






在浏览器中复制到的xpath丢入html.xpath中无法获取到相应的标签,我复制的路径为:/html/body/div[2]/div/div/div[3]/div/div[4]/。由下图可知我需要的在第二个div中,所以用div[2]没错,但是没有获得数据。
当我将div[2]改为div[1]的时候,获得了数据。猜测原因是第一个div是hidden状态。
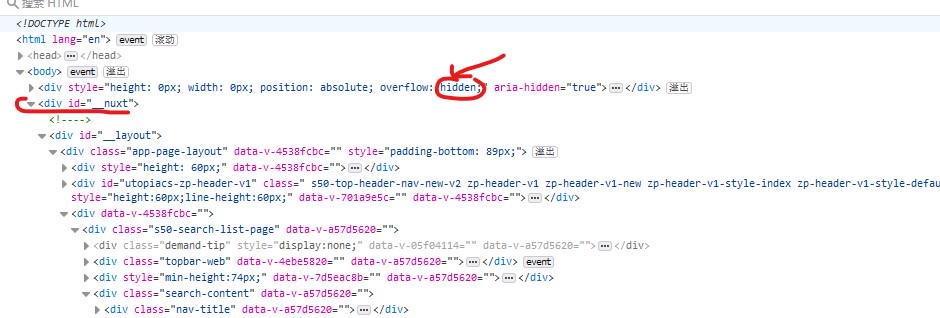
当然也有遇到是本身复制的xpath出现了一些问题,有的浏览器会自动加上一些标签,很可恶。所以检查一下要是没有问题就换成bs4,或者正则表达式也可以。















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









