







OpenAI o1技术报告《Learning to reason with LLMs》,中文标题翻译为:《让语言大模型学会推理》
1. 摘要
OpenAI o1,这是一种新的大型语言模型,经过强化学习训练,可以执行复杂的推理。o1在回答之前会思考——在响应用户之前,它可以产生一个很长的内部思维链。
OpenAI的o1模型在多个领域展示了卓越的性能:
- 在竞争性编程问题(Codeforces)中,o1位于第89百分位。
- 在美国数学奥林匹克资格赛(AIME 2024)中,o1的表现足以让其跻身美国前500名学生之列。
- 在涵盖物理、生物和化学问题的博士级准确度基准测试(GPQA Diamond)中,o1超过了人类博士水平的准确性。
2. 成果
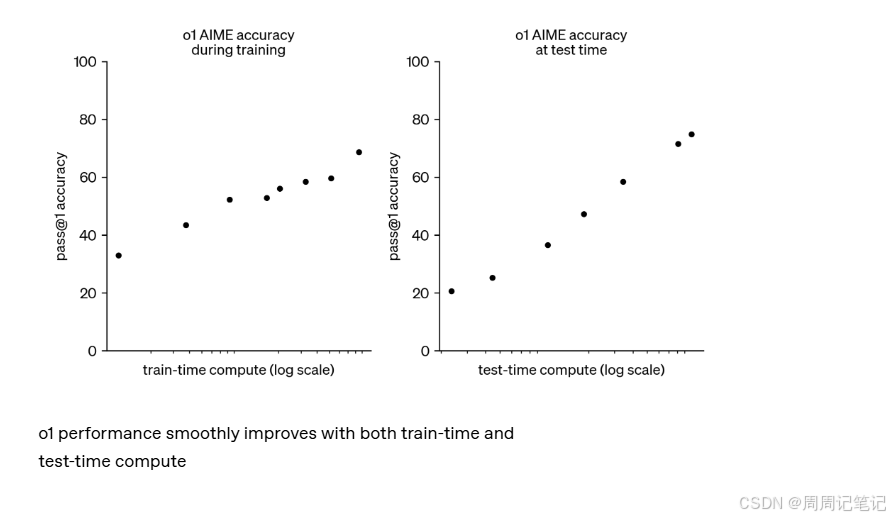
2.1 随着更多的强化学习(即训练计算资源的增加)和更多时间用于“思考”(即测试时计算资源的增加),o1的性能会持续提升。
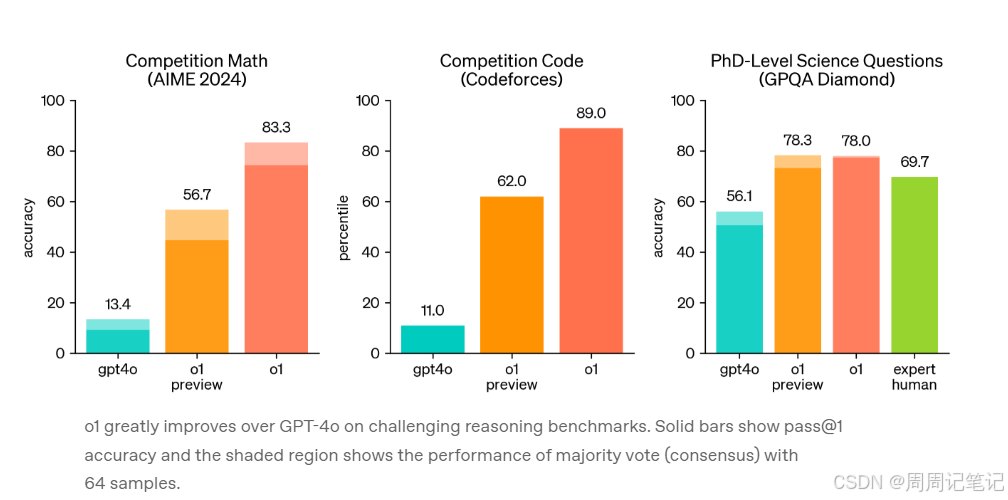
2.2 在o1模型与GPT-4o之间进行比较。结果显示,在绝大多数需要强推理能力的任务上,o1的表现显著优于GPT-4o。这表明o1在处理复杂、需要深入分析的问题方面具有优势。
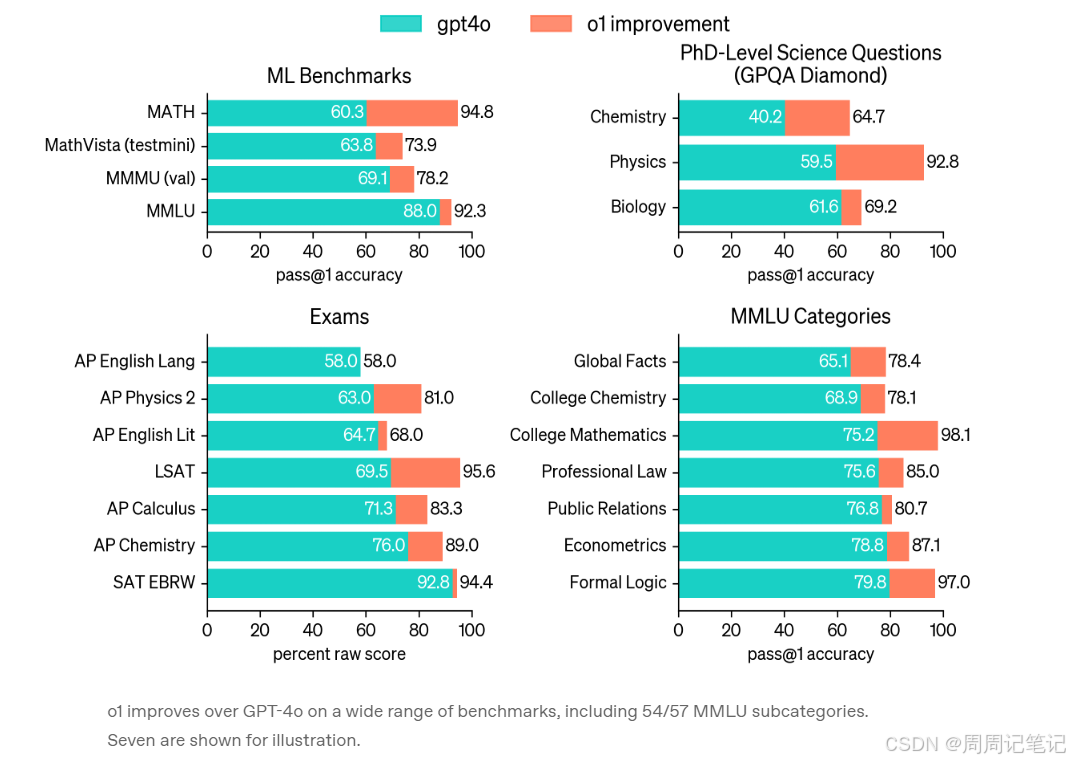
2.3 在许多需要大量推理的基准测试中,o1 的表现可以与人类专家相媲美。
(1)数学能力测试
为了评估数学能力,选择了旨在挑战美国最优秀高中生的AIME考试。2024年的AIME考试结果如下:
- GPT-4o平均仅能解决12%(1.8/15)的问题。
- o1单样本尝试时平均解决了74%(11.1/15)的问题。
- 当使用64个样本达成共识时,准确率提升至83%(12.5/15)。
- 使用学习到的评分函数对1000个样本进行重新排序后,准确率高达93%(13.9/15)。
得分13.9不仅让o1的成绩跻身全国前500名学生之列,还超过了参加美国数学奥林匹克竞赛的分数线。
(2)GPQA钻石级别测试
这是一个难度极高的智能基准测试,旨在评估化学、物理和生物学方面的专业知识。为了进行有效对比,OpenAI邀请了拥有博士学位的专家回答GPQA-钻石级别的问题。结果发现,o1的表现超越了这些人类专家,成为首个在此基准上实现这一成就的模型。需要注意的是,这并不意味着o1在所有方面都优于拥有博士学位的专家,而是在解决某些预期由博士水平人士解决的问题时更为熟练。
(3)Coding水平
结果突显了通过特定领域的训练和优化策略,AI模型可以在复杂编程任务中达到甚至超过顶级人类选手的表现。
重点内容:
-
IOI 2024成绩:初始化自o1并通过额外训练以提升编程能力的模型,在2024年的IOI中得分213分,排名位于第49百分位。该模型与人类参赛者在相同的条件下进行比赛,即有十小时解决六个复杂的算法问题,并且每个问题允许提交50次。
-
提交策略:对于每个问题,系统会生成多个候选提交方案,并根据测试时的选择策略选出50个提交。选择依据包括IOI公开测试案例的表现、模型生成的测试案例以及一个学习到的评分函数。如果采用随机提交的方式,平均得分仅为156分,表明所使用的策略在比赛限制下价值近60分。
-
放宽提交限制的影响:当每个问题的提交次数增加至10,000次时,即使没有使用任何测试时选择策略,模型的得分也达到了362.14分,超过了金牌分数线。
-
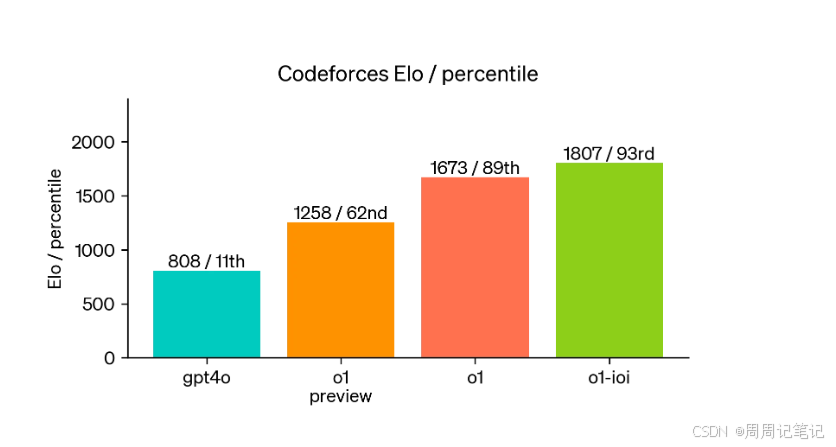
Codeforces模拟赛表现:为了展示该模型的编程技能,还在Codeforces举办的模拟编程比赛中进行了评估。遵循竞赛规则并允许10次提交的情况下,GPT-4o的Elo评分为808,位于人类竞争者的第11百分位。而基于o1改进的模型获得了1807的Elo评分,超越了93%的竞争者。
(4)其他水平
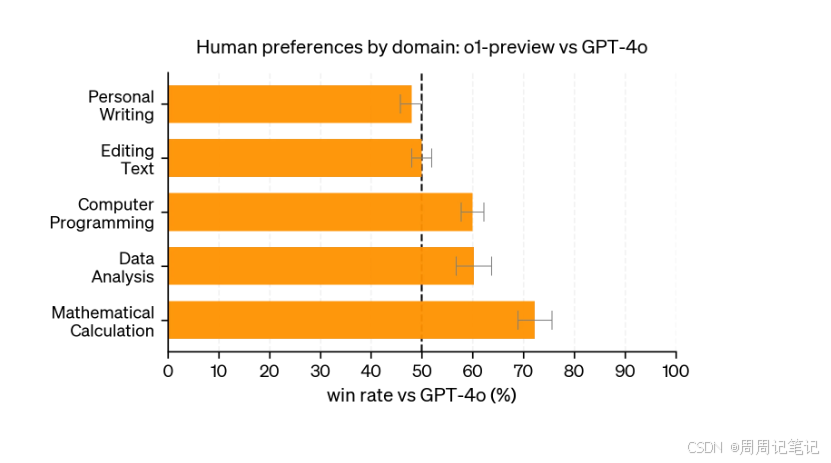
人类训练师被展示来自o1-preview和GPT-4o的匿名响应,针对具有挑战性的开放式提示进行投票,选择他们更偏好的响应。
在需要强推理能力的类别中,如数据分析、编程和数学,o1-preview相比GPT-4o获得了更大的偏好优势。
然而,在某些自然语言处理任务上,o1-preview并不受到偏好,这表明它可能不适合所有类型的使用场景。
3. Chain of Thought-思考链
(1)思维链机制:类似于人类在回答难题前会进行长时间思考,o1在尝试解决问题时也会使用一种“思维链”。这意味着模型能够生成一系列逻辑步骤,以系统地处理和解决复杂问题。
(2)强化学习的作用:通过强化学习,o1学会了优化其思维链并改进所使用的策略。它能够学会识别和纠正错误,将复杂的步骤分解为更简单的部分,并在当前方法不奏效时尝试不同的解决途径。这一过程显著提升了模型的推理能力。
4. 重点
Reinforcement Learning — 强化学习
It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. (它学会识别并纠正自己的错误,学会将复杂的步骤分解为更简单的步骤,学会在当前方法行不通时尝试不同的解决途径。)这些是模型自己学的,不是人教的。
5. 拓展:
- OpenAI研究员Hyung Won Chung在MIT的讲座Don't teach. Incentivize.
- OpenAI前首席科学家Ilya Sutskever早期关于强化学习的讲座 Meta-Learning and Self-Play



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









