






 本文介绍了如何使用Keras框架结合Word2vec预训练词向量,构建GRU、LSTM和RNN的词性标注模型,并通过Django框架实现模型的Web部署。用户可以在线选择模型进行词性标注和模型训练,实时查看评估结果。
本文介绍了如何使用Keras框架结合Word2vec预训练词向量,构建GRU、LSTM和RNN的词性标注模型,并通过Django框架实现模型的Web部署。用户可以在线选择模型进行词性标注和模型训练,实时查看评估结果。
引言
本文基于Keras框架和维基百科中文预训练词向量Word2vec模型,分别实现由GRU、LSTM、RNN神经网络组成的词性标注模型,并且将模型封装,使用python Django web框架搭建网站,使用户通过网页界面实现词性标注模型的使用与生成。
词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation),是语料库语言学(corpus linguistics)中将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学的词文本。
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)
一、词性标注模型封装代码展示
本文采用python面向对象编程思想,对词性标注模型的构建、训练、预测以及数据的处理分别进行封装,采用python Django Web框架,时模型能够在网页端被创建与使用。
后端代码目录如下图:
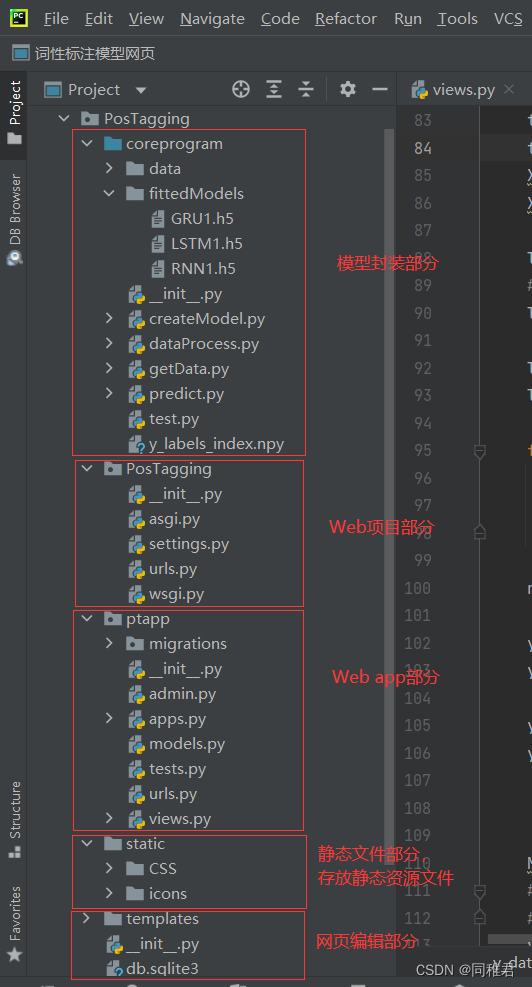
网页效果图如下:

模型代码部分展示:
1.1 data文件夹
data文件夹下存放用于模型训练的原始数据,以及预训练好的维基百科中文词向量模型sgns.wiki.word。
1.2 fittedModels文件夹
fittedModels文件夹下保存的是根据用户在网页端输入的参数而创建的训练好的词性标注模型。用户指定输入的参数如下图。
1.3 getData.py
getData.py 用于读取原始训练数据和测试数据,并接收用户输入的句子,将用户输入的句子使用jieba进行分词,以便用于预测。内部代码如下:
# 获取用于测试以及检测的数据集
def get_dataSet(file_path):
data = pd.read_csv(file_path, sep='\t', skip_blank_lines=False, header=None)
# 取出文本部分
content = data[0]
# 取出标签部分
label = data[1]
return content, label
# 对用户的输入进行分词,输出的格式与get_dataSet() 中的 content 相同
def get_userInputData(userInput):
seg_list = jieba.cut(userInput, cut_all=False)
seg_list = list(seg_list)
for i in range(len(seg_list)):
if seg_list[i] == "。":
seg_list[i] = nan
content = pd.DataFrame(data=seg_list)
content = content[0]
return content1.4 dataProcess.py
dataProcess.py 用于将getData.py得到的数据进行数据变换,变换能够用于训练和预测的数据,即生成X_train_tokenized、X_tset_tokenized、X_data_tokenized(由用户输入的句子转换而来)、y_train_index_paddad、y_test_index_paddad。内部代码如下:
import gensim
from numpy import nan
from tensorflow.keras.preprocessing import sequence
from getData import get_dataSet, get_userInputData
import numpy as np
# 按句对X、y进行拆分
def split_corpus_by_sentence(content):
cleaned_sentence = []
split_label = content.isnull()
last_split_index = 0
index = 0
while index < len(content):
current_word = content[index]
if split_label[index] == True and len(cleaned_sentence) == 0:
cleaned_sentence.append(np.array(content[last_split_index:index]))
last_split_index = index + 1
index += 1
elif split_label[index] == True and len(cleaned_sentence) > 0:
cleaned_sentence.append(np.array(content[last_split_index:index]))
last_split_index = index + 1
index += 1
else:
index += 1
return cleaned_sentence
# --------------------------------------------------------------------------------------------------------
# 序号化 文本,tokenizer句子,并返回每个句子所对应的词语索引
# 由于将词语转化为索引的word_index需要与词向量模型对齐,故在导入词向量模型后再将X进行处理
def tokenizer(texts, word_index):
MAX_SEQUENCE_LENGTH = 100
data = []
for sentence in texts:
new_sentence = []
for word in sentence:
try:
new_sentence.append(word_index[word]) # 把文本中的 词语转化为index
except:
new_sentence.append(0)
data.append(new_sentence)
# 使用kears的内置函数padding对齐句子,好处是输出numpy数组,不用自己转化了
data = sequence.pad_sequences(data, maxlen=MAX_SEQUENCE_LENGTH, padding='post', truncating='post')
return data
def getWord2vec():
myPath = 'coreprogram/data/sgns.wiki.word' # 本地词向量的地址
Word2VecModel = gensim.models.KeyedVectors.load_word2vec_format(myPath) # 读取词向量,以二进制读取
word_index = {" ": 0} # 初始化 `{word : token}` ,后期 tokenize 语料库就是用该词典。
word_vector = {} # 初始化`{word : vector}`字典
embeddings_matrix = np.zeros((len(Word2VecModel.index_to_key) + 1, Word2VecModel.vector_size))
for i in range(len(Word2VecModel.index_to_key)):
word = Word2VecModel.index_to_key[i] # 提取每个词语
word_index[word] = i + 1 # {“词语”:序号, ***} 序号从1开始,
word_vector[word] = Word2VecModel[word] # {"词语":[词向量], ***}
embeddings_matrix[i + 1] = Word2VecModel[word] # 词向量矩阵, 从第1行到最后为各个词的词向量,首行为全0的向量
return word_index, word_vector, embeddings_matrix
def X_dataProcess(X_data):
X_data_sent_split = split_corpus_by_sentence(X_data)
word_index, word_vector, embeddings_matrix = getWord2vec()
X_data_tokenized = tokenizer(X_data_sent_split, word_index)
# print(X_data_tokenized[0])
return X_data_tokenized
# ---------------------------------------------------------------------------------------------------------------
def transfer_label_category_index(origin_labels, labels_types):
transfered_label = []
for sentence_labels in origin_labels:
labels_format_index = [labels_types.index(label) for label in sentence_labels] # 将标签依据字典转化为序号
transfered_label.append(labels_format_index)
return transfered_label
def y_dataProcess():
train_data_url = 'coreprogram/data/ctb5.1-pos/train.tsv'
test_data_url = 'coreprogram/data/ctb5.1-pos/test.tsv'
X_train, y_train = get_dataSet(train_data_url)
X_test, y_test = get_dataSet(test_data_url)
labels = y_train.tolist() + y_test.tolist()
# labels_types = list(set(labels)) # 使用set会导致每次训练的元素排序不同,从而在预测时无法按照索引找到对应的词性
labels_types = [nan, 'AD', 'CC', 'IJ', 'NP', 'ETC', 'DEG', 'VE', 'VV', 'CD', 'VA', 'SB', 'LC', 'NR', 'CS', 'DER', 'PU', 'BA', 'X', 'M', 'OD', 'MSP', 'LB', 'DEC', 'DEV', 'NN', 'P', 'FW', 'DT', 'PN', 'VC', 'SP', 'VP', 'NT', 'AS', 'JJ']
labels_dict = {}
labels_index = {"padded_label": 0}
for index in range(len(labels_types)):
label = labels_types[index]
labels_dict.update({label: labels.count(label)})
labels_index.update({label: index + 1})
np.save('y_labels_index.npy', labels_index)
y_train_sent_split = split_corpus_by_sentence(y_train)
y_test_sent_split = split_corpus_by_sentence(y_test)
y_train_index = transfer_label_category_index(y_train_sent_split, labels_types)
y_test_index = transfer_label_category_index(y_test_sent_split, labels_types)
MAX_SEQUENCE_LENGTH = 100
# 标签格式转化
# 构建对应(标签样本数,句子长度,标签类别数)形状的张量,值全为0
y_train_index_padded = np.zeros((len(y_train_index), MAX_SEQUENCE_LENGTH, len(labels_types) + 1), dtype='float',
order='C')
y_test_index_padded = np.zeros((len(y_test_index), MAX_SEQUENCE_LENGTH, len(labels_types) + 1), dtype='float',
order='C')
# 填充张量
for sentence_labels_index in range(len(y_train_index)):
for label_index in range(len(y_train_index[sentence_labels_index])):
if label_index < MAX_SEQUENCE_LENGTH:
y_train_index_padded[
sentence_labels_index, label_index, y_train_index[sentence_labels_index][label_index] + 1] = 1
if len(y_train_index[sentence_labels_index]) < MAX_SEQUENCE_LENGTH:
for label_index in range(len(y_train_index[sentence_labels_index]), MAX_SEQUENCE_LENGTH):
y_train_index_padded[sentence_labels_index, label_index, 0] = 1
# 优化:若为填充的标签,则将其预测为第一位为1
for sentence_labels_index in range(len(y_test_index)):
for label_index in range(len(y_test_index[sentence_labels_index])):
if label_index < MAX_SEQUENCE_LENGTH:
y_test_index_padded[
sentence_labels_index, label_index, y_test_index[sentence_labels_index][label_index] + 1] = 1
if len(y_test_index[sentence_labels_index]) < MAX_SEQUENCE_LENGTH:
for label_index in range(len(y_test_index[sentence_labels_index]), MAX_SEQUENCE_LENGTH):
y_test_index_padded[sentence_labels_index, label_index, 0] = 1
return y_train_index_padded, y_test_index_padded, labels_types
1.5 createModel.py
createModel.py用于模型的创建于训练,模型创建与训练所需要的参数如模型类型、模型保存名、迭代轮数、学习率、学习率衰减等均可由用户自定义。模型训练会返回在训练集以及测试集的评估结果(交叉熵损失值、准确率),并最终显示在网页上。createModel.py内部代码如下:
此处代码不完整,完整代码请在文末连接处获取
# 此处代码不完整,完整代码请在文末连接处获取
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Embedding, Dense, Dropout, GRU, LSTM, SimpleRNN
import keras
from keras import optimizers
from dataProcess import getWord2vec, y_dataProcess, X_dataProcess
from getData import get_dataSet
EMBEDDING_DIM = 300 #词向量维度
MAX_SEQUENCE_LENGTH = 100
def createModel(modelType, saveName,epochs=10, batch_size=128,lr=0.01, decay=1e-6):
train_data_url = 'coreprogram/data/ctb5.1-pos/train.tsv'
test_data_url = 'coreprogram/data/ctb5.1-pos/test.tsv'
X_train, y_train = get_dataSet(train_data_url)
X_test, y_test = get_dataSet(test_data_url)
X_train_tokenized = X_dataProcess(X_train)
X_test_tokenized = X_dataProcess(X_test)
y_train_index_padded, y_test_index_padded, labels_types = y_dataProcess()
word_index, word_vector, embeddings_matrix = getWord2vec()
model = Sequential()
if modelType=="LSTM":
model.add(LSTM(128, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM), activation='tanh', return_sequences=True))
elif modelType=="RNN":
model.add(SimpleRNN(128, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM), activation='tanh', return_sequences=True))
elif modelType=="GRU":
model.add(GRU(128, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM), activation='tanh', return_sequences=True))
print(testScore)
model.save("coreprogram/fittedModels/"+ saveName +".h5")
return trainScore, testScore二、前后端数据传输代码部分展示
控制前后端数据交互的关键代码在views.py中,前端通过Ajax发送GET请求向后端申请模型数据、词性标注结果、模型训练好后的评估数据等。views.py中的代码如下:
from django.shortcuts import render
# Create your views here.
import json
import os
from django.http import HttpResponse
from django.shortcuts import render
import predict
import createModel
def Home(request):
global result
if request.method == 'GET':
name = request.GET.get('name')
if name == 'getModelsName':
filesList = None
for root, dirs, files in os.walk("coreprogram/fittedModels"):
filesList = files
result = {
"modelsNameList": filesList
}
if name == 'predict':
chosenModelName = request.GET.get('chosenModelName')
inputSentence = request.GET.get('inputSentence')
modelUrl = "coreprogram/fittedModels/" + chosenModelName
posTaggingresult = predict.finalPredict(modelUrl, inputSentence)
print(posTaggingresult)
result = {
"posTaggingresult": posTaggingresult
}
if name == "fit":
modetype = request.GET.get('modetype')
saveName = request.GET.get('saveName')
epochs = request.GET.get('epochs')
batch_size = request.GET.get('batch_size')
lr = request.GET.get('lr')
decay = request.GET.get('decay')
trainScore, testScore = createModel.createModel(modetype, saveName, epochs=int(epochs), batch_size=int(batch_size), lr=float(lr), decay=float(decay))
trainScore = [round(i,3) for i in trainScore]
testScore = [round(i,3) for i in testScore]
result = {
"trainScore": trainScore,
"testScore":testScore,
}
return render(request, "ptapp/HomePage.html")三、前端网页编辑代码部分展示
static文件夹中保存网页中需要用到图标、css页面渲染文件等,templates中保存编写的网页html文件。HomePage.html中的代码如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>词性标注</title>
<link rel="stylesheet" type="text/css" href="../../static/CSS/HomePageCss.css">
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
</head>
<body>
<div class="background"></div>
<div class="part1">
<div class="title">模型选择</div>
<div id="refresh">加载模型<img src="../../static/icons/刷新.png"></img></div>
<div class="modelsList">
<ul id="modelsList_ul"></ul>
</div>
</div>
<div class="part2">
<div class="title">词性标注</div>
<div class="input">
<div>提示:<br/>输入的句子以中文句号隔开,句子长度需小于100词!</div>
<textarea name="inputSentenceTextarea" id="inputSentence" cols="30" rows="10"></textarea>
</div>
<div class="predict">
<div id="predictButton">PREDICT</div>
</div>
<div id="output" class="output"></div>
</div>
<div class="part3">
<div class="title">模型训练</div>
<div class="empty"></div>
<div class="paramenter">模型类型
<input type="text" id="modetype">
</div>
<div class="paramenter">模型命名
<input type="text" id="saveName">
</div>
<div class="paramenter">迭代轮数
<input type="text" id="epochs">
</div>
<div class="paramenter">小批量样本数
<input type="text" id="batch_size">
</div>
<div class="paramenter">学习率
<input type="text" id="lr">
</div>
<div class="paramenter">学习率衰减
<input type="text" id="decay">
</div>
<div class="fit">
<div id="fitbutton">FIT</div>
</div>
<div class="fitresult">
<div class="score">trainScore:<div id="trainScoreResult"></div></div>
<div class="score">testScore:<div id="testScoreResult"></div></div>
</div>
</div>
</body>
<script>
/* 初始化选择的模型的名称 */
var chosenModelName=""
document.getElementById("refresh").onclick = function() {
var data = {'name': 'getModelsName'}
$.ajax({
url: 'ptapp/Home',
type: "GET",
data: data,
success: function (arg) {
var modelsNameList = arg["modelsNameList"]
var ulInnerHtml =""
for(var i=0; i<modelsNameList.length; i++){
ulInnerHtml =ulInnerHtml + "<li class='li_unselected'>" + modelsNameList[i] + "</li>"
}
document.getElementById("modelsList_ul").innerHTML = ulInnerHtml
var modelliList = document.getElementById("modelsList_ul").getElementsByTagName("li")
var modelliList = document.getElementById("modelsList_ul").getElementsByTagName("li")
console.log("modelliList.length",modelliList.length)
for(var i = 0; i < modelliList.length; i++){
modelliList[i].onclick = function(){
var modelName = this.innerText
chosenModelName = modelName
console.log(chosenModelName)
var className = this.className
for(var j = 0; j < modelliList.length; j++){
modelliList[j].className = "li_unselected"
}
this.className = "li_selected"
}
}
}
})
}
document.getElementById("predictButton").onclick = function(){
var inputSentence = document.getElementById("inputSentence").value
if(inputSentence){
if(chosenModelName){
var data = {'name': 'predict', "chosenModelName": chosenModelName, "inputSentence": inputSentence}
$.ajax({
url: 'ptapp/Home',
type: "GET",
data: data,
success: function (arg){
var posTaggingresult = arg["posTaggingresult"]
document.getElementById("output").innerHTML = posTaggingresult
}
})
}else{
alert("请选择训练好的模型!")
}
}else{
alert("请输入句子!")
}
}
document.getElementById("fitbutton").onclick = function(){
var modetype = document.getElementById("modetype").value
var saveName = document.getElementById("saveName").value
var epochs = document.getElementById("epochs").value
var batch_size = document.getElementById("batch_size").value
var lr = document.getElementById("lr").value
var decay = document.getElementById("decay").value
if(modetype&&saveName&&epochs&&batch_size&&lr&&decay){
var data = {'name': 'fit', "modetype": modetype, "saveName": saveName, "epochs": epochs,"batch_size":batch_size, "lr":lr, "decay":decay}
$.ajax({
url: 'ptapp/Home',
type: "GET",
data: data,
success: function (arg){
var trainScore = arg["trainScore"]
var testScore = arg["testScore"]
document.getElementById("trainScoreResult").innerText=trainScore
document.getElementById("testScoreResult").innerText=testScore
}
})
}else{
alert("请输入完成训练参数!")
}
}
</script>
</html>四、使用模型界面以及使用结果
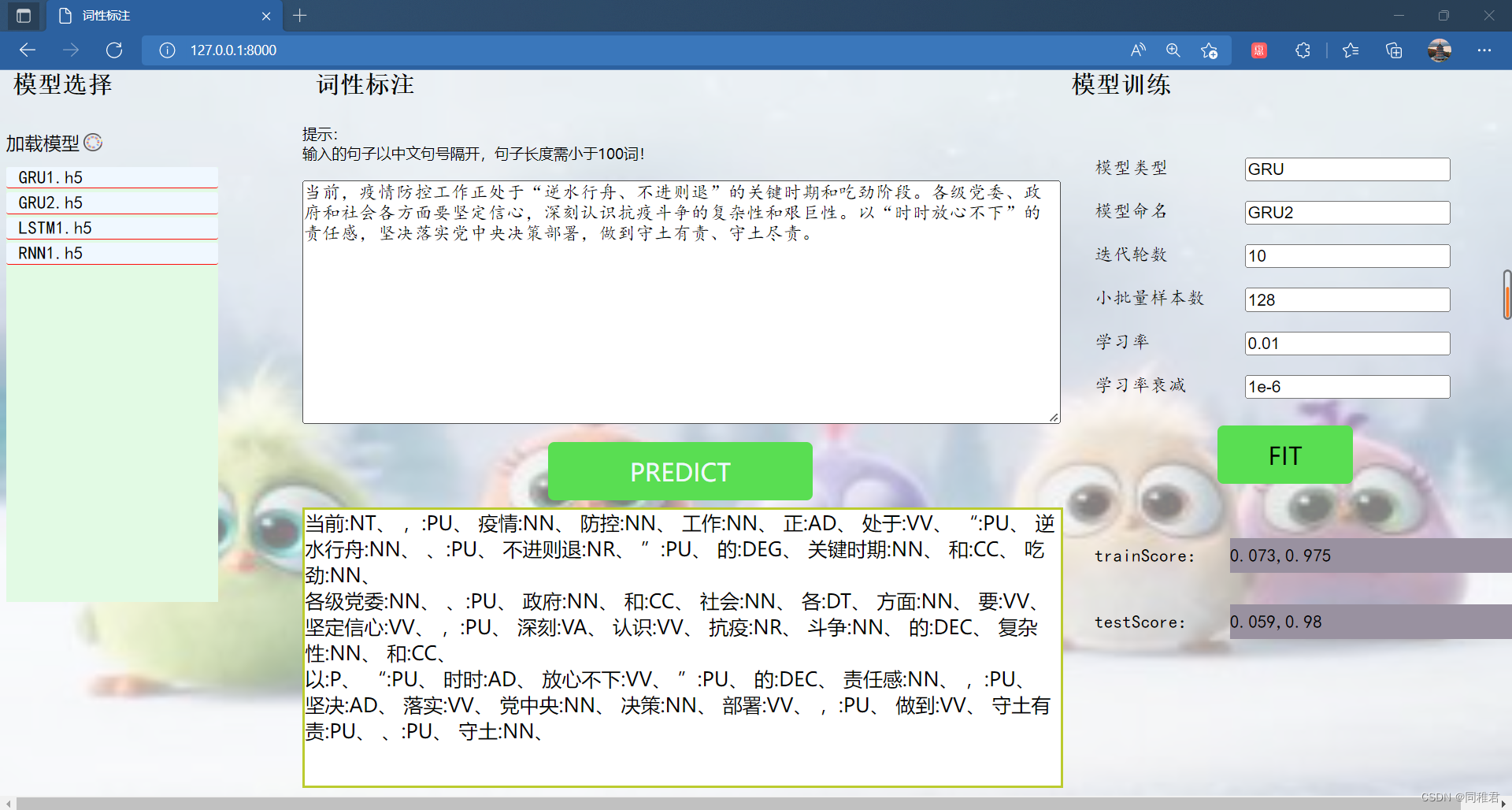
4.1 词性标注部分展示
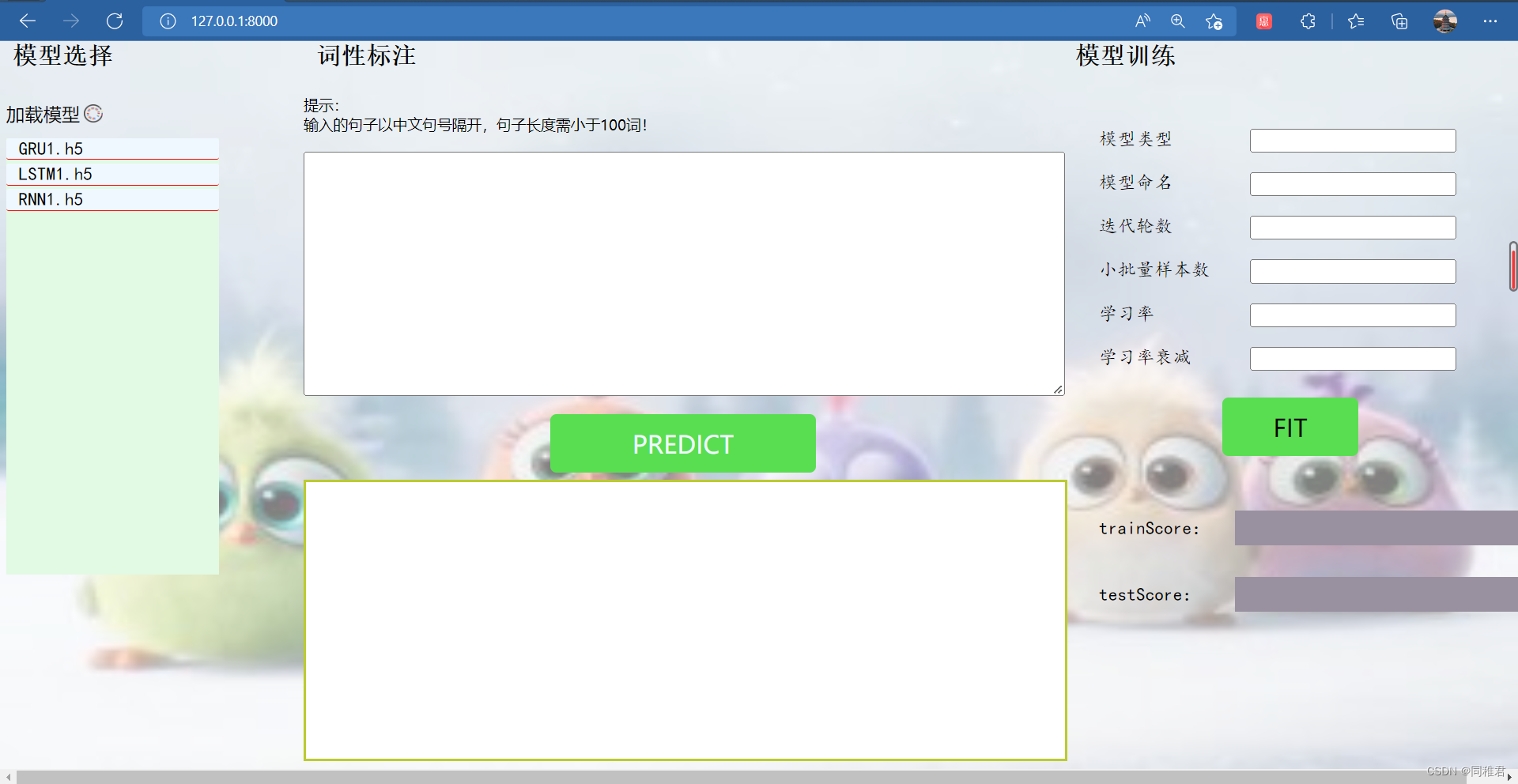
在“模型选择”区域需要先点击“加载模型”按钮,将fittedModels文件中保存的训练好的模型展示出来,以供选择用于词性标注的模型。
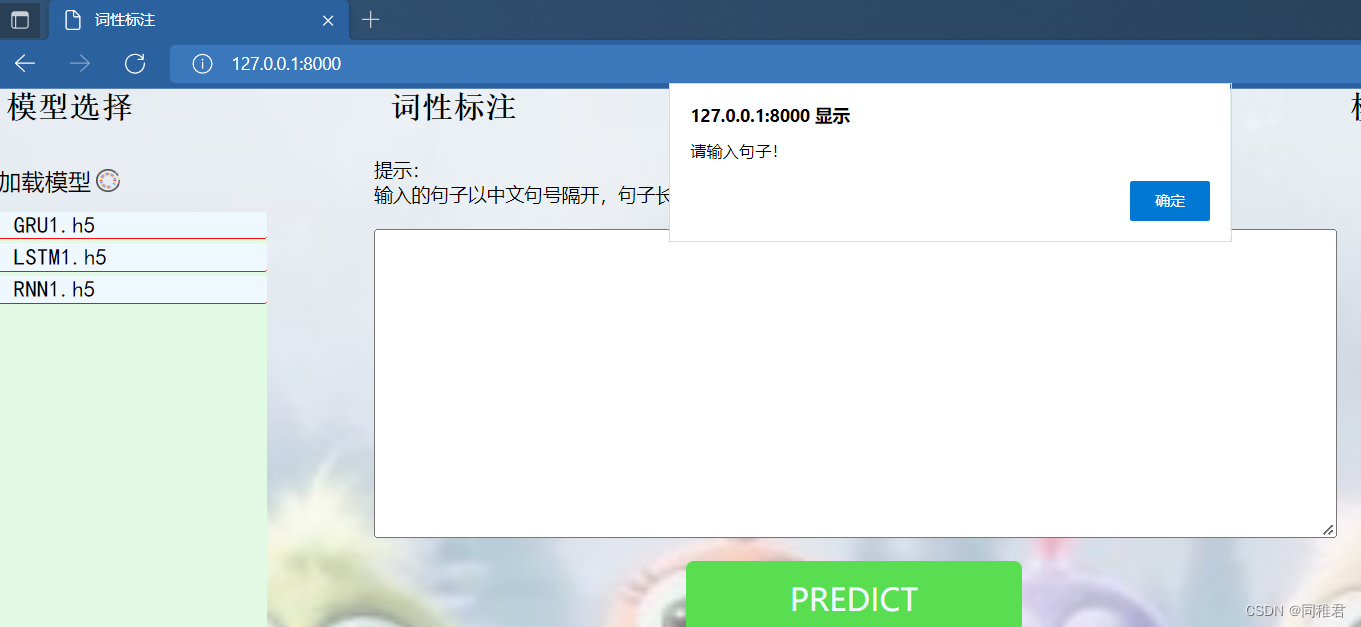
在中间“词性标注”区域的输入文本框中,输入需要词性标注的句子,在选择好模型后,点击“PREDICT”按钮,即可将输入句子以及模型名称传给后端,后端封装好的词性标注模型部分程序会调用用户指定的模型来对用户输入的句子进行词性标注,并将标注结果传给前端,最终显示在“PREDICT”按钮下面的空白区域内。若用户为输入句子或未选中模型,当用户点击“PREDICT”按钮时就会弹出对应提示。
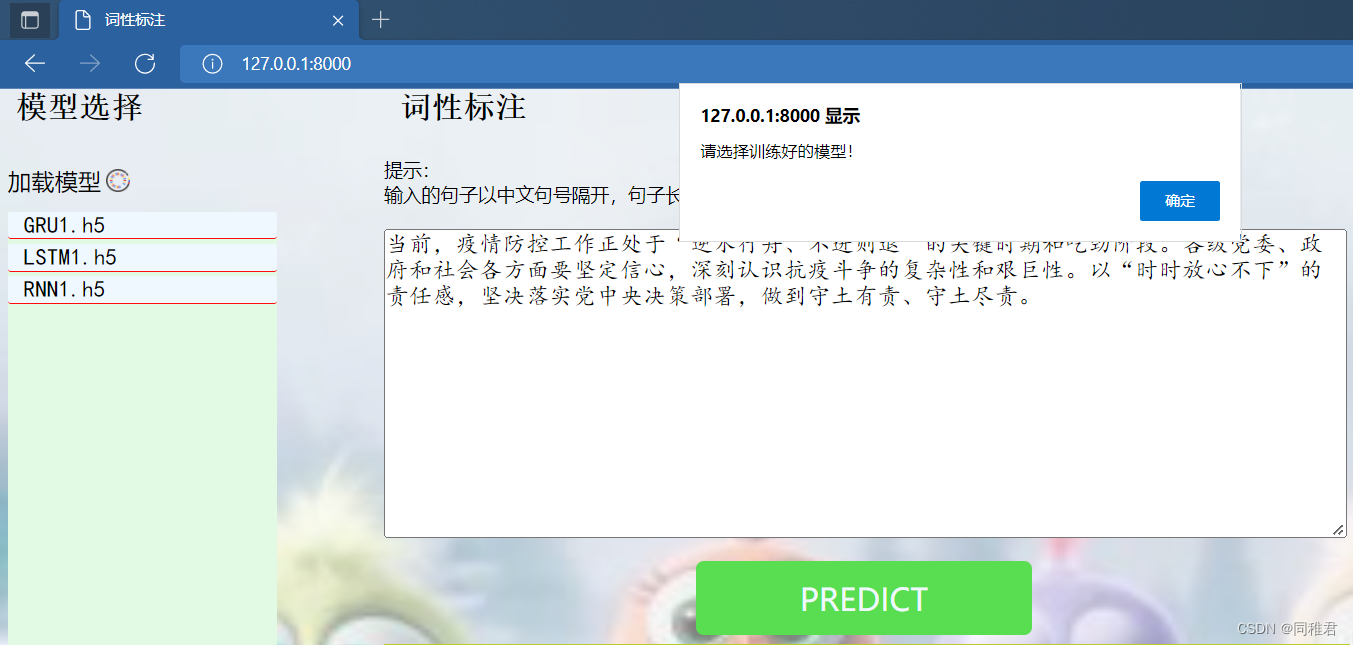
选择GRU1模型以及输入完要标注的句子后,点击“PREDICT”按钮,标注结果如下:
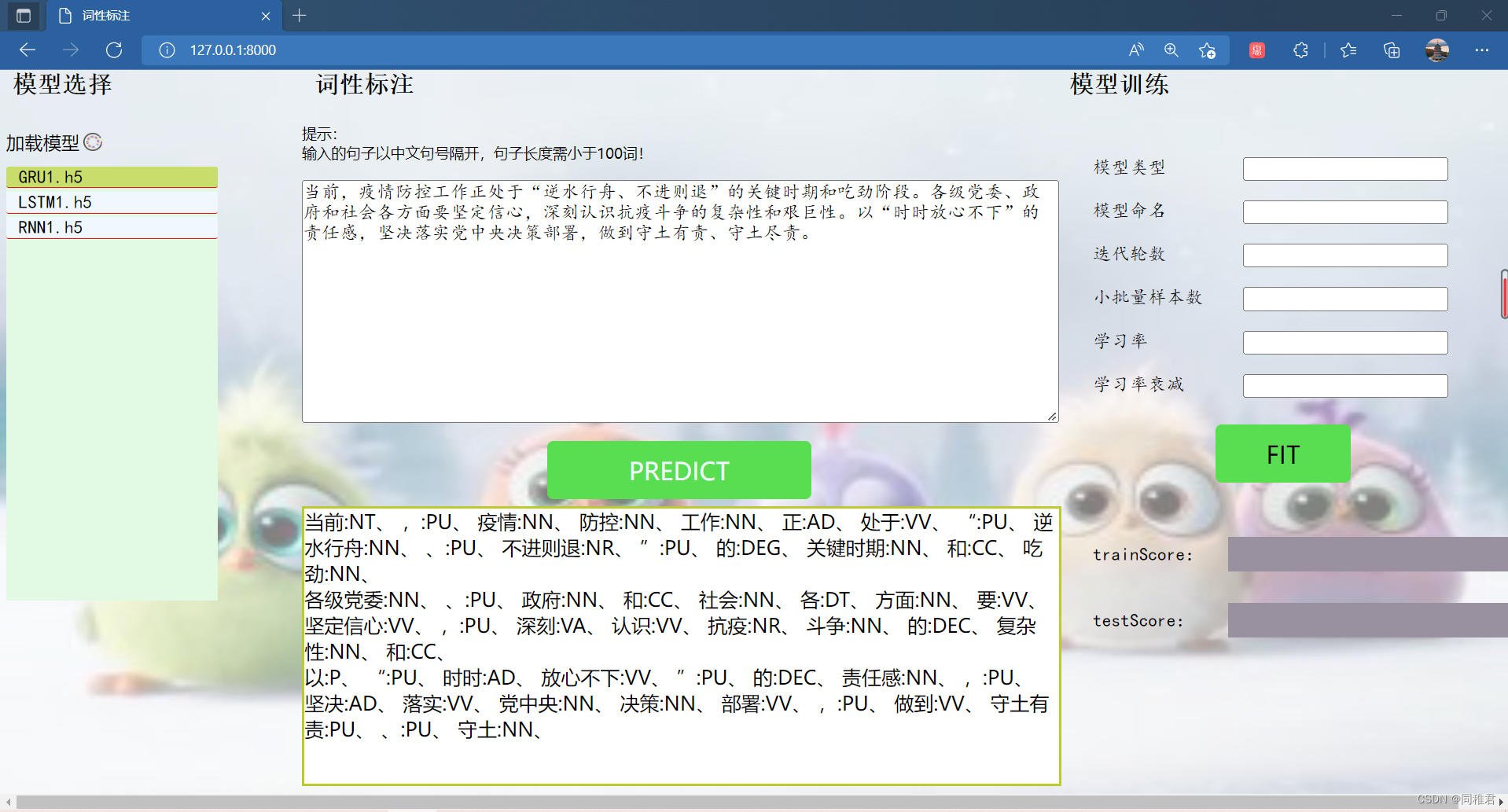
后端运行过程如下:
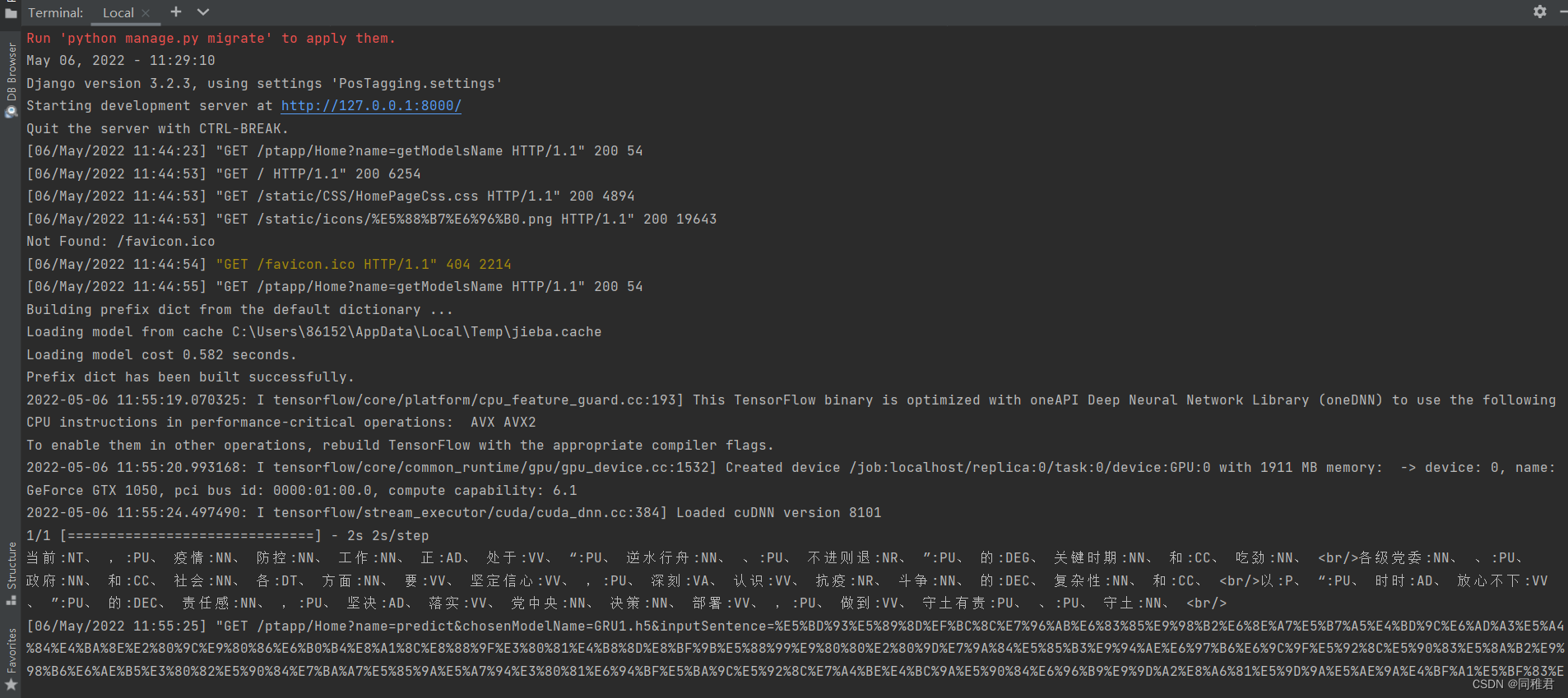
4.2 模型训练部分展示
当前已有训练好的LSTM1.h5、GRU1.h5、RNN1.h5模型,再训练GRU2.h5模型的过程如下:
在“模型训练”部分的文本框中对应地输入各个参数,然后点击“FIT”按钮,即可开始训练。

训练完成后,点击“加载模型”,即可将新训练的模型显示出来。
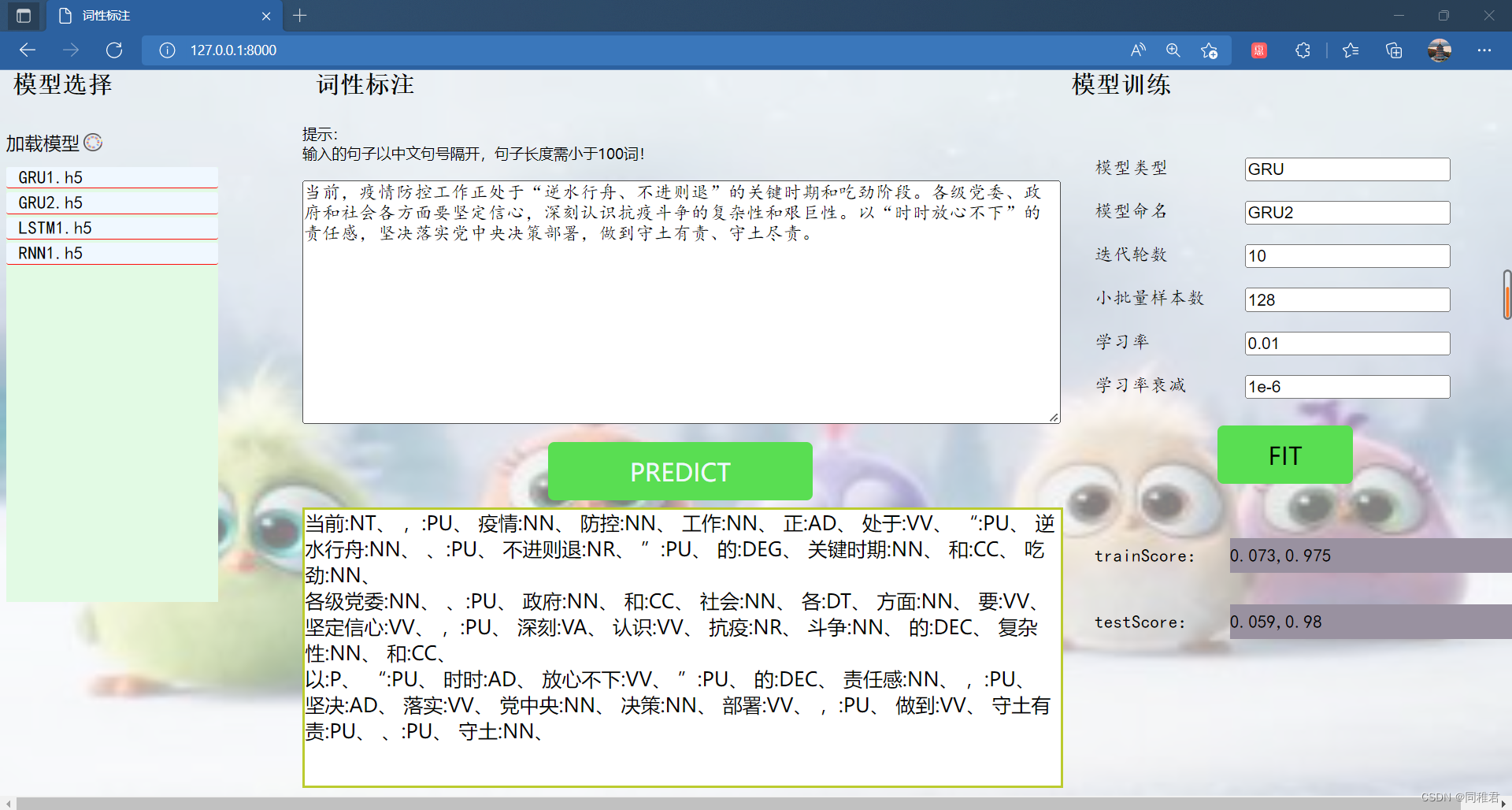
后端运行过程如下:
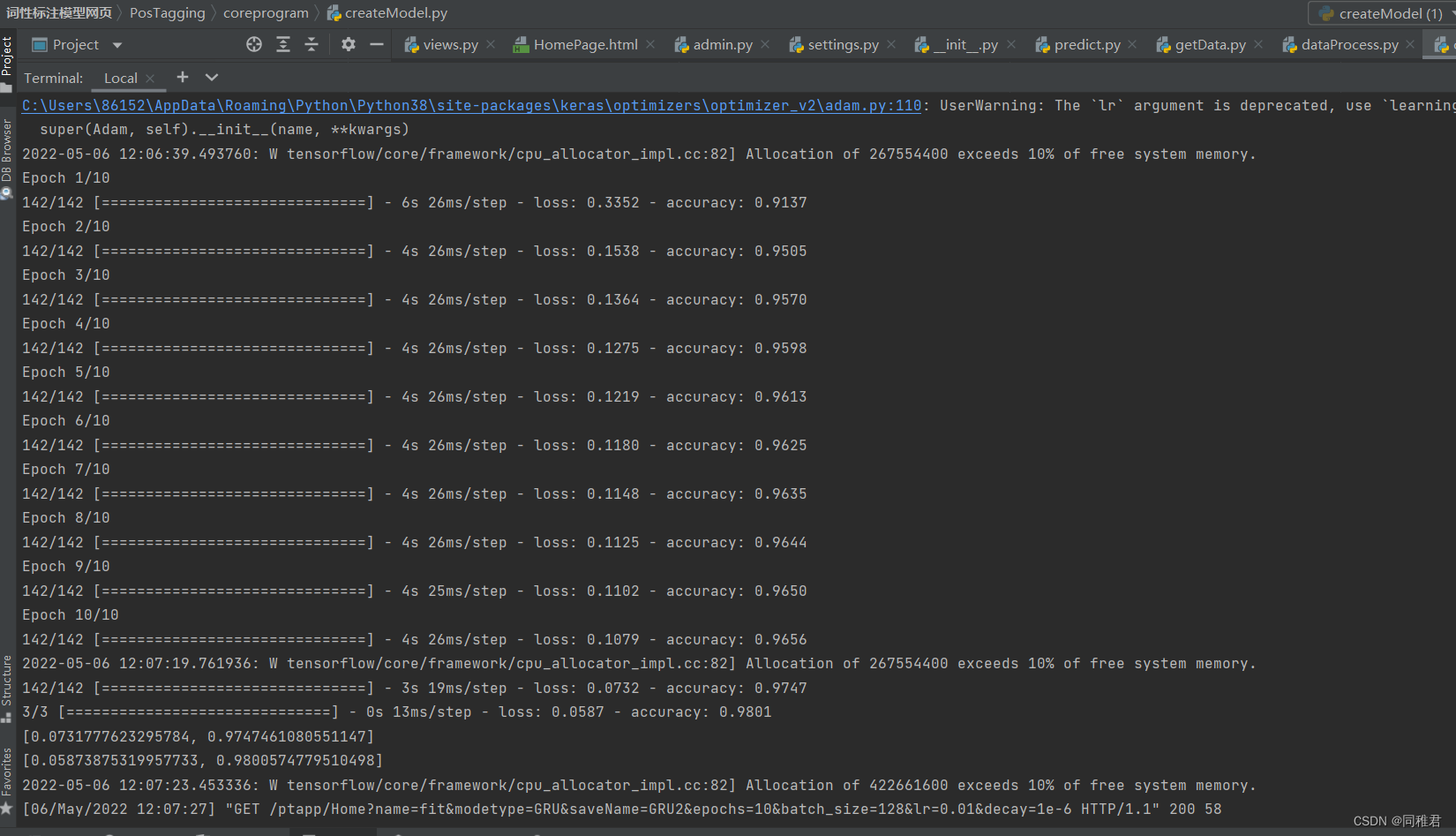
五、项目完整实现资源
链接:https://pan.baidu.com/s/1t5DU_T5nCIsiNpvZevcXXg?pwd=7ke7
提取码:7ke7
注意:需要在 “词性标注模型网站项目\PosTagging\coreprogram\data”中将sgns.wiki.word.bz2解压。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











