






 本文介绍如何使用Selenium爬取网易云音乐用户的详细信息,包括用户ID、昵称、性别等,并提供了完整的Python代码示例。
本文介绍如何使用Selenium爬取网易云音乐用户的详细信息,包括用户ID、昵称、性别等,并提供了完整的Python代码示例。
目录
1.前言:
注意:以下统一用“U”代指“U s e r或U s e r s”。(原因大家都懂)
离年初写的《Python Scrapy 多线程爬取WYY音乐热门歌单信息(手把手教学)》这篇文章已经快将近一年了,文章也受到了大量小伙伴们的点赞和收藏,在文末也提到了将会续写一篇教小伙伴们使用Selenium爬虫来爬取WYY音乐U页面详细信息的文章,其实当时代码是早就已经写好了的,也爬到了原始数据(超过4w条U信息),但是一直犹豫要不要写这篇文章,毕竟这个涉及U的一些信息。最终还是决定写这篇文章,目的是方便大家能够利用数据用于学术研究,而不是商用或交易。
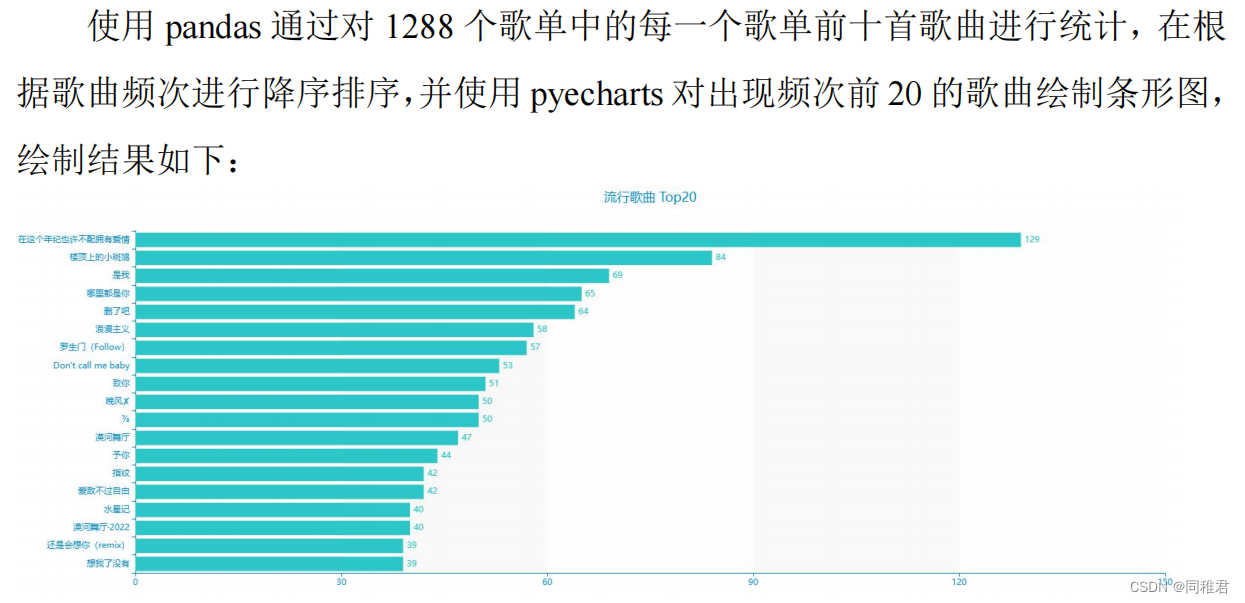
笔者之所以要获取WYY音乐的热门歌单信息和U信息,是为了完成数据挖掘与分析课程论文作业(《移动音乐平台U音乐品味数据分析——以WYY音乐平台为例》),以下是笔者利用获取到的U数据与热门歌单数据绘制的一些可视化图表:
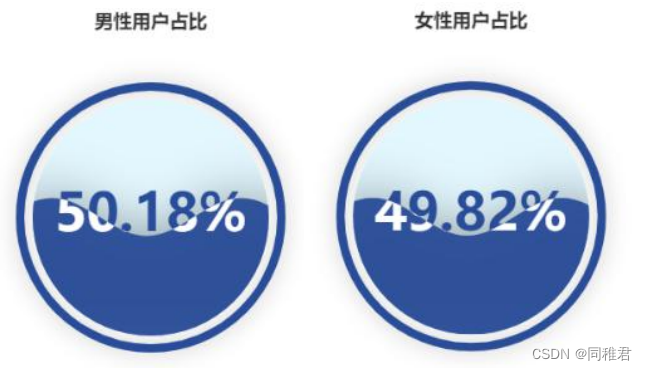
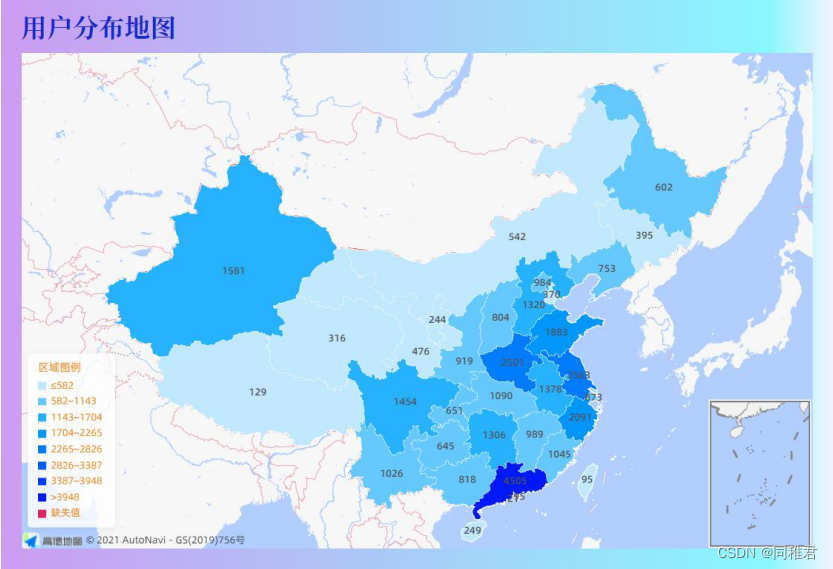
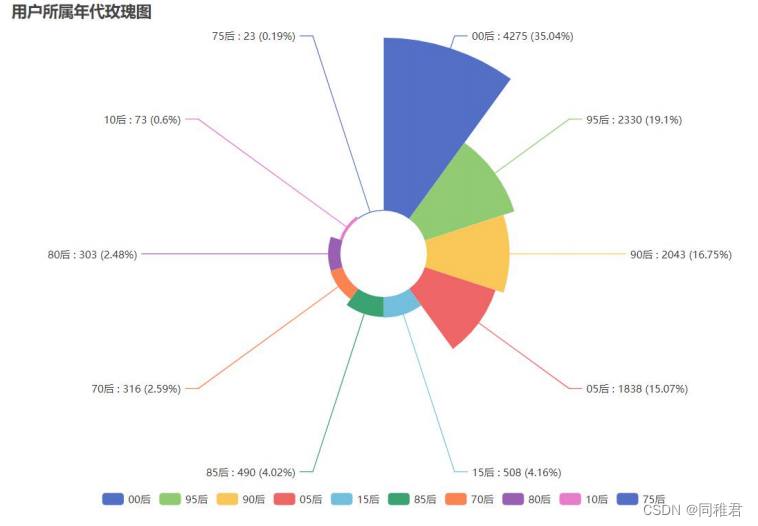
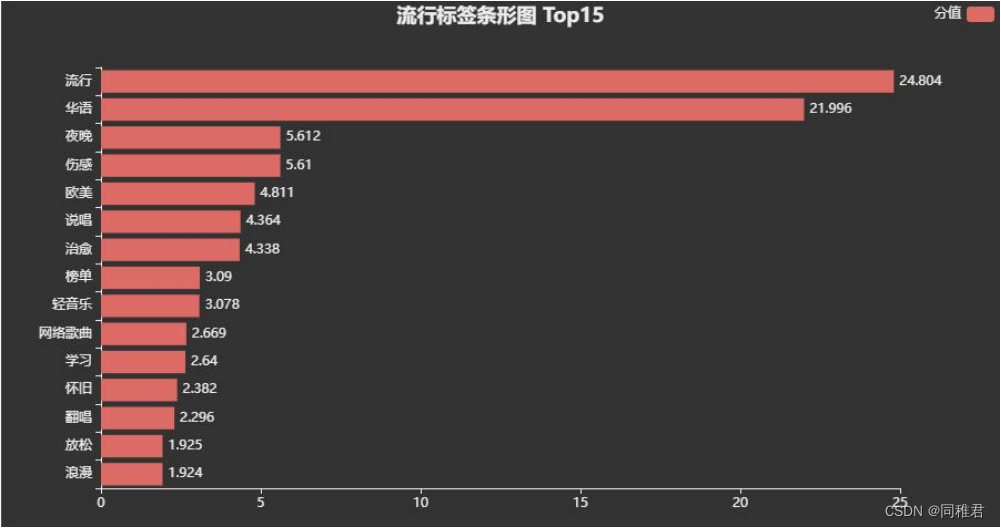
2.熟悉U主页页面结构
2.1 关于URL:
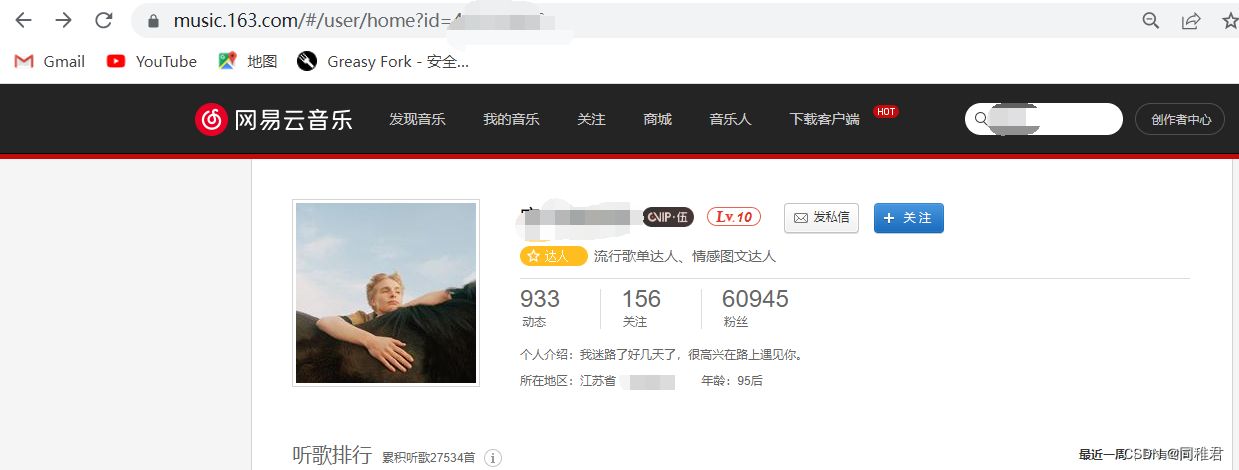
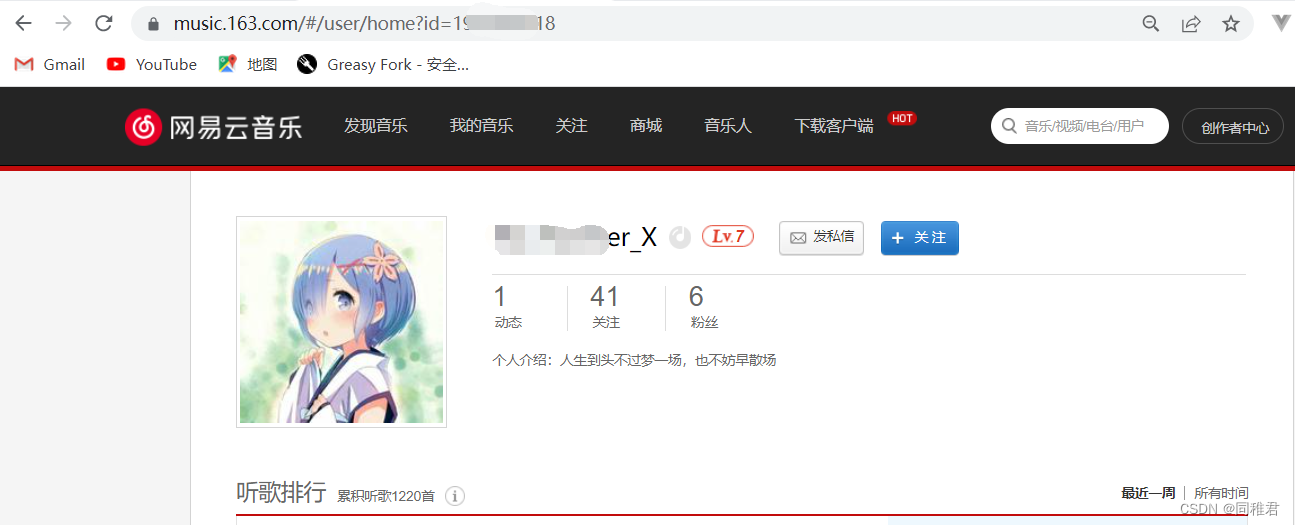
从以上两个U的界面的url中我们可以发现规律,U详情界面的URL是 'https://music.163.com/user/home?id=' + 'U id' 的结构,所以只要得到U的id,就可以访问到该U的详情页面。
2.2关于页面布局:
一个U详情页的结构可以拆成三部分:
①U常规信息部分,这部分包括的信息有:U昵称、VIP等级、达人标签、发布的动态数量、该U关注的其他U数量、该U的粉丝数量、U的个人介绍、U所在地(可以具体到地级市)、U年龄。当然,不是所有的U主页都具有以上信息,可能有的U没有显示地址、年龄等信息,所以在写爬虫代码时需要考虑到这一点,使用try except来解决由于部分信息不存在而导致的报错问题。
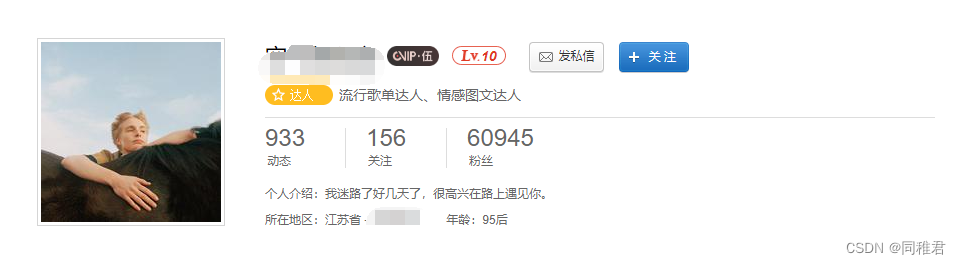
②该U的听歌频率列表
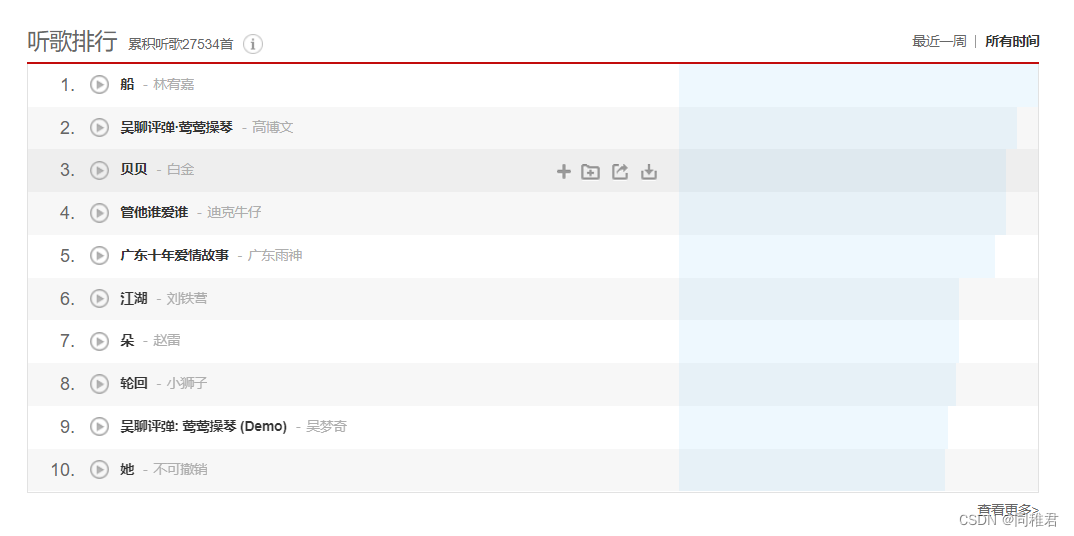
这个表可以用于分析不同性别、年龄、地域的U的听歌习惯。
③U创建的歌单信息

以上可以得到该U创建的歌单数量、歌单名称、以及每个歌单的播放量,如果继续挖掘,还可以根据歌单的地址,到某一歌单的详细页面,就可以获取到歌单内的歌曲名称、歌单收藏量、歌单的评论等信息。
3.获取大量U账号思路
根据2.1的分析,可以得出只要知道U id 号,就可以访问到对应U的主页,这里的第一个难点是采用何种方法来获取大量U的 id 号的,然后根据 id 号来获取U信息。
WYY音乐U的 id 号有 8 位的,也有 10 位的,由于最初没有积累一定量的U id,所以无法分析出WYY音乐U id 号的生成规律。因此最初时我的想法是从1000000000 到 9999999999 一个一个地试过去,若能访问到页面,则说明 id 是有效,但是很快就暴露出了这种方法的弊端,在爬了1000 次后,也就是 id =1000001000 时,依旧没有获取到一个有效的U id 号,这种方法效率过于低下,而且有着被封 IP 的风险。于是我又换了一个思路,即通过产生 10 位的随机数来尝试产生有效的 id,但是这种方法也不可靠,因为无法用于产生大量的U id,可能运气好会产生几百个,但是这远远不够,若要产生上万个 id 号,则要尝试数十倍甚至更多的随机数。
最终我在浏览WYY音乐页面尝试寻找突破口时发现了可以通过一个U的粉丝页面来获取其粉丝的 id 号(即U id),这样就可以通过U的粉丝来获取U id,只要获取到一个具有较大量粉丝的U的 id,就可以根据其粉丝获取U id,再根据粉丝的粉丝,就可以源源不断地获取到U的 id 号。使用上述方法,笔者总共获取到了 6 w多个U id 号。
之后便是获取U的详细信息,于这部分只能用 Selenium 爬虫来爬取(受到反扒机制影响,使用scrapy爬U详情页面得到的都是空数据,这也是为什么这里用selenium而不用Scrapy的原因),爬取一条U信息平均需要两秒,若一直按这个速度爬取,爬完 6 w份U信息则需要 33.33 小时。在实际爬取过程中,还需要考虑出现意外情况,如U账号已注销、服务器禁止访问、计算机卡顿等情况,所以实际爬虫用时可能会远远大于这个数字(由于时间限制,最终获取到了 4 w多条U数据)。

4.编写代码爬数据
在此,笔者不会向任何人提供已经获取到的U id表和U详细信息表。对于U id的获取,大家可以根据我在上文提到的获取大量用户id号的思路,使用scrapy或者selenium去爬取,若是不熟悉scrapy的使用,可以借鉴笔者的上一篇文章,selenium的使用方法将在下文以获取U详细页面的信息为例来展示。
各字段含义如下:
import csv
import time
import random
import pandas as pd
from selenium import webdriver
chrome_driver = "Chrome\Application\chromedriver.exe" # 搜索引擎本地地址
options = webdriver.ChromeOptions()
options.add_argument('--headless') #设置为无Gui界面,这样就不用每爬一个用户就重新打开一次浏览器
'''
函数说明:
作用:获取指定用户的指定详细信息
参数:
UserID:string格式的用户id
返回:
UserInfo_list:包含某一用户各个信息字段值的列表
'''
def GetUersInfo(UserID):
UserInfo_list = []
url = 'https://music.163.com/user/home?id=' + UserID
browser = webdriver.Chrome(executable_path=chrome_driver, chrome_options=options)
browser.set_window_size(1, 10)
try:
browser.get(url)
browser.switch_to.frame("g_iframe")
h2 = browser.find_element_by_id("j-name-wrap")
except:
return UserInfo_list
spans = h2.find_elements_by_tag_name("span")
#获取昵称
NickName = spans[0].get_attribute('innerText')
#获取Vip等级
VipLevel = spans[1].get_attribute('class')
if VipLevel != "":
VipLevel = " ".join(VipLevel.split())
else:
VipLevel="NS"
#获取账号等级
AccountLevel = spans[2].get_attribute('innerText')
#获取性别 1:男性 2:女性 0:未知
Sex = h2.find_elements_by_tag_name("i")[1].get_attribute('class')[-1:]
head_box_dl = browser.find_element_by_id("head-box")
tab_box_ul = head_box_dl.find_element_by_id("tab-box")
li_list = tab_box_ul.find_elements_by_tag_name("li")
#获取动态数
EventCount = li_list[0].find_element_by_id("event_count").get_attribute('innerText')
#获取关注数
FollowCount = li_list[1].find_element_by_id("follow_count").get_attribute('innerText')
#获取粉丝数
Fans = li_list[2].find_element_by_id("fan_count").get_attribute('innerText')
#获取所在地区
District=""
try:
District = head_box_dl.find_element_by_xpath("//span[contains(text(),'所在地区')]").get_attribute('innerText')
District = District[5:]
District = " ".join(District.split())
District = "-".join(District.split(" - "))
except:
District = "NS"
#获取年龄
Age = []
try:
age_span = head_box_dl.find_element_by_id("age")
data_age = time.localtime(int(age_span.get_attribute('data-age')[0:-3]))
# data_age = time.strftime("%Y-%m-%d %H:%M:%S", data_age)
data_age = time.strftime("%Y-%m-%d", data_age)
Age.append(data_age)
era = age_span.find_element_by_tag_name("span").get_attribute('innerText')
Age.append(era)
except:
Age.append("NS")
#获取社交网络
SocialNetworks = []
try:
span = head_box_dl.find_element_by_xpath("//span[contains(text(),'社交网络:')]")
ul = head_box_dl.find_element_by_xpath("//ul[@class = 'u-logo u-logo-s f-cb']")
lis = ul.find_elements_by_tag_name("li")
for li in lis:
SocialNetwork_name = li.find_element_by_tag_name("a").get_attribute('title')
SocialNetworks.append(SocialNetwork_name)
except:
SocialNetworks.append("NS")
#获取累计听歌数
Frequency = ""
try:
rHeader = browser.find_element_by_id("rHeader")
h4_text = rHeader.find_element_by_xpath("//h4[contains(text(),'累积听歌')]").get_attribute('innerText')[4:-1]
Frequency = h4_text
except:
Frequency = "NS"
#获取创建歌单数
Creation = ""
try:
cHeader = browser.find_element_by_id("cHeader")
Creation = cHeader.find_element_by_xpath("//span[contains(text(),'创建的歌单')]").get_attribute('innerText')
Creation = "".join(Creation.split())
Creation = Creation.split("歌单(")[1][0:-1]
except:
Creation = "NS"
#获取收藏的歌单数
Collection = ""
try:
sHeader = browser.find_element_by_id("sHeader")
Collection = sHeader.find_element_by_xpath("//span[contains(text(),'收藏的歌单')]").get_attribute('innerText')
Collection = "".join(Collection.split())
Collection = Collection.split("歌单(")[1][0:-1]
except:
Collection = "NS"
UserInfo_list.append(NickName)
UserInfo_list.append(Sex)
UserInfo_list.append(Age)
UserInfo_list.append(VipLevel)
UserInfo_list.append(AccountLevel)
UserInfo_list.append(District)
UserInfo_list.append(EventCount)
UserInfo_list.append(FollowCount)
UserInfo_list.append(Fans)
UserInfo_list.append(SocialNetworks)
UserInfo_list.append(Frequency)
UserInfo_list.append(Creation)
UserInfo_list.append(Collection)
time.sleep(0.01)
browser.close() #爬完一个用户就要关掉当前浏览器
return UserInfo_list
'''
用来执行爬取所有用户的详细信息
'''
def start():
UserIDList = list(pd.read_csv("File/UsersID.csv", encoding="utf8")["UserID"]) #这里csv地址填写大家自己爬取到用户id CSV文件地址。
f = open("File/UsersInfo.csv", 'w', newline='', encoding='utf-8') # 新打开一个文件用来写入爬取到的用户信息
writer = csv.writer(f)
i = 0 # 用于控制从UsersID.csv文件中的第i个用户开始爬起,这样避免中途出意外后又得从头开始爬起
for userID in UserIDList[i:]:
print(i,end="")
row = [userID]
UserInfo = GetUersInfo(str(userID))
if len(UserInfo) != 0:
row = row + UserInfo
writer.writerow(row)
else:
print("?",userID,end="")
print(".", end=" ")
if i%1000 == 0:
time.sleep(random.uniform(2,3)) #每爬取1000个用户,则随机暂停2-3秒
i+=1
start()
Selenium的原理就是模仿人操作浏览器一样来获取页面的信息,因此只要控制好每次请求的时间间隔,就很难被反扒机制发现。使用Selenium准确获取页面指定位置的信息的关键在于掌握selenium对HTML文档的解析语法。若学过前端三语言,则会对解析语法的理解更加快速,大家也可以根据以上代码中对昵称、性别等信息的获取来逐步了解解析语法,注意这要边在浏览器中打开某一U的详情页面的HTML结构,边看以上Python代码。
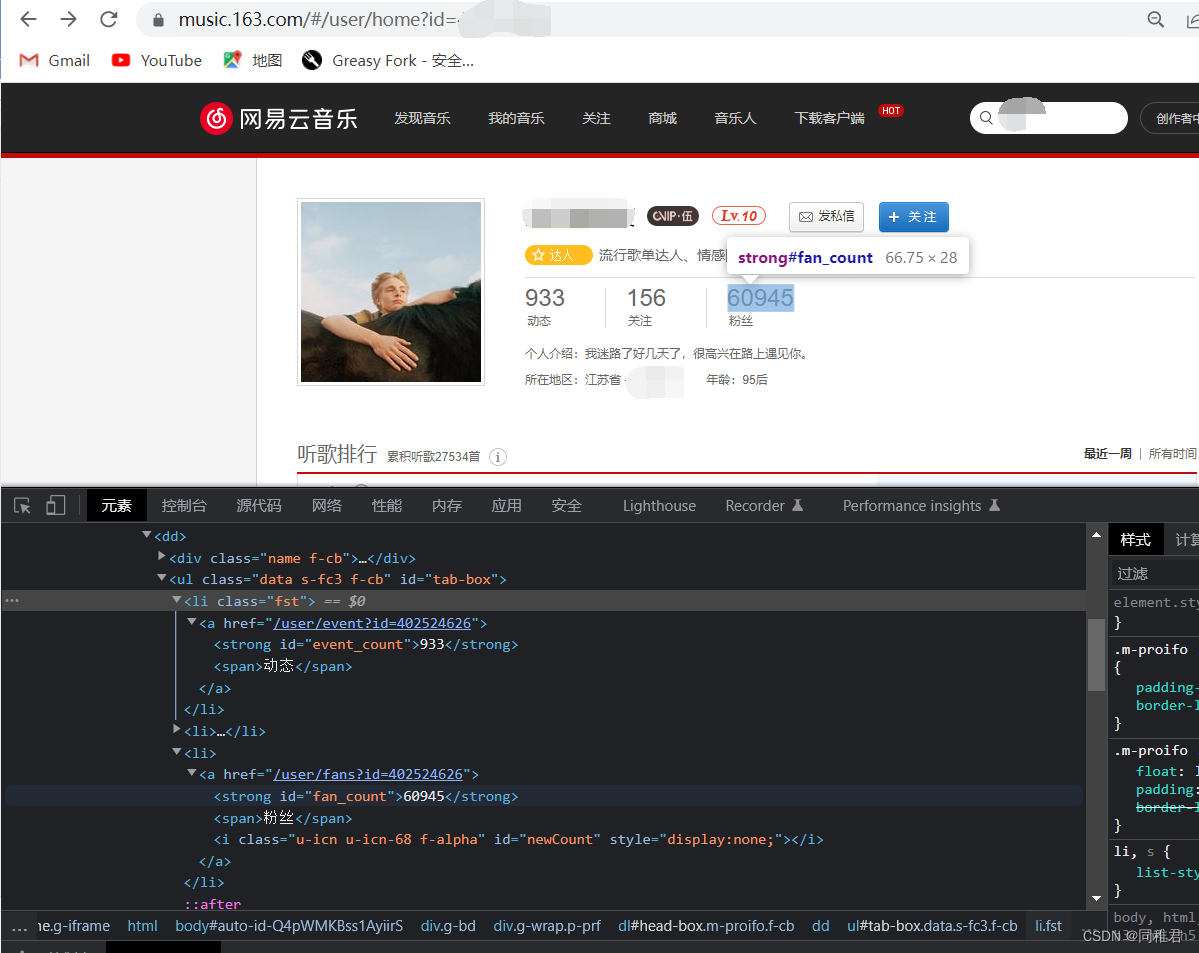
通过在浏览器页面中点击 右键->检查 来打开开发者模式,从而查看页面结构(能看到这的小伙伴应该都不用再细教这些了吧)


















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











