







算法原理
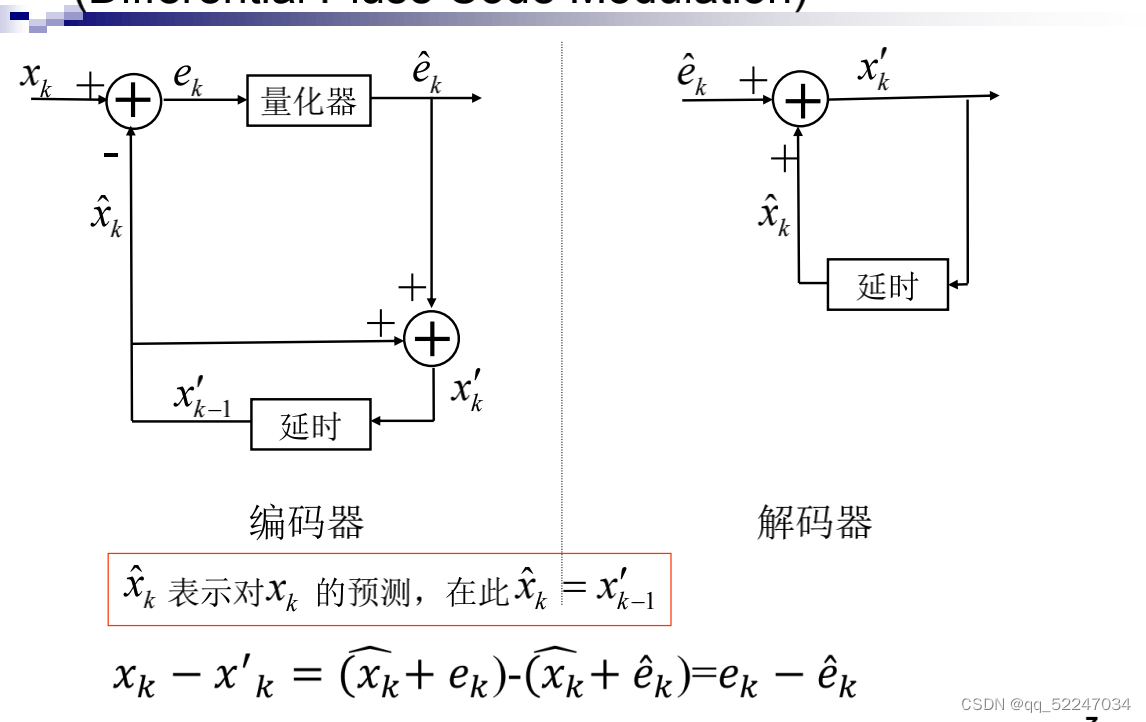
如图,DPCM利用信源相邻符号之间的相关性进行预测编码。在编码端,输入一个样本值,与上一个样本的预测值作差,对差值进行量化,得到的量化结果一方面作为编码端输出,另一方面反量化后作为预测器的输入,与上一个样本的预测值相加,作为当前样本的预测值(或说重建值)。
实现功能
本次采用左侧预测,并且默认最左侧像素前的真实值为均为128。并且实现了如下功能:
进行不同量化bit数的差分预测编码
将编码结果进行输出并进行霍夫曼编码
分别计算原图像和量化后的图像进行概率分布
分别计算原图像经过熵编码和经过DPCM+熵编码的图像的压缩比
比较二者压缩效率
计算重建图像的PSNR
实验代码
#include <iostream>
#include <cstring>
#include <cmath>
#include <fstream>
#include <algorithm>
#define uchar unsigned char
#define ll long long
using namespace std;
const string path = "C:\\Users\\sdlwq\\Desktop\\test\\Lena256B.yuv"; // 原始图像4:1:1
const string build_out = "build.yuv"; // 重建
const string code_out = "code.yuv"; // 量化编码
const int width = 256;
const int height = 256;
double freq[256];
uchar* input_buffer; //原始图像
uchar* out_buffer; //重建图
uchar* code_buffer; //量化输出
uchar* u_buffer; // 色差信号
uchar* v_buffer;
int bitnum;
inline void calculate_freq(uchar* buffer) //计算概率分布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









