







深度学习 (源自吴恩达课程)B站上的吴恩达课程
p21 Python中的广播
广播是一种手段,可以让Python代码端执行的更快
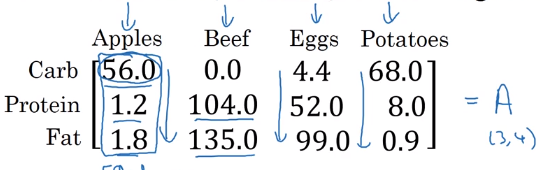
我们先把这个设成一个34的矩阵A,接下来我们将在Python中用一行代码算出矩阵A中的每列的和,对应四种不同食物的卡路里总量,这100克不同类型的食物的热量总量。让后用第二行代码表示让四列中的每一列对应的数除以其列的和。
P22 关于 python _ numpy 向量的说明
Python_numpy给我们提供了优势同时也提供了劣势,优势是因为它让语言的表现力更强,语言的灵活性更大,就是说你可以用一行代码完成很多运算;弱点是因为广播和那么大的灵活性,会带来细微的错误或非常奇怪的bug。所以接下来我们将分享一些技巧可以排除、简化或者说是消除我们自己代码中的各种奇奇怪怪的bug
首先我们先 生成5个随机高斯变量,储存数组a中

让后我们输出a会得到一个秩为1的数组

当我们print a的形状时会输出5,

它既不是行向量也不是列向量。接下来我们把a转置print出来,看起拿来还是和a一样

,当我们把a和a.Tdot(内积)在一起,结果并不是我们想要的15的矩阵而仅仅只是一个数字
 。
。
所以我们就不能用a=np.random.randn(5)这种数据结构,相反当我们用a=np.random.randn(5,1)时,就可以把a变成一个51的列向量
,并且a.T就会变成一个行向量(区别是输出的结果一头有两个括号,一个括号表示数组,两个括号表示矩阵。并且当矩阵比如是15时就是行向量5*1就是列向量)
,所以当我们再把a和a.T dot在一起时就可以输出一个矩阵,所以向量的内积可以得到一个矩阵。
a=np.random.randn(5)这种数据结构是秩为1的数组,它的行为和行向量或列向量不一样,所以有些效果不那么直观。所以我们的建议是当进行编程训练或者logistic回归时不用这些秩为1的数组。所以我们在每次创建数组时要建成一个行向量或者列向量(括号中第一个表示行)
所以第一个是列向量,第二个是行向量。
在代码中如果我们不太清楚一个向量的具体维度是多少,我们会用到assert()这样一个声明,确保这是一个向量,下面这个是用来确保是一个列向量

最后如果你有一个秩为1的数组,你可以用reshape来把它转换成一个你想要的行向量或者列向量。用a=a.reshape((5,1))就可以把a转换成一个列向量。
所以在一个代码中不要用秩为1的数组多用行向量与列向量而且要时不时的插入assert来证明是向量,并且即使用reshape来纠正错误。
p24 logistic 损失函数的解释
如果y=1,那么在给定x得到y=1的概率是 yhat;如果y=0,那么在给定x时得到y=0的概率就是1-yhat。所以yhat表示的是y=1的概率 1-yhat表示的是y=0的概率。
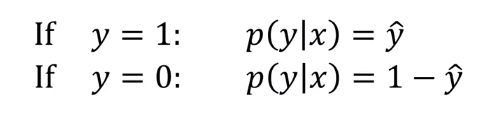
我们可以把上面的公式合成下面一个公式:
这就是对p(y|x)的定义。
由于log函数是严格的单调递增函数所以我们可知:
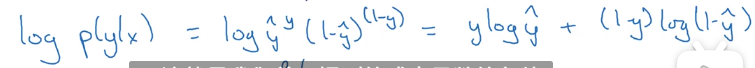
而这就是我们前面提到的成本函数的负值。只所以是负值是因为当我们训练算法时希望算法输出值的概率是最大的,然而在logistic回归中我们需要最小化损失函数,因此最小化成本函数就是最大化的log(p(y|x))。
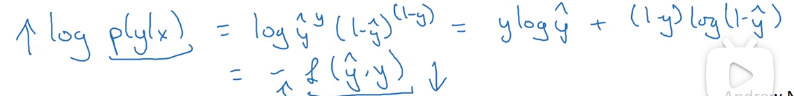
因此这就是单个训练样本的损失函数表达式 。
接下来我们来看看如何求整个训练集中标签的概率,所有这些样本概率的乘积从1到m,p(labels in the training set)表示整个训练集中标签的概率
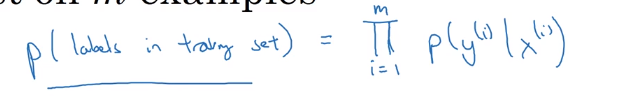
令这个p最大化就等于令其对数最大化。
我们把其化简:
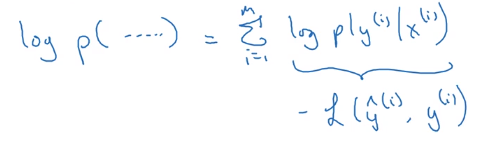
在统计学中有种叫做maximum likelihood estimation(最大似然估计)即求出一组参数使这个式子取最大值。
所以我们就推到出了logistic回归损失函数,由于我们要让损失函数最小化所以我们不是直接用最大似然概率,要去掉这个负号,最后早进行适当的放缩所以在前面乘上1/m
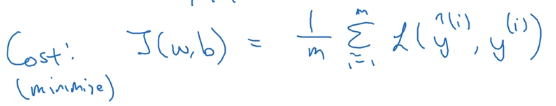
P26 神经网络表示
接下来我将展示一个神经网络,它只有一个输入层、一个隐藏层、一个输出层。隐藏层就是我们只负责输出,中间的计算过程我们不会看到我们会直接得到输出层,而中间的经过就是隐藏层。

一般我们用x来表示输入特征,但我们也可以用a[0]来表示,而这个a也表“激活”的意思就是输入层的激活值
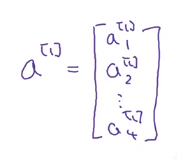
下一层即第一个隐藏层也会有激活值可以称之为a[1]。其中第一个隐藏层的第一个单元或者叫节点我们叫a[1]_1,后面的以此类推。如下图所示,我们有四个节点、四个单元、四个隐藏层单元。

在这里a[1]是一个四维向量
下一层是输出层用a[2]表示,所以输出的就是a[2]即yhat=a[2]。这就等同于在logistic回归中‘y=a’所以中括号“[]”表示的是层数,除了输出层的第几层。(输入层是第0层)
这里的隐藏层有两个相关的参数w和b,用上标表示和第几层有关系。w[1] 是一个(4,3)的矩阵,因为本层有4个单元,而输入层有3个;b[1] 是一个(4,1)的向量。同样输出层的w[2] (1,4)、b[2] (1,1)。

以上我们举的这个例子叫做‘双层神经网络’也叫‘单隐藏层神经网络’。在神经系统中我们约定输入层是第0层,所以这个加双层神经系统。
P27 计算神经网络的输出
本节课我们来看看神经网络是如何工作的
我们先来看回归计算的两个步骤,首先计算出z,然后在第二步激活函数就是函数logistic(z),所以神经网络只不过是重复计算这些步骤很多次

如果把这个原理套用在双层神经网络的第一层的第一个节点: 我们同样把第一个节点分成两部分。以后的也是以此类推。

我们把它整理到一起,其中每一个w、b、z、a都是一个行向量,我们要把他们变成一个矩阵就是让他们转置竖向量把每个w、z、b、a都叠起来。

叠起来后我们可以看到下面这幅图

我们来做个简化
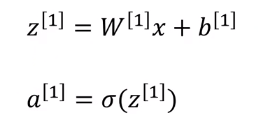
我们再来看每个矩阵的维度
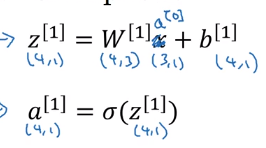
同样我们可以得到输出层
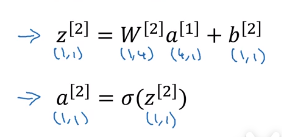
所以当我们有一个单隐层神经网络要在代码中实现时就计算上面四个等式,且你们可以把这看成是一个向量化的过程计算出这四个,四个隐藏层中的logistic回归单元就是前两个等式,而输出层的logistic回归就是用后两个等式求出来的。所以你想要计算神经网络的输出 ,所需要的就是这四行代码。
P28 多个例子中的向量化
在这之前我先来介绍,[]表示第几层,()表示第几个样本。
本节课说的是当我们有多个训练样本时,就想下面这样有1—m个样本

首先我们让 每个样本用for循环加上向量化(后面四个公式是向量化),在最开始用dor循环,太慢,(用for循环版本如下)

接下来我们把for也去除,首先我们先把X定义成一个(n_x,m)的矩阵
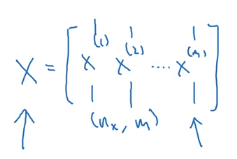
所以原式就变成(就是把1—m个样本变了)
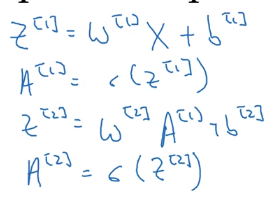
同样我们把Z[1]、Z[2]、A[1]、A[2]、b[1]、b[2]变成(n_x,m)的矩阵

以上每个矩阵分为横向和竖向,横向指标就对应了不同的训练样本,当你从左到右扫的时候就扫过了整个训练集,如果你往横向移动的时候就会从第一个训练样本的第一个隐藏单元,到第二个训练样本的第二个隐藏单元……一直到第m个。竖向指标就对应了神经元里不同的节点,当你从上到下扫过来时这是隐藏单元的指标。总的说横向对应不同的样本,竖向对应不同的输入特征这其实是神经网络的不同节点。
P30 激活函数
本节课我们会讲些激活函数,搭建一个神经网络你可以选择在隐藏层里用那一个激活函数还有神经网络的输出单元用什么激活函数,到目前为止我们一直在用 在例子中的神经网络中有两处要用到
在例子中的神经网络中有两处要用到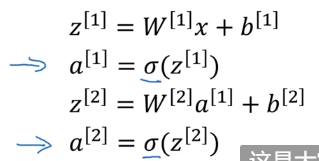
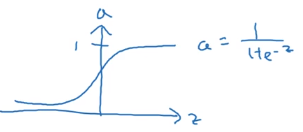
下面就是这个激活函数的图像以及公式
我们再来介绍一个更好的激活函数:tanh函数:
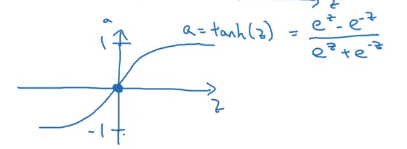
它是介于-1—1之间,公式。图像如上图所示。用这个激活函数替代上面那个得到的结果要好的多,因为根据数据中心化会让每组数据接近平均值,第一个激活函数的平均值是0.5而第二个是0,所以第二个更好。另外我几乎不会再用第一个了因为tanh函数几乎在所有地方都比它要好但除了输出层,因为输出层就是要输出0到1之间的数。所以我们在隐藏层里用tanh函数,在输出层中用第一个隐藏函数。

但这两个激活函数有共同点缺点,当Z过大或者过小时就会导致这个函数的斜率特别小甚至是接近0。
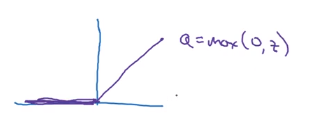
在机器学习中最受欢迎的模型是修正线性单元(ReLU)(如下图),只要z为正数,导数就是1,当z为负数时导数就是0
在选择激活函数时有一条经验:当你想要输出的值是0或1,或在做二分类问题那么第一个激活函数就比较适合,让后其他单元都用ReLU,现在已经变成激活函数的默认选择了,如果你不确定隐藏层用哪个,那就用ReLU作为激活函数。而ReLU函数的缺点是当z为负数时,导数等于0,但还有带泄露ReLU就是当负值时会呈现均匀下降的趋势。ReLU和带泄露ReLU的优点在于对于很多z空间激活函数的导数和0相差很远,所以不会减慢学习速度,所以用ReLU比用一开始的两个函数快的多。
最后总结

第一个只会用于二分类问题
第二个在几乎所有地方都比第一个好
第三个当你在不知道用什么的时候用,第四个也一样
第三个的公式是:a=max(0,z);第四个的公式是:a=max(0.01z,z)
P31 为什么需要非线性激活函数?
假如不用激活函数,那么神经网络只是把输入线性组合再输出,如下图所示,但我们要输出的y还必须是个实数。


由此可见我们必须要加入非线性激活函数,其中隐藏层用线性激活函数是很少见的,可以是tanh、ReLU、带泄露的ReLU等,输出层才能用到非线性激活函数同样也可以用ReLU函数等
P32 激活函数的导数
1、logistic回归函数
下图就是logistic回归函数的图像已经表达式
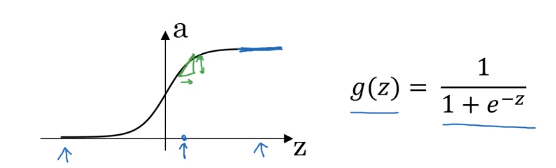
它的导数是

2、tanh函数
图像以及表达式

导数
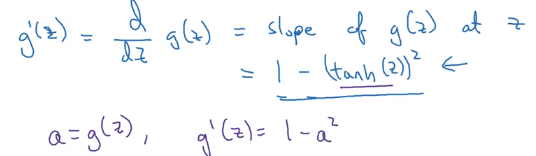
3.ReLU
图像

导数
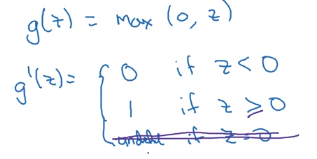
在数学的角度上:当z=0时因为是尖点所以没有导数。但在Python中当z=0时,你可以写代码来让导数等于任何值在这先等于1(由于z=0的可能性很小,所以把导数设成那个值都可以)
4、带泄露ReLU
图像

导数(当z=0时,情况和上面一样)、
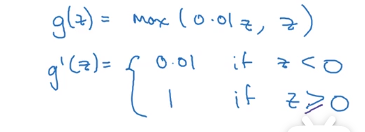
P33 神经网络的梯度下降法
我们在这里用二分法举例
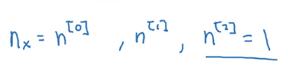
上面三个n 指的是有n[0]个输入单元、n[1]个隐藏单元、n[2]个输出单元并且我们只见过输出单元=1
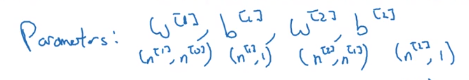
上图说的是每个矩阵的维度是多少
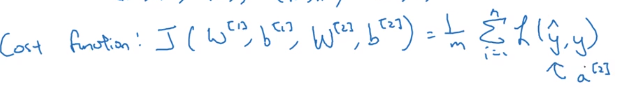
上图说的是我们的成本函数是多少,其中L表示的是其损失函数是什么。
所以要训练参数,你的算法要做梯度下降,在训练神经网络时 随机初始化参数很重要而不是初始化成全零,当你把参数初始化成某些值之后每个梯度下降循环都会计算预测值,所以你要计算i=1—m的预测值yhat让后要计算偏导数dw[1](成本函数对参数w[1]的导数)、db[1](成本函数对参数d[1]的导数)、dw[2]、db[2]
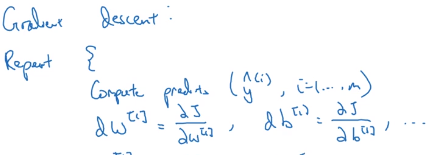
然后梯度下降会更新这四个导数(举了两个例子)其中这个例子中用=或:=都可以
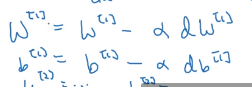
所以这是梯度下降的以此迭代循环,然后你重复这些步骤很多次,直到你的参数看起来在收敛。
先说下正向传播(从左到右传播)
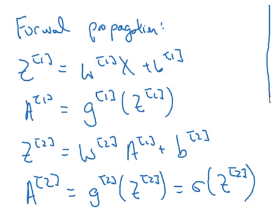
接下来我们来做反向传播(也是求导数)
最后一行是 db[2]=1/m np.sum(dz[2],axis=1,keepdims=True),其中np.sum是Python中numpy命令,用来对矩阵的一个维度求和的,水平相加求和 而加上开关keepdims 就是防止python直接输出这些古怪的秩为1的数组,它的维度是(n,)所以加上keepdims=True,确保Python输出的是矩阵 对于db[2]这个向量输出的维度是(n,1)

其中这个“ * ”是逐个元素乘积,在这里是让(n[1],m)的矩阵和(n[1],m)的矩阵逐元素乘积。
P34(选修)直观理解反向传播
1、关于Logistic回归

关于反向传播:da、dz、dw、db。的公式如图所示。我们不想优化x至少是对监督学习来说,所以我们不求x的导数
简化图是
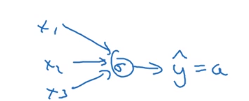
就是说中间没有隐藏层,只有输入层与输出层。
2、关于双层神经网络

我们总结六个重要的公式

把上面的公式向量化

P35 随机初始化
随机初始化很重要,logistic回归中初始化是0,但在神经网络中如果把其各项参数数组全都初始化成0,就会使梯度下降法无效
给b设置成0,没有太大关系。但当w设置成0时就会出现a_1[1]与a_2[1]是一样的,因为a[1]和a[2]是做一样的运算,不止是第一个隐藏层,所有的隐藏层都在做同样的运算,也就是说所有的隐藏层都没有用了。所以我们要进行随机初始化!!!
做法:w[1]=np.random.randn 再乘上一个很小的数(当时单隐藏层时可以用0.01,但当神经网络太过于复杂就要用更小的常数) b[1]=np.zero((2,1)) 其他的看下图
这可以产生参数为(2,2)的高斯分布随机变量。乘上很小的数是为了将权重初始化成很小的随机数,特别是有logistic回归激活函数和tanh激活函数时,要小。
然后关于b 只要w是随机初始化 b就可以是0 。
















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









