






 本文介绍了监督学习中的线性回归模型,通过预测房价实例说明如何利用平方误差函数作为代价函数。重点讲解了梯度下降法在优化代价函数中的应用,以及学习率对算法性能的影响。
本文介绍了监督学习中的线性回归模型,通过预测房价实例说明如何利用平方误差函数作为代价函数。重点讲解了梯度下降法在优化代价函数中的应用,以及学习率对算法性能的影响。
前言
我们第一个学习算法是线性回归,让我们一起具体看看模型和具体的监督学习过程。
一、监督学习-回归-预测房价
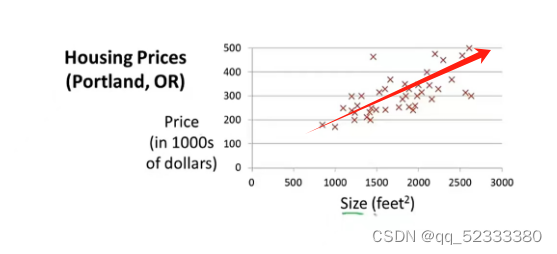
如上图横轴是房子的面积,纵轴是房价,假设你需要卖出一套1250平方英尺的房子你可以通过已知数据集进行模型拟合,如图这组数据可以用一条直线拟合,你就可以大概知道你的房子大概可以卖220,000美元
m=number of training examples 训练样本的数量
x’s=input variable/features 输入变量/特征
y’s=output variable/target variable 输出变量/预测的目标变量
(x,y)代表一个训练样本
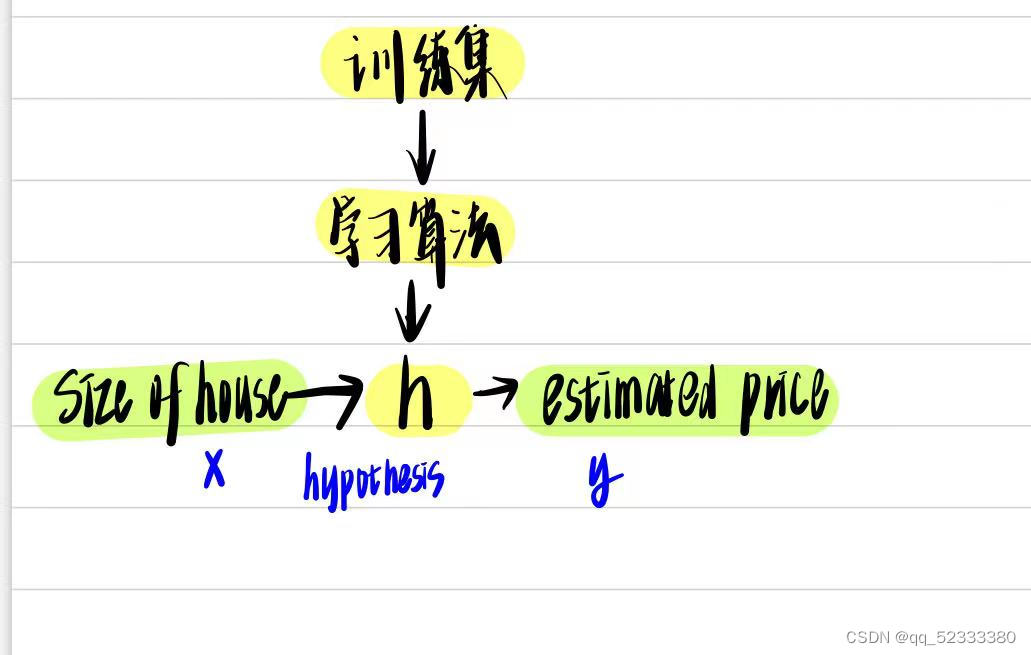
这里的h就是拟合函数,在这个例子里就是一个单变量线性回归函数
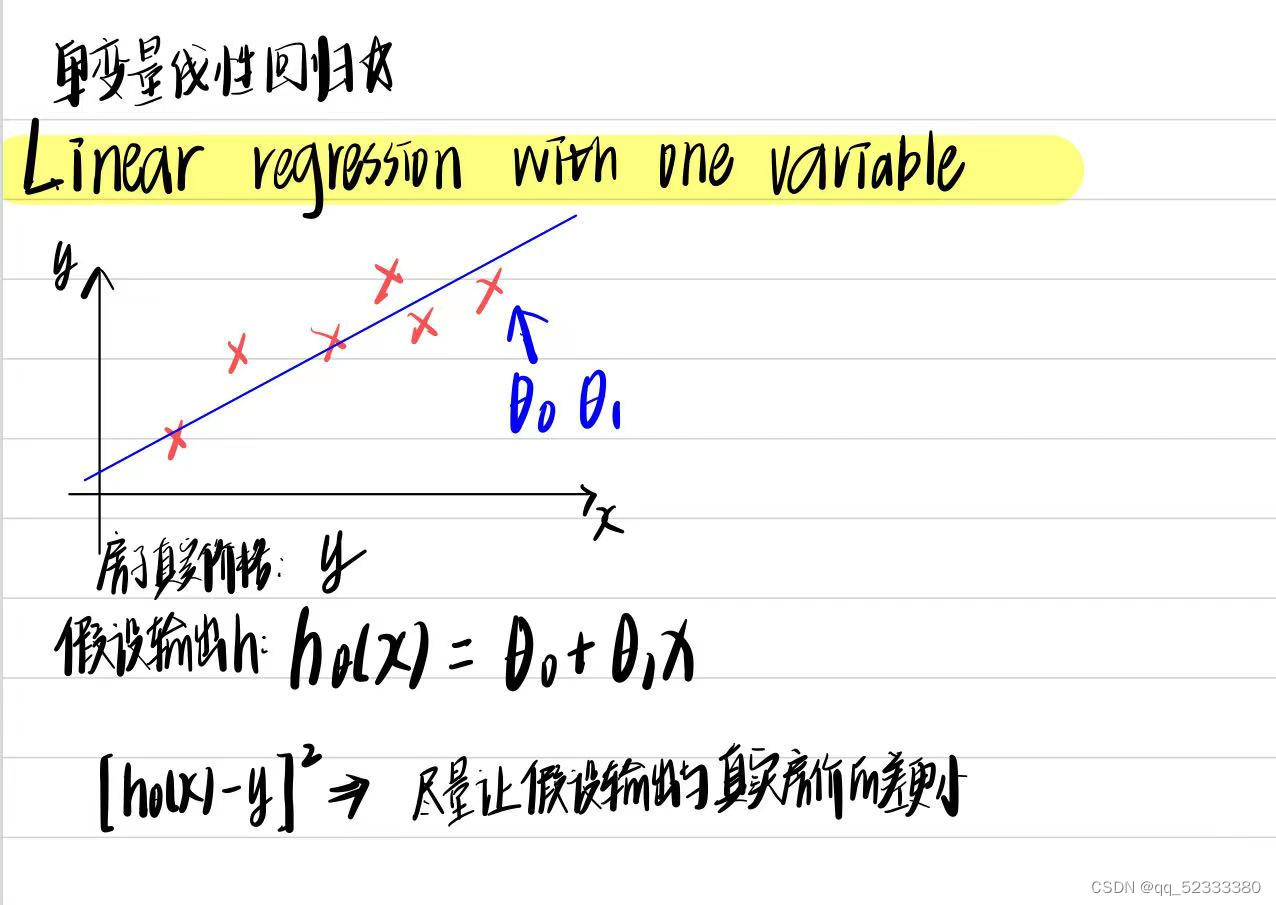
然后我们对所有训练样本进行一个[h(x)-y](预测值和实际值的差)的平方的求和,求和值最小的即为最拟合的函数

这个平方误差函数即为代价函数(square error cost function),平方误差代价函数是解决回归问题最常用的手段
二、代价函数
我们需要理解这两个问题
what the cost function is doing ?
why we want to use it?
来找到一条最符合数据的直线

以下这个简化的例子可以帮助你更好的理解
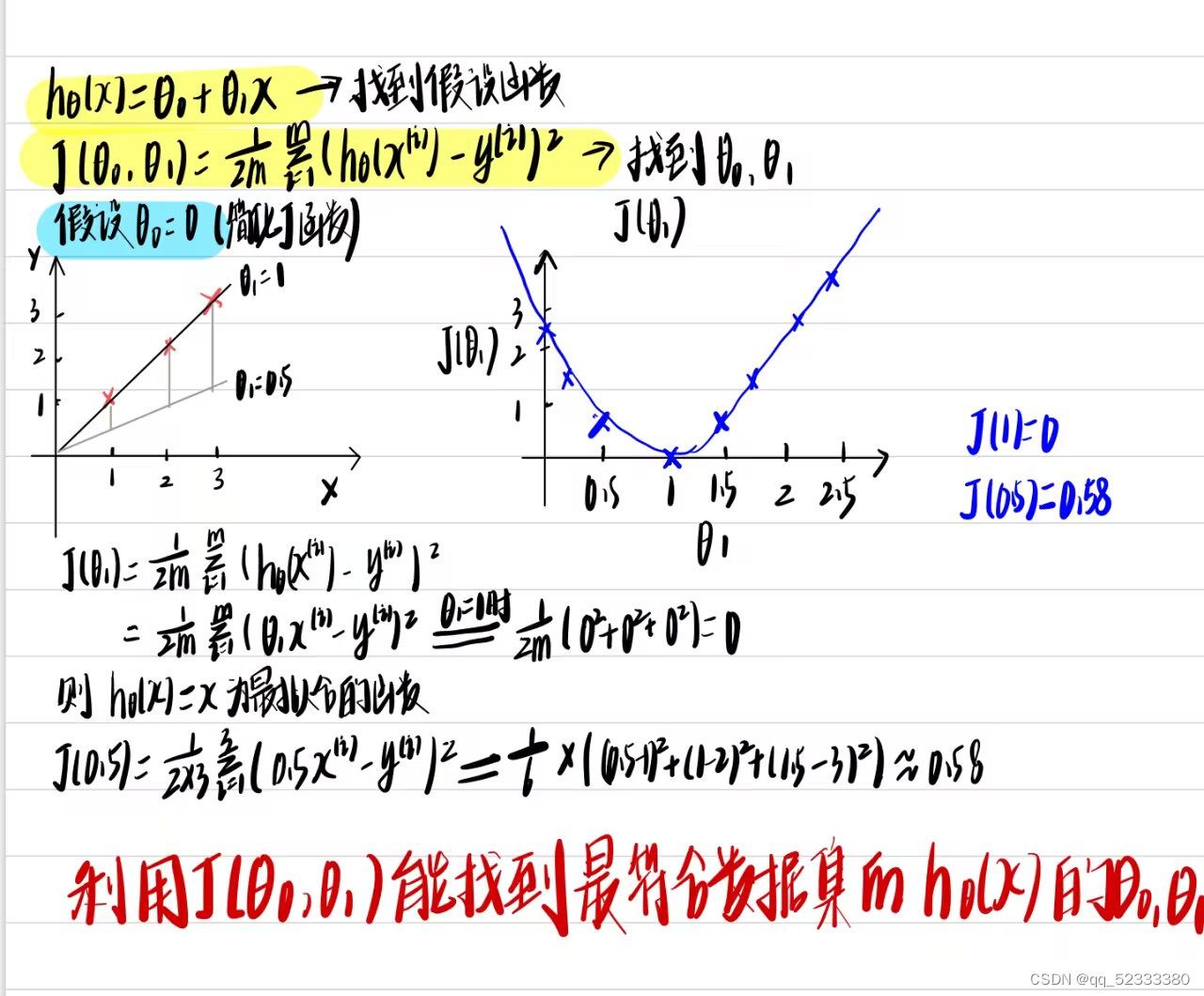
如果不对假设函数进行简化,那么对应的代价函数的图像则为一个3D的碗装,我们通过下面的例子来理解
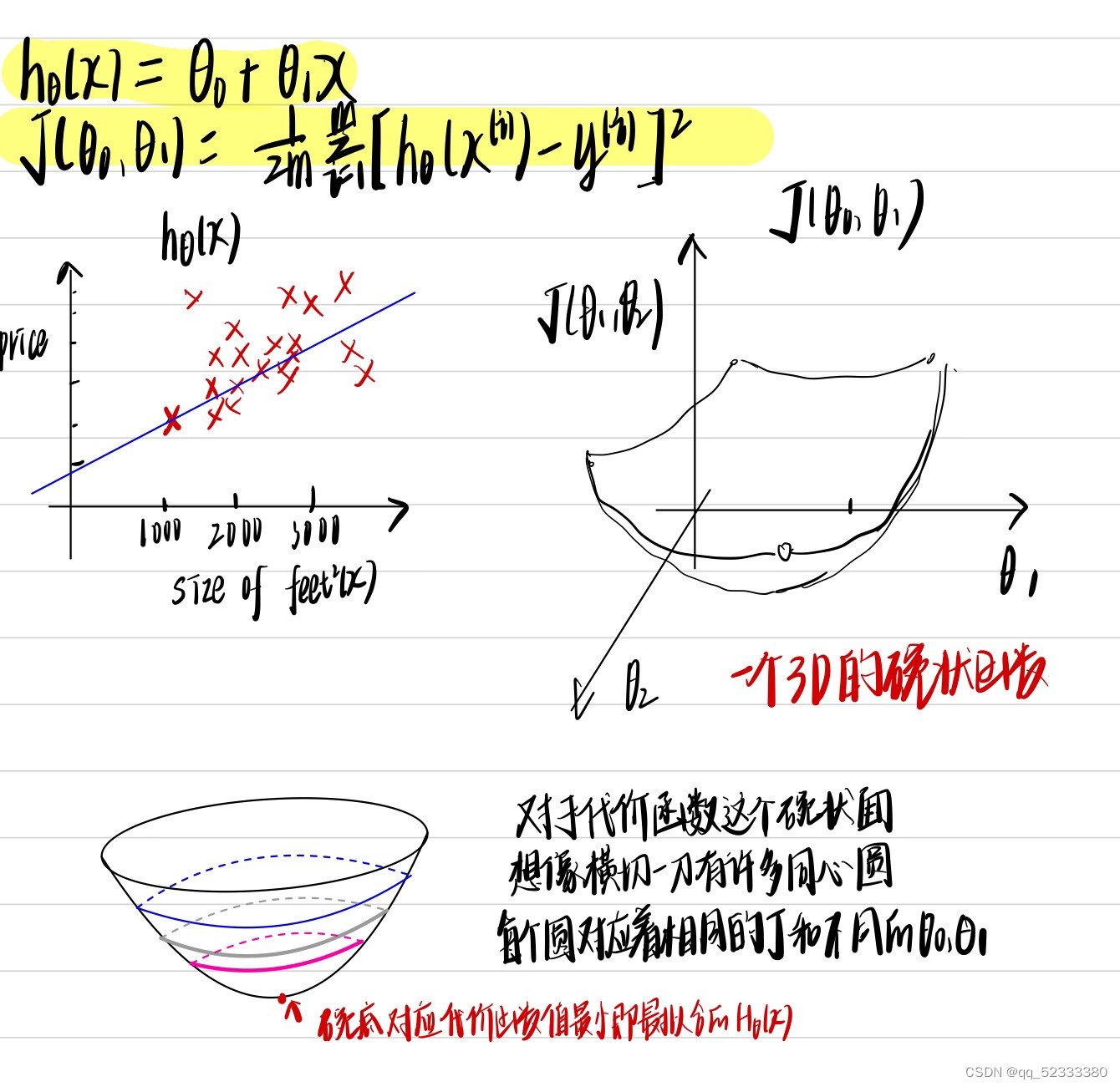
接下来的问题就是,如何找到代价函数最低的点呢???
这就涉及梯度下降法
三.梯度下降法(gradient descent)
梯度下降不仅仅应用于线性回归,也广泛应用于机器学习的众多领域。
此处我们讨论用梯度下降法最小化代价函数J(senta0,senta1)
思路:1.start with senta0 and senta1(一般都初始化为0)
2.keep changing senta0 and senta1 to reduce J(senta0,senta1)until
we hopefully end up at a minimum

梯度下降法有一个有趣的特点,第一次使用梯度下降法我们是从任意一个点A开始,找到了局部最优解B,但是假如你从另外一个完全不同的点C开始找局部最优解,那么你将获得一个完全不同的局部最优解D。

上图的α,和下图的η都表示学习率-learning rate,用来控制我们梯度下降时迈出多大的步子
举个例子
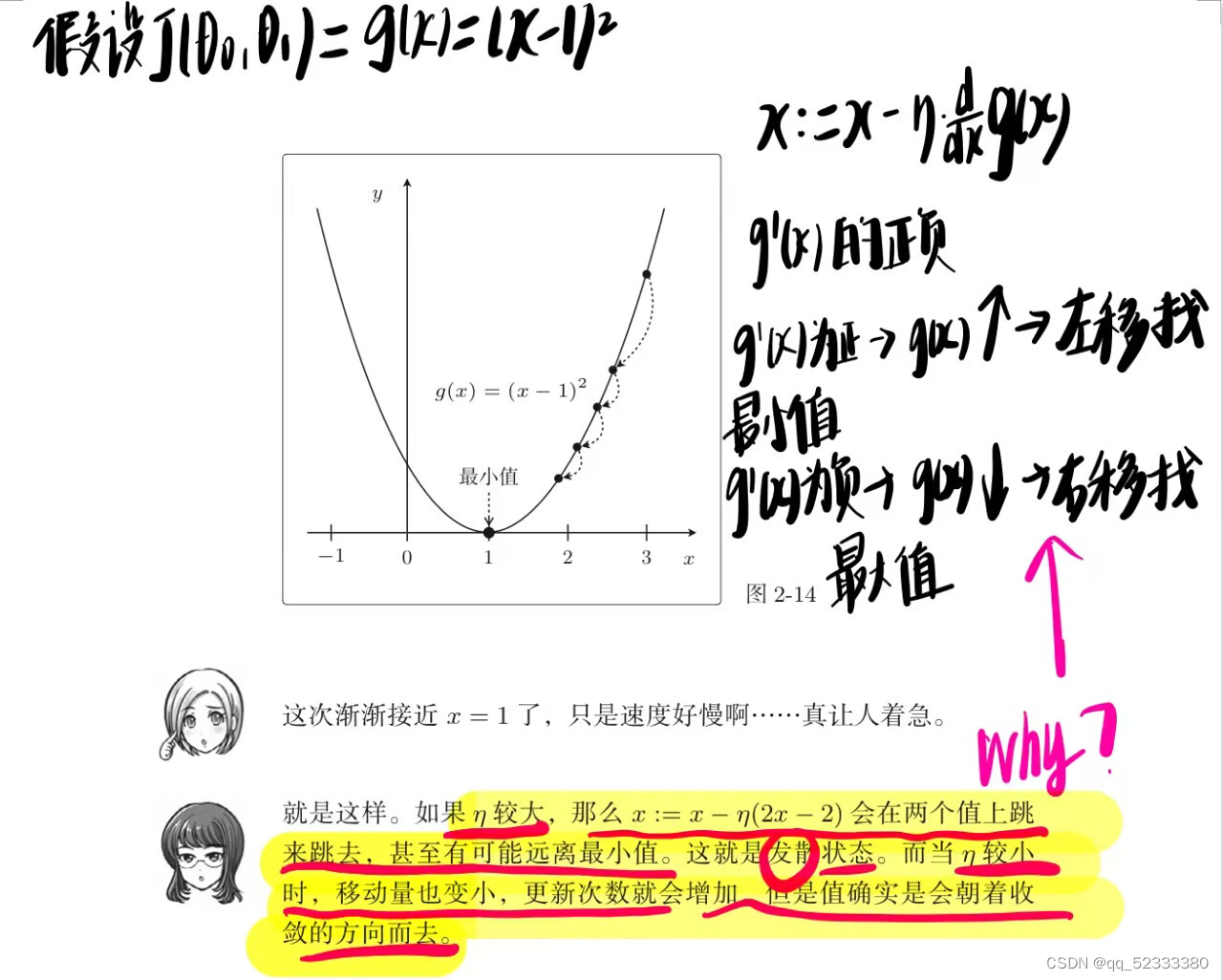
如果我们的学习率太小,可能要很多步才能到最低点,如果学习率很大,迈出很大一部可能离最低点越来越远,总是跨过了。加入已经在局部最低点,那么导数项为0,局部最低值不会变。
总结
必须掌握的线性回归模型和平方差代价函数。线性回归模型包括线性假设和平方差代价函数。我们将梯度下降法来最小化平方差代价函数,得到了线性回归的算法,他可以用直线来拟合数据
Batch -each step of gradient decent uses all the training examples
Barch梯度下降法全览了整个训练集
线性代数中有正规方程组的方法来求解而不用梯度下降的迭代法来求解,梯度下降法适用于更大的数据集。















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









