







SSTable
终于开始看
SSTable的设计了👀, 在这里记录一下我觉得比较亮眼的地方SSTable: Sorted String Table, 作为存储在磁盘上面的数据,有序是必要的,这样我们查询的时候会更快。
当
memtable中的数据超过一定的阈值之后就会转换为immutable memtable,后台线程会将immutable按照SSTable的格式写入到磁盘上面。这里多提一嘴:什么时候我们可以进行 异步操作?之前看Redis中的 非关键路径 那么就可以开一个线程帮我们完成,实现异步操作。非关键路径也就是我们 不需要立即返回操作得到的结果,可能是返回一个 我已经做了的状态,总之就是不要求马上返回结果,那么我们就可以开一个子线程去操作来避免阻塞我们的主线程。
SSTable的文件格式
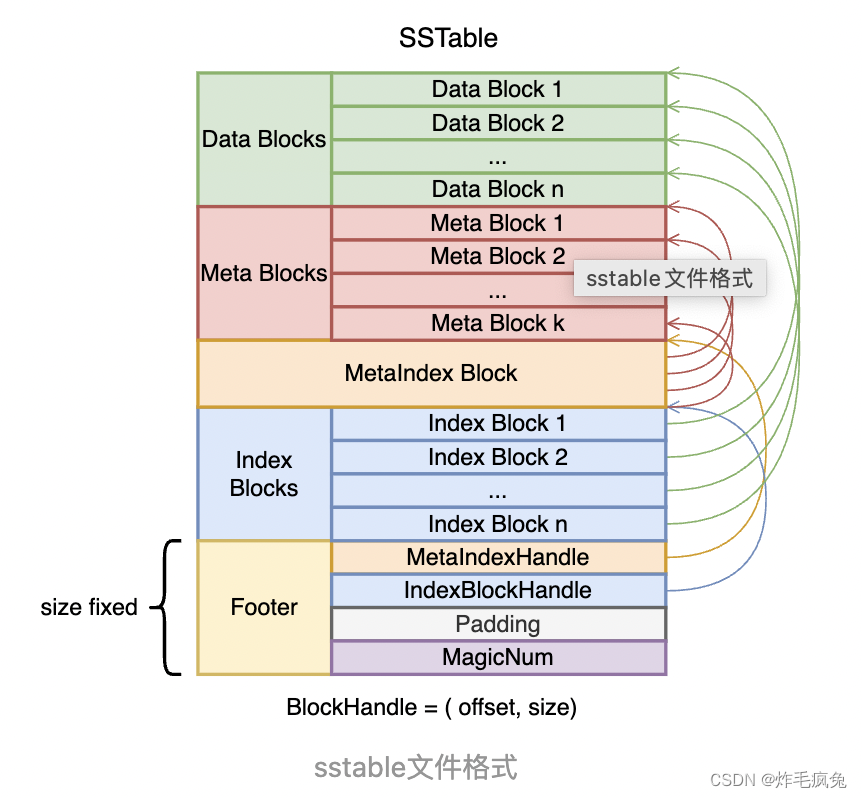
按照功能进行划分的话可以分成几个区域
Data Block: 实际上存放key/value数据Meta Block: 存放过滤器和SSTable相关的统计数据MetaIndex Block: 存放了所有 Meta Block的索引Index Block: Data Block的索引Footer: 48Bytes大小,两个Handle标识metaindex block&index block
Block
想象一下怎么进行
key-value数据的存储,最简单的方式就是一个个的将key-value进行有序的存储。
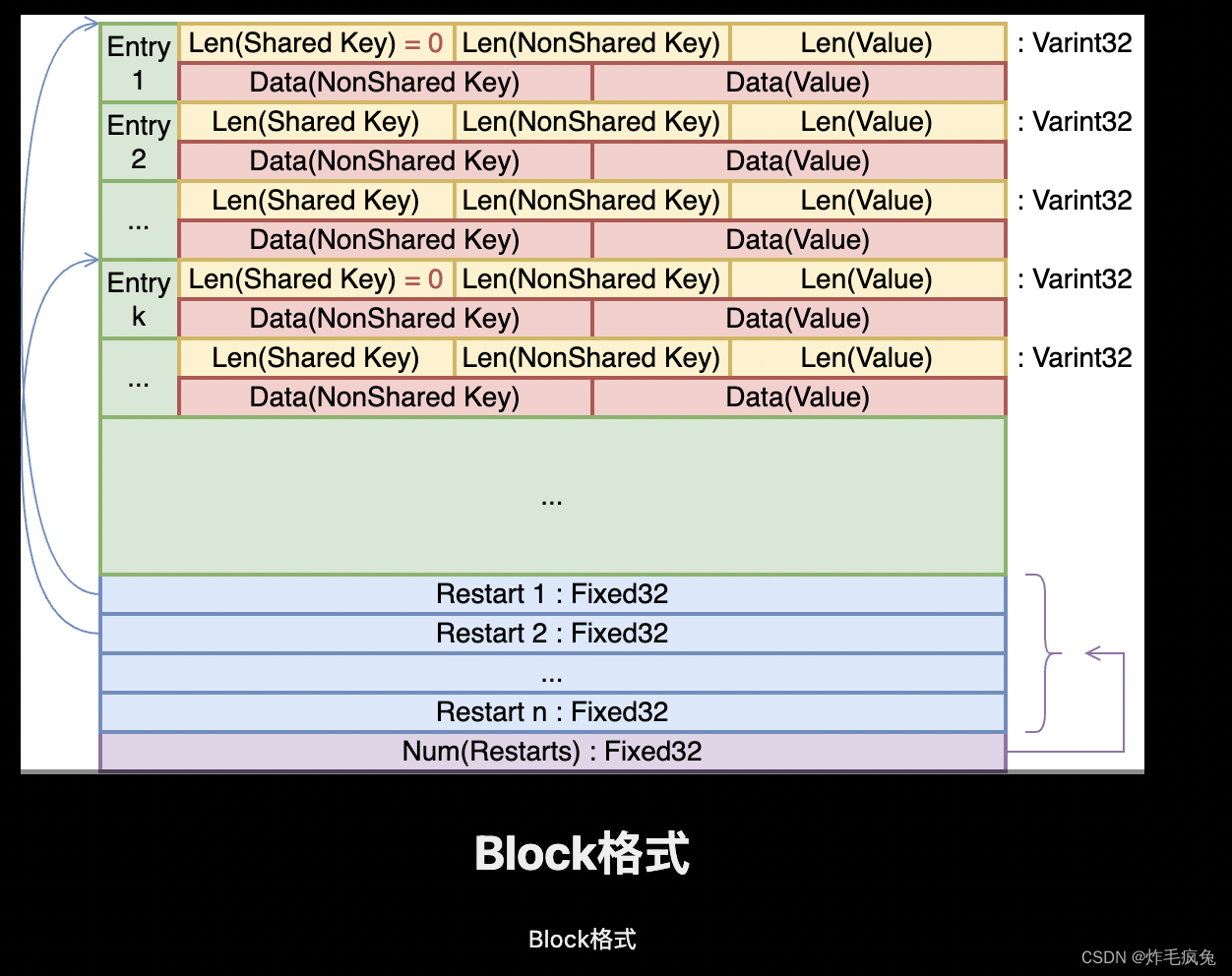

shared_bytes:和前一个 key 相同的前缀长度。
unshared_bytes:和前一个 key不同的后缀部分的长度。
value_length:value 数据的长度。
key_delta:和前一个 key不同的后缀部分。
value:value 数据。
Leveldb中做了一个优化:前缀压缩, 利用了Key的有序性(也就是前缀相同的会聚集到一起的)举个例子🌰:记录1的key:
abcd, 记录2的key:abce, 那么我们就能够将 相同的前缀部分提取出来,这一部分的内容不用每一个entry都去存储,因为key是有序的,这样其实能够 进行一个显著的提升。
shared key:存储在本组中,每一条entry只要记录下 相同前缀的部分长度就好了,再记录独属于自己部分的key和value
下面待更新,看完源码再来说说细节















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









