += 'PUM'
print(s)
6.1.13 循环相克令
题目描述:
循环相克令是一个两人玩的小游戏。
令词为“猎人、狗熊、枪”,两人同时说出令词,同时做出一个动作——猎人的动作是双手叉腰;狗熊的动作是双手搭在胸前;枪的动作是双手举起呈手枪状。
双方以此动作判定输赢,猎人赢枪、枪赢狗熊、狗熊赢猎人,动作相同则视为平局。
现在给定你一系列的动作组合,请你判断游戏结果。
输入格式:
第一行包含整数 T,表示共有 T 组测试数据。
接下来 T 行,每行包含两个字符串,表示一局游戏中两人做出的动作,字符串为 Hunter, Bear, Gun 中的一个,这三个单词分别代表猎人,狗熊和枪。
输出格式:
如果第一个玩家赢了,则输出 Player1。
如果第二个玩家赢了,则输出 Player2。
如果平局,则输出 Tie。
输入样例:
3
Hunter Gun
Bear Bear
Hunter Bear
输出样例:
Player1
Tie
Player2
在线评测环境:AcWing 763. 循环相克令
代码:
n = int(input())
r = ["Hunter", "Bear", "Gun"]
for i in range (n):
p1, p2 = input().split()
r1 = r.index(p1)
r2 = r.index(p2)
if r1 == r2:
print ("Tie")
elif (r1 + 1) % 3 == r2:
print ("Player2")
else:
print ("Player1")
6.1.14 字符串加空格
题目描述:
给定一个字符串,在字符串的每个字符之间都加一个空格。
输出修改后的新字符串。
输入格式:
共一行,包含一个字符串。注意字符串中可能包含空格。
输出格式:
输出增加空格后的字符串。
输入样例:
test case
输出样例:
t e s t c a s e
在线评测环境:AcWing 765. 字符串加空格
代码:
s = input()
res = ''
for x in list(s):
res += x + ' '
print(res)
6.1.15 忽略大小写比较字符串大小
题目描述:
一般我们用 strcmp 可比较两个字符串的大小,比较方法为对两个字符串从前往后逐个字符相比较(按 ASCII 码值大小比较),直到出现不同的字符或遇到 \0 为止。
如果全部字符都相同,则认为相同;如果出现不相同的字符,则以第一个不相同的字符的比较结果为准。
但在有些时候,我们比较字符串的大小时,希望忽略字母的大小,例如 Hello 和 hello 在忽略字母大小写时是相等的。
请写一个程序,实现对两个字符串进行忽略字母大小写的大小比较。
输入格式:
输入为两行,每行一个字符串,共两个字符串。注意字符串中可能包含空格。
数据保证每个字符串的长度都不超过 80。
输出格式:
如果第一个字符串比第二个字符串小,输出一个字符 <。
如果第一个字符串比第二个字符串大,输出一个字符 >。
如果两个字符串相等,输出一个字符 =。
输入样例:
Hello
hello
输出样例:
=
在线评测环境:AcWing 768. 忽略大小写比较字符串大小
代码:
a = input()
b = input()
a = a.lower()
b = b.lower()
if a == b:
print('=')
elif a > b:
print('>')
else:
print('<')
6.1.16 信息加密
题目描述:
在传输信息的过程中,为了保证信息的安全,我们需要对原信息进行加密处理,形成加密信息,从而使得信息内容不会被监听者窃取。
现在给定一个字符串,对其进行加密处理。
加密的规则如下:
1.字符串中的小写字母,a 加密为 b,b 加密为 c,…,y 加密为 z,z 加密为 a。
2.字符串中的大写字母,A 加密为 B,B 加密为 C,…,Y 加密为 Z,Z 加密为 A。
3.字符串中的其他字符,不作处理。
请你输出加密后的字符串。
输入格式:
共一行,包含一个字符串。注意字符串中可能包含空格。
输出格式:
输出加密后的字符串。
输入样例:
Hello! How are you!
输出样例:
Ifmmp! Ipx bsf zpv!
在线评测环境:AcWing 767. 信息加密
代码:
s = input()
c = ''
for i in range (len(s)):
if ( s[i] >="a" and s[i] <"z" ) or (s[i] >= "A" and s[i] <"Z"):
c += chr(ord(s[i]) + 1)
elif s[i] == "z":
c += "a"
elif s[i] == "Z":
c += "A"
else:
c += s[i]
print (c)
6.1.17 区间求和
题目描述:
输入两个整数 l 和 r,请你编写一个函数,def sum(l, r),计算并输出区间 [l,r] 内所有整数的和。
输入格式:
共一行,包含两个整数 l 和 r。
输出格式:
共一行,包含一个整数,表示所求的和。
输入样例:
3 5
输出样例:
12
在线评测环境:AcWing 807. 区间求和
代码:
def sum(l, r):
res = 0
for i in range (l, r + 1):
res += i
return res
m, n = map(int, input().split())
print(sum(m, n))
6.1.18 x和y的最大值
题目描述:
输入两个整数 x 和 y,请你编写一个函数,def max(x, y),计算并输出 x 和 y 的最大值。
输入格式:
共一行,包含两个整数 x 和 y。
输出格式:
共一行,包含一个整数,表示两个数中较大的那个数。
输入样例:
3 6
输出样例:
6
在线评测环境:AcWing 805. x和y的最大值
代码:
def max(x, y):
return y if y > x else x
a, b = map(int, input().split())
print(max(a, b))
6.2 打怪刷级
6.2.1 游戏时间2
题目描述:
读取四个整数 A,B,C,D,用来表示游戏的开始时间和结束时间。
其中 A 和 B 为开始时刻的小时和分钟数,C 和 D 为结束时刻的小时和分钟数。
请你计算游戏的持续时间。
比赛最短持续 1 分钟,最长持续 24 小时。
输入格式:
共一行,包含四个整数 A,B,C,D。
输出格式:
输出格式为 O JOGO DUROU X HORA(S) E Y MINUTO(S),表示游戏共持续了 X 小时 Y 分钟。
输入样例1:
7 8 9 10
输出样例1:
O JOGO DUROU 2 HORA(S) E 2 MINUTO(S)
输入样例2:
7 7 7 7
输出样例2:
O JOGO DUROU 24 HORA(S) E 0 MINUTO(S)
输入样例3:
7 10 8 9
输出样例3:
O JOGO DUROU 0 HORA(S) E 59 MINUTO(S)
在线评测环境:AcWing 668. 游戏时间2
代码:
a = input()
b = [int(x) for x in a.split()]
if b[2] < b[0] or (b[2] == b[0] and b[1] >= b[3]):
b[2] += 24
if b[3] < b[1]:
b[3] += 60
b[2] -= 1
print('O JOGO DUROU %d HORA(S) E %d MINUTO(S)' % (b[2] - b[0], b[3] - b[1]))
6.2.2 平均数3
题目描述:
读取 4 个数字 N1,N2,N3,N4,这 4 个数字都是保留 1 位小数的浮点数,对应于学生获得的 4 个分数。
这 4 个分数的权重分别为 2,3,4,1,请你计算学生成绩的平均值 X 并输出 Media: X。
接下来分为以下三种情况:
1.如果平均值为 7.0 或更高,则输出 Aluno aprovado.。
2.如果平均值小于 5.0,则输出 Aluno reprovado.。
3.如果平均值大于等于 5.0 并且小于 7.0,则输出 Aluno em exame.,并再读取一个数字 Y,然后输出 Nota do exame: Y。接下来重新计算平均值 Z=(X+Y)/2,如果 Z 大于或等于 5.0,则输出 Aluno aprovado.,否则输出 Aluno reprovado.。最后输出 Media final: Z,表示学生的最终成绩。
输入格式:
输入中包含四个浮点数,表示学生的四个成绩。
也有部分满足情况 3的数据,多包含一个浮点数。
输出格式:
输出的结果均保留 1 位小数,具体形式参照题目描述和输出样例。
输入样例1:
2.0 4.0 7.5 8.0
6.4
输出样例1:
Media: 5.4
Aluno em exame.
Nota do exame: 6.4
Aluno aprovado.
Media final: 5.9
输入样例2:
2.0 6.6 4.0 9.0
输出样例2:
Media: 4.9
Aluno reprovado.
输入样例3:
9.0 4.0 8.5 9.0
输出样例3:
Media: 7.3
Aluno aprovado.
在线评测环境:AcWing 661. 平均数3
代码:
a, b, c, d = map(float, input().split())
x = (a * 2 + b * 3 + c * 4 + d) / 10
print("Media: %.1f" % x)
if(x >= 7.0):
print("Aluno aprovado.")
if(x < 5.0):
print("Aluno reprovado.")
if(x >= 5.0 and x < 7.0):
print("Aluno em exame.")
y = float(input())
print("Nota do exame: %0.1f" % y)
z = (x + y) / 2
if(z >= 5.0):
print("Aluno aprovado.")
else:
print("Aluno reprovado.")
print("Media final: %0.1f" % z)
6.2.3 简单斐波那契
题目描述:
以下数列 0 1 1 2 3 5 8 13 21 ... 被称为斐波纳契数列。
这个数列从第 3 项开始,每一项都等于前两项之和。
输入一个整数 N,请你输出这个序列的前 N 项。
输入格式:
一个整数 N。
输出格式:
在一行中输出斐波那契数列的前 N 项,数字之间用空格隔开。
输入样例:
5
输出样例:
0 1 1 2 3
在线评测环境:AcWing 717. 简单斐波那契
代码:
n = int(input())
a, b = 0, 1
s = ''
for i in range(n):
s += str(a) + ' '
c = a
a = b
b = c + a
print(s)
6.2.4 完全数
题目描述:
一个整数,除了本身以外的其他所有约数的和如果等于该数,那么我们就称这个整数为完全数。
例如,6 就是一个完全数,因为它的除了本身以外的其他约数的和为 1+2+3=6。
现在,给定你 N 个整数,请你依次判断这些数是否是完全数。
输入格式:
第一行包含整数 N,表示共有 N 个测试用例。
接下来 N 行,每行包含一个需要你进行判断的整数 X。
输出格式:
每个测试用例输出一个结果,每个结果占一行。
如果测试数据是完全数,则输出 X is perfect,其中 X 是测试数据。
如果测试数据不是完全数,则输出 X is not perfect,其中 X 是测试数据。
输入样例:
3
6
5
28
输出样例:
6 is perfect
5 is not perfect
28 is perfect
在线评测环境:AcWing 725. 完全数
代码:
n = int(input())
for i in range(n):
x = int(input())
if x == 1:
t = 0
else:
t = 1
for j in range(2, int(x ** 0.5) + 1):
if x % j == 0 and j != x ** 0.5:
t += j + x / j
if x % j == 0 and j == x ** 0.5:
t += j
if t == x:
print("%d is perfect" % x)
else:
print("%d is not perfect" % x)
6.2.5 质数
题目描述:
一个大于 1 的自然数,如果除了 1 和它自身外,不能被其他自然数整除则称该数为质数。
例如 7 就是一个质数,因为它只能被 1 和 7 整除。
现在,给定你 N 个大于 1 的自然数,请你依次判断这些数是否是质数。
输入格式:
第一行包含整数 N,表示共有 N 个测试数据。
接下来 N 行,每行包含一个自然数 X。
输出格式:
每个测试用例输出一个结果,每个结果占一行。
如果测试数据是质数,则输出 X is prime,其中 X 是测试数据。
如果测试数据不是质数,则输出 X is not prime,其中 X 是测试数据。
输入样例:
3
8
51
7
输出样例:
8 is not prime
51 is not prime
7 is prime
在线评测环境:AcWing 726. 质数
代码:
n = int(input())
for i in range(n):
x = int(input())
flag = True
for i in range(2, int(x ** 0.5) + 1):
if x % i == 0:
flag = False
break
if flag:
print("%d is prime" % x)
else:
print("%d is not prime" % x)
6.2.6 只出现一次的字符
题目描述:
给你一个只包含小写字母的字符串。
请你判断是否存在只在字符串中出现过一次的字符。
如果存在,则输出满足条件的字符中位置最靠前的那个。
如果没有,输出 no。
输入格式:
共一行,包含一个由小写字母构成的字符串。
数据保证字符串的长度不超过 100000。
输出格式:
输出满足条件的第一个字符。
如果没有,则输出 no。
输入样例:
abceabcd
输出样例:
e
在线评测环境:AcWing 772. 只出现一次的字符
代码:
str = input()
d = dict()
for s in str:
if s not in d:
d[s] = 1
else:
d[s] += 1
flag = True
for s in str:
if d[s] == 1:
flag = False
print(s)
break
if flag == True:
print("no")
6.2.7 单词替换
题目描述:
输入一个字符串,以回车结束(字符串长度不超过 100)。
该字符串由若干个单词组成,单词之间用一个空格隔开,所有单词区分大小写。
现需要将其中的某个单词替换成另一个单词,并输出替换之后的字符串。
输入格式:
输入共 3行。
第 1 行是包含多个单词的字符串 s;
第 2 行是待替换的单词 a(长度不超过 100);
第 3 行是 a 将被替换的单词 b(长度不超过 100)。
输出格式:
共一行,输出将 s 中所有单词 a 替换成 b 之后的字符串。
输入样例:
You want someone to help you
You
I
输出样例:
I want someone to help you
在线评测环境:AcWing 770. 单词替换
代码:
str = input().split(' ')
a = input()
b = input()
for i in range(len(str)):
if (str[i] == a):
str[i] = b
str1 = ' '.join(str)
print(str1)
6.2.8 字符串中最长的连续出现的字符
题目描述:
求一个字符串中最长的连续出现的字符,输出该字符及其出现次数,字符串中无空白字符(空格、回车和 tab),如果这样的字符不止一个,则输出第一个。
输入格式:
第一行输入整数 N,表示测试数据的组数。
每组数据占一行,包含一个不含空白字符的字符串,字符串长度不超过 200。
输出格式:
共一行,输出最长的连续出现的字符及其出现次数,中间用空格隔开。
输入样例:
2
aaaaabbbbbcccccccdddddddddd
abcdefghigk
输出样例:
d 10
a 1
在线评测环境:AcWing 771. 字符串中最长的连续出现的字符
代码:
n = int(input())
for i in range (n):
s = input()
cnt, cc = 0, ''
max, mc = 0, ''
for i in range (len(s)):
if (s[i]) == cc:
cnt += 1
if s[i] != cc or i == len(s) - 1:
if max < cnt:
max = cnt
mc = cc
cnt = 1
cc = s[i]
print (mc, max)
6.2.9 最长单词
题目描述:
一个以. 结尾的简单英文句子,单词之间用空格分隔,没有缩写形式和其它特殊形式,求句子中的最长单词。
输入格式:
输入这个简单英文句子,长度不超过 500。
输出格式:
该句子中最长的单词。如果多于一个,则输出第一个。
输入样例:
I am a student of Peking University.
输出样例:
University
在线评测环境:AcWing 774. 最长单词
代码:
s = input()
s = s[:-1].split()
m = ''
for i in s:
if len(i) > len(m):
m = i
print(m)
6.2.10 倒排单词
题目描述:
编写程序,读入一行英文(只包含字母和空格,单词间以单个空格分隔),将所有单词的顺序倒排并输出,依然以单个空格分隔。
输入格式:
输入为一个字符串(字符串长度至多为 100)。
输出格式:
输出为按要求排序后的字符串。
输入样例:
I am a student
输出样例:
student a am I
在线评测环境:AcWing 775. 倒排单词
代码:
s = input().split(' ')
s.reverse()
s = ' '.join(s)
print(s)
6.2.11 递归求斐波那契数列
题目描述:
请使用递归的方式求斐波那契数列的第 n 项。
斐波那契数列:1,1,2,3,5…,这个数列从第 3 项开始,每一项都等于前两项之和
输入格式:
共一行,包含整数 n。
输出格式:
共一行,包含一个整数,表示斐波那契数列的第 n 项。
输入样例:
4
输出样例:
3
在线评测环境:AcWing 820. 递归求斐波那契数列
代码:
def mul(n):
if n == 1:
return 1
elif n == 2:
return 1
else:
return mul(n - 1) + mul(n - 2)
n = int(input())
print(mul(n))
6.2.12 最大公约数
题目描述:
输入两个整数 a 和 b,请你编写一个函数,int gcd(int a, int b), 计算并输出 a 和 b 的最大公约数。
输入格式:
共一行,包含两个整数 a 和 b。
输出格式:
共一行,包含一个整数,表示 a 和 b 的最大公约数。
输入样例:
12 16
输出样例:
4
在线评测环境:AcWing 808. 最大公约数
代码:
def gcd(m, n):
min = m
if m > n :
min = n
for i in range(min, 0, -1):
if m % i == 0 and n % i == 0:
return i
m, n = input().split()
print(gcd(int(m), int(n)))
6.2.13 最小公倍数
题目描述:
输入两个整数 a 和 b,请你编写一个函数,int lcm(int a, int b),计算并输出 a 和 b 的最小公倍数。
输入格式:
共一行,包含两个整数 a 和 b。
输出格式:
共一行,包含一个整数,表示 a 和 b 的最小公倍数。
输入样例:
6 8
输出样例:
24
在线评测环境:AcWing 809. 最小公倍数
代码:
def gcd(m, n):
min = m
if m > n :
min = n
for i in range(min, 0, -1):
if m % i == 0 and n % i == 0:
return i
def lcm(m, n):
return m * n // gcd(m, n)
m, n = input().split()
print(lcm(int(m), int(n)))
6.3 进阶之道
6.3.1 菱形
题目描述:
输入一个奇数 n,输出一个由 * 构成的 n 阶实心菱形。
输入格式:
一个奇数 n。
输出格式:
输出一个由 * 构成的 n 阶实心菱形。
具体格式参照输出样例。
输入样例:
5
输出样例:
*
***
*****
***
*
在线评测环境:AcWing 727. 菱形
代码:
n = int(input())
for i in range(n):
s = ''
for j in range(n):
t = n // 2
if abs(i - t) + abs(j - t)>t:
s += str(' ')
else:
s += str('*')
print(s)
6.3.2 字符串移位包含问题
题目描述:
对于一个字符串来说,定义一次循环移位操作为:将字符串的第一个字符移动到末尾形成新的字符串。
给定两个字符串 s1 和 s2,要求判定其中一个字符串是否是另一字符串通过若干次循环移位后的新字符串的子串。
例如 CDAA 是由 AABCD 两次移位后产生的新串 BCDAA 的子串,而 ABCD 与 ACBD 则不能通过多次移位来得到其中一个字符串是新串的子串。
输入格式:
共一行,包含两个字符串,中间由单个空格隔开。
字符串只包含字母和数字,长度不超过 30。
输出格式:
如果一个字符串是另一字符串通过若干次循环移位产生的新串的子串,则输出 true,否则输出 false。
输入样例:
AABCD CDAA
输出样例:
true
在线评测环境:AcWing 776. 字符串移位包含问题
代码:
s1, s2 = input().strip().split(" ")
if len(s1) < len(s2):
s1, s2 = s2, s1
s1 = s1 * 2
if(s1.find(s2) != -1):
print("true")
else:
print("false")
6.3.3 字符串乘方
题目描述:
给定两个字符串 a 和 b,我们定义 a×b 为他们的连接。
例如,如果 a=abc 而 b=def, 则 a×b=abcdef。
如果我们将连接考虑成乘法,一个非负整数的乘方将用一种通常的方式定义:a0=''(空字符串),a(n+1)=a×(an)。
输入格式:
输入包含多组测试样例,每组测试样例占一行。
每组样例包含一个字符串 s,s 的长度不超过 100。
最后的测试样例后面将是一个点号作为一行。
输出格式:
对于每一个 s,你需要输出最大的 n,使得存在一个字符串 a,让 s=an。
输入样例:
abcd
aaaa
ababab
.
输出样例:
1
4
3
在线评测环境:AcWing 777. 字符串乘方
代码:
while True:
s = input()
if s == '.':
break
n = len(s)
for i in range (n):
if n % (i + 1) == 0:
sub = s[:i + 1]
c = n // (i+1)
sp = ''
for j in range (c):
sp += sub
j += 1
if s == sp:
print (c)
break
6.3.4 字符串最大跨距
题目描述:
有三个字符串 S,S1,S2,其中,S 长度不超过 300,S1 和 S2 的长度不超过 10。
现在,我们想要检测 S1 和 S2 是否同时在 S 中出现,且 S1 位于 S2 的左边,并在 S 中互不交叉(即,S1 的右边界点在 S2 的左边界点的左侧)。
计算满足上述条件的最大跨距(即,最大间隔距离:最右边的 S2 的起始点与最左边的 S1的终止点之间的字符数目)。
如果没有满足条件的 S1 ,S2 存在,则输出 −1 。
例如,S= abcd123ab888efghij45ef67kl, S1= ab, S2= ef,其中,S1 在 S 中出现了 2 次,S2 也在 S 中出现了 2 次,最大跨距为:18。
输入格式:
输入共一行,包含三个字符串 S,S1,S2,字符串之间用逗号隔开。
数据保证三个字符串中不含空格和逗号。
输出格式:
输出一个整数,表示最大跨距。
如果没有满足条件的 S1 和 S2 存在,则输出 −1。
输入样例:
abcd123ab888efghij45ef67kl,ab,ef
输出样例:
18
在线评测环境:AcWing 778. 字符串最大跨距
代码:
s, s1, s2 = input().split(",")
a = s.find(s1)
b = s.rfind(s2)
if(a == -1 or b == -1 or a+len(s1) >= b):
print("-1")
else:
print(b - a - len(s1))
6.3.5 最长公共字符串后缀
题目描述:
给出若干个字符串,输出这些字符串的最长公共后缀。
输入格式:
由若干组输入组成。
每组输入的第一行是一个整数 N。
N为 0 时表示输入结束,否则后面会继续有 N 行输入,每行是一个字符串(字符串内不含空白符)。
每个字符串的长度不超过 200。
输出格式:
共一行,为 N 个字符串的最长公共后缀(可能为空)。
输入样例:
3
baba
aba
cba
2
aa
cc
2
aa
a
0
输出样例:
ba
a
在线评测环境:AcWing 779. 最长公共字符串后缀
代码:
while True:
n = int(input())
if n == 0:
break
s = [''] * 200
s_len, mlen = n, 200
ms = ''
for i in range(n):
s[i] = input()
if mlen > len(s[i]):
mlen = len(s[i])
ms = s[i]
found = False
for j in range(mlen):
is_success = True
ms2 = ms[j:]
for k in range(s_len):
if s[k][len(s[k]) - mlen + j:] != ms2:
is_success = False
if is_success:
found = True
print(ms2)
break
if not found:
print('')
6.3.6 跳台阶
题目描述:
一个楼梯共有 n 级台阶,每次可以走一级或者两级,问从第 0 级台阶走到第 n 级台阶一共有多少种方案。
输入格式:
共一行,包含一个整数 n。
输出格式:
共一行,包含一个整数,表示方案数。
输入样例:
5
输出样例:
8
在线评测环境:AcWing 821. 跳台阶
代码:
def steps(n):
if n==1 or n==2:
return n
return steps(n-1)+steps(n-2)
n = int(input())
a = steps(n)
print(a)
6.3.7 走方格
题目描述:
给定一个 n×m 的方格阵,沿着方格的边线走,从左上角 (0,0) 开始,每次只能往右或者往下走一个单位距离,问走到右下角 (n,m) 一共有多少种不同的走法。
输入格式:
共一行,包含两个整数 n 和 m。
输出格式:
共一行,包含一个整数,表示走法数量。
输入样例:
2 3
输出样例:
10
在线评测环境:AcWing 822. 走方格
代码:
def dfs(x, y):
global a
if x == n and y == m:
a += 1
else:
if x < n:
dfs(x + 1, y)
if y < m:
dfs(x, y + 1)
global n, m
a = 0
n, m = map(int, input().split())
a = 0
dfs(0, 0)
print(a)
6.3.8 排列
题目描述:
给定一个整数 n,将数字 1∼n 排成一排,将会有很多种排列方法。
现在,请你按照字典序将所有的排列方法输出。
输入格式:
共一行,包含一个整数 n。
输出格式:
按字典序输出所有排列方案,每个方案占一行。
输入样例:
3
输出样例:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
在线评测环境:AcWing 823. 排列
代码:
def array(d):
global n, ans, res
if n == d:
for x in range(n):
print(ans[x], end = ' ')
print()
return
for x in range(1, n + 1):
if not res[x]:
ans[d] = x
res[x] = 1
array(d + 1)
res[x] = 0
ans = [0] * 10
res = [0] * 10
n = int(input())
array(0)
6.3.9 蛇形矩阵
题目描述:
输入两个整数 n 和 m,输出一个 n 行 m 列的矩阵,将数字 1 到 n×m按照回字蛇形填充至矩阵中。
具体矩阵形式可参考样例。
输入格式:
输入共一行,包含两个整数 n 和 m。
输出格式:
输出满足要求的矩阵。
矩阵占 n 行,每行包含 m 个空格隔开的整数。
输入样例:
3 3
输出样例:
1 2 3
8 9 4
7 6 5
在线评测环境:AcWing 756. 蛇形矩阵
代码:
n, m = input().split()
m = int(m)
n = int(n)
l = [[0] * m for i in range (n)]
x = y = 0
dx = [-1, 0, 1, 0]
dy = [0, 1, 0, -1]
d = 1
for i in range(1, m * n + 1):
l[x][y] = i
a = x + dx[d]
b = y + dy[d]
if a < 0 or a >= n or b < 0 or b >= m or l[a][b]>0:
d = (d + 1) % 4
a = x + dx[d]
b = y + dy[d]
x = a
y = b
for i in range(n):
for j in range(m):
print(l[i][j], end = ' ')
print('')
*6.4 关于程序设计竞赛
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 面向过程是代码的核心思想,它涉及众多的算法,如果你还是大一或者大二,那么我强烈建议你去参加算法竞赛,如:ICPC,CCPC,CCSP,蓝桥杯,GPLT团队程序设计天梯赛,,以及一些能力测试:CCF-CSP,PAT(甲级,顶级),你可以通过一些小型比赛去积累经验,比如:全国高校计算机能力挑战赛,全国大学生算法设计与编程挑战赛,这里给出一些网址,需要的读者可以进网址去了解详情:
ICPC:The ICPC International Collegiate Programming Contest
CCPC:中国大学生程序设计竞赛(CCPC)-官网
CCSP:CCSP(CCF大学生计算机系统与程序设计竞赛)
蓝桥杯:蓝桥杯大赛——全国大学生TMT行业赛事
GPLT团队程序设计天梯赛:团队程序设计天梯赛
CCF-CSP:CCF-CSP认证
PAT:PAT计算机程序设计能力考试
全国高校计算机能力挑战赛:2021年第三届全国高校计算机能力挑战赛
全国大学生算法设计与编程挑战赛:赛氪竞赛网
❗️ 注:上述的所有比赛都需要算法基础,这是现在的我们所不具备的,目前我们只掌握了语言的基础,上述比赛感兴趣的读者自行去了解,我也写过一些算法博客,可供大家学习,这些算法博客是用 C++ 去写的,如果你要参加算法竞赛,那么 C++ 是你必须学会的语言,而不是 Python:算法基础内容汇总,算法提高内容汇总,当然,这有点扯远了,本博客的目的是给大家讲解 Python 语言,是面向企业和工作的,和算法竞赛无任何关联,上述只是给小部分读者所解释
三、玩转Python语法(二):面向对象
从这一大章节开始,就进入了面向对象的部分,Python 是面向对象的解释型高级动态编程语言,完全支持面向对象的基本功能,只掌握了面向过程是远远不够的,就开发而言,面向对象的重要程度要高于面向过程,如果你学习完了之前所讲的面向过程的内容,并且做了一定量的习题,那么你的基础可以说已经很牢固了,接下来就让我们走进对象的世界,程序员最不缺的是什么?是对象!
1.百宝箱
1.1 自定义模块
🚩首先来介绍一下什么是模块:模块英文为Modules,在Python中一个扩展名为.py的文件就是一个模块,我们写代码时使用模块的好处:
1.方便其它程序和脚本的导入并使用
2.避免函数名和变量名冲突
3.提高代码的可维护性
4.提高代码的可重用性
创建模块其实就是新建一个.py文件,要求名称不能和Python自带的标准模块名称相同,导入模块的代码格式:
# 把模块的内容全部导入
import 模块名称 [as 别名]
# 把模块的部分导入
from 模块名称 import 函数/变量/类
下面我们通过导入 math 模块来讲解上述格式,math 模块中存有很多的数学公式,这些公式将被我们经常调用
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/20 20:48
# 欢迎大家关注AIoT相关博客~
import math
print(type(math))
print(math.pi)
print('----------------')
# 使用dir() 可以查看模块中的所有函数
print(dir(math))
# 常用的math中的函数:
# 计算几次方:
print(math.pow(2, 3)) # 计算2的3次方
# 向上取整
print(math.ceil(9.01))
# 向下取整
print(math.floor(9.99))
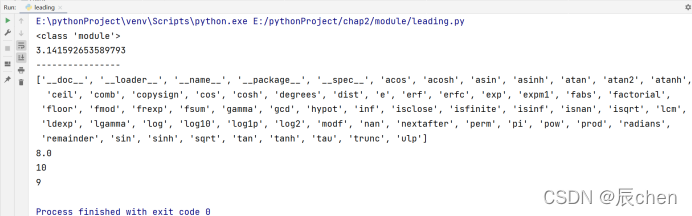
我们可以用 [as 别名] 来起别名:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/20 21:09
# 欢迎大家关注AIoT相关博客~
import math as m
# 这个操作其实就是我们以后写代码可以用 m 代替 math
print(type(m))
print(m.pi)
print(m.pow(2, 3))
print(m.ceil(9.01))
print(m.floor(9.99))
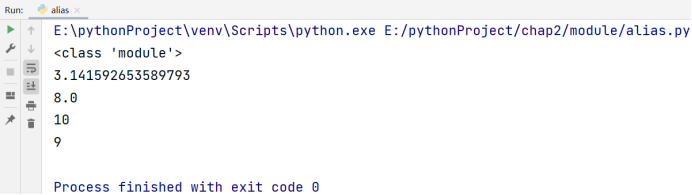
我们使用 dir() 函数可以看出 math 模块中有很多的函数,但是我们写代码可能不需要这么多的函数,往往只需要其中的一两个即可,故我们没必要把所有函数都导入,这个时候就可以使用 from 模块名称 import 函数/变量/类 来导入部分的函数,并且以这种形式导入的这些函数不需要 .的调用,可直接使用:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/20 21:12
# 欢迎大家关注AIoT相关博客~
from math import pi, floor
print(pi)
print(floor(9.99))

那么,我们不是自己也写了很多的模块嘛,是否可以像导入系统模块这样导入我们自己的模块呢?答案是:如果你和我一样下载的是最新版的 PyCharm,是可以的,如果你下载的原来版本的 PyCharm,需要一点额外的操作:
1️⃣ 新版 PyCharm 支持直接调用:
2️⃣ 如果你是老版的 PyCharm 需要右击目录,选择最下方的 Mark Dictionary as,选择 Sources Root,这样的操作后,你就可以像调用系统模块一样调用自己写的模块:
1.2 以主程序形式运行
🚩这部分概念字面理解起来晦涩难懂,没必要看下述定义,如果你很好奇,可以看一下如下定义:在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__
好的,如果我没猜错你没有看懂,无关紧要,我们用代码解释:
比如我们写好了 demo3,并且在 demo4 中导入了 demo3,我们在 demo4 中调用了 demo3 的 add 函数,显然我们只想计算 100 + 200 的值,但是程序的输出结果却是输出了两个数,这是因为我们的 demo3 中还附带这一个计算 10 + 20,这样的结果是我们不想要的,这时,我们既不想删除 demo3 中的 10 + 20,又不想让我们 demo4 在调用 demo3 时输出额外的东西,就可以在 demo3 中 写一行 main:
然后按下回车:并把 print(10 + 20) 放入 if 语句中,这样一来,在别的模块调用 demo3 时,不会输出 if 语句中的内容,只有当 运行 demo3 的时候,才会输出 if 语句中的内容
运行 demo4:
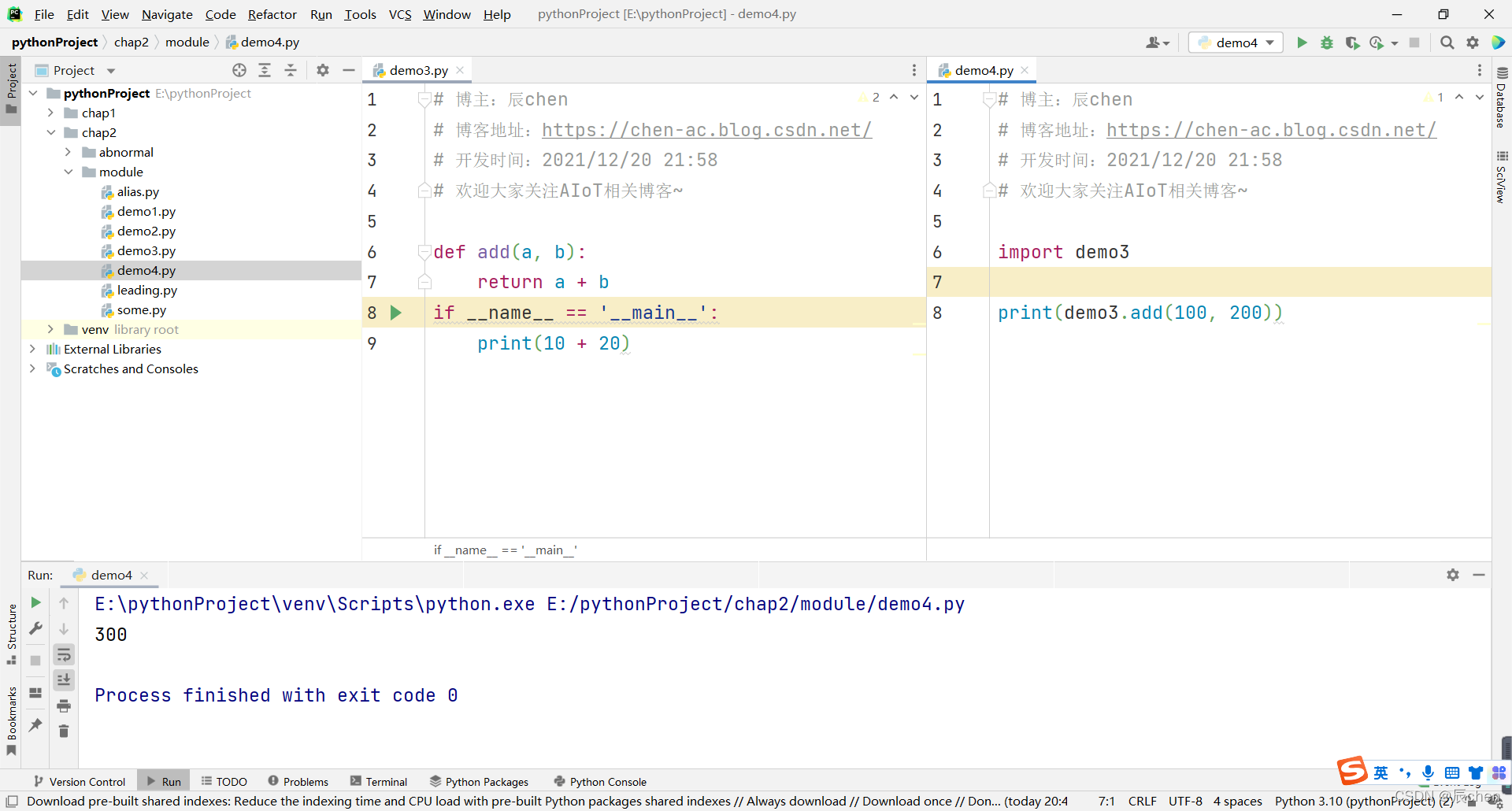
运行 demo3:
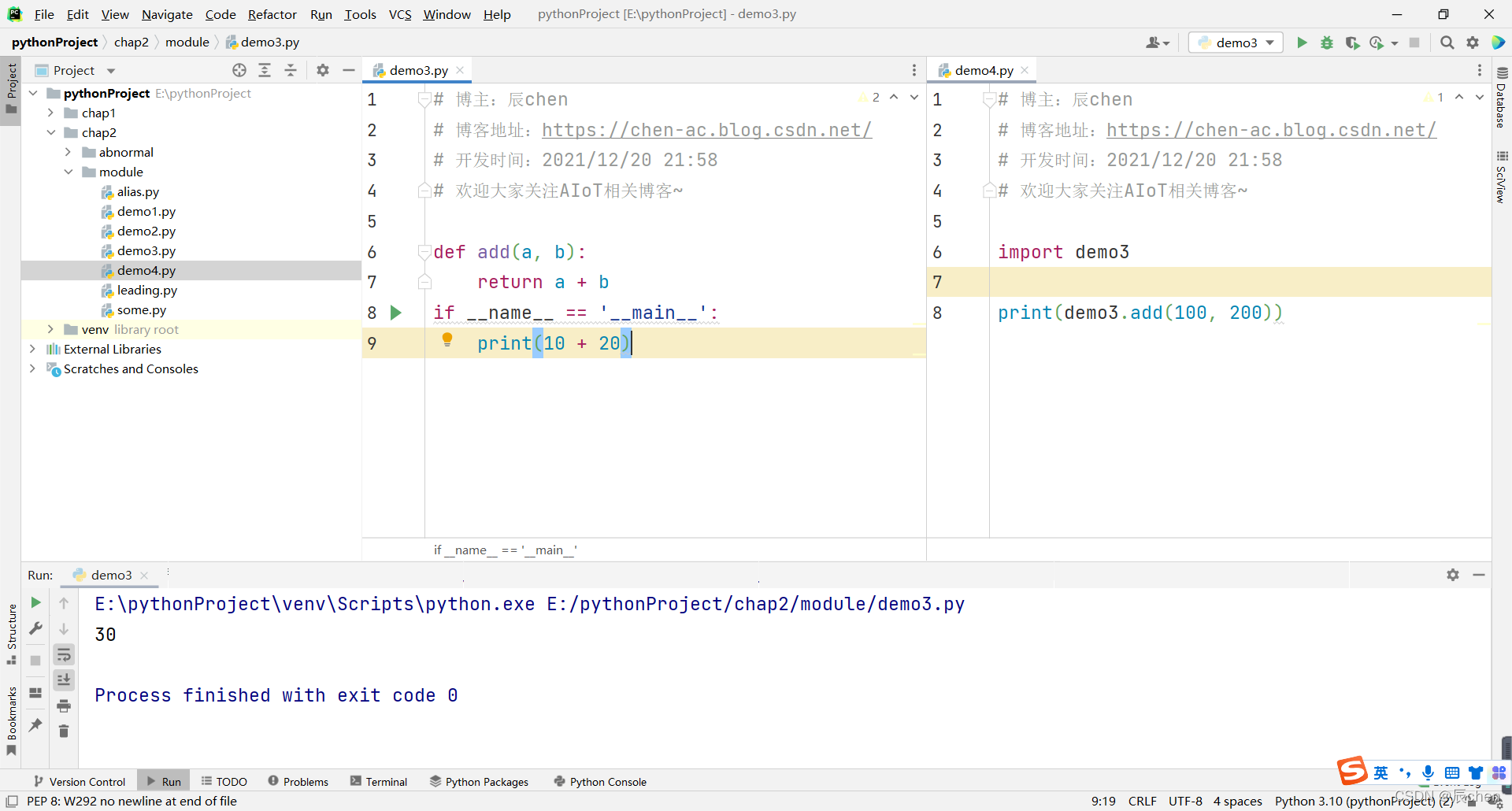
1.3 包
🚩包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下。包的作用:
1.代码规范
2.避免模块名称冲突
包与目录的区别:
包含__init__.py文件的目录称为包
目录里通常不包含__init__.py文件
建立包的方式:
可以看出,目录和包的区别就是包自带一个__init__.py文件:

包的导入语法结构:
import 包名.模块名
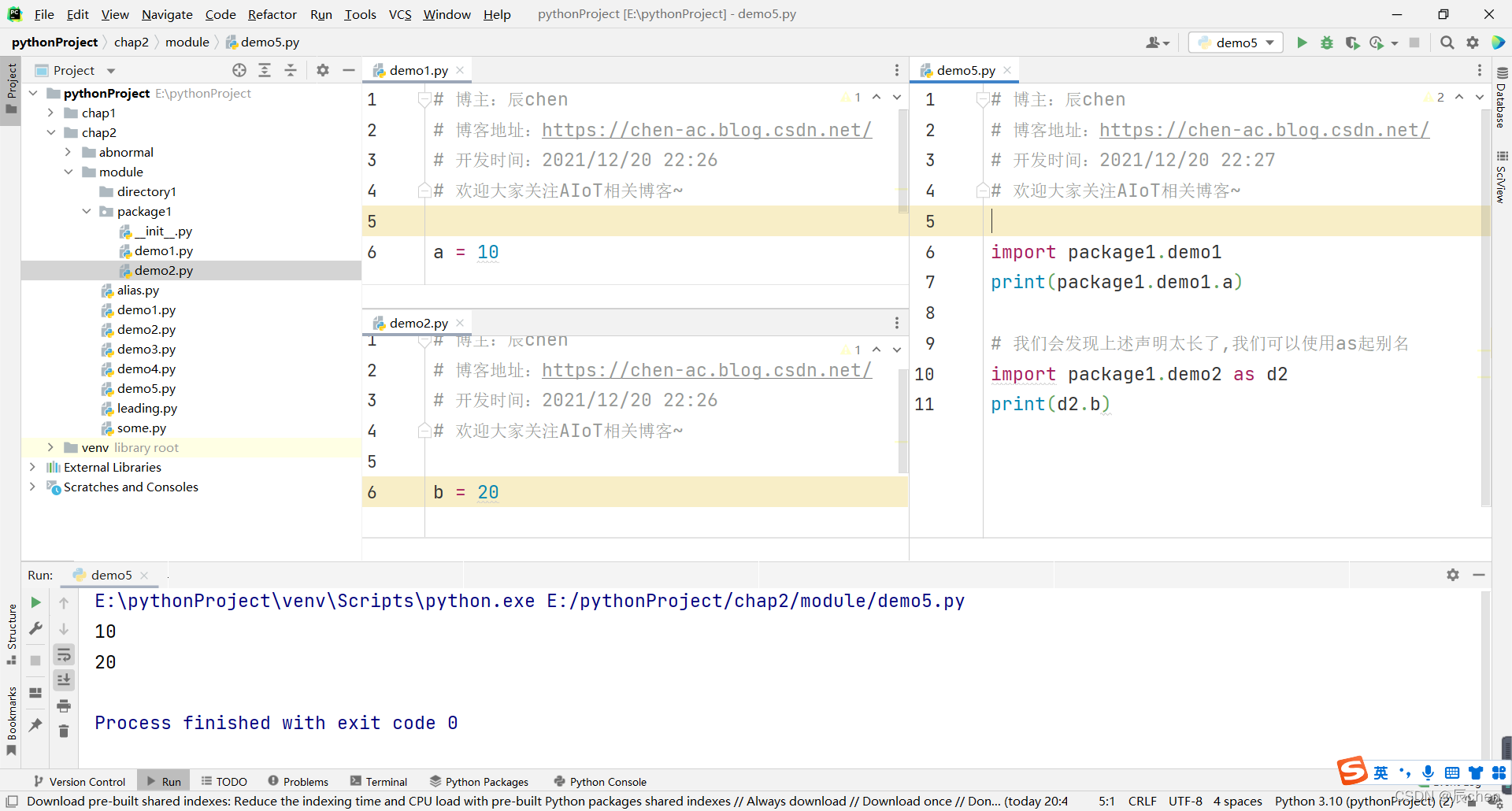
*1.4 Python中常用的内置模块
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 本小节可以说还是比较重要的,但为什么本小节打 * 了呢?这是因为我们没必要去记忆这些函数(期末考试除外),在我们需要的时候我们只需要来本小节去查找用法即可。
下面简单介绍一下我们经常使用的模块,并调用部分模块的部分函数做演示:
| 模块名 | 描述 |
|---|---|
| sys | 与 Python 解释器极其环境操作相关的标准库 |
| time | 提供与时间相关的各种函数的标准库 |
| os | 提供了访问操作系统服务功能的标准库 |
| calendar | 提供与日期相关的各种函数的标准库 |
| urllib | 用于读取来自网上(服务器)的数据标准库 |
| json | 用于使用 JSON 序列化和反序列化对象 |
| re | 用于在字符串中执行正则表达式匹配和替换 |
| math | 提供标准算数运算函数的标准库 |
| decimal | 用于进行精确控制运算精度、有效数位和四舍五入操作的十进制运算 |
| logging | 提供了灵活的记录事件、错误、警告和调试信息等日志信息的功能 |
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/20 22:38
# 欢迎大家关注AIoT相关博客~
import sys
import time
import urllib.request # 爬虫会用到 urllib
import math
# 获取对象所占的内存大小
print(sys.getsizeof(24))
print(sys.getsizeof(45))
print(sys.getsizeof(True))
print(sys.getsizeof(False))
# 输出的是秒
print(time.time())
# 把秒转成具体的日期
print(time.localtime(time.time()))
# 打开百度的网址然后将百度服务器返回的东西都进行读取
print(urllib.request.urlopen('http://www.baidu.com').read())
# math模块
print(math.pi)
1.5 第三方模块的安装及使用
🚩Python 之所以如此之强大,实际上和第三方模块有很大的关系,因为有很多的大佬写了第三方模块,我们只需要把他们写的模块进行安装之后,我们就可以使用模块中的方法,类和属性等.
第三方模块的安装语法结构:pip install 模块名,这是在线安装的方式,也是我们使用的最多的一种安装方式。接下来我们来安装 schedule 这个模块:
1️⃣ 键盘按下 Windows + R,输入cmd
2️⃣ 打开后直接输入 pip install schedule,回车进入等待
3️⃣ 安装完成后,输入 Python 进入到 Python的交互式应用程序,输入 import schedule,如果程序不报错,证明安装成功
接下来,我们用 schedule 写一个程序让它不断的输出文件,每间隔一些时间就执行这样的操作任务:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/20 23:08
# 欢迎大家关注AIoT相关博客~
import schedule
import time
def job():
print('辰chen666 ------------')
# 每三秒去执行一次job函数
schedule.every(3).seconds.do(job)
while True:
schedule.run_pending()
# 设置一个缓冲的时间:每隔三秒做一次休息一秒
time.sleep(1)
# 我们后续可以使用这个模块去实现一个定时发送邮件的功能
好,那么接下来问题又来啦,当你输入了上述代码后,你会惊讶的发现导入模块报错了!

这是因为 PyCharm 使用的解释器和安装模块的解释器并不是同一个解释器,所以下面我们来讲解 PyCharm 所使用的解释器:
File -> Settings… -> Project:代码文件名 -> Python Interpreter
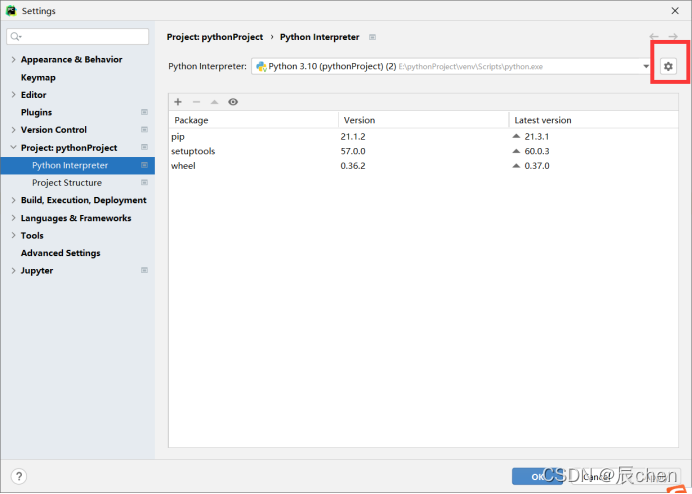
然后我们去找到我们的 Python安装模块的解释器,并把它的地址粘贴到这里:
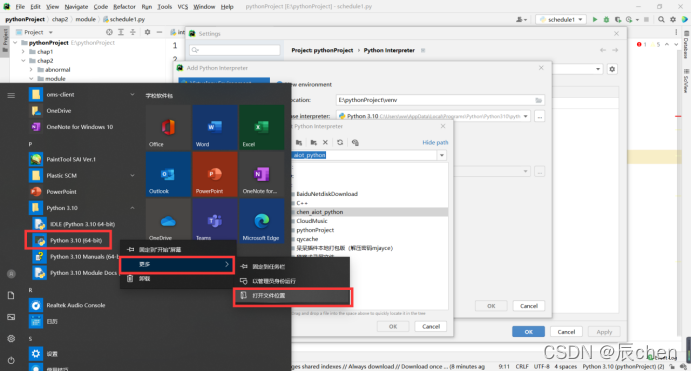
复制地址:
粘贴地址:
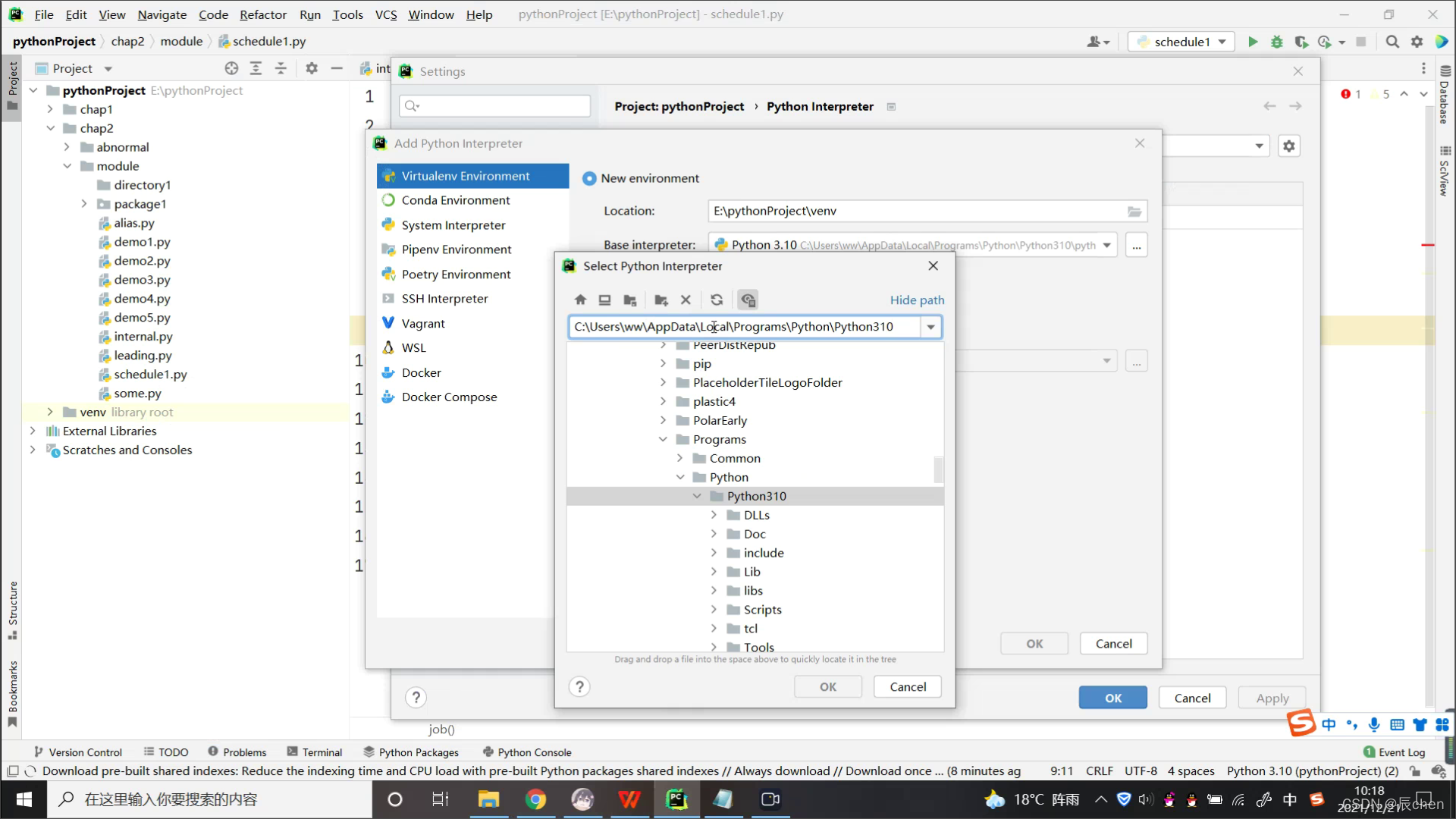
选择 python.exe,点击 OK
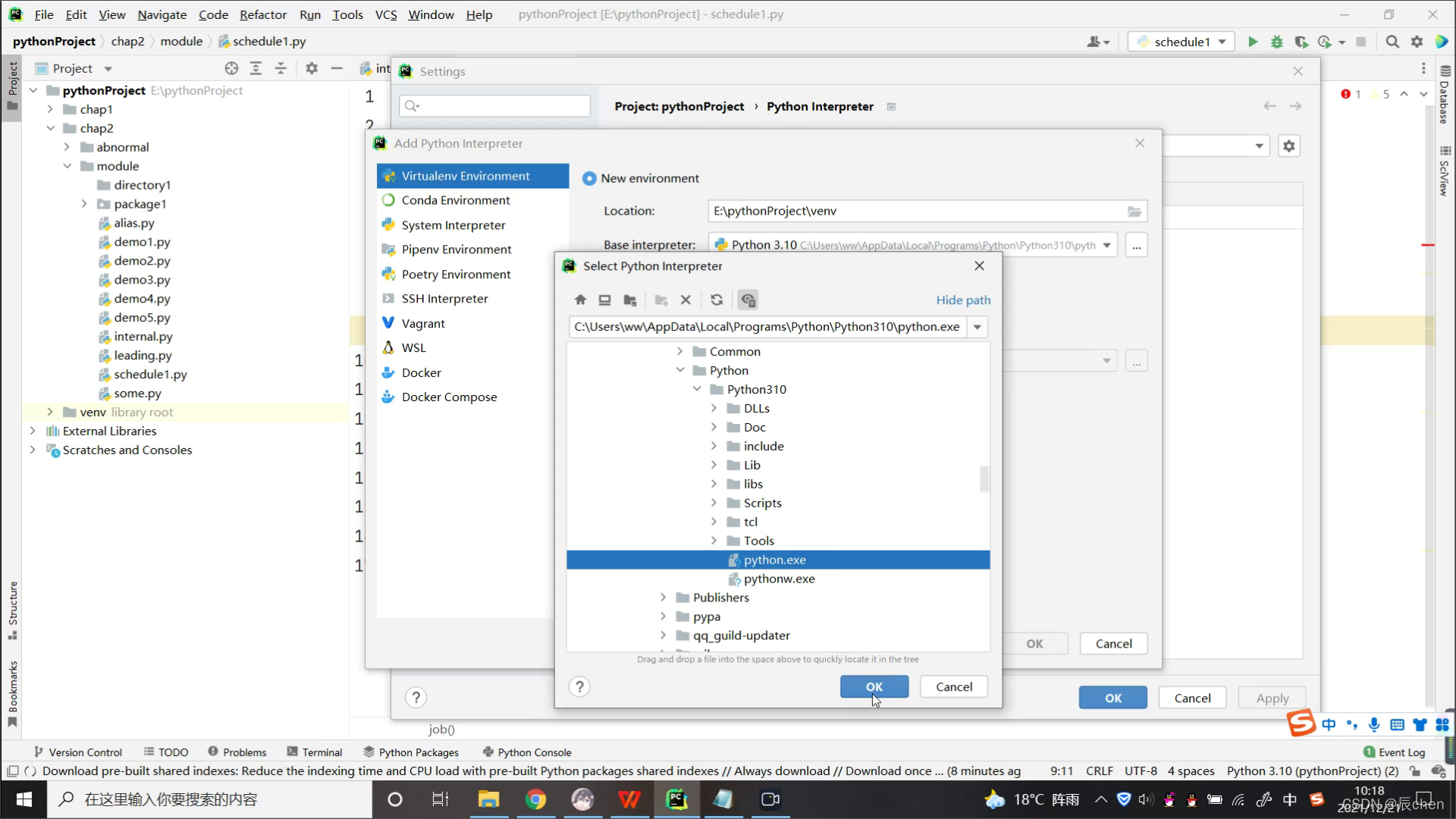
接下来 点击 Existing environment,进行一样的操作:
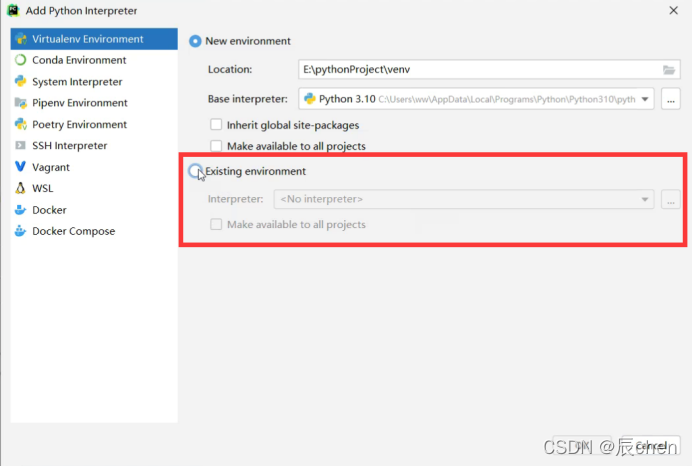
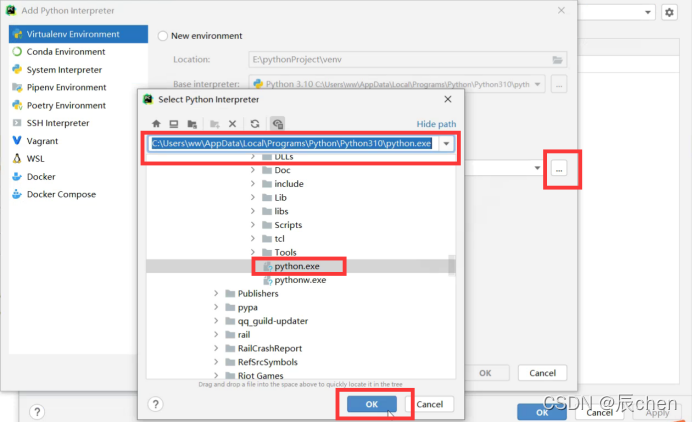
至此,就全部修改完毕了,点击 OK
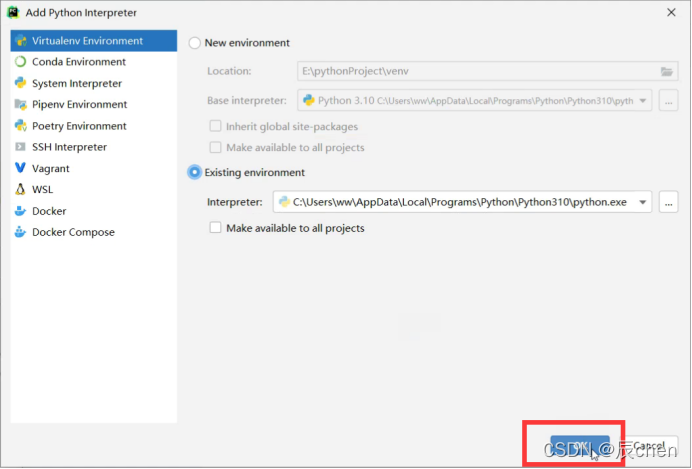
稍微等待后,我们就会发现 schedule 出现了,点击 OK 即可:
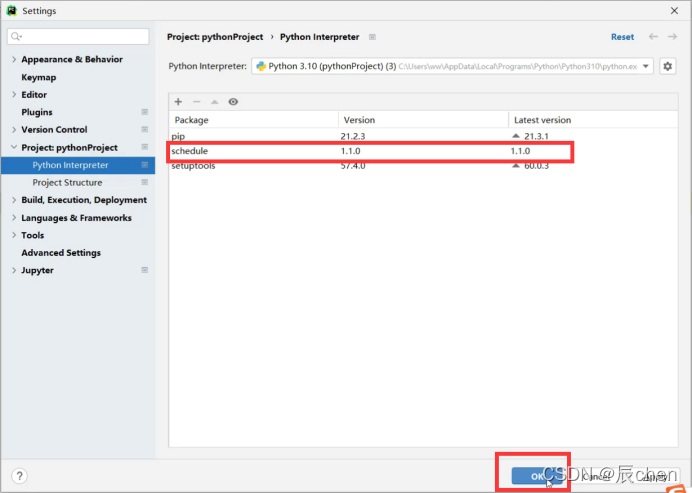
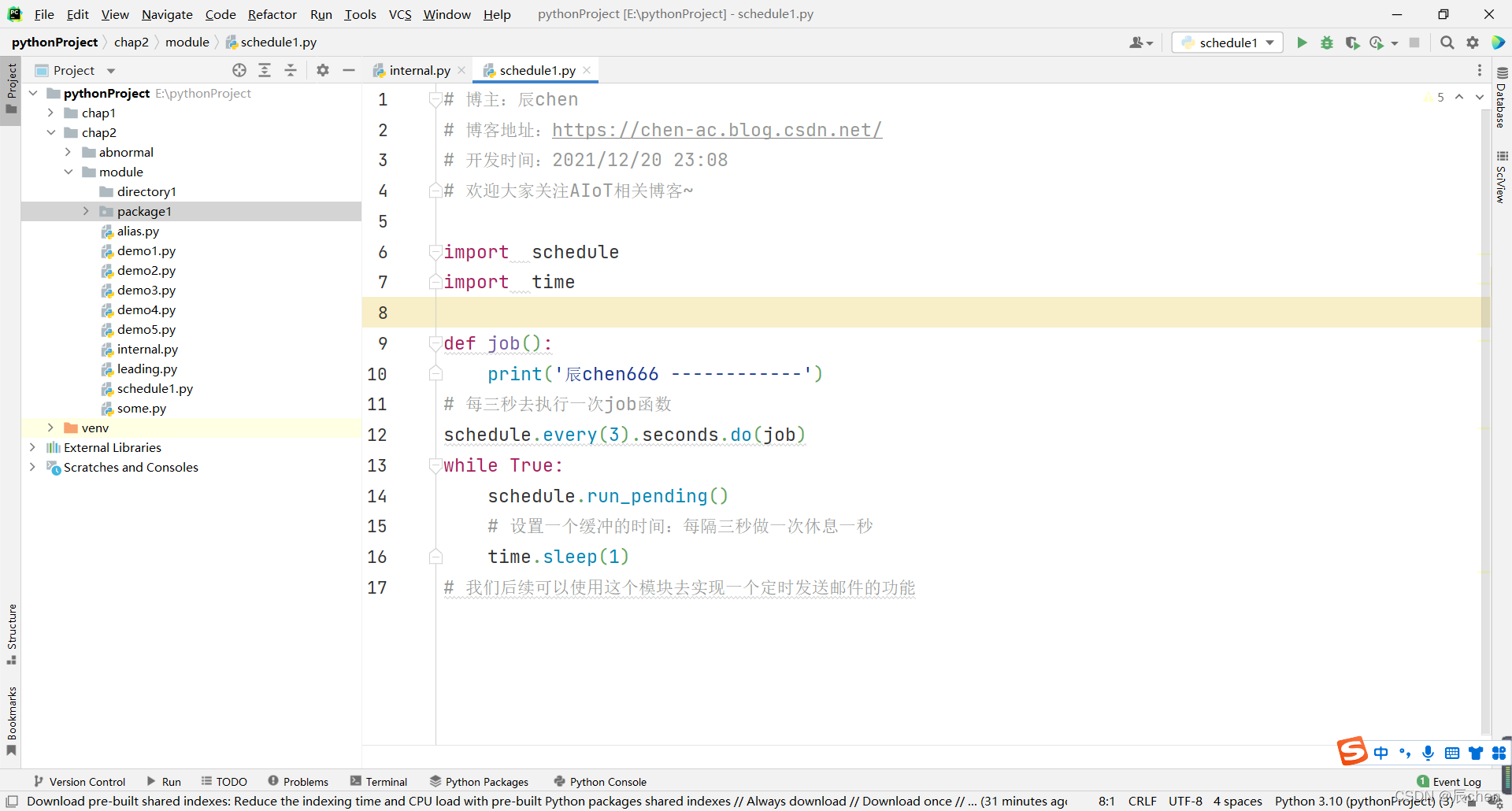
至此,我们就可以实用 schedule 模块啦,Congratulation~🎈
2.你是来找茬的吧?
*2.1 bug 与 debug
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 所谓 bug 其实有一个有趣的小故事:有一天,计算机程序之母Grace Hopper正在用马克二号调试程序,但程序却一直出现错误,所以她开始了层层排查,拆开了继电器之后她发现有一只飞蛾夹在了触点之间,卡住了机器的运行,她把虫子的尸体拿出来之后,把它粘到了自己的工作日记上,并喊它为bug(臭虫),从此 bug 化身计算机领域故障的代言词,而 debug 的意思就是为程序排除错误.
2.2 bug 的常见错误类型
2.2.1 粗心导致的错误
🚩粗心导致的错误其实是最不应该犯的错误,如果你有很多的粗心错误,那么证明,你对于 Python 的语法还不是十分的熟练,还需要继续刷题如果你把本博客中 Python程序设计训练场 的题目已经全部自己手动打过一遍了,是绝对不会再犯这种的错误的,在这里,我也总结了一些粗心的错误,大家要牢记以下几点:
1.漏了末尾的冒号,如if语句,循环语句,else子句,自定义函数等
2.缩进错误,该缩进的没缩进,不该缩进的瞎缩进
3.把英文符号写成中文符号,比如说:引号,冒号,括号
4.字符串拼接的时候,把字符串和数字拼在一起
5.没有定义变量,比如说while的循环条件的变量
6.“==”比较运算符和”=”赋值运算符的混用
2.2.2 知识点掌握不熟练导致的错误
🚩这个错误究其根本其实是和 1.2.1 粗心导致的错误 是一个属性的,比如可能会犯的列表索引越界的错误,亦或者是使用一些函数时的错误,这都是我们不熟练才导致的错误,这些错误是低级的,且是最容易更改的,唯一的办法就是:练练练!,这里强烈建议大家要刷完本博客中 Python程序设计训练场 的题目,这些题目都是博主精挑细选出来的,并且所有的题目都支持线上提交的功能。
2.2.3 思路不清导致的错误
🚩思路不清晰的错误可以说是最复杂的一个错误了,导致这个错误的原因可能有很多,拿面向过程来说,你的代码很可能会提示出现超时,亦或者是出现段错误,在竞赛中调试代码有一个很强大的操作:print 大法,即我们把我们过程中改变的量全部输出一下,尤其是例如列表,字典这种数据结构,我们输出一下它们的值,看一下是否符合预期要求,不符合的话就可以进行更改;还有一个强大的操作那就是注释大法,这个操作我们在超时和段错误的时候尤其使用,注释掉一大段内容,查看是否代码仍然超时或显示段错误,如果没有显示,那么证明,错误的代码就是你注释掉的代码,这种方法可以帮我们缩减代码的调试范围。
2.2.4 被动掉坑导致的错误
🚩这个错误其实在绝大多数情况下是没有任何问题的,它大多来源于一些奇人的神奇操作,但这不可否认是我们代码的鲁棒性较差,即代码不够健壮,举个例子,比如我们要求用户输入自己的年龄,99.9%的用户都会正常的输入自己的年龄,但总不免排除那么一两个奇葩输入自己的名字或者其他字符,这般操作后,和我们的期初要求显然是不符合的,程序自然会崩溃,亦或者是计算两个数相除,我们知道除数不可为0,大多数人用计算器也不会进行 1/0 等等这类操作,但是也总不乏有人真的输入了 1/0 这样的案例,这同样会导致我们的程序崩溃,针对以上的现象,在 Python 中提供了异常处理机制,可以在异常出现的时候立即补货,然后在内部进行“消化”,从而使得程序正常运行。代码语法结构为:
try:
可能异常的代码1
可能异常的代码2
......
except 异常类型:
异常处理代码1(报错后执行的代码)
异常处理代码2(报错后执行的代码)
......
我们就拿除数不得为0来写一个代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 21:17
# 欢迎大家关注AIoT相关博客~
try:
a = int(input('请输入被除数:'))
b = int(input('请输出除数:'))
print(a / b)
except ZeroDivisionError:
print('对不起,除数不得为0')
print('程序结束')
当然啦,我们说过,奇葩到处有,代码中特别多,我们从上述代码处理后其实就可以避免输入除数等于0这种异常,但是会不会有人让你输入数字,他却偏偏输入字母呢?可能没有,但作为程序员的我们这些细节必须考虑到,为此,你会发现,可能有多个不同的异常,这个时候就需要多个 except 结构,这里出现了多个异常,我们对于异常的处理顺序有这样的规定:捕获异常的顺序按照先子类后父类的顺序,为了避免遗漏可能出现的异常,可以在最后加 BaseException,表示对其他所有的异常都进行一个捕获,这里你还不了解什么是子类和父类,这个我们会在后续中进行讲解,这里你只需要知道,捕获异常的顺序是和我们解决问题的顺序是一致的,都是先解决小问题,再解决大问题,其语法结构如下:
try:
可能异常的代码1
可能异常的代码2
......
except 异常类型1:
异常处理代码1(报错后执行的代码)
异常处理代码2(报错后执行的代码)
......
except 异常类型2:
异常处理代码1(报错后执行的代码)
异常处理代码2(报错后执行的代码)
......
......
except BaseException:
异常处理代码1(报错后执行的代码)
异常处理代码2(报错后执行的代码)
......
更改后我们的除法程序:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 21:17
# 欢迎大家关注AIoT相关博客~
try:
a = int(input('请输入被除数:'))
b = int(input('请输出除数:'))
print(a / b)
except ZeroDivisionError:
print('对不起,除数不得为0')
except ValueError:
print('请输入数字')
print('程序结束')
2.3 try…except…else结构
🚩如果try块中没有抛出异常,则执行else块,如果try中抛出异常,则执行except块,我们更改上述代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 21:17
# 欢迎大家关注AIoT相关博客~
try:
a = int(input('请输入被除数:'))
b = int(input('请输出除数:'))
print(a / b)
# 代表捕获所有错误,并把错误原因放入e
except BaseException as e:
print('出错了,出现的错误为:', e)
else:
print('程序完好,结果为:', a / b)
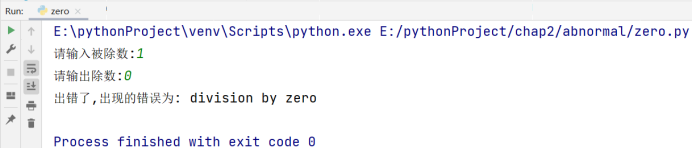

2.4 try…except…else…finally结构
🚩finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源,比如我们后续学习文件处理的时候文件的关闭的东西以及数据库的连接的内容都会放在 finally 当中,这段代码是无论是否产生异常都会执行的一段代码,流程图如下图所示:
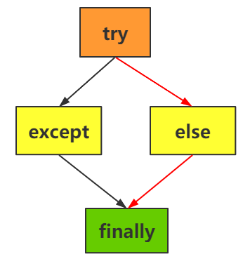
对上述代码再次进行修改:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 21:17
# 欢迎大家关注AIoT相关博客~
try:
a = int(input('请输入被除数:'))
b = int(input('请输出除数:'))
print(a / b)
# 代表捕获所有错误,并把错误原因放入e
except BaseException as e:
print('出错了,出现的错误为:', e)
else:
print('程序完好,结果为:', a / b)
finally:
print('谢谢您的使用')
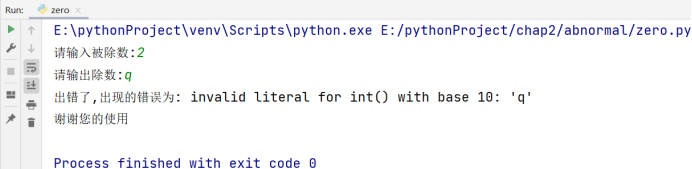
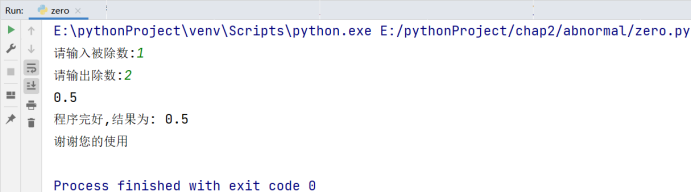
2.5 Python中常见的异常类型
🚩下表是 Python 中常见的异常类型,注意,Python 中的异常类型有很多,我们需要在后续的代码生涯中不断的总结:
| 异常类型 | 描述 |
|---|---|
| ZeroDivisionError | 除(或取模)0 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| NameError | 未声明/初始化对象(没有属性) |
| SyntaxError | Python 语法错误 |
| ValueError | 传入无效的参数 |
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 21:53
# 欢迎大家关注AIoT相关博客~
# (1)ZeroDivisionError:
# print(10/0)
# (2)IndexError:
'''
l = [1, 2, 3, 4]
print(l[4])
'''
# (3)KeyError
'''
d = {'name':'辰chen', 'age': 19}
print(d['location'])
'''
# (4)NameError
# print(res)
# (5)SyntaxError
# int age = 19
# (6)ValueError
# age = int('辰chen')
2.6 traceback模块
🚩我们使用traceback模块打印异常信息,使用 traceback 模块之前需要先导包:import traceback,使用 traceback 模块是因为,我们处理的这些异常细节,有可能在后续被存入到文件当中,去放到我们的日志文件里,所以我们会使用 traceback 模块将异常信息存储到文件里,我们把这种文件叫做 log 日志。
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/19 22:20
# 欢迎大家关注AIoT相关博客~
import traceback
try:
print('--------------')
print(1 / 0)
except:
traceback.print_exc()
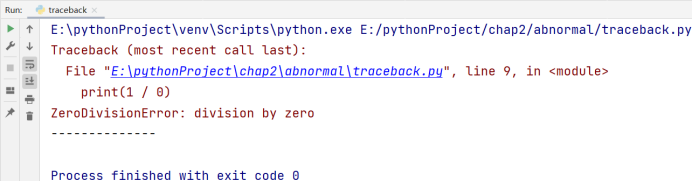
2.7 Python的程序调试
🚩程序的调试是我们程序员必备的本领,接下来我们来讲解如何使用 PyCharm 调试 Python 代码
1️⃣ 断点,程序运行到断点处,会暂时挂起,停止执行。此时可以详细观察程序的运行情况,方便做出进一步的判断:

我们在程序的蓝色区域可以设置断点,只需要鼠标左键点击即可,那个红色的点就是所谓的断点,再次点击这个红色的点就会取消断点
2️⃣ 进入调试视图
进入调试视图的三种方式
(1)单击工具栏上的按钮
(2)右键单击编辑区:点击:debug’模块名’
(3)快捷键:shift+F9
3.这年头程序员谁还没几个对象了
3.1 类与对象
🚩类就是类别,所谓物以类聚,类就是多个类似事物组成的群体的统称。能够帮我们快速的去判断一个事物所具有的性质,比如我们可以把世界上的生物大致的分为:微生物、动物、植物三类,我们也可以把动物按照一定规则继续进行细分:人类,鸟类…,每一个类显然是具有一些特殊的功能的,比如人可以吃喝生产创造等。
数据类型:不同的数据类型属于不同的类,我们曾学过一个函数:type(),使用这个函数可以查看数据类型:
print(type(100))
print(type('辰chen'))
print(type(3.14))
数据类型:不同的数据类型属于不同的类,我们曾学过一个函数:对象:100,'辰chen',3.14,分别是int类,str类,float类之下的不同个例,这些个例的专业属于被称为实例或对象。
在 Python 中,一切皆对象
3.2 类的创建与组成
🚩创建类的语法结构:
class 类名:
pass
比如我们可以创造一个学生类:
class Student:
pass
'''
在之前的学习中我们知道,当我们不清楚要实现什么的时候
可以先写一个 pass,这样可以让程序不报错
'''
这里需要注意,我们在起类名的时候需要尽量做到见名知意,我们需要养成这样的习惯,这是一个程序员的自我修养!
类的组成:
1.类属性
2.实例方法
3.静态方法
4.类方法
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
class Student: #Student为类的名称(类名)由一个或多个单词组成,每个单词的首字母大写,其余小写
native_pace='长治' #直接写在类里的变量,称为类属性
def __init__(self,name,age):
self.name=name #self.name 称为实体属性,进行了一个赋值的操作,将局部变量的name的值赋给实体属性
self.age=age
#实例方法
def eat(self):
print('学生在吃饭...')
#静态方法
@staticmethod
def method():
print('我使用了statticmethod进行修饰,所以我是静态方法')
#类方法
@classmethod
def cm(cls):
print('我是类方法,因为我使用了classmethod进行修饰')
#在类之外定义的称为函数,在类之内定义的称为方法
def drink():
print('喝水')
你可以这么去理解:
在类中定义的函数被称为:实例方法
在类中定义的变量被称为:类属性
在类中定义函数前用 @staticmethod 修饰则为 静态方法
在类中定义函数前用 @classmethod 修饰则为 类方法
3.3 对象的创建
好啦好啦,现在让我来教你们怎么搞对象(不是
🚩创建对象的语法结构:
实例名 = 类名()
# 比如:
stu1 = Student()
下面我们来把 3.2 类的创建与组成 中的代码补全一下,你可以理解为 类 等同于一个框架,只有框架显然是不行的,在框架中具体实现的 对象,才是我们真正创造出来的个体
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/23 19:06
# 欢迎大家关注AIoT相关博客~
class Student: #Student为类的名称(类名)由一个或多个单词组成,每个单词的首字母大写,其余小写
native_pace='长治' #直接写在类里的变量,称为类属性
def __init__(self,name,age):
self.name=name #self.name 称为实体属性,进行了一个赋值的操作,将局部变量的name的值赋给实体属性
self.age=age
#实例方法
def eat(self):
print('学生在吃饭...')
#静态方法
@staticmethod
def method():
print('我使用了statticmethod进行修饰,所以我是静态方法')
#类方法
@classmethod
def cm(cls):
print('我是类方法,因为我使用了classmethod进行修饰')
#在类之外定义的称为函数,在类之内定义的称为方法
def drink():
print('喝水')
#创建Student类的对象
stu1 = Student('辰chen',19) # 因为我们在类中重写了 __init__()方法,即可以创建对象的时候赋值
stu1.eat() #对象名.方法名()
print(stu1.name)
print(stu1.age)
print('------------------------')
Student.eat(stu1) #37行与32行代码功能相同,都是调用Student中的eat方法
#类名.方法名(类的对象)-->实际上就是方法定义处的self
3.4 动态绑定属性和方法
🚩Python 是动态语言,在创建对象之后,可以动态地绑定属性和方法,下面我们直接用代码去介绍:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2021/12/31 23:35
# 欢迎大家关注AIoT相关博客~
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
# 实例方法
def eat(self):
print(self.name + '正在吃饭')
stu1 = Student('辰chen', 19)
stu2 = Student('娇妹儿', 20)
print(stu1.name, stu1.age)
print(stu2.name, stu2.age)
print('------------------------')
# 我们知道,经过上述赋值后,对于 stu1 和 stu2 只有两个实体属性: name, age
# 现在我们想给 stu1 添加一个性别的属性,可以采取下述结构
stu1.gender = '男' # 动态绑定属性
print(stu1.name, stu1.age, stu1.gender)
# 下述代码运行结果可以看出我们只给 stu1 赋予了 gender 属性, stu2 是没有的
try:
print(stu2.name, stu2.age, stu2.gender)
except AttributeError as e:
print(e)
print('------------------------')
# 我们除了动态绑定属性,还可以动态绑定方法:
def drink():
print('要多喝水!!!')
# 我们给 stu2 添加一个 drink 方法:
stu2.drink = drink # 动态绑定方法
stu2.drink()
# 下述代码运行结果可以看出我们只给 stu2 赋予了 drink 方法, stu1 是没有的
try:
stu1.drink()
except AttributeError as e:
print(e)
4.不会吧不会吧,你居然还没有对象
*4.1 面向对象的三大特征
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 封装:提高程序的安全性
将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度。
在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个_ 。
继承:提高代码的复用性
多态:提高程序的可扩展性和可维护性
接下来,我们来具体介绍这三大特征
4.2 封装
🚩将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度。
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 0:39
# 欢迎大家关注AIoT相关博客~
class Car:
def __init__(self, brand):
self.brand = brand
def start(self):
print('车启动了')
car = Car('Veneno')
print(car.brand)
car.start()

在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个_
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 0:49
# 欢迎大家关注AIoT相关博客~
class Student:
def __init__(self, name, age):
self.name = name
self.__age = age # 年龄不希望在外部被使用,所以加了两个_
def show(self):
print(self.name, self.__age)
stu = Student('辰chen', 19)
stu.show()
# 在类的外部使用 name 和 age
try:
print(stu.__age)
except AttributeError as e:
print(e)

现在有小淘气出来了:真的没有方法访问 age 了么?
其实还是有的,见下述代码:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 0:49
# 欢迎大家关注AIoT相关博客~
class Student:
def __init__(self, name, age):
self.name = name
self.__age = age # 年龄不希望在外部被使用,所以加了两个_
def show(self):
print(self.name, self.__age)
stu = Student('辰chen', 19)
stu.show()
# 在类的外部使用 name 和 age
try:
print(stu.__age)
except AttributeError as e:
print(e)
# 在类的外部可以通过 _Student__age进行访问(不推荐!!!)
print(stu._Student__age)

4.3 继承
🚩我们通过一张图来介绍父类和子类:
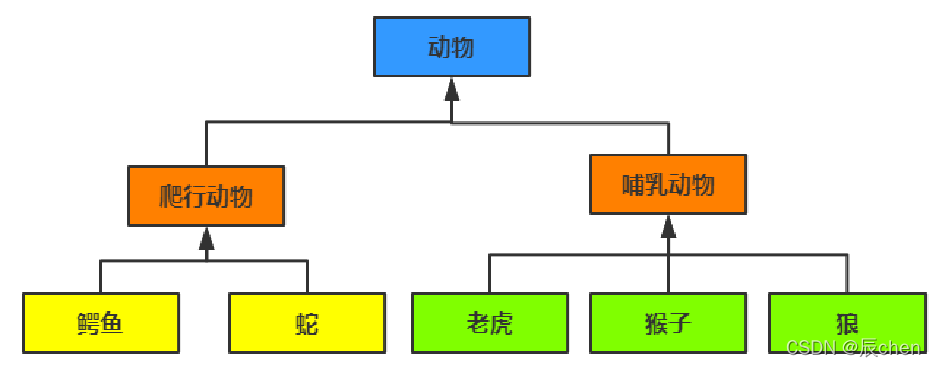
上面的图中,我们可以说动物是爬行动物和哺乳动物的父类,即爬行动物和哺乳动物是动物的子类;鳄鱼、蛇的父类是爬行动物,爬行动物的子类是鳄鱼和蛇;老虎、猴子、狼的父类是哺乳动物,哺乳动物的子类为老虎、猴子、狼。
不难看出,父类中拥有一些性质是子类中所共有的,所以我们在定义子类的时候就不必写的那么麻烦,只需要从父类那边继承即可。
Python 中可以单继承,也可以多继承,其语法格式为:
class 子类类名(父类1, 父类2, ...):
pass
如果一个类没有继承任何类,则默认继承object,比如我们之前学习中的代码其实就是默认继承 object。
定义子类时,必须在其构造函数中调用父类的构造函数。
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 1:28
# 欢迎大家关注AIoT相关博客~
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name, self.age)
class Student(Person):
def __init__(self, name, age, stuNum):
self.name = name
self.age = age
self.stuNum = stuNum
class Teacher(Person):
def __init__(self, name, age, teaNum):
self.name = name
self.age = age
self.teaNum = teaNum
stu = Student('辰chen', 19, '171519')
stu.info()
tea = Teacher('晶姐', 30, '52519')
tea.info()

下面简单介绍多继承:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 1:49
# 欢迎大家关注AIoT相关博客~
class A(object):
pass
class B(object):
pass
class C(A, B): # C 有两个父类: A 和 B
pass
4.4 方法重写
🚩所谓方法重写其实就是当我们父类的某个属性或方法无法满足我们子类的需求,我们可以在子类中对其(方法体)进行重新编写,例如我们在 4.3 继承 中单继承的例子,我们在 Person 类中定义的 info 方法只能输出名字和年龄,但是学生和老师都有属于自己的学生编号和教职工编号,这些属性是子类中所特有的,但我们在调用子类中继承父类中的 info 方法时发现只能输出姓名和年龄,这不是我们想要的我,针对以上这种情况我们就可以使用方法重写。对于方法重写就是在子类中定义一个和父类中相同名称的函数体(可理解为覆盖)。
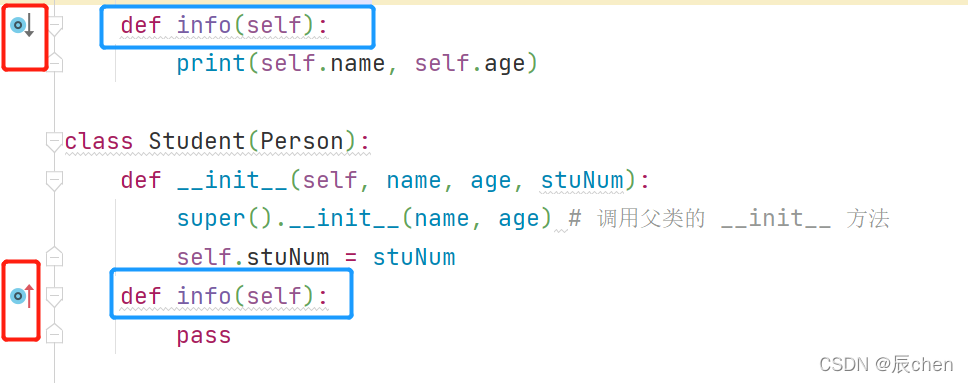
如上图所示,当你在子类中重写方法时在PyCharm中会有提示。
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 8:28
# 欢迎大家关注AIoT相关博客~
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name, self.age)
class Student(Person):
def __init__(self, name, age, stuNum):
self.name = name
self.age = age
self.stuNum = stuNum
def info(self):
print(self.stuNum)
class Teacher(Person):
def __init__(self, name, age, teaNum):
self.name = name
self.age = age
self.teaNum = teaNum
def info(self):
print(self.teaNum)
stu = Student('辰chen', 19, '171519')
stu.info()
tea = Teacher('晶姐', 30, '52519')
tea.info()

哎,问题又来了,我们成功输出了学号和教师编号,但是姓名和年龄却没有了,这就是我上面说过的覆盖,可以简单的理解成子类和父类同时定义了一个方法体,我们在实例化对象对方法进行调用的时候,优先调用子类的方法,我们如果想把输出姓名,年龄,编号都输出,当然可以在子类的方法中写成:
def info(self):
print(self.name, self.age, self.stuNum)
def info(self):
print(self.name, self.age, self.teaNum)
但这显然是不够简洁美观的,我们父类中的方法消失了么?其实并没有消失,我们只不过是优先调用了子类的方法。我们可以用super().xxx()去调用父类中被重写的方法。这样可以精简我们的代码:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 8:28
# 欢迎大家关注AIoT相关博客~
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name, self.age)
class Student(Person):
def __init__(self, name, age, stuNum):
self.name = name
self.age = age
self.stuNum = stuNum
def info(self):
super().info()
print(self.stuNum)
class Teacher(Person):
def __init__(self, name, age, teaNum):
self.name = name
self.age = age
self.teaNum = teaNum
def info(self):
super().info()
print(self.teaNum)
stu = Student('辰chen', 19, '171519')
stu.info()
tea = Teacher('晶姐', 30, '52519')
tea.info()

显然,父类中有 __init__() 方法,可以传入姓名和年龄两个参数,子类中也有 __init()__ 方法,这其实就是在重写父类中的方法,我们同样可以按照上述去调用父类中的 __init__() 方法,从而可以精简我们的代码:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 8:28
# 欢迎大家关注AIoT相关博客~
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name, self.age)
class Student(Person):
def __init__(self, name, age, stuNum):
super().__init__(name, age)
self.stuNum = stuNum
def info(self):
super().info()
print(self.stuNum)
class Teacher(Person):
def __init__(self, name, age, teaNum):
super().__init__(name, age)
self.teaNum = teaNum
def info(self):
super().info()
print(self.teaNum)
stu = Student('辰chen', 19, '171519')
stu.info()
tea = Teacher('晶姐', 30, '52519')
tea.info()

4.5 object类
🚩object类是所有类的父类,因此所有类都有object类的属性和方法。
class Student: # 默认继承 object 类
pass
class Teacher(): # 默认继承 object 类
pass
class headmaster(object):
pass
内置函数dir()可以查看指定对象所有属性
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 9:02
# 欢迎大家关注AIoT相关博客~
class Student: # 默认继承 object 类
pass
stu = Student()
print(dir(stu))

我们可以看到 object 类中其实有很多的属性以及方法,我们在之前其实已经介绍过了 __init__() 方法,这里我们介绍一下 object 中的 __str__() 方法,其他的方法和属性我们会在 4.7 特殊属性,4.8 特殊方法 中介绍。__str__() 方法用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象的信息,所以我们经常会对 __str__() 进行重写,不重写 __str__() 方法输出的其实是对象的内存地址。
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 9:02
# 欢迎大家关注AIoT相关博客~
class Student: # 默认继承 object 类
pass
stu = Student()
print(stu.__str__())

接下来我们去重写这个方法返回我们要的信息:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 9:02
# 欢迎大家关注AIoT相关博客~
class Student: # 默认继承 object 类
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return '你好,我是{0},今年{1}岁'.format(self.name, self.age)
stu = Student('辰chen', 19)
print(stu.__str__())

这里额外补充一下:直接输出对象名的形式其实就是默认调用 __str__() 方法:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 9:02
# 欢迎大家关注AIoT相关博客~
class Student: # 默认继承 object 类
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return '你好,我是{0},今年{1}岁'.format(self.name, self.age)
stu = Student('辰chen', 19)
print(stu)

4.6 多态的实现
🚩简单地说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法。
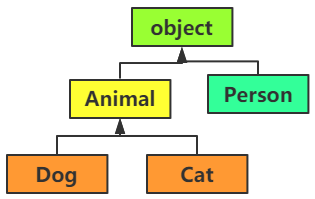
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 9:38
# 欢迎大家关注AIoT相关博客~
class Animal:
def eat(self):
print('动物会吃东西')
class Dog(Animal):
def eat(self):
print('狗会吃骨头')
class Cat(Animal):
def eat(self):
print('猫会吃鱼')
class Person:
def eat(self):
print('人会吃五谷杂粮')
# 类之外定义函数:
def fun(obj):
obj.eat()
# 在调用 fun() 函数的时候,我们只关心传入的类是否具有 eat() 方法,而并不关心类之间的关系。
fun(Dog())
fun(Cat())
fun(Animal())
fun(Person())

静态语言与动态语言
静态语言实现多态的三个必要条件:
1.继承
2.方法重写
3.父类引用指向子类对象
动态语言的多态崇尚“鸭子类型”当看到一只鸟走起来像鸭子、游泳起来像鸭子、收起来也像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为。
Python 就是动态语言,而 Java 就是静态语言
4.7 特殊属性
🚩部分特殊属性:
| 名称 | 描述 |
|---|---|
| __dict__ | 获得类对象或实例对象所绑定的所有属性和方法的字典序列 |
| __class__ | 获取对象所属的类 |
| __bases__ | 获取类的父类的元组序列 |
| __base__ | 获取类的基类(继承的第一个父类) |
| __mro__ | 获取类的层次结构 |
| __subclasses__ | 获取子类的列表序列 |
这里直接用代码去演示,具体实现看备注和运行结果即可:
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 10:48
# 欢迎大家关注AIoT相关博客~
#print(dir(object))
class A:
pass
class B:
pass
class C(A,B):
def __init__(self, name,age):
self.name = name
self.age = age
class D(A):
pass
#创建C类的对象
x = C('辰chen', 19) # x是C类型的一个实例对象
print(x.__dict__) # 实例对象的属性字典
print(C.__dict__) # 类的属性字典
print('-----------------------------')
print(x.__class__) # <class '__main__.C'> 输出了对象所属的类
print(C.__bases__) # C类的父类类型的元组
print(C.__base__) # 类的基类(哪个父类离得最近就输出哪个父类)
print(C.__mro__) # 类的层次结构
print(A.__subclasses__()) # 子类的列表
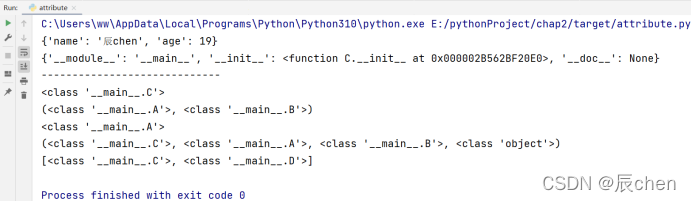
4.8 特殊方法
🚩部分特殊方法:
| 名称 | 描述 |
|---|---|
| __len__() | 通过重写__len__()方法,让内置函数len()的参数可以是自定义类型 |
| __add__() | 通过重写__add__()方法,可使用自定义对象具有“+”功能 |
| __new__() | 用于创建对象 |
| __init__() | 对创建的对象进行初始化 |
这里直接用代码去演示,具体实现看备注和运行结果即可:(__new__(),__init__() 会在下一小节中进行讲解)
❗️ 注:下面的代码使用了 __init__() 方法,后续会有讲解,读者这里只需要知道 __init__() 的含义是把输入的值进行赋值即可(对创建的对象进行初始化)
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 11:10
# 欢迎大家关注AIoT相关博客~
a, b = 10, 20
c = a + b # 两个整数类型的对象的相加操作
d = a.__add__(b) # '+'的底层实现
print(c)
print(d)
class Student:
def __init__(self,name):
self.name=name
def __add__(self, other):
return self.name+other.name
def __len__(self):
return len(self.name)
stu1=Student('辰chen')
stu2=Student('枭哥')
s = stu1 + stu2 #实现了两个对象的加法运算(因为在Student类中 编写__add__()特殊的方法)
print(s)
s = stu1.__add__(stu2)
print(s)
print('----------------------------------------')
lst = [1, 2, 3, 4]
print(len(lst)) # 调用内置函数 len() 计算列表的长度
print(lst.__len__())
print(len(stu1)) # 返回的是 stu1 的 name 长度
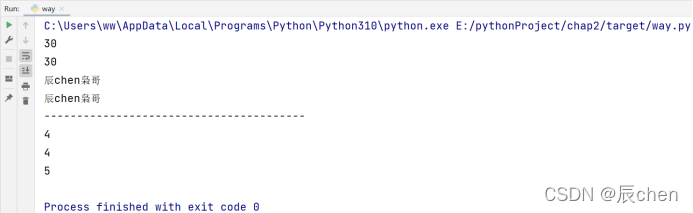
4.9 __new__与__init__演示创建对象的过程
🚩这里直接上代码,根据运行结果进行讲解:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 12:56
# 欢迎大家关注AIoT相关博客~
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行了,cls的id值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为:{0}'.format(id(obj)))
return obj
def __init__(self, name, age):
print('__init__被调用了,self的id值为:{0}'.format(id(self)))
self.name = name
self.age = age
print('object这个类对象的id为:{0}'.format(id(object)))
print('Person这个类对象的id为:{0}'.format(id(Person)))
#创建Person类的实例对象
p1 = Person('辰chen', 19)
print('p1这个Person类的实例对象的id:{0}'.format(id(p1)))
我们看到程序先执行的是第 18 行,输出了 object 的地址(我们地址用后四位进行简写):9312;然后输出了 Person 的地址:8560,然后执行第 21 行的 Person('辰chen', 19),创建一个实例化对象,然后程序来到了 7 行的 __new__(),这实际上就是把 Person 传给了 cls,故第 8 行输出 cls 的地址为:8560,紧接着第 9 行继续把 Person 传入,调用父类方法创建实例化对象 obj,然后输出 obj 的地址:0992,接着有 return 语句,return 实际是返回给了 13 行的 __init__()中的 self,故执行第 14 行代码,输出的 self 地址:0992,在经过了这些,实例化对象创建完成并赋值成功,最后再返回到 22 行,把创建好的对象赋值给 p1,故输出 p1 的地址为:0992.
*4.10 类的赋值与浅拷贝
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 变量的赋值操作:只是形成两个变量,实际上还是指向同一个对象
浅拷贝:Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
这里直接上代码,根据代码结果画出流程图去辅助理解:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 13:35
# 欢迎大家关注AIoT相关博客~
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
#(1)变量的赋值
cpu1 = CPU()
cpu2 = cpu1
print(cpu1, id(cpu1))
print(cpu2, id(cpu2))
print('------------------------------')
#(2)类有浅拷贝
disk = Disk() #创建一个硬盘类的对象
computer = Computer(cpu1, disk) #创建一个计算机类的对象
#浅拷贝
import copy
print(disk)
computer1 = copy.copy(computer)
print(computer, computer.cpu, computer.disk)
print(computer1, computer1.cpu, computer1.disk)
类对象的赋值操作内存图解:
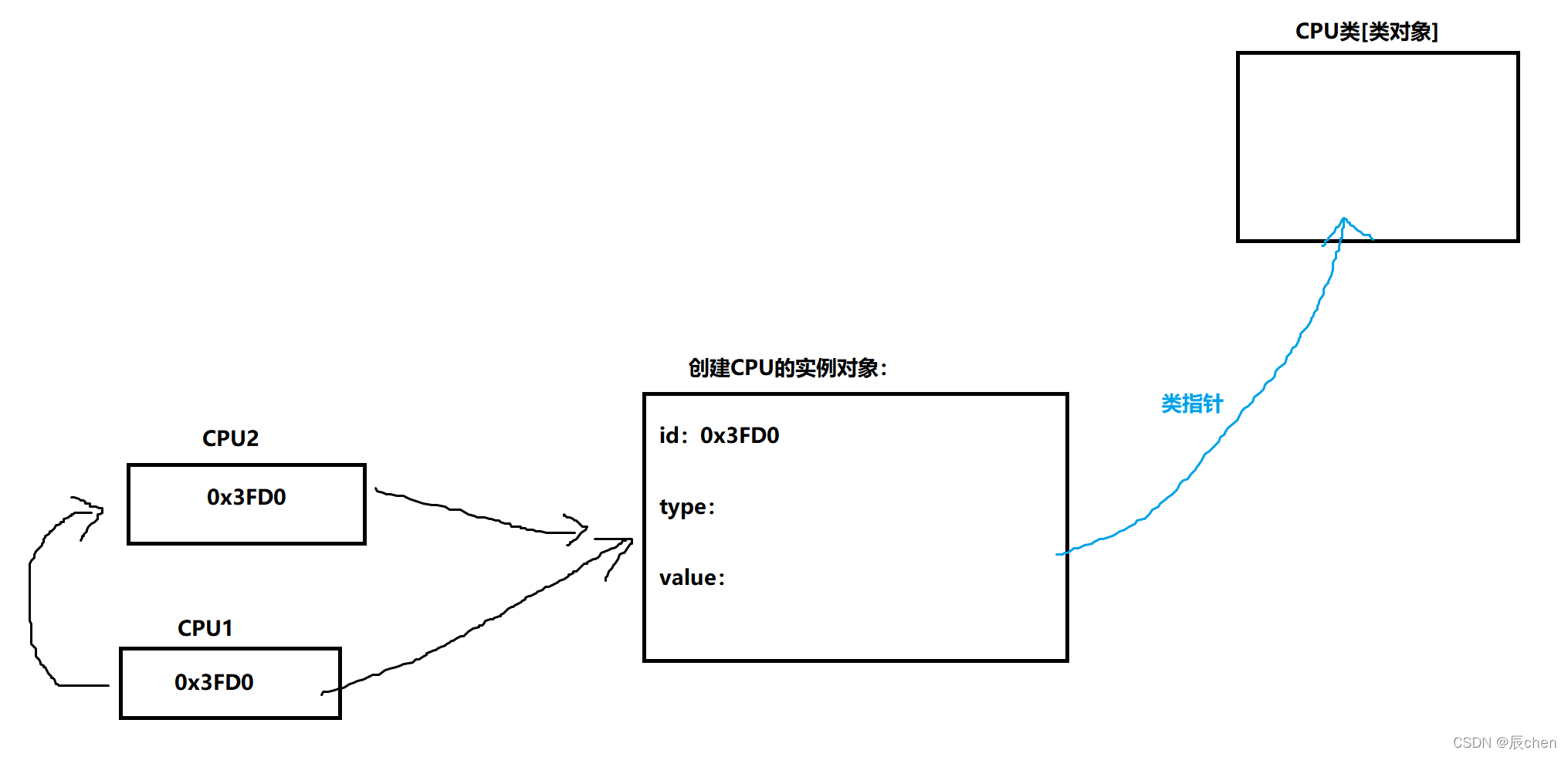
浅拷贝内存图解:
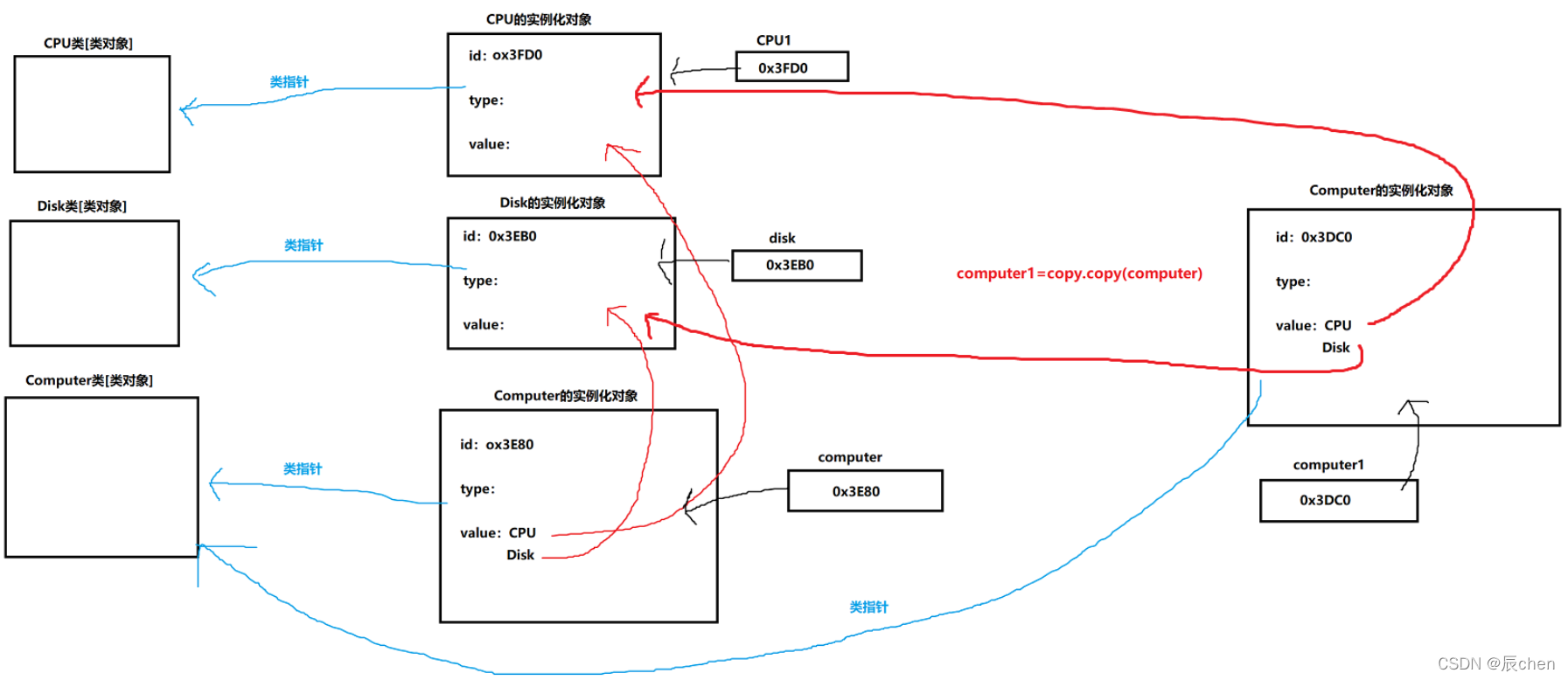
从这个图中其实很好理解浅拷贝,就是我们拷贝后,只拷贝了Computer实例化对象,并没有把CPU实例化对象和Disk实例化对象也拷贝一份,这样的拷贝模式就被称为浅拷贝。
*4.11 深拷贝
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 深拷贝:使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同。
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 13:35
# 欢迎大家关注AIoT相关博客~
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
#(1)变量的赋值
cpu1 = CPU()
cpu2 = cpu1
print(cpu1, id(cpu1))
print(cpu2, id(cpu2))
print('------------------------------')
#(2)类有浅拷贝
disk = Disk() #创建一个硬盘类的对象
computer = Computer(cpu1, disk) #创建一个计算机类的对象
#浅拷贝
import copy
print(disk)
computer1 = copy.copy(computer)
print(computer, computer.cpu, computer.disk)
print(computer1, computer1.cpu, computer1.disk)
print('------------------------------')
#深拷贝
computer2 = copy.deepcopy(computer)
print(computer, computer.cpu, computer.disk)
print(computer2, computer2.cpu, computer2.disk)
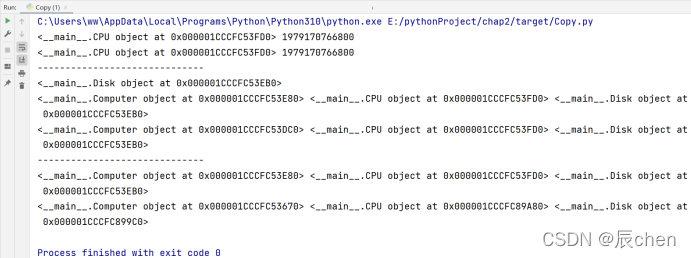
深拷贝内存图解:
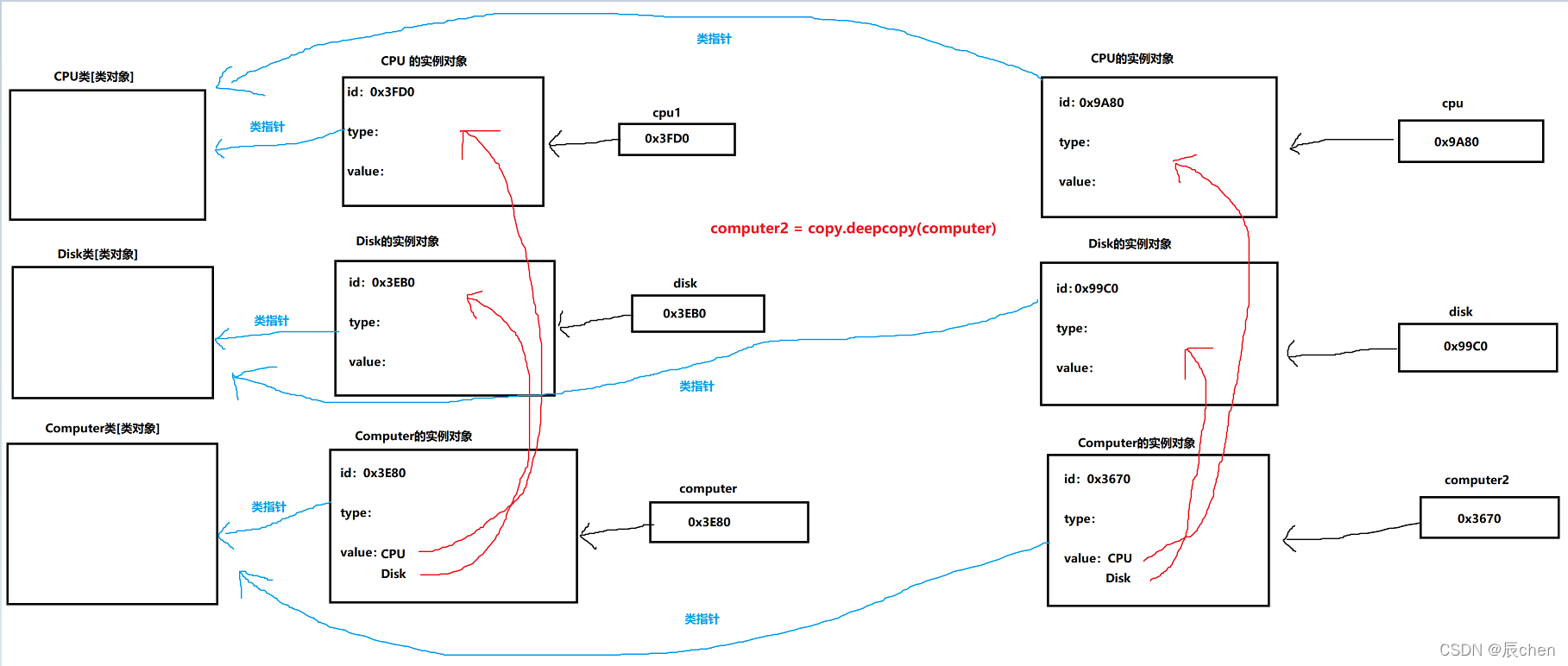
5.这是一封浪漫的情书
❗️ 注:注意文件这一章节因为涉及大量的文件路径相关的东西,不同的计算机的文件路径都可能有微小区别,故这章将很少展示运行结果,只附上代码,需读者根据自己的路径对代码进行小处理并自己操作。
*5.1 编码格式介绍
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 常见的字符编码格式
Python的解释器使用的是Unicode(内存)
.py文件在磁盘上使用UTF-8存储(外存)
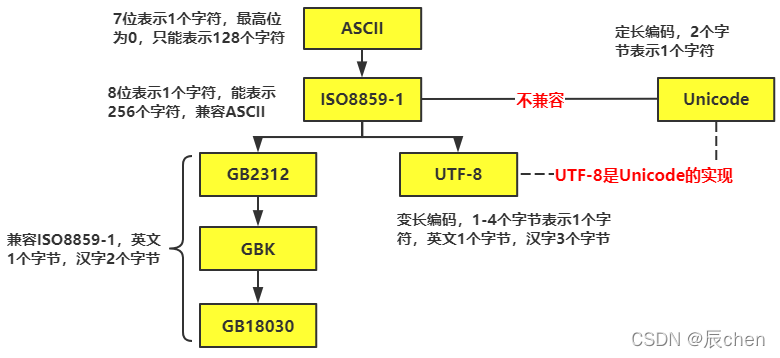
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 15:28
# 欢迎大家关注AIoT相关博客~
print('很感谢你看到了这里')
我们找到该Python文件的路径,选择用记事本打开。
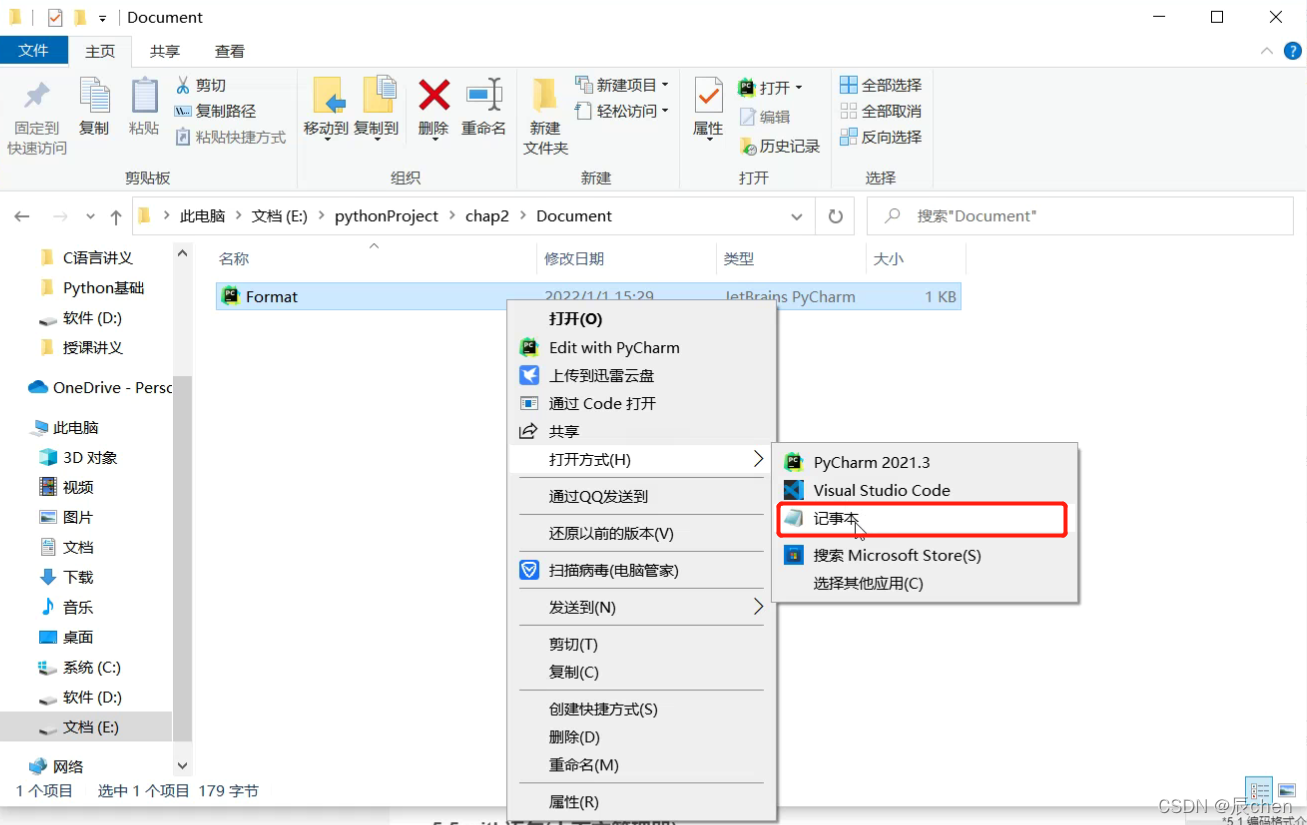
可以看到这里显示的是 UTF-8,我们也可以更改编码格式:在最开头加一行:# encoding=gbk
# encoding=gbk
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 15:28
# 欢迎大家关注AIoT相关博客~
print('很感谢你看到了这里')
我们找到该Python文件的路径,选择用记事本打开。
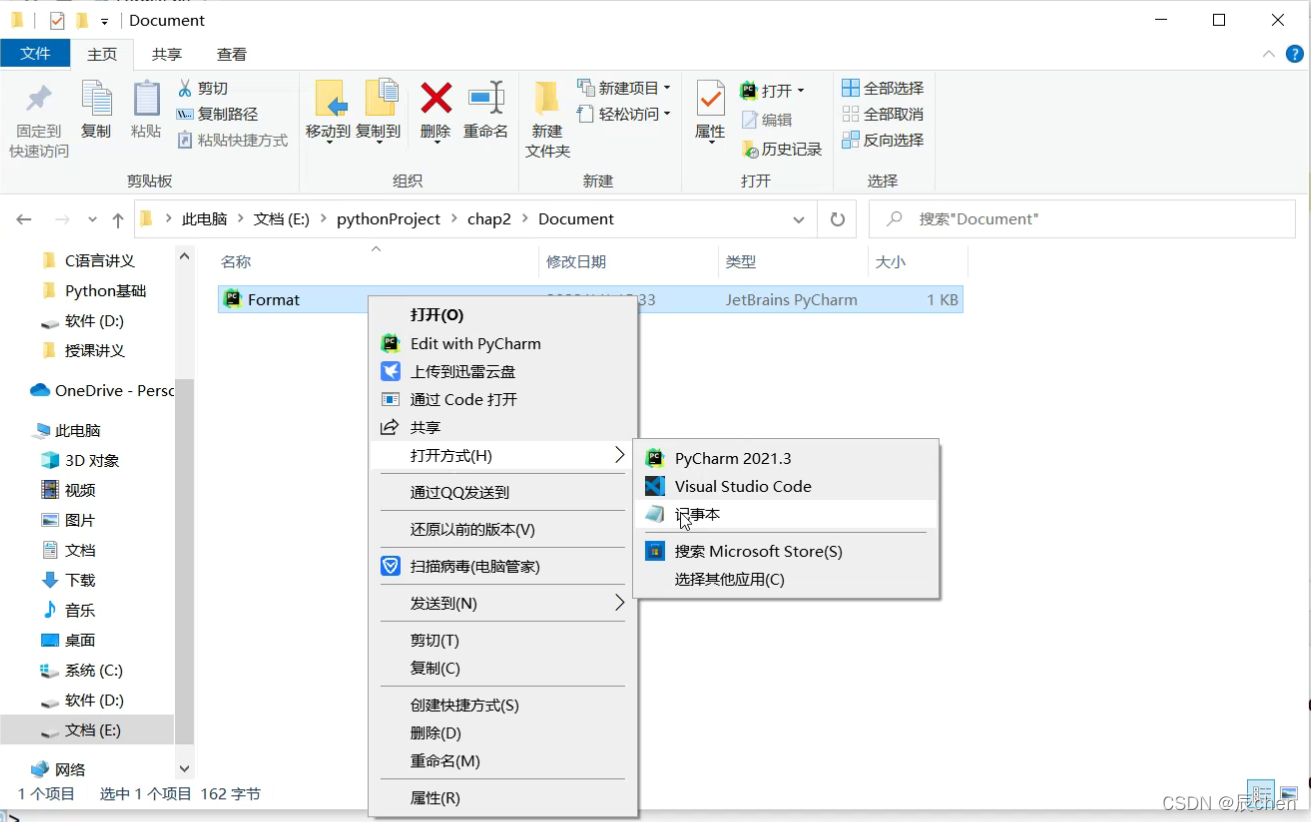
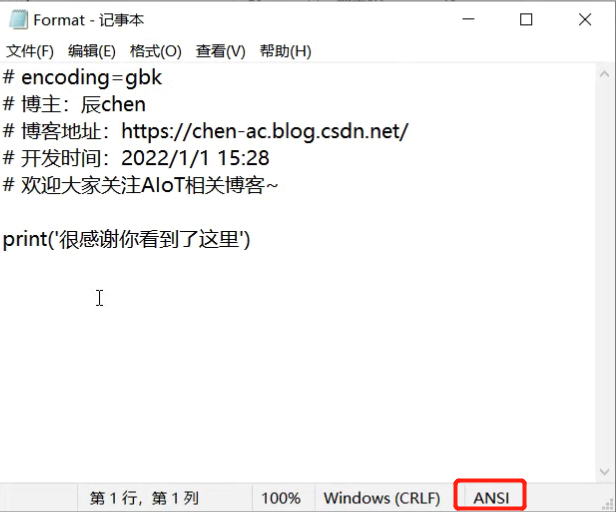
可以看到这里显示的是 ANSI,即我们更改了文件的编码格式。
这里我们还需要知道:不同的编码格式决定了占用磁盘空间的大小
*5.2 文件的读写原理
注:本小节带 *,不需要进行学习,可以简单进行了解
⛲️ 文件的读写俗称 IO 操作,i 就是 input(输入),o 就是 output(输出)
文件读写的操作流程可以分为如下图所示四步:
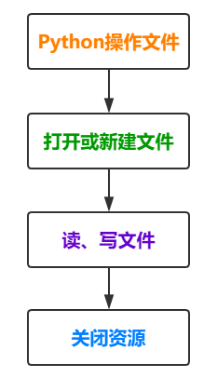
操作原理:
5.3 文件的读写操作
🚩内置函数open()打开文件对象(其实也可以创建,以后会有讲解,这里可以先行理解为 open() 为打开文件对象)
故我们先创建一个文本:a.txt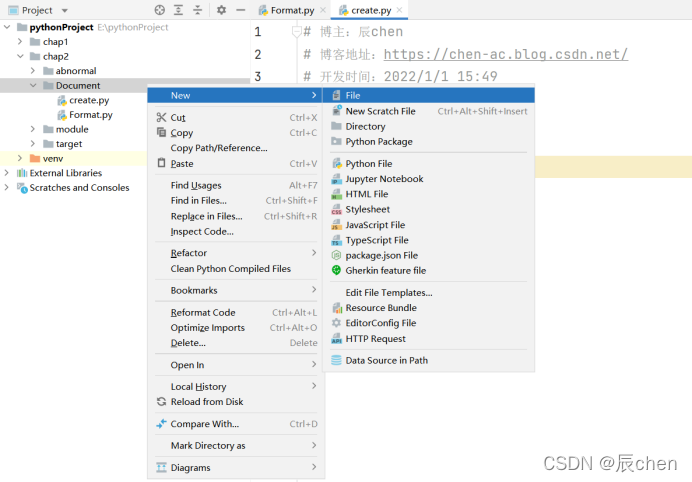
并在里面可以自己写上一些东西:
胜利就在眼前!!!
大家不要放弃呀!!!
文件读写的语法结构:
file = open(filename [,mode,encoding])
# file: 被创建的文件对象,当然你可以随意命名
# open: 创建文件对象的函数
# filename: 要打开的文件名称(也可以是要创建的文件名【后续讲解】)
# mode: 设置打开模式,默认为只读
# encoding: 设置字符的编写格式,默认文本文件中字符的编写格式为gbk
❗️ 注:下面的代码使用了 readlines() 方法,后续会有讲解,读者这里只需要知道 readlines() 的含义是读取文件中的信息即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 15:49
# 欢迎大家关注AIoT相关博客~
file = open('a.txt', encoding='utf-8')
# 默认为只读, gbk, 需要设置为 utf-8
print(file.readlines()) # file.readlines() 读取文件内容
file.close() # 关闭资源

文件的类型 :
按文件中数据的组织形式,文件分为以下两大类
文本文件 :存储的是普通“字符”文本,默认为unicode字符集,可以使用记本事程序打开
二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开 ,举例:mp3音频文件,jpg图片 .doc文档等
| 打开模式 | 描述 |
|---|---|
| r | 以只读模式打开文件,文件的指针将会放在文件的开头 |
| w | 以只写模式打开文件,如果文件不存在则创建,如果文件存在,则覆盖原有内容,文件指针在文件的开头 |
| a | 以追加模式打开文件,如果文件不存在则创建,文件指针在文件开头,如果文件存在,则在文件末尾追加内容,文件指针在源文件末尾 |
| b | 以二进制方式打开文件,不能单独使用,可以搭配使用如 rb(读取),wb(写入) |
| + | 以读写方式打开文件,不能单独使用,需要与其他模式一起使用,如 a+ |
下面的这些代码,读者可以敲写后运行测试结果:
❗️ 注:下面的代码使用了 write() 方法,后续会有讲解,读者这里只需要知道 write() 的含义是把信息写入到目标文件中即可
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 15:49
# 欢迎大家关注AIoT相关博客~
file = open('b.txt', 'w')
file.write('Python')
file.close()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 15:49
# 欢迎大家关注AIoT相关博客~
file = open('a.txt', 'a')
file.write('Python')
file.write('Python')
file.write('Python')
file.close()
5.4 文件对象常用的方法
| 方法名 | 说明 |
|---|---|
| read([size]) | 从文件中读取 size 个字节或字符的内容返回。若省略 [size],则读取到文件末尾,即一次读取文件所有内容 |
| readline() | 从文本文件中读取一行内容 |
| readlines() | 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入到列表返回 |
| write(str) | 将字符串 str 内容写入文件 |
| writelines(s_list) | 将字符串列表 s_list 写入文本文件,不添加换行符 |
| seek(offset[, whence]) | 把文件指针移动到新的位置,offset 表示相对于 whence 的位置:offset:为正往结束方向移动,为负往开始方向移动;whence 不同的值代表不同含义:0:从文件头开始计算(默认值);1:从当前位置开始计算;2:从文件尾开始计算 |
| tell() | 返回文件指针的当前位置 |
| flush() | 把缓冲区的内容写入文件,但不关闭文件 |
| close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源 |
下面的代码请读者自己于本地运行输出结果:
file = open('a.txt', 'r', encoding='utf-8')
print(file.read())
file.close()
file = open('a.txt', 'r', encoding='utf-8')
print(file.read(3))
file.close()
file = open('a.txt', 'r', encoding='utf-8')
print(file.readline())
file.close()
file = open('a.txt', 'r', encoding='utf-8')
print(file.readlines())
file.close()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 23:40
# 欢迎大家关注AIoT相关博客~
file = open('c.txt', 'w', encoding='utf-8')
file.write('hello 辰chen')
list = ['Python', 'C', 'C++', 'Java', 'go']
file.writelines(list)
file.close()
运行结束后,c.txt 的内容为:
hello 辰chenPythonCC++Javago
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/1 23:51
# 欢迎大家关注AIoT相关博客~
file = open('a.txt', 'r', encoding='utf-8')
file.seek(3) # 注意,如果采用utf-8,因为中文占3个字节,故如果你的文件内容是汉字,需为3的倍数
# 上一行代码其实就是跳过第一个汉字,从第二个汉字开始
print(file.read())
file.close()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:14
# 欢迎大家关注AIoT相关博客~
file = open('b.txt', 'r', encoding='utf-8')
file.seek(3)
print(file.read())
print(file.tell())
file.close()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:21
# 欢迎大家关注AIoT相关博客~
file = open('b.txt', 'w', encoding='utf-8')
file.write('hello')
file.flush()
file.write(' world')
# 程序不报错,flush操作后仍能继续写入内容
file.close()
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:21
# 欢迎大家关注AIoT相关博客~
file = open('b.txt', 'w', encoding='utf-8')
file.write('hello')
file.close()
file.write(' world')
# 程序报错,close操作后不能继续写入内容
file.flush()
5.5 with语句(上下文管理器)
🚩with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
我们直接上代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:36
# 欢迎大家关注AIoT相关博客~
with open('a.txt','r', encoding='utf-8') as file:
print(file.read())

可以看出,在使用了 with 语句之后,我们可以不用手写 close,会自动关闭文件资源。
with 语句的使用语法:
with open() as 文件名
语句体
当然也有:
with 类方法 as 对象
一个类对象,实现了\_\_enter\_\_(),\_\_exit\_\_()这两个特殊方法
称这个类对象遵守上下文管理协议,而这个类的实例对象被称为上下文管理器
我们把 with 语句之后的,as语句之前的:open(), 类方法 被称为上下文表达式,结果为上下文管理器
下面我们用一个类对象去介绍:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:36
# 欢迎大家关注AIoT相关博客~
'''
MyContentMgr实现了特殊方法__enter__(),__exit__()称为该类对象遵守了上下文管理器协议
该类对象的实例对象,称为上下文管理器
'''
class MyContentMgr(object):
def __enter__(self):
print('enter方法被调用执行了')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit方法被调用执行了')
def show(self):
print('show方法被调用执行了')
with MyContentMgr() as file: #相当于file=MyContentMgr()
file.show()

我们在最开头说过,无论什么原因跳出 with 块,都能确保文件正常的关闭,即不论发生什么,我们都会执行__enter__(),__exit__(),我们来给上述代码搞点破坏,看看能不能还执行这两个特殊方法:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 9:36
# 欢迎大家关注AIoT相关博客~
'''
MyContentMgr实现了特殊方法__enter__(),__exit__()称为该类对象遵守了上下文管理器协议
该类对象的实例对象,称为上下文管理器
'''
class MyContentMgr(object):
def __enter__(self):
print('enter方法被调用执行了')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit方法被调用执行了')
# 在 show() 中加入 1 / 0
def show(self):
print('show方法被调用执行了', 1 / 0)
with MyContentMgr() as file: #相当于file=MyContentMgr()
file.show()
可以看到,虽然抛出异常,但是我们的 enter方法和exit方法还是执行了。
我们在后续涉及到文件处理的时候,要尽量去使用 with语句。
5.6 目录操作
1.os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
2.os模块与os.path模块用于对目录或文件进行操作
5.6.1 os模块
🚩os模块操作目录相关函数
| 函数 | 说明 |
|---|---|
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path[,mode]) | 创建目录 |
| makedirs(path1/path2...[,mode]) | 创建多级目录 |
| rmdir(path) | 删除目录 |
| removedirs(path1/path2......) | 删除多级目录 |
| chdir(path) | 将path设置为当前工作目录 |
这些函数如果你学过 linux,那么你会觉得很熟悉,其实也没什么区别,只不过是用 Python 去使用了一些操作指令,大家可以自行在 PyCharm 中调用这些函数,这里不再赘述。
执行操作系统的内容:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 10:17
# 欢迎大家关注AIoT相关博客~
# os模块与操作系统相关的一个模块
import os
os.system('notepad.exe') # 打开记事本
os.system('calc.exe') # 打开计算器
# 直接调用可执行文件
os.startfile('D:\\QQ\\Bin\\QQScLauncher.exe')
# 第11行代码为打开QQ,需要找到你的QQ安装位置才可以打开,注意转义字符需要 \\
5.6.2 os.path模块
🚩os.path模块操作目录相关函数
| 函数 | 说明 |
|---|---|
| abspath(path) | 用于获取文件或目录的绝对路径 |
| exists(path) | 用于判断文件或目录是否存在,如果存在返回 True,否则返回False |
| join(path, name) | 将目录与目录或者文件名拼接起来 |
| splitext() | 分离文件名和扩展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdit(path) | 用哦关于判断是否为路径 |
函数结果演示:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 10:53
# 欢迎大家关注AIoT相关博客~
import os.path
print(os.path.abspath('OsPath.py'))
print(os.path.exists('OsPath.py'),os.path.exists('666.py'))
print(os.path.join('E:\\pythonProject', 'OsPath.py'))
print(os.path.split('E:\\pythonProject.py\\chap2\\Document\\OsPath.py'))
print(os.path.splitext('OsPath.py.py'))
print(os.path.basename('E:\\pythonProject.py\\chap2\\Document\\OsPath.py'))
print(os.path.dirname('E:\\pythonProject.py\\chap2\\Document\\OsPath.py'))
print(os.path.isdir('E:\\pythonProject.py\\chap2\\Document\\OsPath.py'))
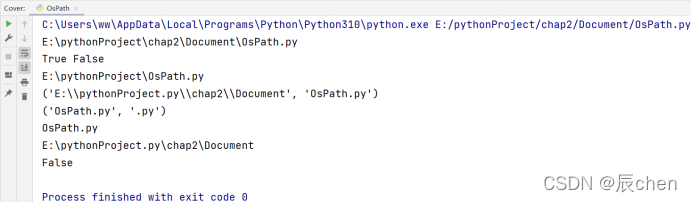
列出指定目录下的所有 py 文件:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 10:57
# 欢迎大家关注AIoT相关博客~
import os
path=os.getcwd()
lst=os.listdir(path)
for filename in lst:
if filename.endswith('.py'):
print(filename)
walk() 方法:递归遍历所有的文件:可以把指定目录下的子目录文件也一一列举出来。
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 11:05
# 欢迎大家关注AIoT相关博客~
import os
path = os.getcwd()
lst_files = os.walk(path)
for dirpath, dirname, filename in lst_files:
'''
print(dirpath)
print(dirname)
print(filename)
print('----------------------------------')
'''
for dir in dirname:
print(os.path.join(dirpath, dir))
for file in filename:
print(os.path.join(dirpath, file))
print('----------------------------------')
四、学生管理系统
1.需求分析
学生管理系统应具备的功能
1.添加学生及成绩信息
2.将学生信息保存到文件中
3.修改和删除学生信息
4.查询学生信息
5.根据学生成绩进行排序
6.统计学生的总分
2.系统设计
系统功能结构
学生信息管理系统的7大模块
1.录入学生信息模块
2.查找学生信息模块
3.删除学生信息模块
4.修改学生信息模块
5.学生成绩排名模块
6.统计学生总人数模块
7.显示全部学生信息模块
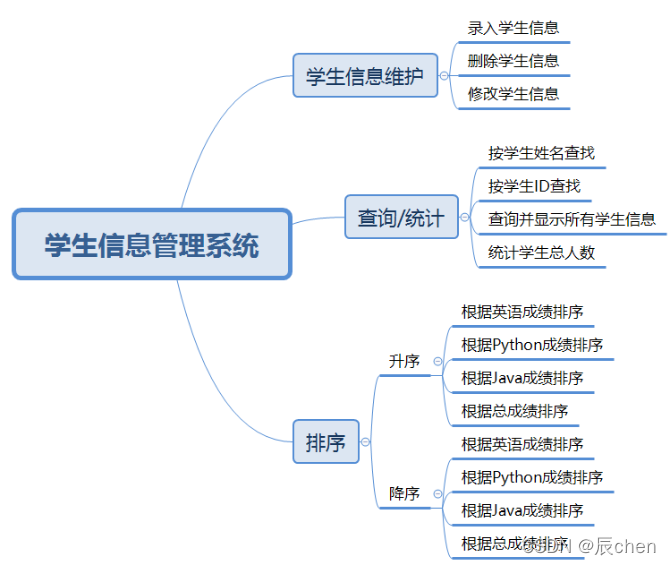
系统业务流程
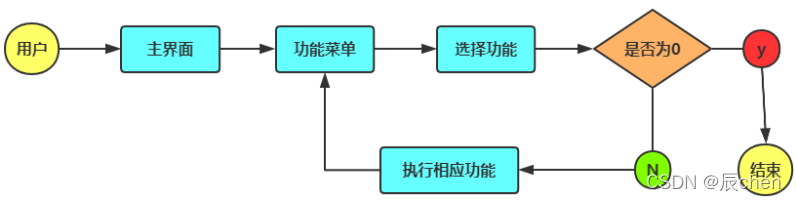
3.系统开发必备
1.系统开发环境
a.操作系统:win10
b.Python解释器版本 :Python3.10
c.开发工具:PyCharm
d.Python内置模块:os ,re
2.项目目录结构

4.主函数设计
系统主界面运行效果图:

主函数的业务流程
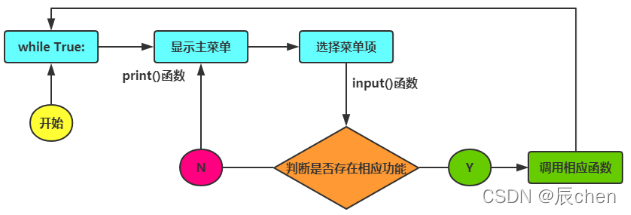
实现主函数
| 编号 | 功能 |
|---|---|
| 0 | 退出系统 |
| 1 | 录入学生信息,调用 insert() 函数 |
| 2 | 查找学生信息,调用 search() 函数 |
| 3 | 删除学生信息,调用 delete() 函数 |
| 4 | 修改学生信息,调用 modify() 函数 |
| 5 | 对学生成绩排序,调用 sort() 函数 |
| 6 | 统计学生总人数,调用 total() 函数 |
| 7 | 显示所有的学生信息,调用 show() 函数 |
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 12:25
# 欢迎大家关注AIoT相关博客~
def main():
while True:
menu()
choice = int(input('请选择:'))
if choice in range(8):
if choice == 0:
flag = True
while True:
answer = input('您确定要退出系统吗?y/n:')
if answer == 'y' or answer == 'Y':
print('感谢您的使用!!!')
break # 退出 y/n 循环
elif answer == 'n' or answer == 'N':
flag = False # 更改 flag 的值
break # 退出 y/n 循环
else: # 输入了未知的字符,重新输入
print('输入错误,请重新输入', end=' ')
if flag: # flag = True代表退出
break # 退出循环
else: # flag = False代表不退出
continue
elif choice == 1:
insert()
elif choice == 2:
search()
elif choice == 3:
delete()
elif choice == 4:
modify()
elif choice == 5:
sort()
elif choice == 6:
total()
elif choice == 7:
show()
def menu():
print('==========================学生信息管理系统==========================')
print('-----------------------------功能菜单-----------------------------')
print('\t\t\t\t\t\t 1.录入学生信息')
print('\t\t\t\t\t\t 2.查找学生信息')
print('\t\t\t\t\t\t 3.删除学生信息')
print('\t\t\t\t\t\t 4.修改学生信息')
print('\t\t\t\t\t\t 5.排序')
print('\t\t\t\t\t\t 6.统计学生总人数')
print('\t\t\t\t\t\t 7.显示所有学生信息')
print('\t\t\t\t\t\t 0.退出')
print('-----------------------------------------------------------------')
def insert():
pass
def search():
pass
def delete():
pass
def modify():
pass
def sort():
pass
def total():
pass
def show():
pass
if __name__ == '__main__':
main()

5.学生信息维护模块设计
5.1 录入学生信息功能
实现录入学生信息功能
从控制台录入学生信息,并且把它们保存到磁盘文件中
业务流程
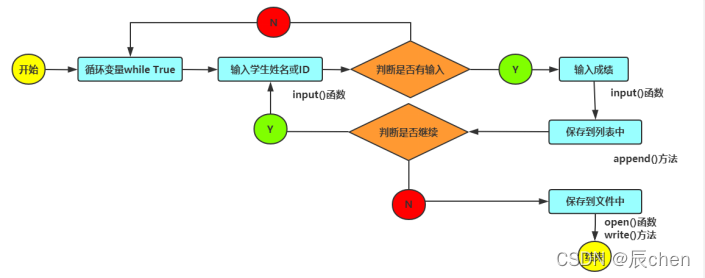
具体实现
save(student)函数,用于将学生信息保存到文件
insert()函数,用于录入学生信息
因为我们要反复用到保存信息的磁盘文件,故我们在代码最开始定义一个变量:
filename = 'student.txt'
insert() 函数:
def insert():
student_list = []
while True:
id = input('请输入ID(如1001):')
if not id:
break
name = input('请输入姓名:')
if not name:
break
try:
englist = int(input('请输入英语成绩:'))
python = int(input('请输入Python成绩:'))
java = int(input('请输入Java成绩:'))
except:
print('输入无效,不是整数类型,请重新输入')
continue
#将录入的学生信息保存到字典中
student={'id':id, 'name':name, 'english':englist, 'python':python, 'java':java}
#将学生信息添加到列表中
student_list.append(student)
answer=input('是否继续添加?y/n\n')
if answer=='y':
continue
else:
break
#调用save()函数
save(student_list)
print('学生信息录入完毕!!!')
save() 函数:
def save(lst):
try:
stu_txt = open(filename,'a',encoding='utf-8')
except:
stu_txt = open(filename,'w',encoding='utf-8')
for item in lst:
stu_txt.write(str(item)+'\n')
stu_txt.close()
运行实例:

查看一下我们的 student.txt 文件:
{'id': '1001', 'name': '辰chen', 'english': 60, 'python': 100, 'java': 60}
{'id': '1002', 'name': '娇妹儿', 'english': 70, 'python': 100, 'java': 90}
{'id': '1003', 'name': '枭哥', 'english': 80, 'python': 90, 'java': 90}
5.2 删除学生信息功能
实现修改学生信息功能
从控制台录入学生ID,到磁盘文件中找到对应的学生信息,将其进行修改
业务流程
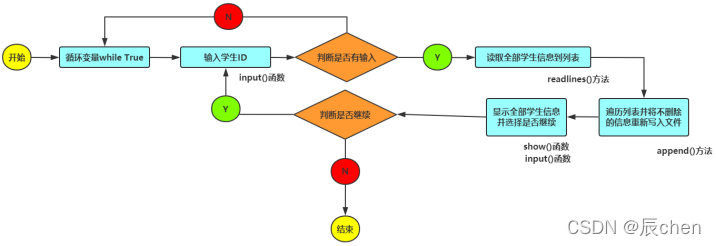
具体实现
编写主函数中调用的删除学生信息的函数delete()
调用了show()函数显示学生信息,该函数的功能将在后面完成
show() 函数会在后面实现,这里实现 delete() 函数,需导入 os:
def delete():
while True:
student_id = input('请输入要删除的学生的ID:')
if student_id != '':
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as file:
student_old = file.readlines()
else:
student_old = []
flag = False # 标记是否删除
if student_old:
with open(filename, 'w', encoding='utf-8') as wfile:
d = {}
for item in student_old:
d = dict(eval(item)) # 将字符串转成字典
if d['id'] != student_id:
wfile.write(str(d) + '\n')
else:
flag = True
if flag:
print(f'id为{student_id}的学生信息已被删除')
else:
print(f'没有找到ID为{student_id}的学生信息')
else:
print('无学生信息')
break
show() # 删除之后要重新显示所有学生信息
answer = input('是否继续删除?y/n\n')
if answer == 'y':
continue
else:
break
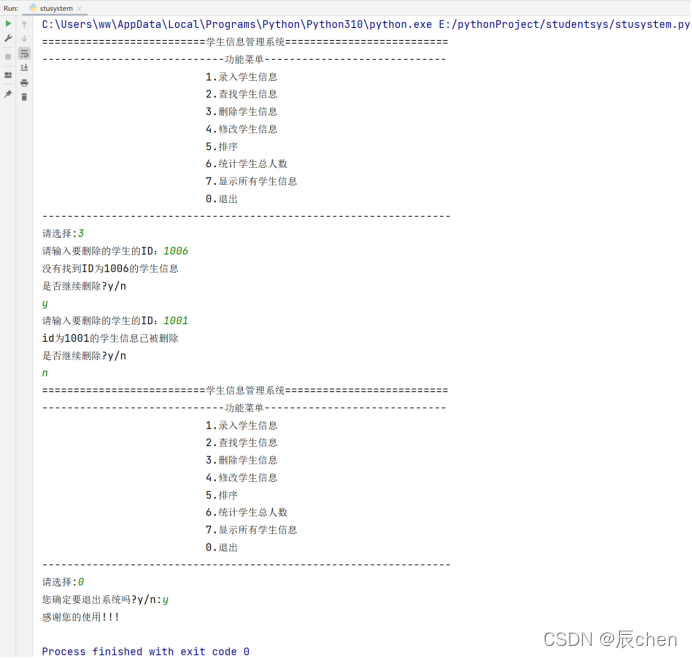
student.txt 文档:
{'id': '1002', 'name': '娇妹儿', 'english': 70, 'python': 100, 'java': 90}
{'id': '1003', 'name': '枭哥', 'english': 80, 'python': 90, 'java': 90}
5.3 修改学生信息功能
实现修改学生信息功能
从控制台录入学生ID,到磁盘文件中找到对应的学生信息,将其进行修改
业务流程
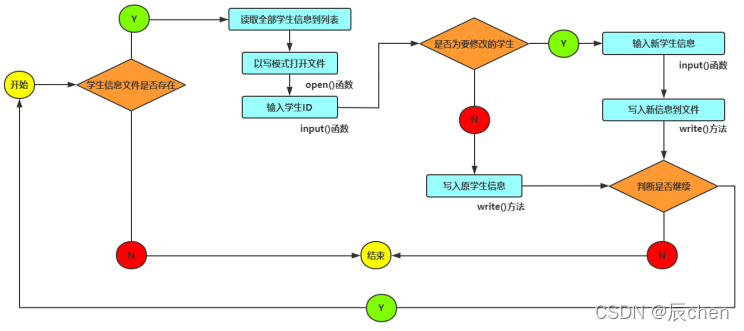
具体实现
编写主函数中调用的修改学生信息的函数modify()
调用了show()函数显示学生信息,该函数的功能将在后面完成
def modify():
show()
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
student_old = rfile.readlines()
else:
return
student_id = input('请输入要修改的学员的ID:')
if student_id != '':
with open(filename, 'w', encoding='utf-8') as wfile:
for item in student_old:
d = dict(eval(item))
if d['id'] == student_id:
print('找到学生信息,可以修改他的相关信息了!')
while True:
try:
d['name'] = input('请输入姓名:')
d['english'] = input('请输入英语成绩:')
d['python'] = input('请输入Python成绩:')
d['java'] = input('请输入Java成绩:')
except:
print('您的输入有误,请重新输入!!!')
else:
break
wfile.write(str(d) + '\n')
print('修改成功!!!')
else:
wfile.write(str(d) + '\n')
answer = input('是否继续修改其它学生信息?y/n\n')
if answer == 'y':
modify()
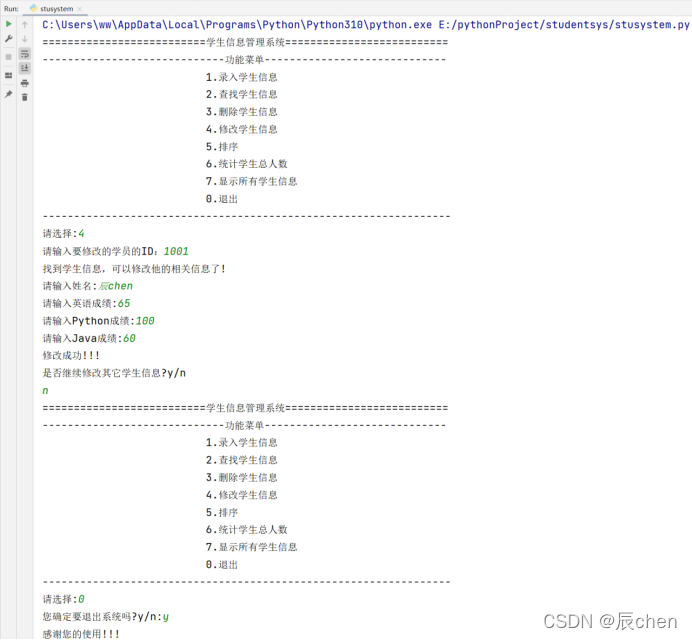
student.txt 文档:
{'id': '1002', 'name': '娇妹儿', 'english': 70, 'python': 100, 'java': 90}
{'id': '1003', 'name': '枭哥', 'english': 80, 'python': 90, 'java': 90}
{'id': '1001', 'name': '辰chen', 'english': '65', 'python': '100', 'java': '60'}
6.查询/统计模块设计
6.1 查找学生信息功能
*实现查询学生信息功能
从控制台录入学生ID或姓名,到磁盘文件中找到对应的学生信息
业务流程
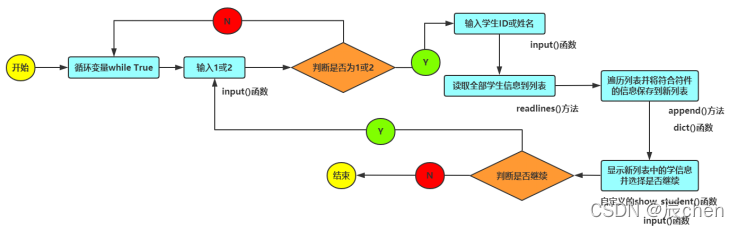
具体实现
编写主函数中调用的查找学生信息的函数search()
定义显示查询结果的函数show_student(query_student)
search() 函数:
def search():
student_query = []
while True:
id = ''
name = ''
if os.path.exists(filename):
mode = input('按ID查找请输入1,按姓名查找请输入2:')
if mode == '1':
id = input('请输入学生ID:')
elif mode == '2':
name = input('请输入学生姓名:')
else:
print('您的输入有误,请重新输入')
search()
with open(filename, 'r', encoding='utf-8') as rfile:
student = rfile.readlines()
for item in student:
d = dict(eval(item))
if id != '':
if d['id'] == id:
student_query.append(d)
elif name != '':
if d['name'] == name:
student_query.append(d)
# 显示查询结果
show_student(student_query)
# 清空列表
student_query.clear()
answer = input('是否要继续查询?y/n\n')
if answer == 'y':
continue
else:
break
else:
print('暂未保存学生信息')
return
show_student() 函数:
def show_student(lst):
if len(lst)==0:
print('没有查询到学生信息,无数据显示!!!')
return
# 定义标题显示格式
format_title='{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
print(format_title.format('ID', '姓名', '英语成绩', 'Python成绩', 'Java成绩', '总成绩'))
# 定义内容的显示格式
format_data='{:^6}\t{:^12}\t{:^8}\t{:^8}\t{:^8}\t{:^8}'
for item in lst:
print(format_data.format(item.get('id'),
item.get('name'),
item.get('english'),
item.get('python'),
item.get('java'),
int(item.get('english'))
+int(item.get('python'))
+int(item.get('java'))
))
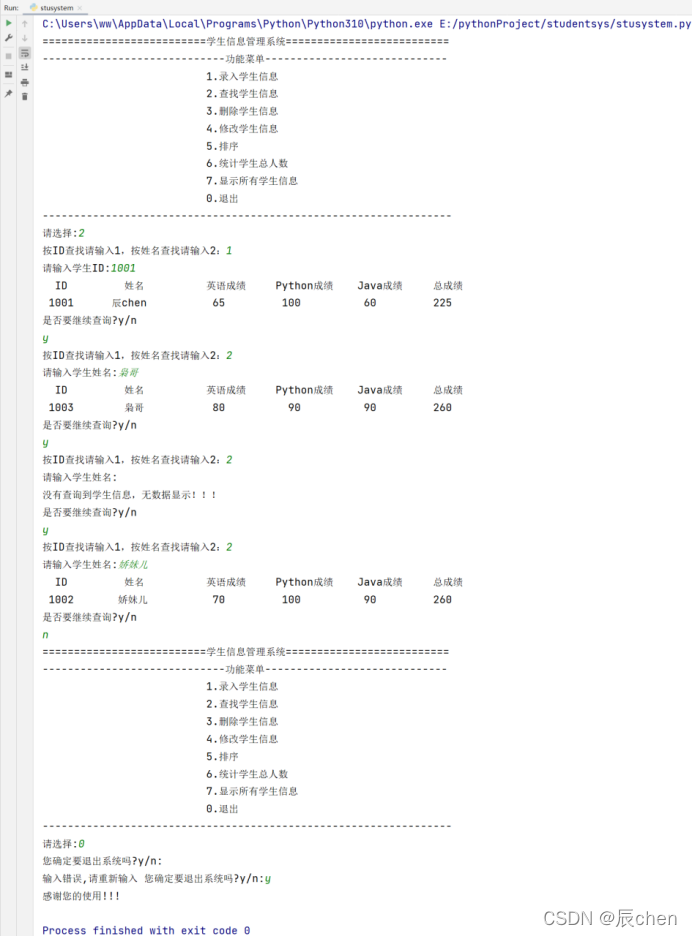
6.2 统计学生总人数功能
实现统计学生总人数功能
统计学生信息文件中保存的学生信息个数
业务流程
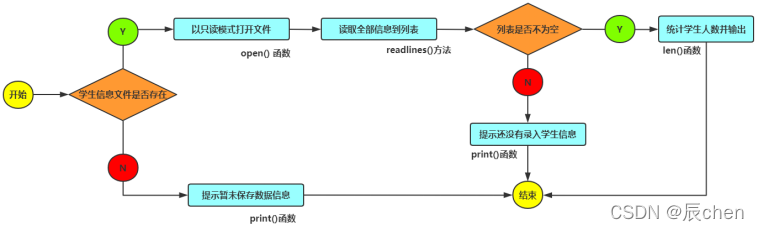
total() 函数:
def total():
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
students = rfile.readlines()
if students:
print(f'一共有{len(students)}名学生')
else:
print('还没有录入学生信息')
else:
print('暂未保存数据信息.....')

6.3 显示所有学生信息功能
实现显示所有学生信息功能
将学生信息文件中保存的全部学生信息获取并显示
业务流程
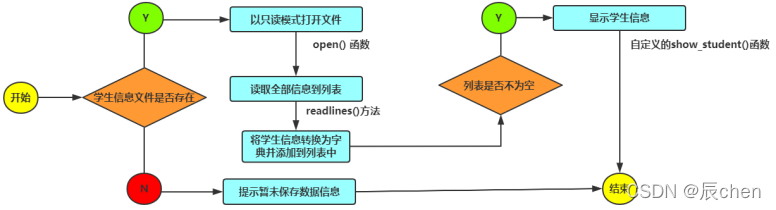
show() 函数:
def show():
student_lst = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
students = rfile.readlines()
for item in students:
student_lst.append(eval(item))
if student_lst:
show_student(student_lst)
else:
print('暂未保存过数据!!!!')

7.排序模块设计
实现按学生成绩排序功能
主要对学生信息按英语成绩、Python成绩、Java成绩、总成绩进行升序或降序排序
业务流程
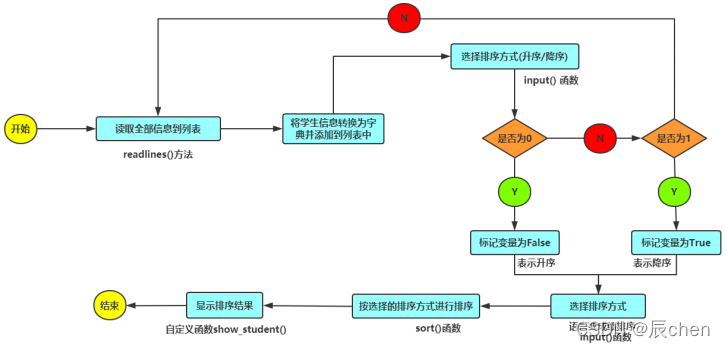
sort() 函数:
def sort():
show()
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
student_list = rfile.readlines()
student_new = []
for item in student_list:
d = dict(eval(item))
student_new.append(d)
else:
return
asc_or_desc = input('请选择(0.升序 1.降序):')
if asc_or_desc == '0':
asc_or_desc_bool = False
elif asc_or_desc == '1':
asc_or_desc_bool = True
else:
print('您的输入有误,请重新输入')
sort()
mode = input('请选择排序方式(1.按英语成绩排序 2.按Python成绩排序 3.按Java成绩排序 0.按总成绩排序):')
if mode == '1':
student_new.sort(key = lambda x: int(x['english']), reverse=asc_or_desc_bool)
elif mode == '2':
student_new.sort(key = lambda x: int(x['python']), reverse=asc_or_desc_bool)
elif mode == '3':
student_new.sort(key = lambda x: int(x['java']), reverse=asc_or_desc_bool)
elif mode == '0':
student_new.sort(key = lambda x: int(x['english']) + int(x['python'])
+ int(x['java']), reverse=asc_or_desc_bool)
else:
print('您的输入有误,请重新输入!!!')
sort()
show_student(student_new)
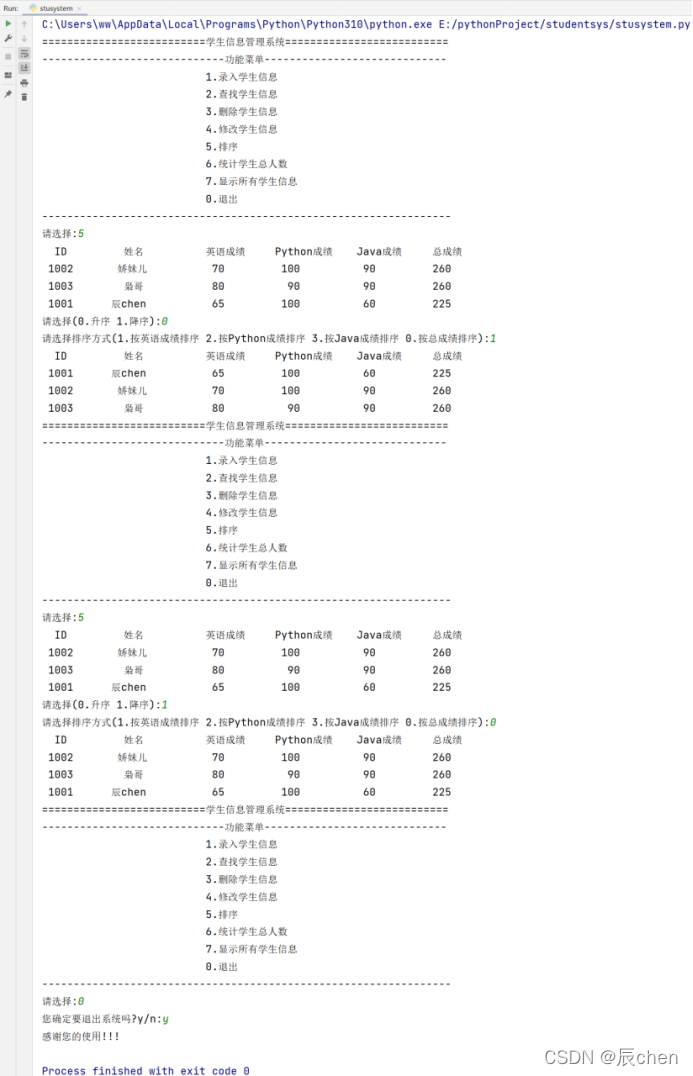
8.项目打包
安装第三方模块
在线安装方式
Windows + R 打开 cmd,输入pip install PyInstaller
下载等待:
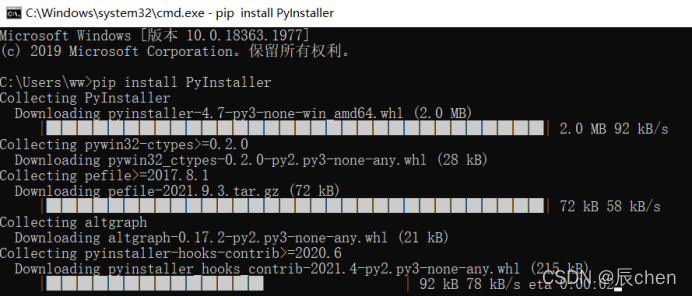
下载完成:
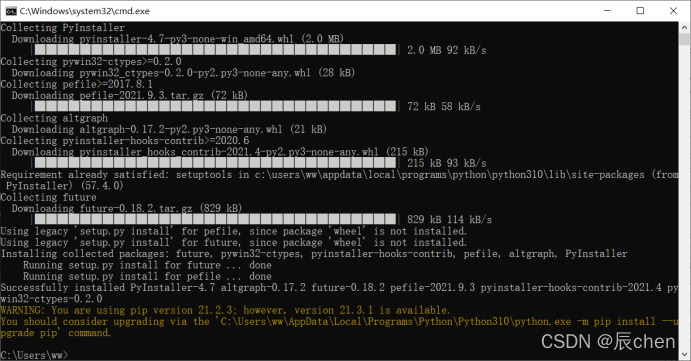
执行打包操作
输入:pyinstaller -F 文件路径
文件路径就是我们写好的 stusystem.py 的绝对路径
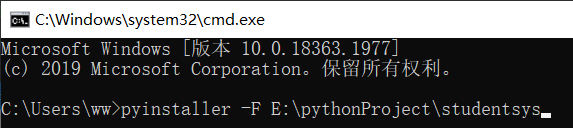
再把文件名给复制进来:

回车后等待生成可执行文件:
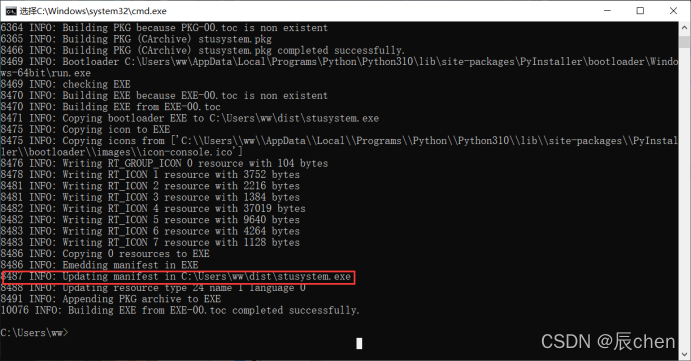
红圈圈住的就是生成的可执行文件地址,根据地址可找到我们的文件。
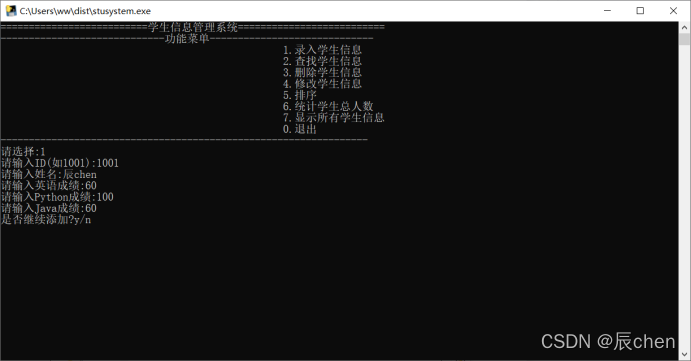
9.总结与完整代码
总结:都说学生管理系统已经是个烂大街的项目,但是确确实实第一次完整的设计并敲出代码还是有些费时间,不得不承认,这是一个很适合初学者的小项目,希望读者能在理解代码的基础之上自己独立完整的敲打一遍;本文的代码还有一些不足之处,只能说是学生管理系统的大模板,代码健壮性很差,读者可以自己完善代码,多使用 try catch 来应对异常的处理。另外,对于文件的操作希望读者掌握,这些操作在以后的工作之中会经常的使用。
完整代码:
# 博主:辰chen
# 博客地址:https://chen-ac.blog.csdn.net/
# 开发时间:2022/1/2 12:25
# 欢迎大家关注AIoT相关博客~
import os
filename = 'student.txt'
def main():
while True:
menu()
choice = int(input('请选择:'))
if choice in range(8):
if choice == 0:
flag = True
while True:
answer = input('您确定要退出系统吗?y/n:')
if answer == 'y' or answer == 'Y':
print('感谢您的使用!!!')
break # 退出 y/n 循环
elif answer == 'n' or answer == 'N':
flag = False # 更改 flag 的值
break # 退出 y/n 循环
else: # 输入了未知的字符,重新输入
print('输入错误,请重新输入', end=' ')
if flag: # flag = True代表退出
break # 退出循环
else: # flag = False代表不退出
continue
elif choice == 1:
insert()
elif choice == 2:
search()
elif choice == 3:
delete()
elif choice == 4:
modify()
elif choice == 5:
sort()
elif choice == 6:
total()
elif choice == 7:
show()
def menu():
print('==========================学生信息管理系统==========================')
print('-----------------------------功能菜单-----------------------------')
print('\t\t\t\t\t\t 1.录入学生信息')
print('\t\t\t\t\t\t 2.查找学生信息')
print('\t\t\t\t\t\t 3.删除学生信息')
print('\t\t\t\t\t\t 4.修改学生信息')
print('\t\t\t\t\t\t 5.排序')
print('\t\t\t\t\t\t 6.统计学生总人数')
print('\t\t\t\t\t\t 7.显示所有学生信息')
print('\t\t\t\t\t\t 0.退出')
print('-----------------------------------------------------------------')
def insert():
student_list = []
while True:
id = input('请输入ID(如1001):')
if not id:
break
name = input('请输入姓名:')
if not name:
break
try:
englist = int(input('请输入英语成绩:'))
python = int(input('请输入Python成绩:'))
java = int(input('请输入Java成绩:'))
except:
print('输入无效,不是整数类型,请重新输入')
continue
#将录入的学生信息保存到字典中
student={'id':id, 'name':name, 'english':englist, 'python':python, 'java':java}
#将学生信息添加到列表中
student_list.append(student)
answer=input('是否继续添加?y/n\n')
if answer=='y':
continue
else:
break
#调用save()函数
save(student_list)
print('学生信息录入完毕!!!')
def save(lst):
try:
stu_txt = open(filename,'a',encoding='utf-8')
except:
stu_txt = open(filename,'w',encoding='utf-8')
for item in lst:
stu_txt.write(str(item)+'\n')
stu_txt.close()
def search():
student_query = []
while True:
id = ''
name = ''
if os.path.exists(filename):
mode = input('按ID查找请输入1,按姓名查找请输入2:')
if mode == '1':
id = input('请输入学生ID:')
elif mode == '2':
name = input('请输入学生姓名:')
else:
print('您的输入有误,请重新输入')
search()
with open(filename, 'r', encoding='utf-8') as rfile:
student = rfile.readlines()
for item in student:
d = dict(eval(item))
if id != '':
if d['id'] == id:
student_query.append(d)
elif name != '':
if d['name'] == name:
student_query.append(d)
# 显示查询结果
show_student(student_query)
# 清空列表
student_query.clear()
answer = input('是否要继续查询?y/n\n')
if answer == 'y':
continue
else:
break
else:
print('暂未保存学生信息')
return
def show_student(lst):
if len(lst)==0:
print('没有查询到学生信息,无数据显示!!!')
return
# 定义标题显示格式
format_title='{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
print(format_title.format('ID', '姓名', '英语成绩', 'Python成绩', 'Java成绩', '总成绩'))
# 定义内容的显示格式
format_data='{:^6}\t{:^12}\t{:^8}\t{:^8}\t{:^8}\t{:^8}'
for item in lst:
print(format_data.format(item.get('id'),
item.get('name'),
item.get('english'),
item.get('python'),
item.get('java'),
int(item.get('english'))
+int(item.get('python'))
+int(item.get('java'))
))
def delete():
while True:
student_id = input('请输入要删除的学生的ID:')
if student_id != '':
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as file:
student_old = file.readlines()
else:
student_old = []
flag = False # 标记是否删除
if student_old:
with open(filename, 'w', encoding='utf-8') as wfile:
d = {}
for item in student_old:
d = dict(eval(item)) # 将字符串转成字典
if d['id'] != student_id:
wfile.write(str(d) + '\n')
else:
flag = True
if flag:
print(f'id为{student_id}的学生信息已被删除')
else:
print(f'没有找到ID为{student_id}的学生信息')
else:
print('无学生信息')
break
show() # 删除之后要重新显示所有学生信息
answer = input('是否继续删除?y/n\n')
if answer == 'y':
continue
else:
break
def modify():
show()
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
student_old = rfile.readlines()
else:
return
student_id = input('请输入要修改的学员的ID:')
if student_id != '':
with open(filename, 'w', encoding='utf-8') as wfile:
for item in student_old:
d = dict(eval(item))
if d['id'] == student_id:
print('找到学生信息,可以修改他的相关信息了!')
while True:
try:
d['name'] = input('请输入姓名:')
d['english'] = input('请输入英语成绩:')
d['python'] = input('请输入Python成绩:')
d['java'] = input('请输入Java成绩:')
except:
print('您的输入有误,请重新输入!!!')
else:
break
wfile.write(str(d) + '\n')
print('修改成功!!!')
else:
wfile.write(str(d) + '\n')
answer = input('是否继续修改其它学生信息?y/n\n')
if answer == 'y':
modify()
def sort():
show()
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
student_list = rfile.readlines()
student_new = []
for item in student_list:
d = dict(eval(item))
student_new.append(d)
else:
return
asc_or_desc = input('请选择(0.升序 1.降序):')
if asc_or_desc == '0':
asc_or_desc_bool = False
elif asc_or_desc == '1':
asc_or_desc_bool = True
else:
print('您的输入有误,请重新输入')
sort()
mode = input('请选择排序方式(1.按英语成绩排序 2.按Python成绩排序 3.按Java成绩排序 0.按总成绩排序):')
if mode == '1':
student_new.sort(key = lambda x: int(x['english']), reverse=asc_or_desc_bool)
elif mode == '2':
student_new.sort(key = lambda x: int(x['python']), reverse=asc_or_desc_bool)
elif mode == '3':
student_new.sort(key = lambda x: int(x['java']), reverse=asc_or_desc_bool)
elif mode == '0':
student_new.sort(key = lambda x: int(x['english']) + int(x['python'])
+ int(x['java']), reverse=asc_or_desc_bool)
else:
print('您的输入有误,请重新输入!!!')
sort()
show_student(student_new)
def total():
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
students = rfile.readlines()
if students:
print(f'一共有{len(students)}名学生')
else:
print('还没有录入学生信息')
else:
print('暂未保存数据信息.....')
def show():
student_lst = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
students = rfile.readlines()
for item in students:
student_lst.append(eval(item))
if student_lst:
show_student(student_lst)
else:
print('暂未保存过数据!!!!')
if __name__ == '__main__':
main()
跋文
现在是 2022/1/14/1:09,这篇文章是突然结束的,这篇文章应该还包含NumPy,Panda,数据可视化三大部分内容,但是没有,原因在于 CSDN 的MarkDown编辑器设置了写作上限,当前我正在写NumPy最后一小节内容,把运行图粘到编辑器中发现,图片后面的内容全部消失了,试了很多次,包括重启等都没有解决这个问题,最终猜到可能是编辑器的问题…人麻了,原本跋文我打算写一下我的写作的心路历程,但是现在我只想喷这个编辑器!!!
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)
NumPy
Pandas
Matplotlib数据可视化



















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











