






前言:在Elasticsearch中,自动补全(Autocomplete)是一种功能,它允许用户在输入搜索词的过程中获得即时的补全建议或建议列表。自动补全功能通常在搜索框或搜索引擎的用户界面中使用,旨在提供更快速和更准确的搜索体验。简而言之:自动补全是一种搜索功能,它可以帮助我们更快速地找到我们想要的内容。你可能已经在一些网站或应用程序的搜索框中见过它。当你开始输入搜索词时,它会自动显示一些相关的建议或完成词,帮助你选择或补全你的搜索词。
举个例子,假设你在一个电商网站上搜索商品,当你输入关键词时,自动补全会立即显示一些相关的商品名称或类别供你选择。这样,你就不需要输入完整的搜索词,而是从建议列表中选择一个,这其中就使用了自动补全功能。
1、拼音分词器
什么是拼音分词器?
拼音分词器是一种在中文文本中将汉字转换为对应拼音的工具。它可以将中文文本分解为拼音首字母或完整拼音,并将其作为词汇进行索引和搜索。
下载拼音分词器:https://github.com/medcl/elasticsearch-analysis-pinyin
首先我们需要下载文件,并将文件上传到ES的插件挂载目录:
所需文件:

上述文件是如何得到的https://github.com/medcl/elasticsearch-analysis-pinyin
拼音分词器需要在Github上下载,并通过maven打包才能得到名为elasticsearch-analysis-pinyin-7.12.1.jar的jar包,具体内容不再赘述。
使用命令查看es插件的挂载目录:
docker volume inspect 卷名
我们的插件卷名是:es-plugins
[root@localhost ~]# docker volume inspect es-plugins
[
{
"CreatedAt": "2023-04-04T19:36:05+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
[root@localhost ~]#
进入目录:/var/lib/docker/volumes/es-plugins/_data
将文件上传到此文件夹:
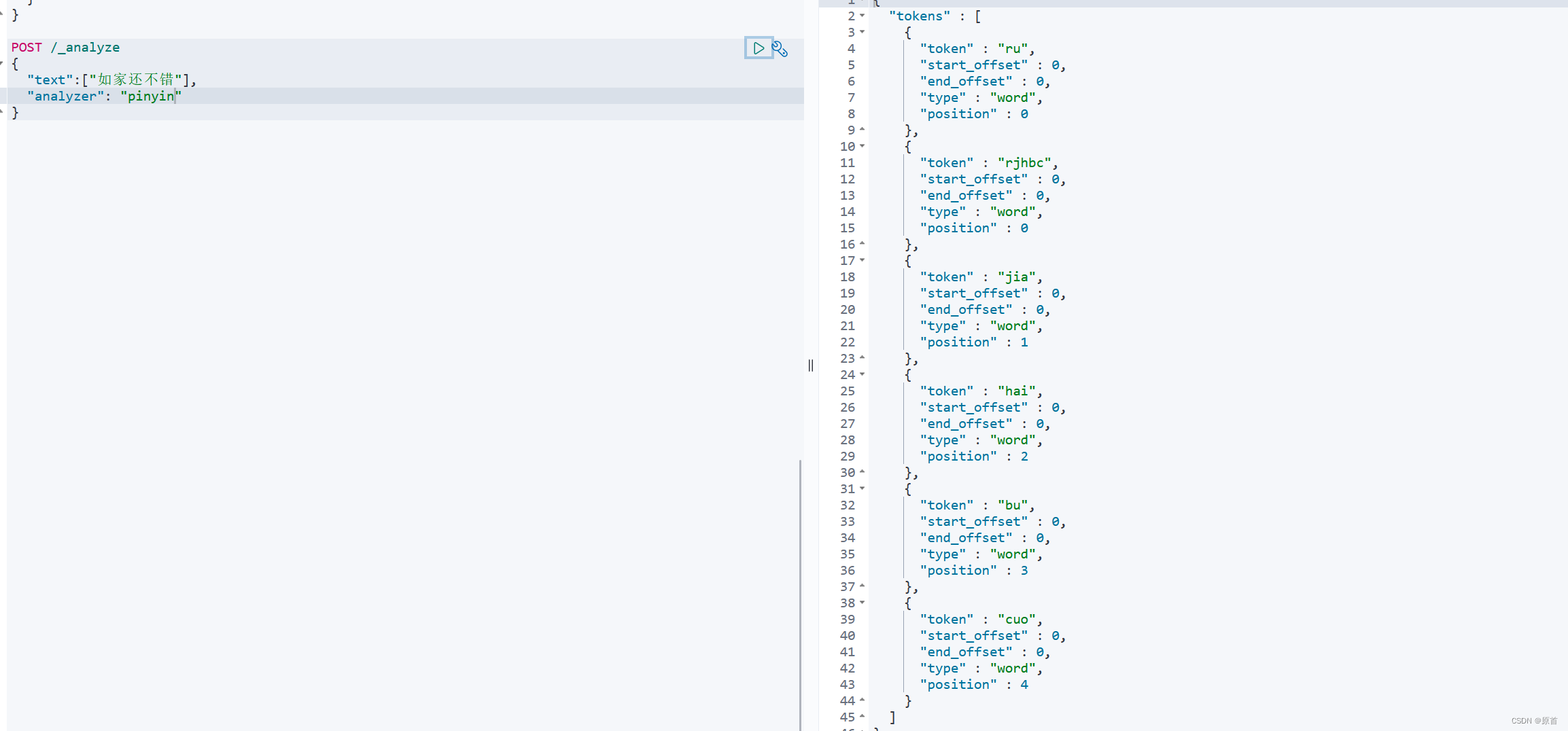
POST /_analyze
{
"text":["value"],
"analyzer": "pinyin"
}
上述代码是对文本进行分词的操作,其中value是我们要分词的文本,pinyin使用的分词器。
测试使用拼音分词器:
2、自定义分词器
使用拼音分词器并不能完美的分词我们要设置一些参数
#自定义分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py":{
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}, "mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
“type”: “pinyin”:指定使用拼音过滤器进行拼音转换。
“keep_full_pinyin”: false:表示不保留完整的拼音。如果设置为true,则会将完整的拼音保留下来。
“keep_joined_full_pinyin”: true:表示保留连接的完整拼音。当设置为true时,如果某个词的拼音有多个音节,那么它们将被连接在一起作为一个完整的拼音。
“keep_original”: true:表示保留原始词汇。当设置为true时,原始的中文词汇也会保留在分词结果中。
“limit_first_letter_length”: 16:限制拼音首字母的长度。默认为16,即只保留拼音首字母的前16个字符。
“remove_duplicated_term”: true:表示移除重复的拼音词汇。如果设置为true,则会移除拼音结果中的重复词汇。
“none_chinese_pinyin_tokenize”: false:表示是否对非中文文本进行拼音分词处理。当设置为false时,非中文文本将保留原样,不进行拼音分词处理。
在索引的设置(settings)中,我们定义了一个名为analysis的分析器配置。
在分析器配置中,我们创建了一个名为my_analyzer的自定义分词器(analyzer)。
自定义分词器使用了ik_max_word作为分词器,即使用ik分词器进行最大化分词。
我们将一个名为py的过滤器(filter)添加到自定义分词器中,用于处理拼音转换。
过滤器py是一个拼音过滤器(pinyin filter),可以将中文转换为拼音。
在拼音过滤器的参数中,我们设置了一些选项,如禁用全拼音、保留连接的全拼音、保留原始词汇等。
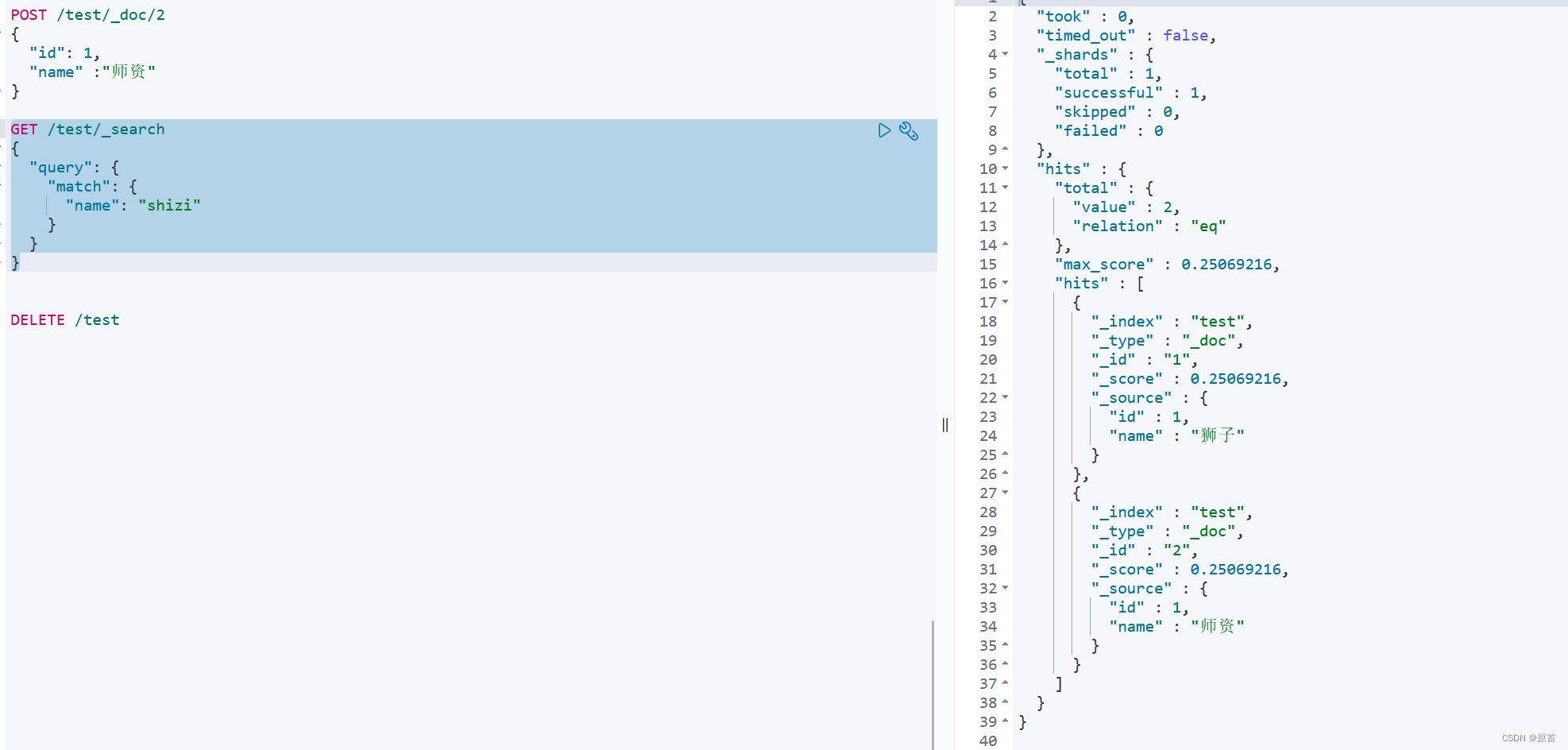
我们在将数据添加到这个测试索引库中:
POST /test/_doc/1
{
"id": 1,
"name" :"狮子"
}
POST /test/_doc/2
{
"id": 1,
"name" :"师资"
}
测试:
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
3、自动补全查询
自动补全查询是一种在搜索引擎中提供实时搜索建议的功能。当用户在搜索框中输入关键词时,搜索引擎会根据已有的数据进行匹配,并返回与输入关键词相关的建议。
要实现自动补全查询首先我们需要创建一个索引库,
这里我们创建一个名为test2的索引库,并创建类型为completion 字段名为title
#创建自动补全索引库
PUT /test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
#插入数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
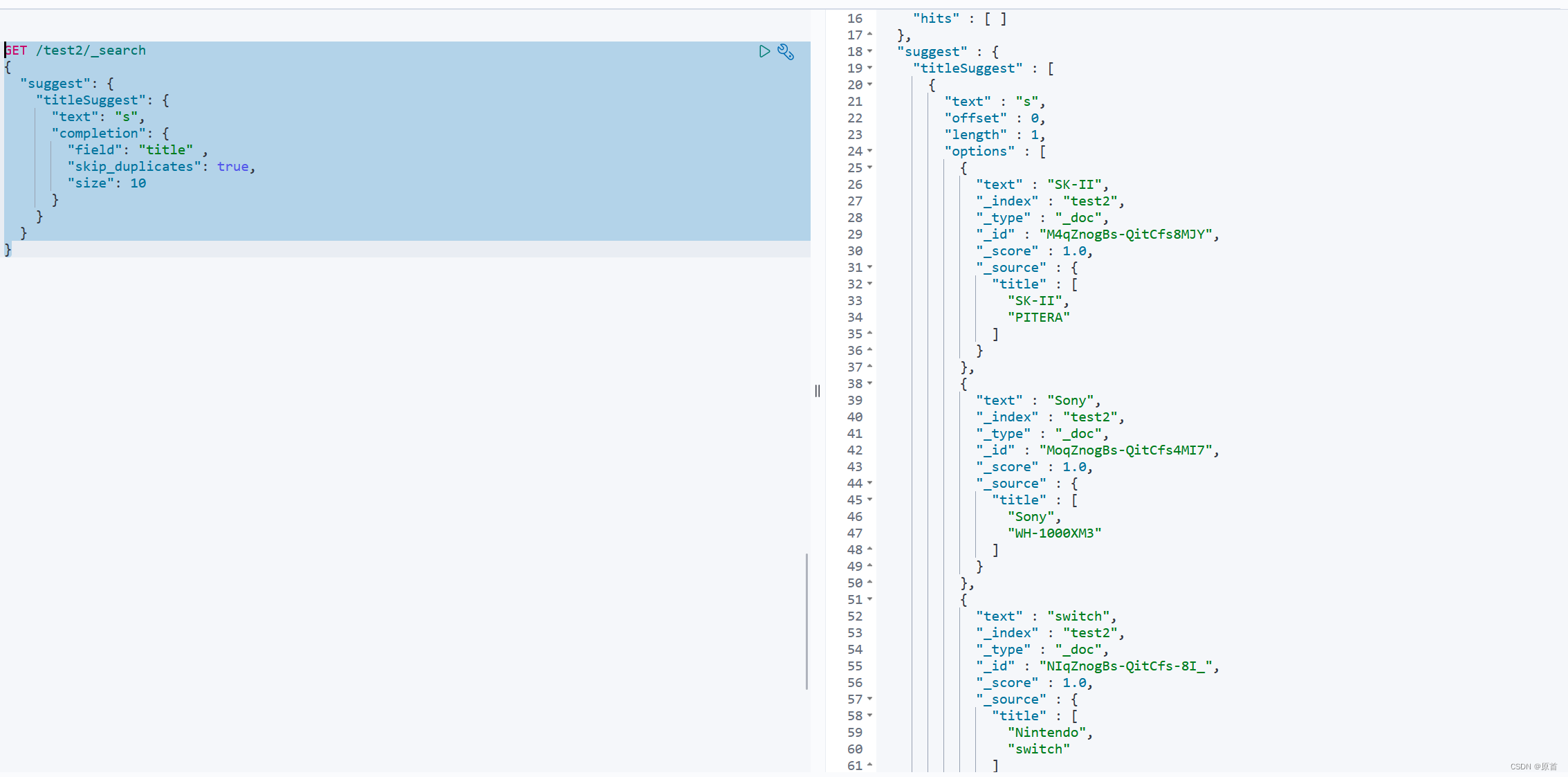
查询语法
GET /索引库名/_search
{
"suggest": {
"titleSuggest": { //suggest名
"text": "s", //查询的之,基于这个值做自动补全
"completion": { //类型
"field": "title" , //查询字段名
"skip_duplicates": true, //跳过重复
"size": 10 //数量
}
}
}
}
4、实现酒店搜索自动补全
 导入索引库:
导入索引库:
// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
创建完索引库需要将数据导入到索引库,关于导入索引库的文章http://t.csdn.cn/wPNp4这里不在赘述
代码关键部分讲解:
analysis字段用于定义索引的分析器和过滤器。
在分析器部分,有两个定义:text_analyzer和completion_analyzer。
text_analyzer分析器:
tokenizer:使用ik_max_word分词器,该分词器适用于中文文本,可以将文本按照最大词长进行分词。
filter:使用名为py的过滤器,该过滤器是自定义的拼音过滤器,用于将中文转换为拼音。
completion_analyzer分析器:
tokenizer:使用keyword分词器,该分词器将输入作为单个关键字进行处理,不进行分词。
filter:使用名为py的过滤器,同样是用于将中文转换为拼音。
同时我们在创建索引库时候新加入了字段
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
这段代码主要用来实现自动补全的,我们会将需要自动补全的字段的数据导入到suggestion字段中,suggestion是一个数组类型的这里我们将商圈、品牌作为进行自动补全的内容,也就是说当我们搜索对应的商圈、酒店品牌辉有自动补全的功能
if (this.business.contains("/")){
String[] arr = this.business.split("/");
//添加元素
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion, arr);
}else{
this.suggestion = Arrays.asList(this.brand, this.business);//将品牌和商圈放入suggestion中作为自动补全的内容
}
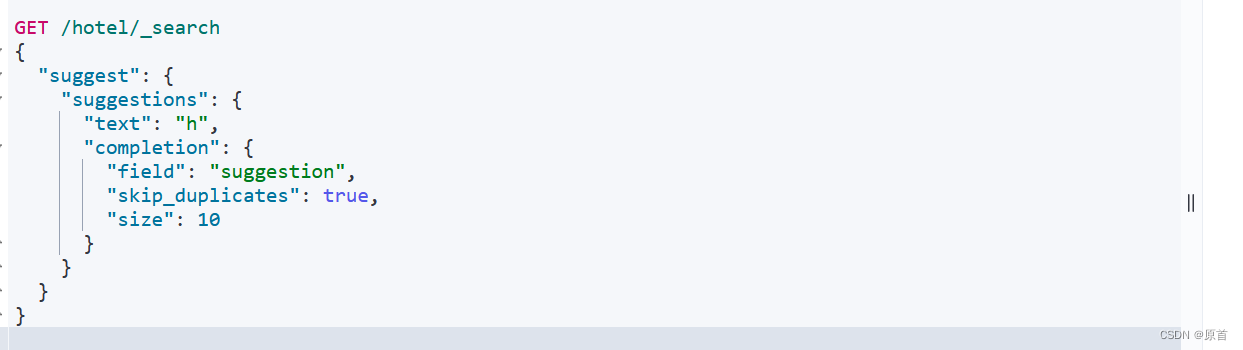
GET /hotel/_search
{
"suggest": {
"suggestions": {
"text": "h",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
eg:
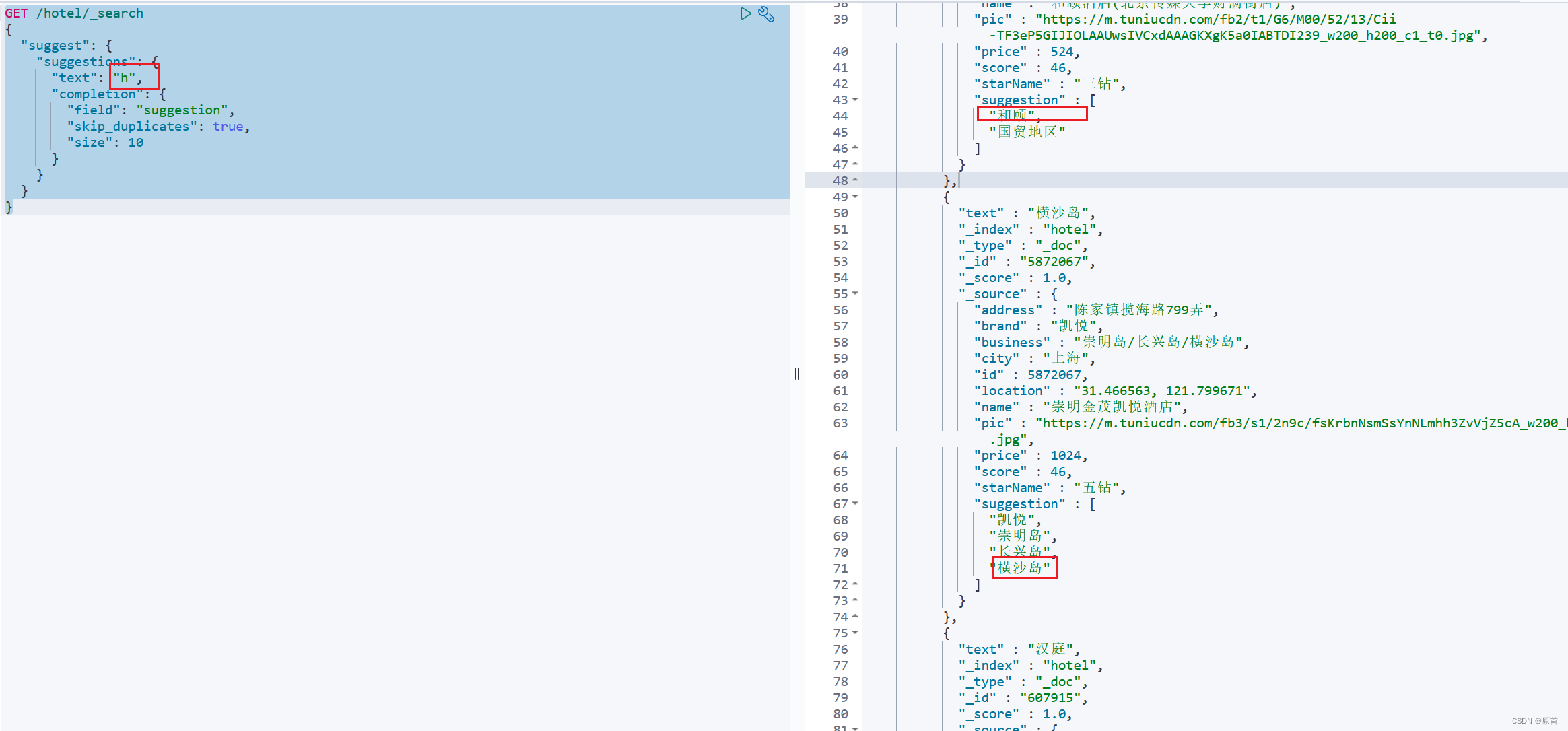
使用RestAPI实现自动补全功能
关于连接ES客户端部分内容略,之展示有关自动补全相关API的使用
现在将上文中DSL使用java代码实现:
@Test
void testRequest() throws IOException {
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")//搜索值,会对h进行自动补全
.skipDuplicates(true)//去重
.size(10)));//数量
//3、发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析结果
System.out.println(response);
}
结果解析:
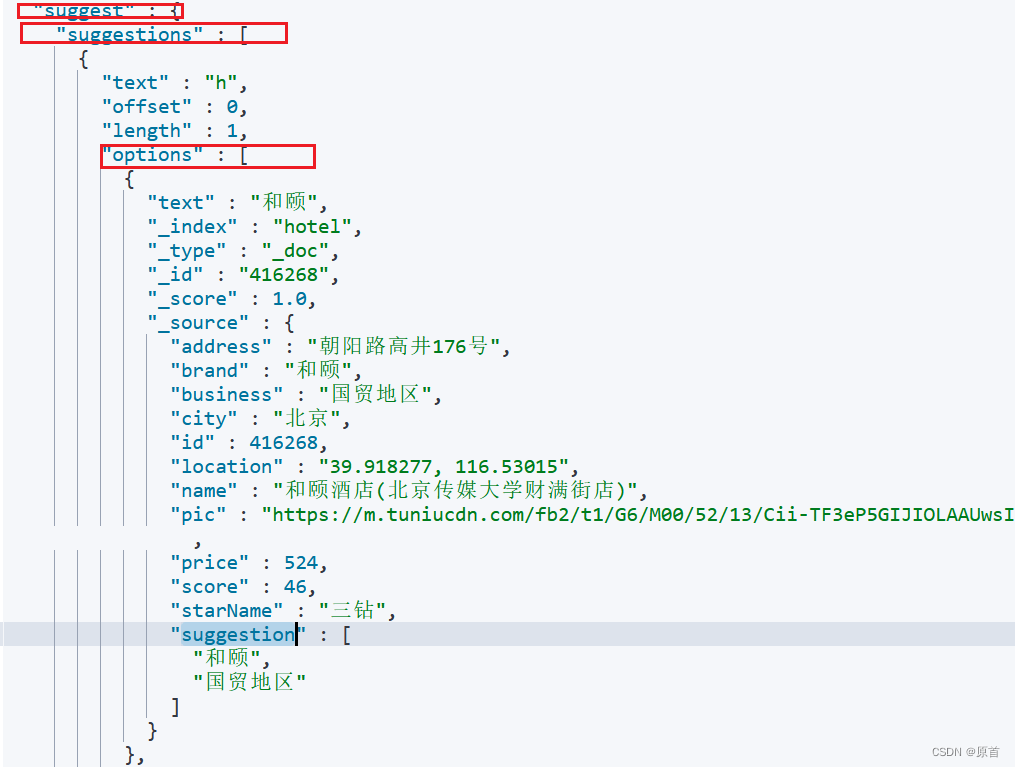
@Test
void testRequest() throws IOException {
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")//搜索值,会对h进行自动补全
.skipDuplicates(true)//去重
.size(10)));//数量
//3、发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析结果
Suggest suggest = response.getSuggest();
//4、1根据名字去结果
CompletionSuggestion suggestions
= suggest.getSuggestion("suggestions");
//4、2获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//4、3遍历
for (CompletionSuggestion.Entry.Option option : options) {
String value = option.getText().toString();
System.out.println(value);
}
}

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











