






encoder and decoder
注意力机制
多头注意力机制
自注意力机制
编码器解码器架构
编码器:输入一系列的词n个变成向量z,向量每个元素表示序列的一个词
解码器:得到z,把它变成序列m,得到的长度可以不一样
基本的结构图是这样的。左边编码器右边解码器
每一个作为一个层
N就是有多少个这种层
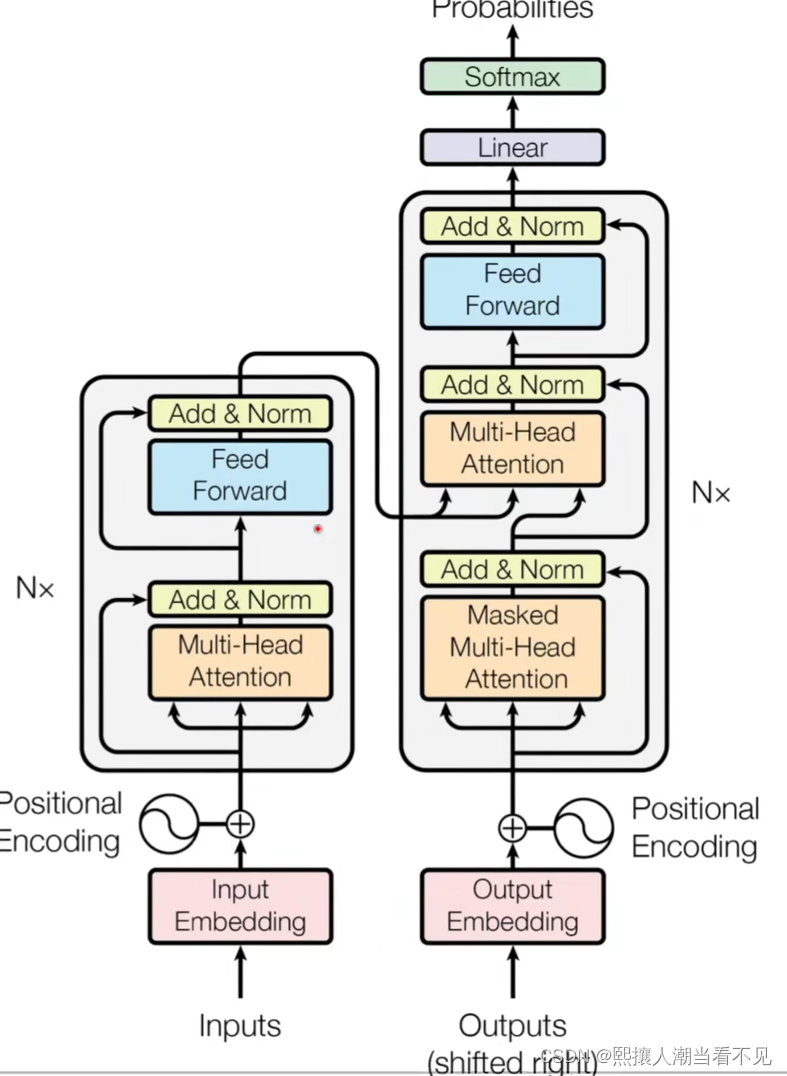
编码器
在transfomer中,N编码器N=6,特征层数d=512
layerNormalization
对每个样本进行变成均值为1,方差为0
BN是对每个特征进行均值为1,方差为0
解码器
有一个带掩码的多头注意力(masked),保证t时刻不会看到t时刻以后的输入
注意力机制
注意力机制是这个
简单理解就是对输入进行一个加权和。
n个词n个向量,每个长度为d,那么attention之后,也是n个d长度的向量(其实就是与其他每个词加权和)
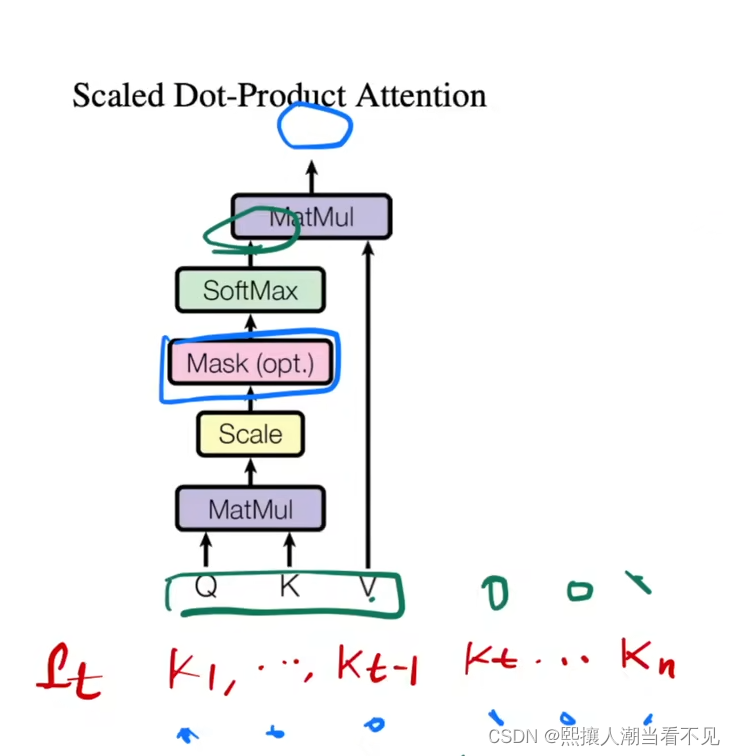
理解加权和:
输入的q、k、v是query(每个词序列)、key值、value,但是其实就是输入的n维d向量,只是作为不同的效果
一个query对应每个时刻的序列,与key(每个时刻的特征)做内积,得到这样的矩阵,然后再每个除以根号dk,然后进行softmax之后(得到每个特征在该时刻的权重)再乘以V,就得到我们输出,每一行就是一个向量。

可以发现,其实query向量,第t时刻对应Qt。Qt会与Key每个值做运算,得到输出的一行
而我们要的是,0~t-1时刻起权重效果,而t之后都不起效果,所以加入了mask,做了一件事,让t时刻之后都乘以了非常小的负数,这样softmax之后t之后权重就变0,t之前继续起效果。
multi -head Attention 多头
把query、key、value都输入进来
对于每一个q,都要和其他k与v计算,最后拼接起来。那么用多个注意力机制,互相进行独立运算。防止过拟合
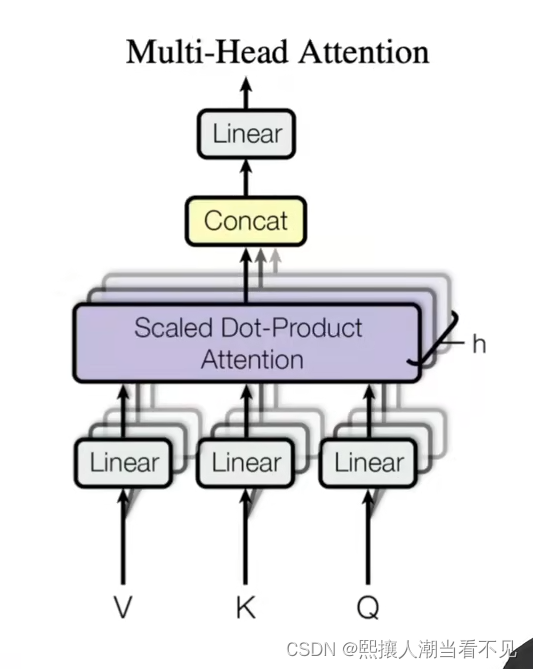
网络结构中的
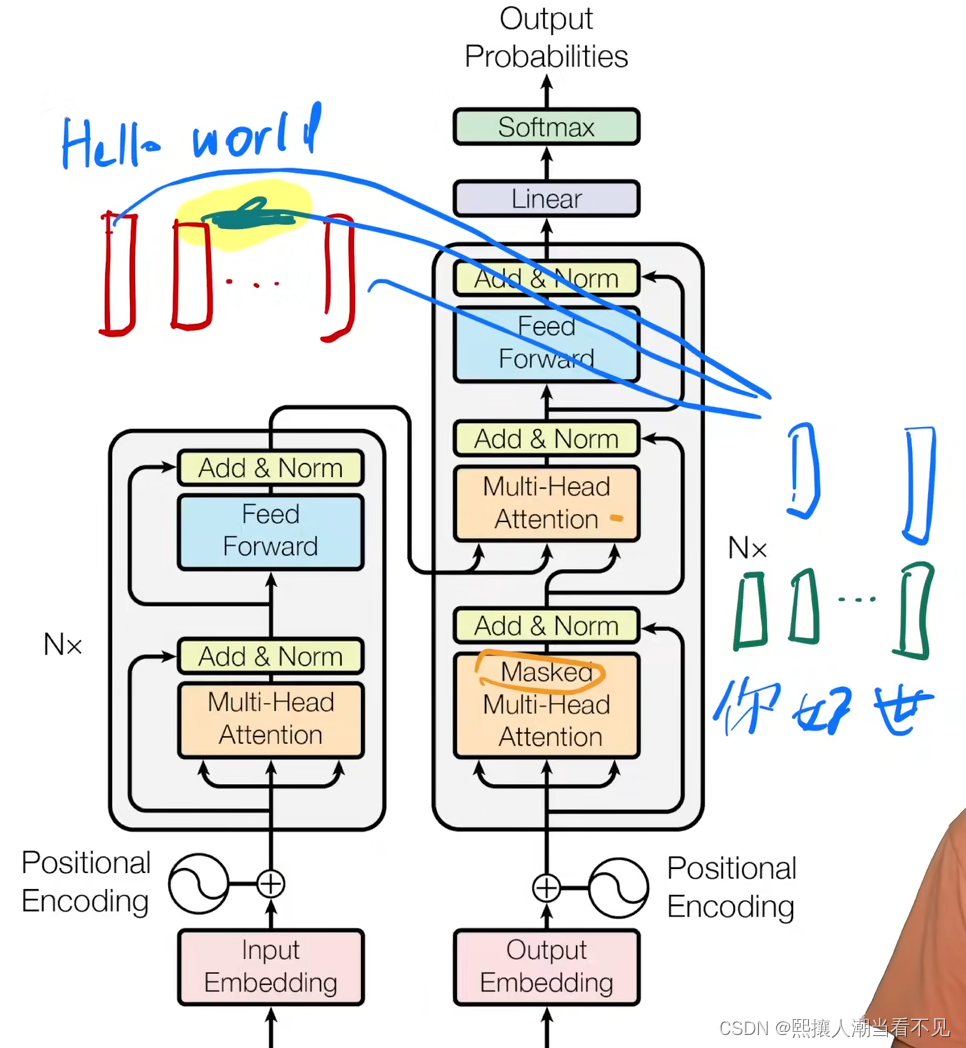
如果输入是n个文字的巨子,那么编码器解码器的输入就是,n个长为d向量
编码器的:输入q、k、v(其实就是个长为d向量分成3份输入进去,每份作不同的效果)经过多注意力机制,得到输出是n个输出。其实就是当前q和其他q之间的匹配度。
解码器的mask:与编码器相同,但是进行mask,也就是第t个q只能算t之前的匹配度,不能算之后的。
最后一个注意力,这里的输入是编码器的n维向量和解码器的n维向量,(作为q、k、v不管,因为他们其实也是向量本身),最后计算编码器和解码器对应的匹配度
position-wise feed forward
就是MLP,n个词,每个词进行一次MLP
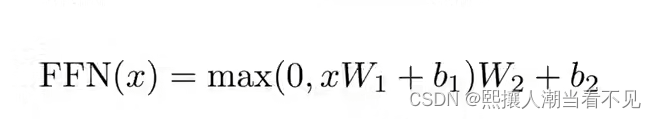
注意力机制得到的d=512,也就是每个q对应的x是512维。W1把512升到2048,W2再降回512。
Embeddings and Softmax
Embeddings把输入的词变成n个d的向量
positional Encoding
attention只会算词之间的关系,不会管顺序,如果一句话顺序打乱,结果也是一样
所以positional Encoding是时序信息















 40万+
40万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









