






1.安装Hadoop
到官网Apache Hadoop下载与上边的Spark对应的版本,或者下载其他版本的

下载完成后解压到你自定义的目录,然后配置环境变量
- 配置变量名为
HADOOP_HOME,值为D:\Hadoop\hadoop-3.1.3 - 在
Path变量下新建%HADOOP_HOME%\bin
到这个链接:GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows

下载对应版本的bin目录下载hadoop.dll和winutils.exe,复制到hadoop目录的bin目录下

检查安装是否成功:win+r, 打开cmd,输入如下命令
hadoop version

显示版本即为安装成功!
2.安装Spark
到官网Downloads | Apache Spark选择合适的版本下载,注意Spark与Hadoop版本选择要相对应,建议下载预编译(Pre-built)好的版本,省得麻烦

下载完成后解压到你自定义的目录,然后配置环境变量:
- 配置变量名为
SPARK_HOME,值为D:\Spark\spark-3.0.0-bin-hadoop3.2 - 在
Path变量下新建%SPARK_HOME%\bin
3.IDEA测试Spark开发
这里还需要下载一个Scala的框架,右键点击项目,然后选择第二行添加框架支持

打开项目结构,添加Spark的jar到模块中:
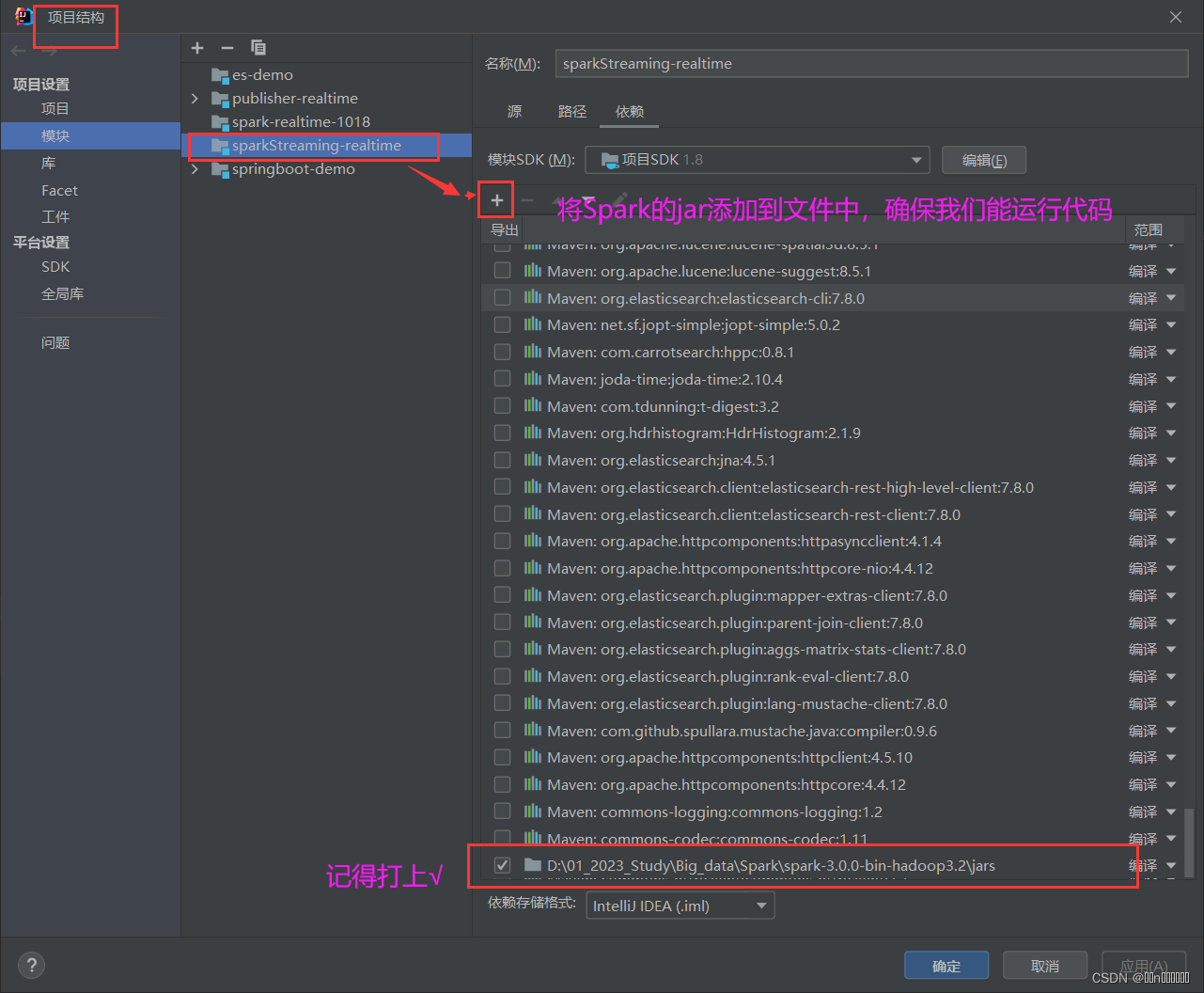
然后创建一个包,写如下代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TmoonTest {
def main(args: Array[String]): Unit = {
// new SparkConf()
val sparkConf = new SparkConf().setMaster("local").setAppName("Wordcount")
val sc = new SparkContext(sparkConf)
println("Hello scala");
val lines: RDD[String] = sc.textFile("datas")
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
val wordToCount = wordGroup.map {
case (word, list) => {
(word, list.size)
}
}
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
sc.stop()
}
}再到文件根目录下,创建一个datas 的目录,放入两个文件,用来给我们代码跑:
 文件内容随便写单词。
文件内容随便写单词。
之后就可以愉快的运行代码了。效果如下:

4、Tips 提示
1、如果不想看到这么多的红色日志信息,我们可以在resource文件下配置一下log4j.properties,当然我这里是引入了对应的依赖了,
log4j.appender.atguigu.MyConsole=org.apache.log4j.ConsoleAppender
log4j.appender.atguigu.MyConsole.target=System.out
log4j.appender.atguigu.MyConsole.layout=org.apache.log4j.PatternLayout
log4j.appender.atguigu.MyConsole.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger =error,atguigu.MyConsole2、我是学习硅谷的,大数据Spark实时项目丨Spark Streaming ,在配置过程中也是遇到蛮多的问题,因为这个只是浅浅学习一下,所有有些东西也不是很懂的。
3、如果你也学习这个项目,有什么问题可以一起交流~
4、本文借鉴文章如下:
觉得不错的话,点个赞吧~














 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









