







分析器
可以直接定义在settings下analysis下的几个属性:
- Analyzer由Charactor Filter—>Tokenizer—>Token Filter三部分组成。
- Normalizer:规整器,它没有分词器,只有字符过滤器和分词过滤器。例如对keyword类型做标准化处理。
- Charactor Filter:字符过滤器,去掉文本原始的一些字符,例如html标签等。可以有多个
- Tokenizer:分词器,将上一步处理完的全文数据根据一定的规则拆分成词项。
- Token Filter:分词过滤器,转换分词后产生的所有词项,例如将分词转为小写,取出的、地、得等停用词,没有Tokenizer。
其中1是组装2345的,2和3是用于数据加入ES时处理原始数据的,4是用于2、3处理后分词的,5是用于4分词后产生的词项进行操作。
- Analyzer用于非keyword类型的字段,给keyword类型字段设置了analyzer,该字段会不会分词,keyword类型是不能设置analyzer的,该类型下没有该属性,强行设置会直接报错。
- Normalizer只用于keyword类型的字段,除了keyword类型,其他类型字段不能设置normalizer。
- 当查询设置了normalizer属性的keyword类型字段时,其normalizer也会作用到查询词上。
设置和查询分析器的两个restful的api,分别是_setting和_analyze
内置过滤器
-
html_strip:html标签过滤器
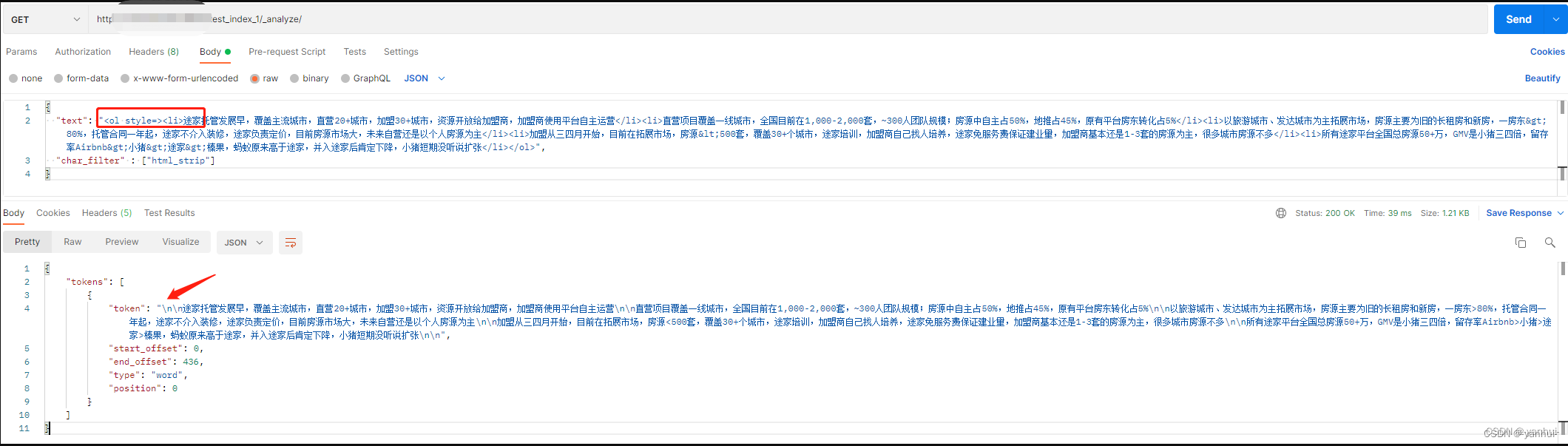
-
lowercase:忽略大小写
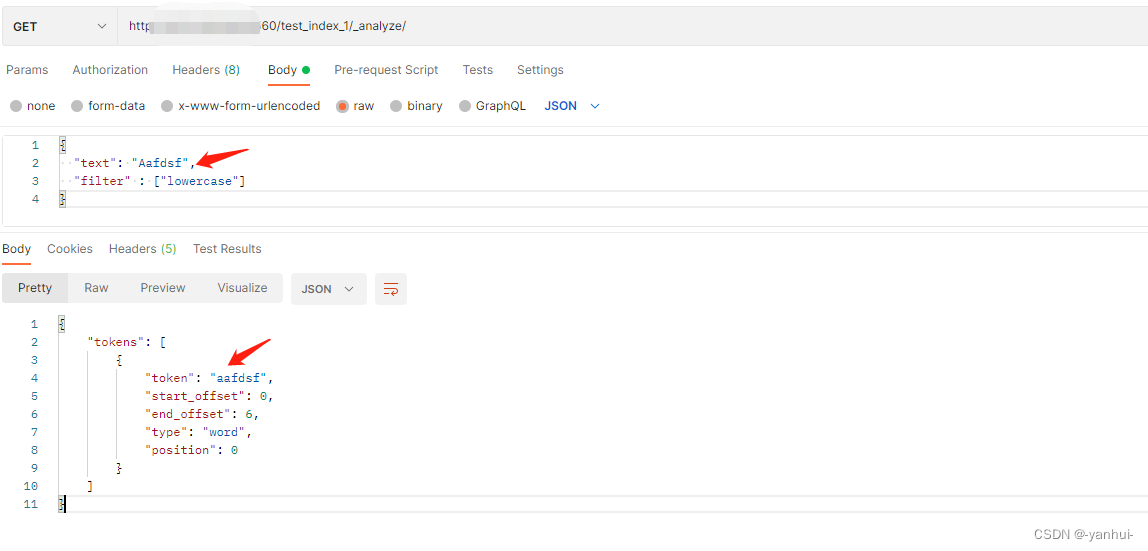
-
synonyms:同义词过滤,这个过滤器也支持指定近义词路径参数
synonyms_path。http://localhost:9560/test_index_1/_settings/ { "index": { "analysis":{ "filter":{ "my_synonyms_filter": { "type": "synonym_graph", "synonyms": [ "China, chn" ] } }, "analyzer":{ "my_synonyms_analyzer": { "filter": [ "my_synonyms_filter" ], "type":"custom", "tokenizer":"ik_smart" } } } } }
-
pattern_replace:正则替换,将所有非数字或字母都替换为空值。
{ "index":{ "analysis":{ "char_filter":{ "patternFilter":{ "pattern":"[^A-Za-z0-9]", "type":"pattern_replace", "replacement":"" } } } } }
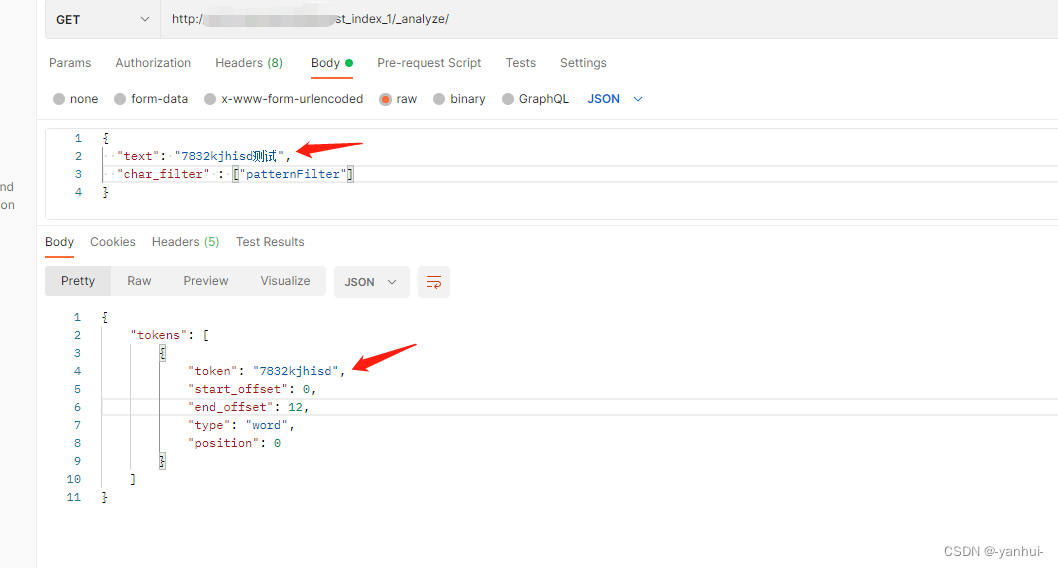
内置分析器、分词器
-
standard:根据Unicode文本分段算法,这个会把中文的话就把中文拆成一个字一个字的了,可能会造成冗余结果。还支持设置参数
stopwords,stopwords_path,max_token_length{ "index":{ "analysis":{ "analyzer":{ "my_standrad_analyzer":{ "type":"standard", "max_token_length":5, "stopwords":"and,or" } } } } }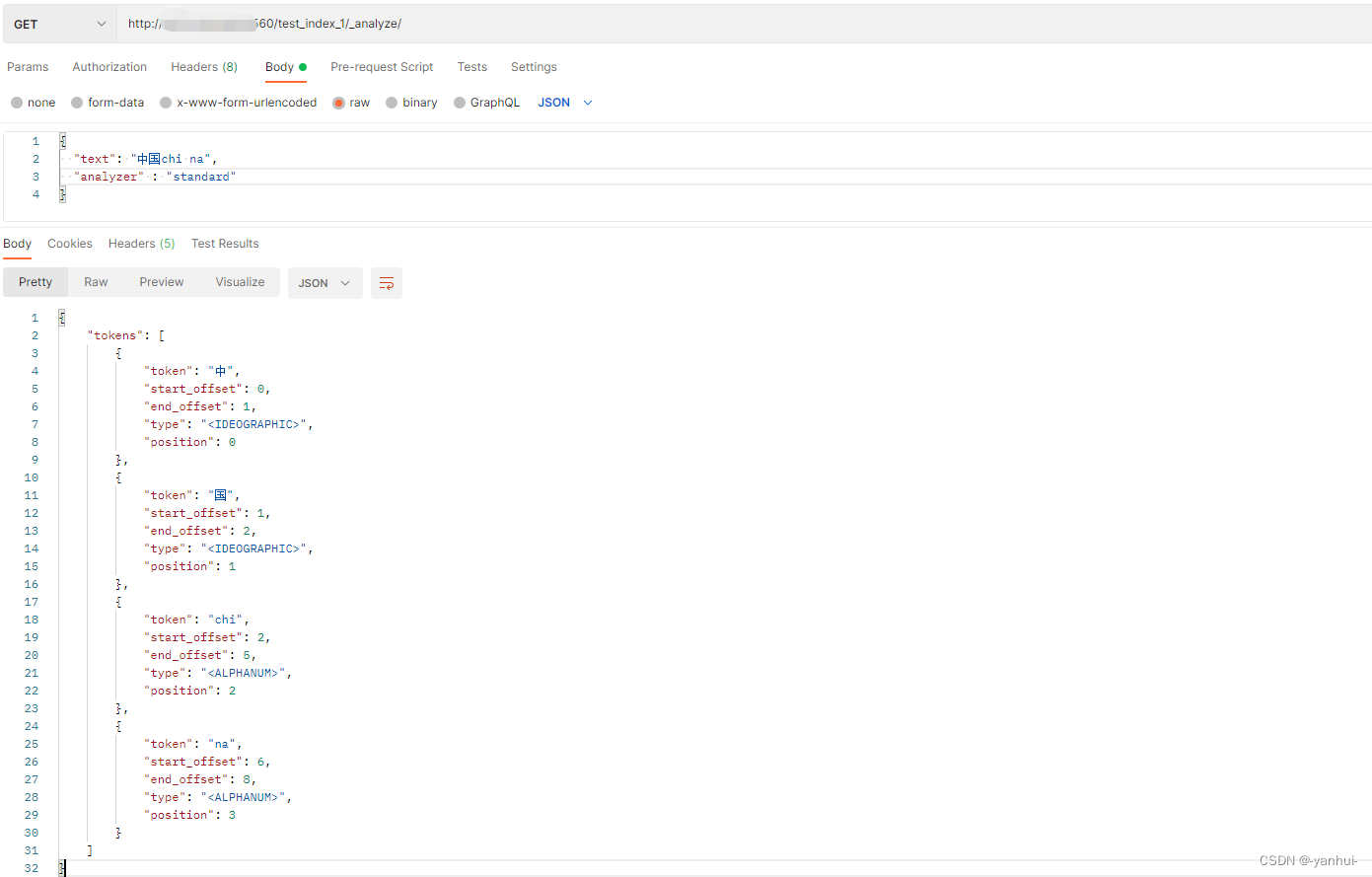
-
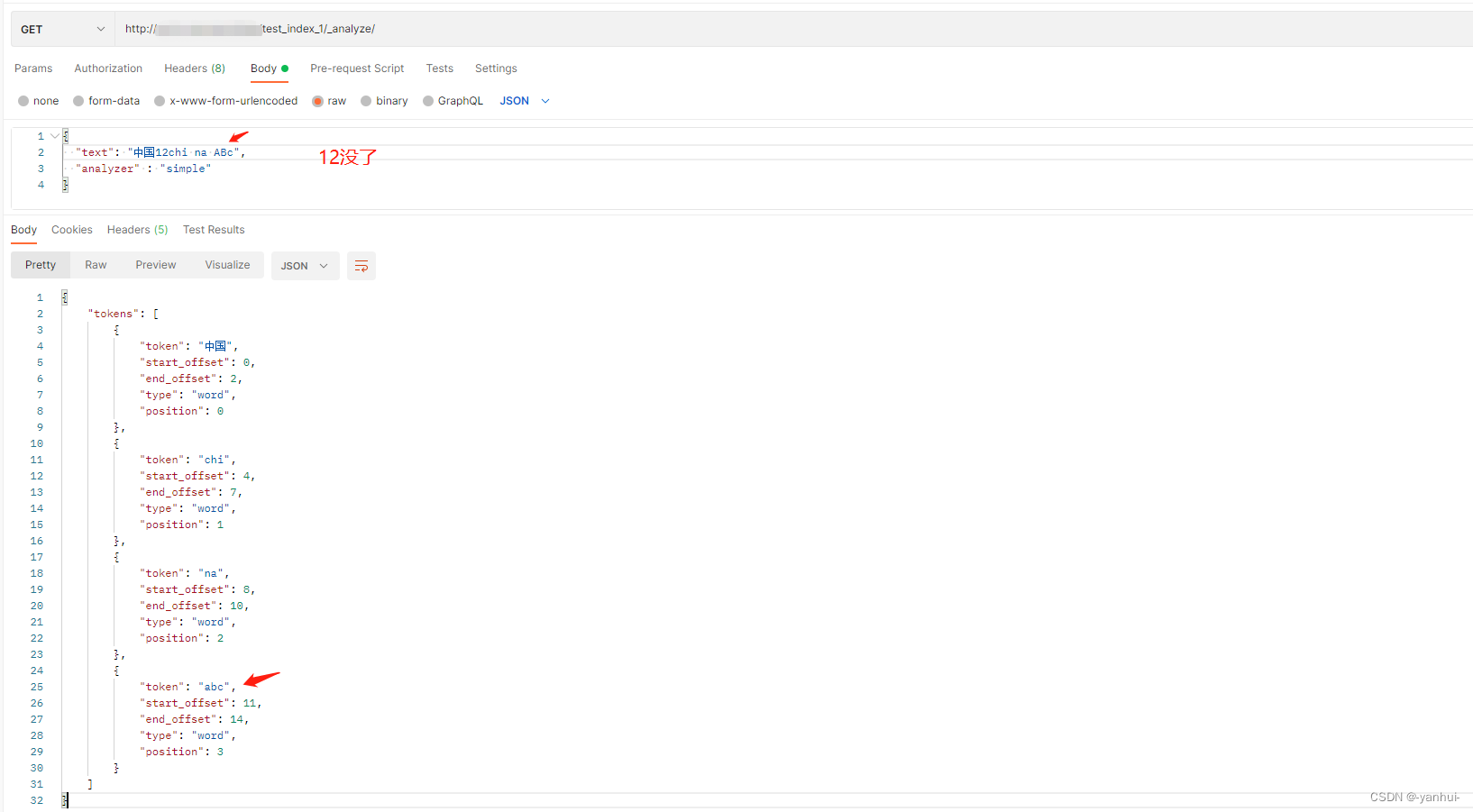
simple:将文本按照非字母字符进行拆分,并将分词转为小写。
-
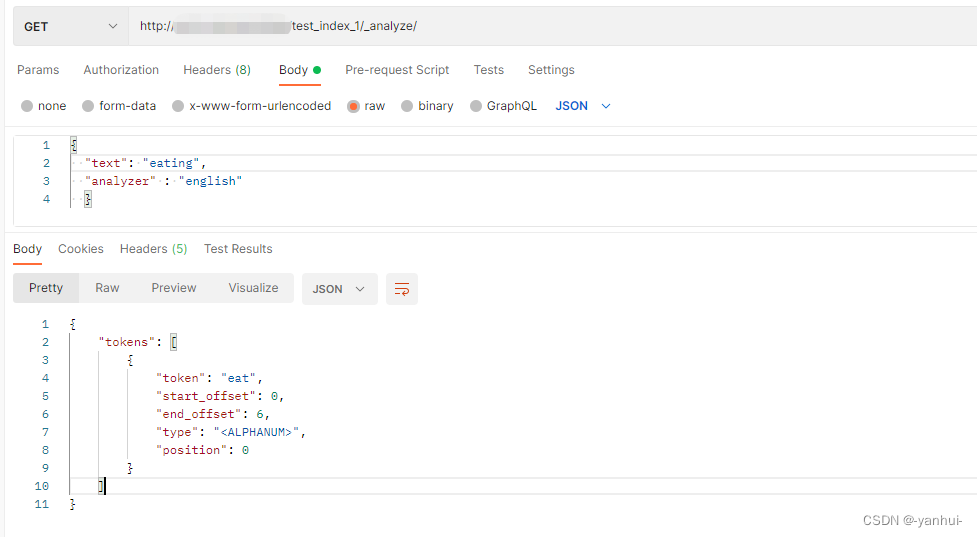
english:将英文单词的各种变形处理成单词原型。
-
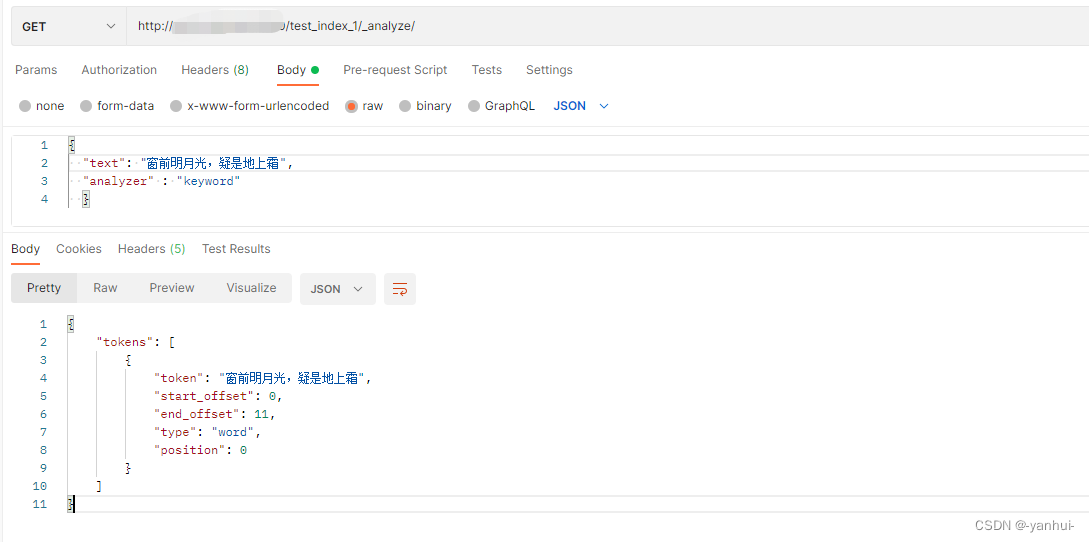
keyword:保留原始值不变
-
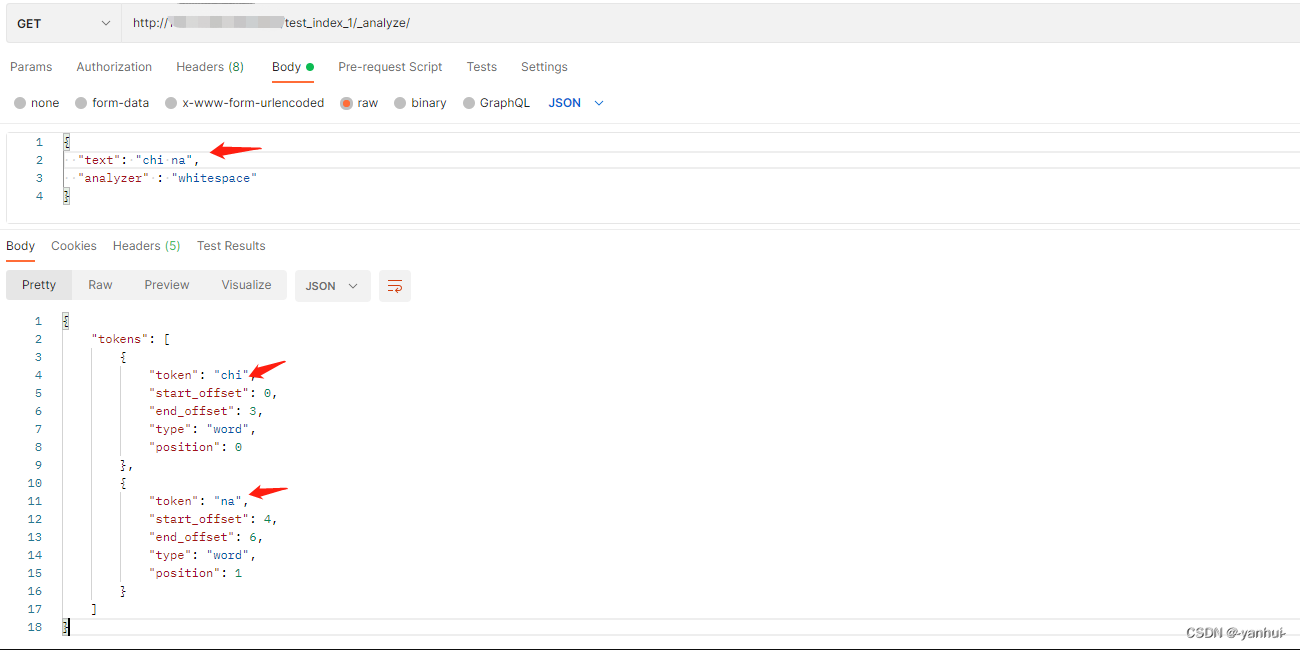
whitespace:按照空格进行分词。
-
classic:按照英语的语法进行分词,去掉一些碎词。比如:
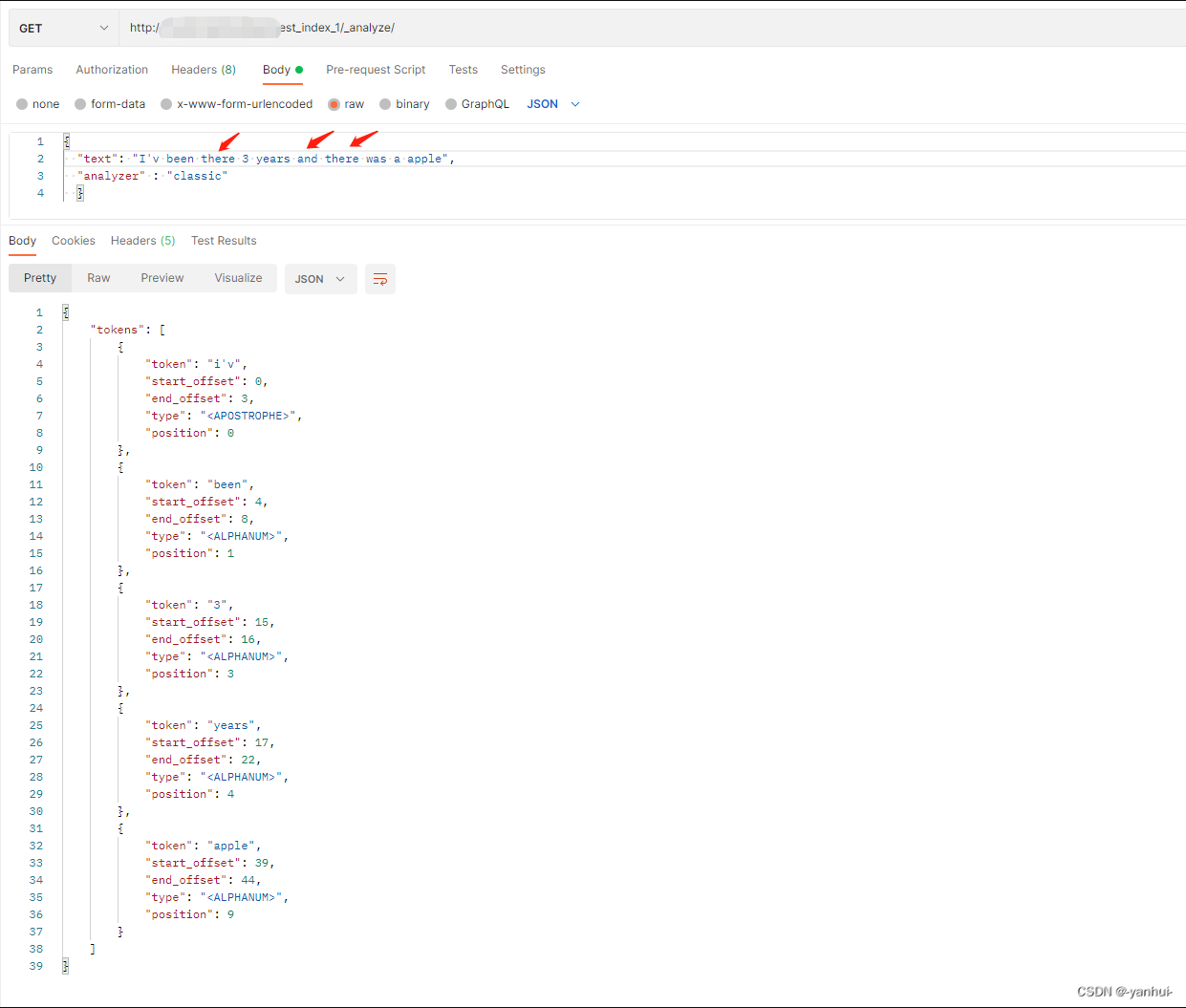
分词器
-
letter:在非字母位置上分割文本。
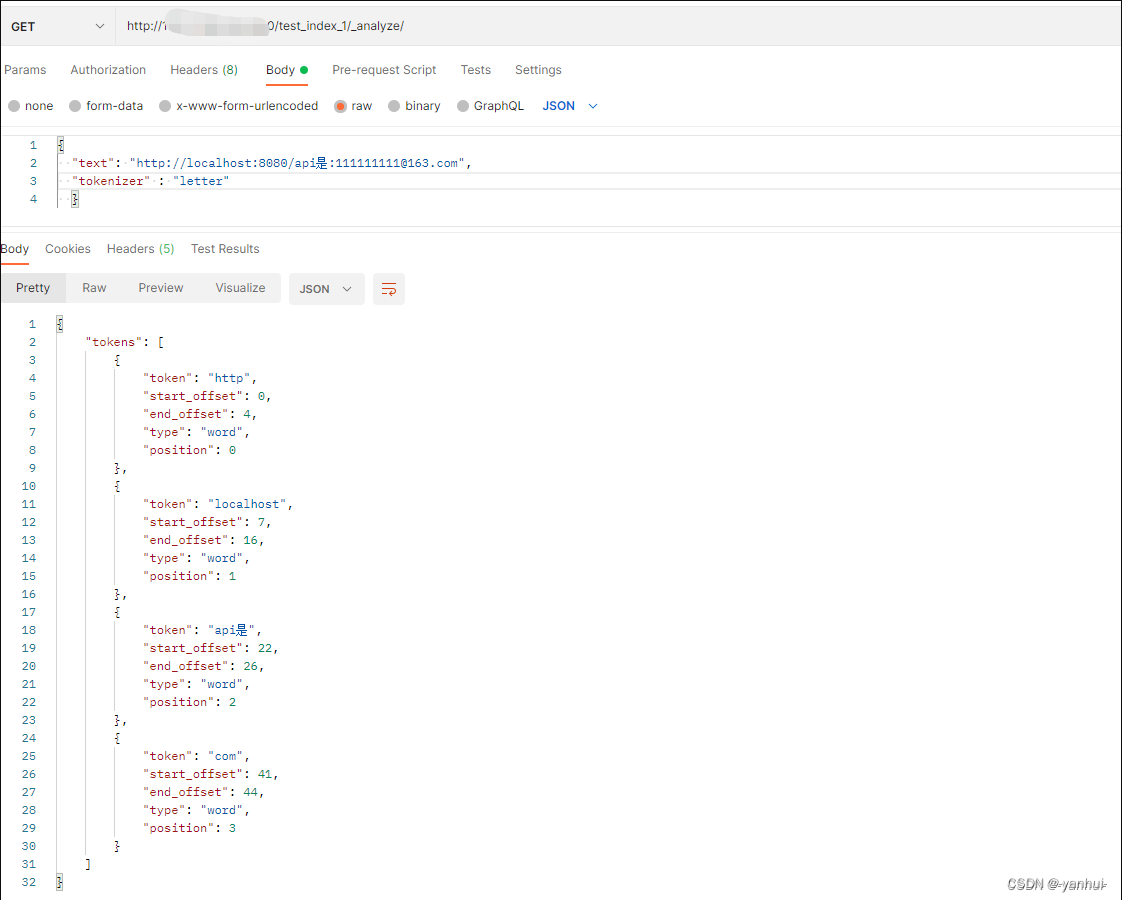
-
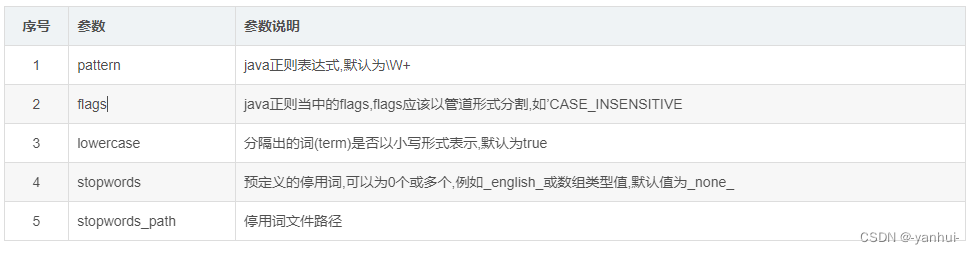
pattern:使用正则表达式进行分词,
默认值为\W+,匹配非单词字符(含中文)。支持配置一些额外参数。
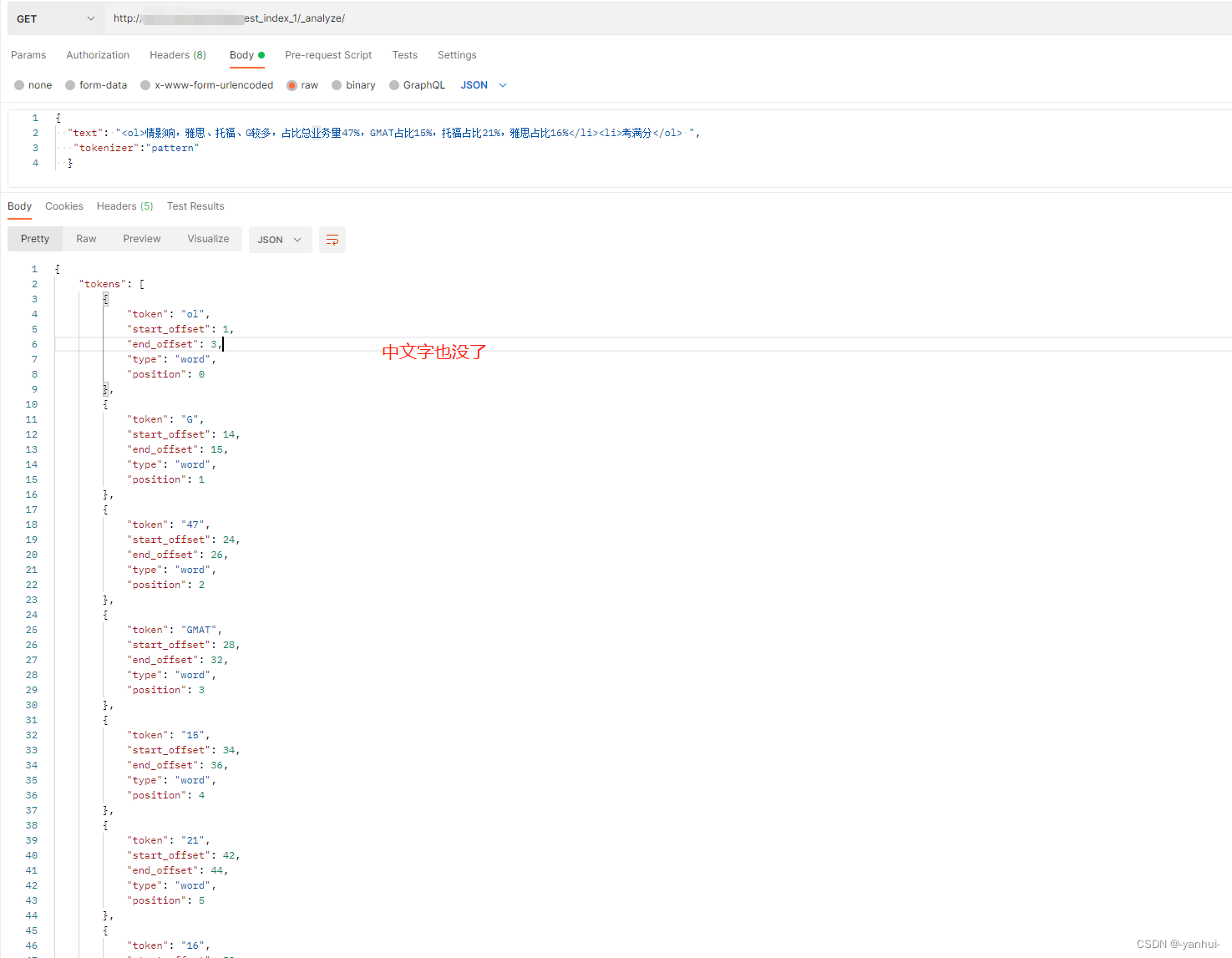
其他示例:{ "settings": { "analysis": { "analyzer": { "email_analyzer":{ "type":"pattern", "pattern":"\\W|_", "lowercase":true } } } } -
uax_url_email:按照文本中的url,邮箱地址去做分词。

官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/multi-fields.html
拼音分词器:
git地址:https://github.com/medcl/elasticsearch-analysis-pinyin,相关参数配置:

总结如下:
- keep_first_letter:刘德华—>ldh,
默认值为true - keep_separate_first_letter:刘德华—>l,d,h,
默认为false - limit_first_letter_length:设置first_letter结果的最大长度,
默认长度16 - keep_full_pinyin:刘德华—> liu,de,hua,
默认为true - keep_joined_full_pinyin:刘德华—>liudehua,
默认为false - keep_none_chinese:非中文字不分词,
默认为true - keep_none_chinese_together :将非中文放在一起,
默认为true,DJ音乐家 -> DJ,yin,yue,jia,如果设置为false,DJ音乐家 -> D,J,yin,yue,jia - keep_none_chinese_in_first_letter :将非中文字母放在第一个字母中合成为一个分词,刘德华AT2016—>ldhat2016,
默认为true - keep_none_chinese_in_joined_full_pinyin:保持非中文字母的完整拼音,刘德华2016—>liudehua2016,
默认为false - none_chinese_pinyin_tokenize:将非中文字母(如果是拼音)的话拆分成一块一块的,
默认为true,keep_none_chinese和keep_none_chinese_together应该首先启用。 - keep_original:保留原始输入值,
默认为false - lowercase:小写非中文字母,
默认值为true - trim_whitespace:去空格,
默认值为true - remove_duplicated_term:重复的词将会被删除,de的—>de,(正常de的—>dede),
默认为false - ignore_pinyin_offset:没看懂














 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









