







一:实验原理

DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
二:预测结果
原始图像:

概率分布:

8bit量化

预测误差图像:
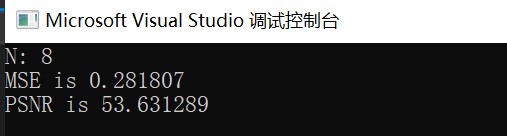
 运行结果:
运行结果:
 概率分布:
概率分布:

huffman编码:


| 图像 | 图像大小 | 压缩比 |
|---|---|---|
| 原始图像 | 732KB | 1 |
| DCPM8bit量化 | 366KB | 2 |
| huffman编码 | 219KB | 3.342 |
| DPCM+huffman | 216KB | 3.389 |
通过图像压缩比,可以看出,在8bit量化时,DPCM的压缩程度比较下,效果不如huffman编码。对图像进行DPCM+huffman编码的压缩比最大,压缩效果最好。
三:代码部分
头文件:
#pragma once
void frequency(int num, unsigned char *y, double *fre);
void DPCM(int H, int W, unsigned char* y_in, char* diff_in, unsigned char* re_in, int Nbit);
计算概率分布:
void frequency(int num, unsigned char *y, double *fre)
{
for (int i = 0; i < 256; i++)
{
fre[i] = 0;
for (int j = 0; j < num; j++)
{
if (y[j] == i)
fre[i] += 1;
}
fre[i] = fre[i] / num;
}
}
DPCM:
void DPCM(int H, int W, unsigned char* y_in, char* diff_in, unsigned char* re_in, int Nbit)
{
int i, j;
unsigned char *y, *re;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









