







编辑器:jupyter notebook
一、数据处理
1.将数据导入数据库
import os
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
# 用户:root
# 密码:root
# 服务器:localhost
# 端口号:3306
# 库名:db
# 指定目录
path = './data'
df = pd.DataFrame() # 存储数据
for i in os.listdir(path):
# 文件路径及名称
name = os.path.join(path, i)
# 单一文件的数据
data = pd.read_excel(name)
# 逐个插入DataFrame
df = df.append(data, ignore_index=True)
df['houseInfo2'] = df['houseInfo2'].fillna('-').str.replace('\s', '')
df.to_sql('house_info', engine, index=False, if_exists='replace')
# The default value of regex will change from True to False in a future version
# 在未来的版本中,正则表达式的默认值将从True更改为False
# house_info 清洗前的表
sql = 'select * from db.house_info'
df = pd.read_sql(sql, con=engine)
df.to_excel('house_info.xlsx', index=False)
df.head()
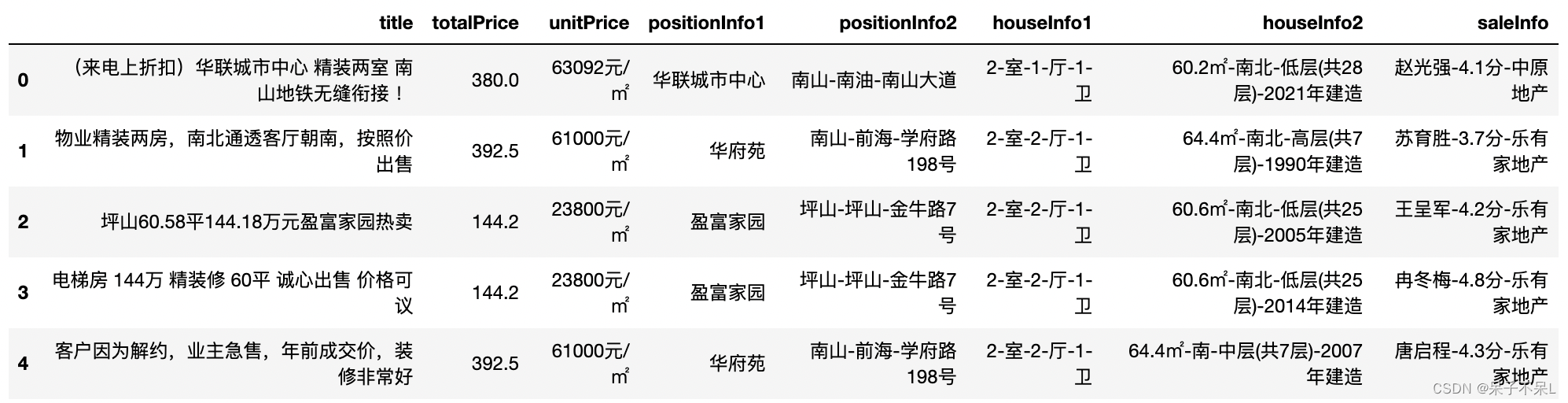
2.数据清洗
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_info', engine)
df.info()
‘’‘
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6000 entries, 0 to 5999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 6000 non-null object
1 totalPrice 6000 non-null float64
2 unitPrice 6000 non-null object
3 positionInfo1 6000 non-null object
4 positionInfo2 6000 non-null object
5 houseInfo1 6000 non-null object
6 houseInfo2 6000 non-null object
7 saleInfo 6000 non-null object
dtypes: float64(1), object(7)
memory usage: 375.1+ KB
’‘’
df.rename({
'title': '标题',
'totalPrice': '总价',
'unitPrice': '单价',
'positionInfo1': '小区',
'houseInfo1': '户型'},
axis=1,
inplace=True)
# 从0开始索引,左闭(含)右开(不含)
df['区域'] = df['positionInfo2'].str[0:2]
# 2-室-1-厅-1-卫
df[['卧室数量', '厅室数量', '卫生间数量']] = df['户型'].str.extract(pat='(\d+)-室-(\d+)-厅-(\d+)-卫', expand=True)
# 60.2㎡-南北-低层(共28层)-2021年建造
df[['面积', '朝向', '楼层信息', '建造信息']] = df['houseInfo2'].str.split(pat='-', expand=True)
# "()"分组匹配,"\"转义,引用括号本身
df[['楼层类型', '总楼层']] = df['楼层信息'].str.extract(pat='(.*?)\(共(\d+)层\)', expand=True)
# \d:匹配数值,数量:{1,}
df['建造年份'] = df['建造信息'].str.extract(pat='(\d+)', expand=True)
df[['销售人员', '服务评分', '地产公司']] = df['saleInfo'].str.split(pat='-', expand=True)
df.drop(
labels=['positionInfo2', 'houseInfo2', 'saleInfo'],
axis=1,
inplace=True)
# 清洗包含字符串单位的字段
df['单价'] = pd.to_numeric(df['单价'].str.replace('元/㎡', '')) # to_numeric 转换为数字格式
df['面积'] = pd.to_numeric(df['面积'].str.replace('㎡', ''))
df['服务评分'] = pd.to_numeric(df['服务评分'].str.replace('分', ''), errors='coerce') # errors='coerce' 异常数据返回空值
df['卧室数量'] = pd.to_numeric(df['卧室数量'])
df['厅室数量'] = pd.to_numeric(df['厅室数量'])
df['卫生间数量'] = pd.to_numeric(df['卫生间数量'])
df['总楼层'] = pd.to_numeric(df['总楼层'])
# 空值处理:forward向前填充, backward向后填充
# 服务评分(均值填充)
df['总楼层'].fillna(method='bfill', inplace=True)
df['楼层信息'].fillna(method='bfill', inplace=True)
df['建造信息'].fillna(method='bfill', inplace=True)
df['楼层类型'].fillna(method='bfill', inplace=True)
df['建造年份'].fillna(method='bfill', inplace=True)
df['地产公司'].fillna(method='bfill', inplace=True)
df['服务评分'].fillna(value=df['服务评分'].mean(), inplace=True)
df['总楼层'] = df['总楼层'].astype(int)
df['建造年份'] = df['建造年份'].astype(int)
# 查看某列的唯一值
df['区域'].unique()
'''
array(['南山', '坪山', '龙岗', '龙华', '福田', '大鹏', '宝安', '深圳', '罗湖', '布吉', '光明',
'盐田'], dtype=object)
'''
# 或 set(df['区域'])
df = df[~(df['区域'] == '深圳')]
df['区域'].unique()
‘’‘
array(['南山', '坪山', '龙岗', '龙华', '福田', '大鹏', '宝安', '罗湖', '布吉', '光明', '盐田'],
dtype=object)
’‘’
df.to_sql('house_data', engine, index=False, if_exists='replace')
# house_data 清洗后的表
sql = 'select * from db.house_data'
df = pd.read_sql(sql, con=engine)
df.to_excel('house_data.xlsx', index=False)
df.head()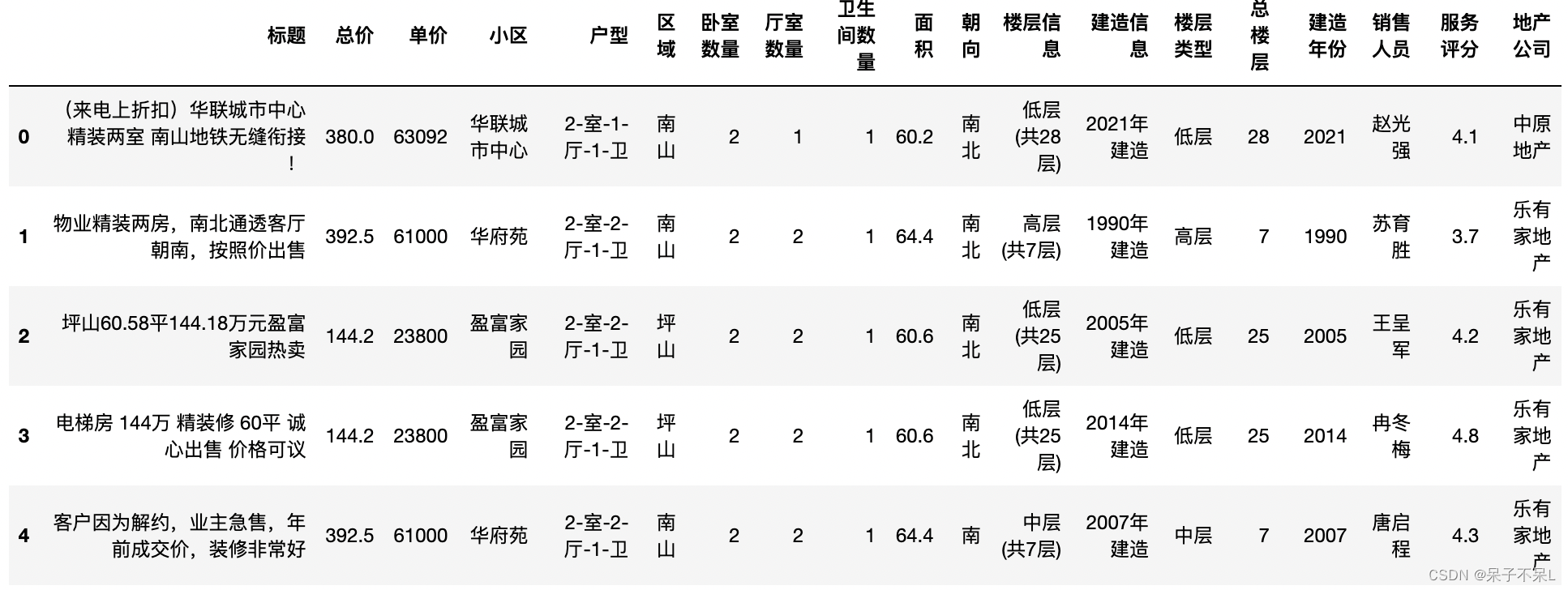
二、配置静态资源服务
1.获取 pyecharts-assets 项目
下载链接:GitHub - pyecharts/pyecharts-assets: 🗂 All assets in pyecharts
下载 pyecharts-assets.zip 压缩包
2.安装扩展插件
1)解压 pyecharts-assets.rar ,将解压文件放到任意的目录中
2)在 pyecharts-assets 中开启终端 或 终端进入pyecharts-assets,如:cd pyecharts-assets
3)终端中依次运行:
jupyter nbextension install assets
jupyter nbextension enable assets/main
4)配置 pyecharts 全局 HOST
# 只需要在顶部声明 CurrentConfig.ONLINE_HOST 即可
from pyecharts.globals import CurrentConfig, OnlineHostType
# OnlineHostType.NOTEBOOK_HOST 默认值为 http://localhost:8888/nbextensions/assets/
CurrentConfig.ONLINE_HOST = OnlineHostType.NOTEBOOK_HOST
# 接下来所有图形的静态资源文件都会来自刚启动的服务器
from pyecharts.charts import Bar
bar = Bar()三、折线图
# pyechats 官网:https://pyecharts.org/
# 图表示例网:https://gallery.pyecharts.org/
# 解压pyecharts-assets.rar
# 复制至某目录下,自定义目录
# pyecharts-assets目录下运行cmd
# 安装并激活插件
# jupyter nbextension install assets
# jupyter nbextension enable assets/main
from pyecharts.globals import CurrentConfig, OnlineHostType
CurrentConfig.ONLINE_HOST = OnlineHostType.NOTEBOOK_HOST
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
df.head()
以建造年份分组,求单价的均值,并绘制折线图
tb = df.groupby('建造年份').agg({'单价': 'mean'}).reset_index()
tb['单价'] = tb['单价'].astype(int)
# tb['单价'] = np.round(tb['单价'], 0)
x, y = tb['建造年份'], tb['单价']
line = Line(
init_opts=opts.InitOpts( # 设置画布
width='900px',
height='500px',
theme=ThemeType.DARK),
)
line.add_xaxis(x)
line.add_yaxis(
series_name='房价',
y_axis=y,
# 是否显示数据标签
label_opts=opts.LabelOpts(is_show=False),
# 是否平滑曲线
is_smooth=True,
# 阴影面积
areastyle_opts=opts.AreaStyleOpts(
opacity=0.5, # 透明度
),
# 标记点
markpoint_opts=opts.MarkPointOpts(
data=[{'type':'max','name':'最大值'},{'type':'min','name':'最小值'}]
),
# 标记线
markline_opts=opts.MarkLineOpts(
data=[{'type':'average','name':'平均值'}],
precision=0,
)
)
line.set_global_opts(
xaxis_opts=opts.AxisOpts(
name='建造年份',
type_='category'
),
yaxis_opts=opts.AxisOpts(
name='房价',
type_='value'
)
)
line.render_notebook()
# 只能将图片保存为网页形式
line.render('./图片/折线图.html')四、柱状图
以区域分组,求单价的均值,并绘制柱形图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
tb1 = (df.groupby('区域')
.agg({'单价': 'mean'})
.sort_values(by='单价', ascending=False)
.reset_index())
tb1['单价'] = tb1['单价'].astype(int)
# XY轴为列表
x, y = list(tb1['区域']), list(tb1['单价'])
# x, y = tb1['区域'].tolist(), tb1['单价'].tolist()
bar = Bar()
bar.add_xaxis(x)
bar.add_yaxis('房价',y)
bar.set_global_opts(
title_opts=opts.TitleOpts(title='各区均价'),
datazoom_opts=opts.DataZoomOpts(),
graphic_opts=opts.GraphicText(
graphic_item=opts.GraphicItem(
top='10%',
left='40%',
),
graphic_textstyle_opts={'text':'坚持每天学习一点技术,离买汤臣一品就更进一步'},
)
)
bar.render_notebook()

五、饼状图
以区域分组,求房源数量,并绘制饼状图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 数据结构要求:
# [['龙华', 1034],
# ['罗湖', 1027],
# ['宝安', 823],
# ['龙岗', 810],
# ['南山', 604],
# ['布吉', 468],
# ['福田', 393],
# ['坪山', 281],
# ['光明', 130],
# ['盐田', 125],
# ['大鹏', 63]]
tb = (df.groupby('区域')
.agg(房源数量=('标题', 'count'))
.sort_values(by='房源数量', ascending=False)
.reset_index())
# Series.tolist()
# DataFrame.values.tolist()
# data = [list(z) for z in zip(tb['区域'], tb['房源数量'])]
data = tb[['区域', '房源数量']].values.tolist()
pie = Pie()
pie.add('房源数量',data)
pie.set_global_opts(
title_opts=opts.TitleOpts(title='各区房源数量'),
legend_opts=opts.LegendOpts(
pos_left='left',
pos_top='middle',
orient='vertical',
)
)
pie.render_notebook()
六、玫瑰图
- 以户型分区,求房源数量,并绘制玫瑰图
- 提取卧室-厅室,剔除卫室,如2-室-1-厅
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
df['户型'] = df['户型'].str[0:7]
tb = (df.groupby('户型')
.agg(房源数量=('标题', 'count'))
.sort_values(by='房源数量', ascending=False)
.reset_index())
data = tb[['户型', '房源数量']].values.tolist()
# data = [list(z) for z in zip(tb['户型'], tb['房源数量'])]
pie = Pie()
pie.add(
'房源数量',
data,
radius=['30%','70%'], # 内外圆半径
# 玫瑰图类型:半径
rosetype='radius',
# label_opts=opts.LabelOpts(is_show=False), # 不显示数据标签
)
pie.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示数据标签
pie.set_global_opts(
title_opts=opts.TitleOpts(title='户型分布'),
legend_opts=opts.LegendOpts(
pos_right='right', # 靠右
pos_top='middle', # 剧中
orient='vertical', # 垂直显示
)
)
pie.render_notebook()

七、散点图
x轴为面积,y轴为总价,绘制散点图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
tb = df[['面积', '总价']].sort_values(
by=['面积', '总价'],
ascending=[True, True])
x, y = list(tb['面积']), list(tb['总价'])
scatter = Scatter()
scatter.add_xaxis(x)
scatter.add_yaxis('',y,label_opts=opts.LabelOpts(is_show=False))
scatter.set_global_opts(
title_opts=opts.TitleOpts(title='面积与总价的散点图'),
xaxis_opts=opts.AxisOpts(name='面积',type_='value',min_=0),
yaxis_opts=opts.AxisOpts(name='总价',type_='value',min_=0),
visualmap_opts=opts.VisualMapOpts(min_=min(y),max_=max(y)),
)
scatter.render_notebook()
八、箱形图
绘制各区域的房价箱形图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 数据结构要求:
# x_data = ['南山', '福田', '宝安']
# y_data = [[1, 2, 3, 4], 南山房价列表
# [1, 2, 3, 4], 福田房价列表
# [1, 2, 3, 4]] 宝安房价列表
x_data = df['区域'].unique().tolist()
y_data = [df[df['区域'] == x]['单价'].tolist() for x in x_data]
# y_data = []
# for x in x_data:
# lst = df[df['区域'] == x]['单价'].tolist()
# y_data.append(lst)
boxplot = Boxplot()
boxplot.add_xaxis(x_data)
boxplot.add_yaxis('房价',boxplot.prepare_data(y_data))
boxplot.set_global_opts(
title_opts=opts.TitleOpts(title='各区房价箱形图'),
datazoom_opts=opts.DataZoomOpts(),
)
boxplot.render_notebook()

九、热力图
x轴为建造年份,y轴为总楼层,绘制房价的热力图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
tb = df.groupby(['建造年份', '总楼层']).agg({'单价': 'mean'}).reset_index()
tb['单价'] = tb['单价'].astype(int)
tb = tb.sort_values(by=['建造年份', '总楼层'], ascending=True)
# xy轴标签: 升序, 字符串, 去重
x_label = list(tb['建造年份'].sort_values().astype(str).unique())
y_label = list(tb['总楼层'].sort_values().astype(str).unique())
tb['建造年份'] = tb['建造年份'].astype(str)
tb['总楼层'] = tb['总楼层'].astype(str)
data = tb.values.tolist()
heat_map = HeatMap()
heat_map.add_xaxis(x_label)
heat_map.add_yaxis('均价',y_label,data)
heat_map.set_global_opts(
title_opts=opts.TitleOpts('建造年份、总楼层与房价的热力图'),
xaxis_opts=opts.AxisOpts(name='建造年份'),
yaxis_opts=opts.AxisOpts(name='总楼层'),
# 视觉映射
visualmap_opts=opts.VisualMapOpts(
min_=min(tb['单价']),
max_=max(tb['单价'])
)
)
heat_map.render_notebook()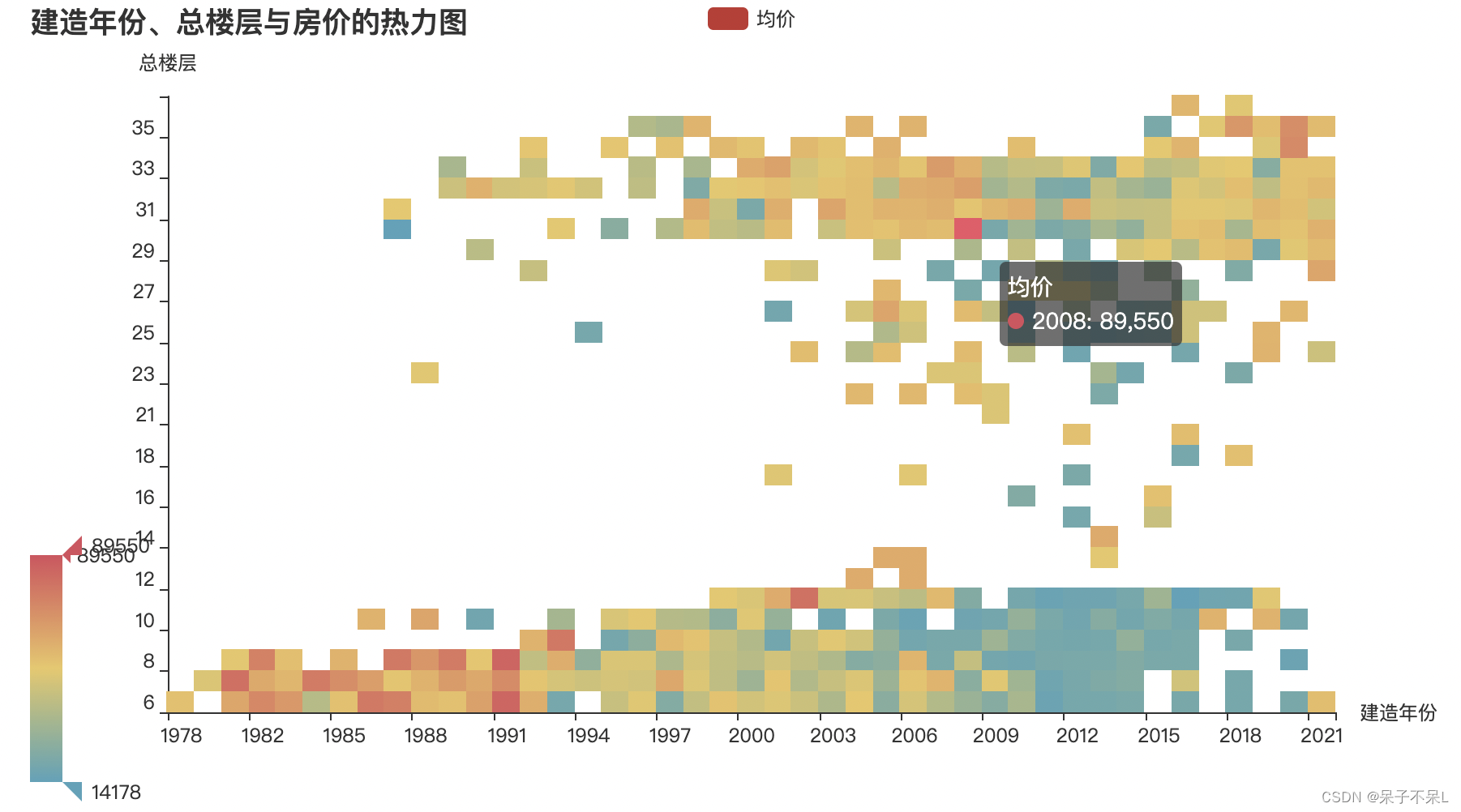
3D图
bar3d = Bar3D()
bar3d.add(
series_name='均价',
data=data,
xaxis3d_opts=opts.Axis3DOpts(data=x_label),
yaxis3d_opts=opts.Axis3DOpts(data=y_label),
zaxis3d_opts=opts.Axis3DOpts(),
)
bar3d.set_global_opts(
# 视觉映射
visualmap_opts=opts.VisualMapOpts(
min_=min(tb['单价']),
max_=max(tb['单价']),
)
)
bar3d.render_notebook()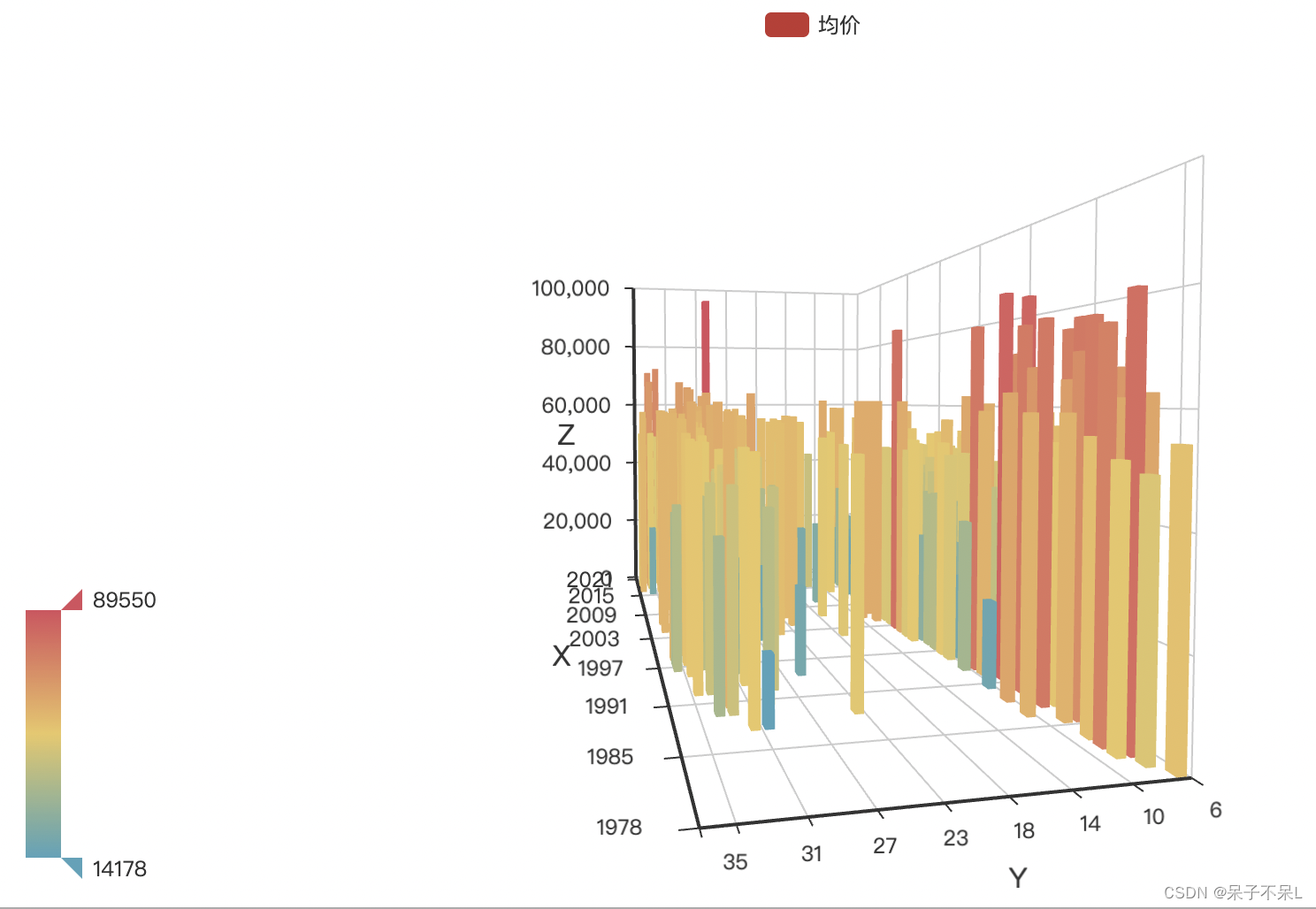
十、地图
绘制深圳房价地图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
# 数据结构要求:
# [['光明区', 130],
# ['南山区', 604],
# ['坪山区', 281],
# ['大鹏区', 63],
# ['宝安区', 1291],
# ['盐田区', 125],
# ['福田区', 393],
# ['罗湖区', 1027],
# ['龙华区', 1034],
# ['龙岗区', 810]]
# 1.深圳地图
df = pd.read_sql('select * from db.house_data', engine)
# 将 布吉 划分到 龙岗区
df['区域'] = df['区域'].str.replace('布吉','龙岗')
df['房源数量'] = 1
tb = df.groupby('区域').agg({'房源数量': 'count'}).reset_index()
tb['区域'] = tb['区域'] + '区' # 添加后缀
data = tb[['区域','房源数量']].values.tolist()
data
‘’‘
[['光明区', 130],
['南山区', 604],
['坪山区', 281],
['大鹏区', 63],
['宝安区', 823],
['盐田区', 125],
['福田区', 393],
['罗湖区', 1027],
['龙华区', 1034],
['龙岗区', 1278]]
’‘’
map_chart = Map()
map_chart.add('房源数量',data,maptype='深圳')
map_chart.set_global_opts(
title_opts=opts.TitleOpts(title='各区房源数量分布'),
visualmap_opts=opts.VisualMapOpts(
max_=max(tb['房源数量']),
# 是否分段
is_piecewise=True,
# 自定义分段
pieces=[{'min':0,'max':200},{'min':200,'max':400},{'min':400,'max':600},{'min':600,'max':800},{'min':800,'max':1000},{'min':1000,'max':1300}]
),
)
map_chart.render_notebook()

- 全国地图
df = pd.read_csv('./dataset/订单数据.csv')
df = df[df['国家'] == '中国']
tb = df.groupby(['产品类别','省份']).agg({'金额':'sum'}).reset_index()
tb.head()
map_ = Map()
# 循环插入各产品类别的数据
for i in tb['产品类别'].unique():
data = tb[tb['产品类别']==i][['省份','金额']].values.tolist()
map_.add(i,data,is_map_symbol_show=False) # is_map_symbol_show=False 是否显示标记
map_.set_global_opts(
title_opts=opts.TitleOpts(title='各省业务地图'),
visualmap_opts=opts.VisualMapOpts(
max_=max(tb['金额']),
)
)
map_.render_notebook() 
十一、词云图
将标题分词并绘制词云图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
import jieba
import jieba.analyse as anls
# pip install jieba
# pip install wordcloud # 国外开源的词云
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 合并每行的字符串
strings = ''.join( str(x) for x in df['标题'])
# 分词
jieba.analyse.set_stop_words('del_word.txt') # 设置想要屏蔽的词汇,将需要屏蔽的词汇添加到 del_word.txt 中,并且一行一个词
words = anls.extract_tags(
sentence=strings,
topK=50,
withWeight=True, # 添加权重系数
allowPOS=['ns', 'n', 'vn', 'v','nr'], # 指定词性分词
)
words
‘’‘
[('地铁口', 0.46348121060541103),
('精装', 0.3944921963442434),
('业主', 0.2832062569943062),
('三房', 0.25423380599584205),
('红本', 0.2536784317995584),
('首付', 0.2263495716381579),
('花园', 0.21701240028039917),
('小区', 0.12393997780901442),
('阳台', 0.10903571421518997),
('出售', 0.10758799795035184),
('地铁', 0.10534524896648755),
('车位', 0.10058882122530324),
('采光', 0.09487634032402145),
('过户', 0.09172649265640467),
('笋盘', 0.08810183374660338),
('电梯', 0.0863552278817538),
('南北', 0.07601487084674878),
('物业', 0.06797559460326556),
('楼层', 0.06513405188448944),
('装修', 0.06493330126635219),
('粤海', 0.06277501726620309),
('公立', 0.05782558069865913),
('罗湖', 0.057393517448478766),
('朝南', 0.05667130684335158),
('包税', 0.0538209645845009),
('拎包', 0.05369634077756431),
('分期', 0.052564815124693895),
('在手', 0.05251742840428412),
('南山', 0.052497443538052656),
('号线', 0.0524497298180168),
('急卖', 0.052106921126395776),
('钥匙', 0.05119345784392653),
('产权', 0.050847587497835),
('回迁房', 0.050293434885788434),
('家私', 0.04754433058730766),
('公寓', 0.046737994070571505),
('燃气', 0.04559633136407106),
('入住', 0.04407269498161042),
('方正', 0.04369144914831532),
('新房', 0.042390614053550886),
('社区', 0.04148521485236745),
('三房两厅', 0.03946225124159092),
('价格', 0.03898374699350443),
('赠送', 0.03875082539151349),
('市场价', 0.037560415691580876),
('宝安', 0.03753499783208499),
('翠园', 0.03668053000344966),
('村委', 0.036669780350351275),
('低于', 0.03587279094997735),
('置换', 0.035758734523470885)]
’‘’
wc = WordCloud()
wc.add(
'权重系数',
words,
word_size_range=[10,100],
shape='diamond', # 设置词云图的轮廓
)
wc.render_notebook()
- 自定义图片轮廓作为词云图轮廓
wc = WordCloud()
wc.add(
'权重系数',
words,
word_size_range=[10,100],
mask_image='./房子.png', # 自定义图片轮廓作为词云图轮廓,图片最好不要多颜色
)
wc.render_notebook() 
十二、层叠多图
- 绘制柱形图+折线图的组合图
- 柱形图:各区的平均房价
- 折线图:各区的房源数量
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 柱形图的数据
tb1 = df.groupby('区域').agg({'单价': 'mean'}).reset_index()
tb1['单价'] = tb1['单价'].astype(int)
x_bar, y_bar = list(tb1['区域']), list(tb1['单价'])
# 折线图的数据
tb2 = df.groupby('区域').agg(房源数量=('标题', 'count')).reset_index()
x_line, y_line = list(tb2['区域']), list(tb2['房源数量'])
# 柱形图
bar = Bar()
bar.add_xaxis(x_bar)
bar.add_yaxis(
'平均房价',
y_bar,
yaxis_index=0, # 设置柱形图y轴的索引
z_level=-1, # 设置图形展示的层级,默认值为0
)
# 扩展一个y轴,绘制折线图
bar.extend_axis(yaxis=opts.AxisOpts(name='房源数量',type_='value'))
# 设置左y轴的名称及类型
bar.set_global_opts(
yaxis_opts=opts.AxisOpts(name='平均房价',type_='value'),
)
# 折线图
line = Line()
line.add_xaxis(x_line)
line.add_yaxis(
'房源数量',
y_line,
yaxis_index=1, # 设置折线图y轴索引
z_level=1, # 设置图形展示的层级,默认值为0
)
# 组合柱形图和折线图
bar.overlap(line)
bar.render_notebook()
十三、顺序多图
- 绘制柱形图+折线图的顺序多图
- 一个画布展示两个图表,上下各一个
- 柱形图:各区的平均房价
- 折线图:各区的房源数量
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 柱形图
tb1 = df.groupby('区域').agg({'单价': np.mean}).reset_index()
tb1['单价'] = tb1['单价'].astype(int)
x, y = list(tb1['区域']), list(tb1['单价'])
bar = Bar()
bar.add_xaxis(x)
bar.add_yaxis('平均房价', y)
# bar.render_notebook()
# 折线图
tb2 = df.groupby('区域').agg(房源数量=('标题', 'count')).reset_index()
x, y = list(tb2['区域']), list(tb2['房源数量'])
line = Line()
line.add_xaxis(x)
line.add_yaxis('房源数量', y)
# line.render_notebook()- 简单页面布局
page = Page(layout=Page.SimplePageLayout)
page.add(bar,line)
page.render_notebook() 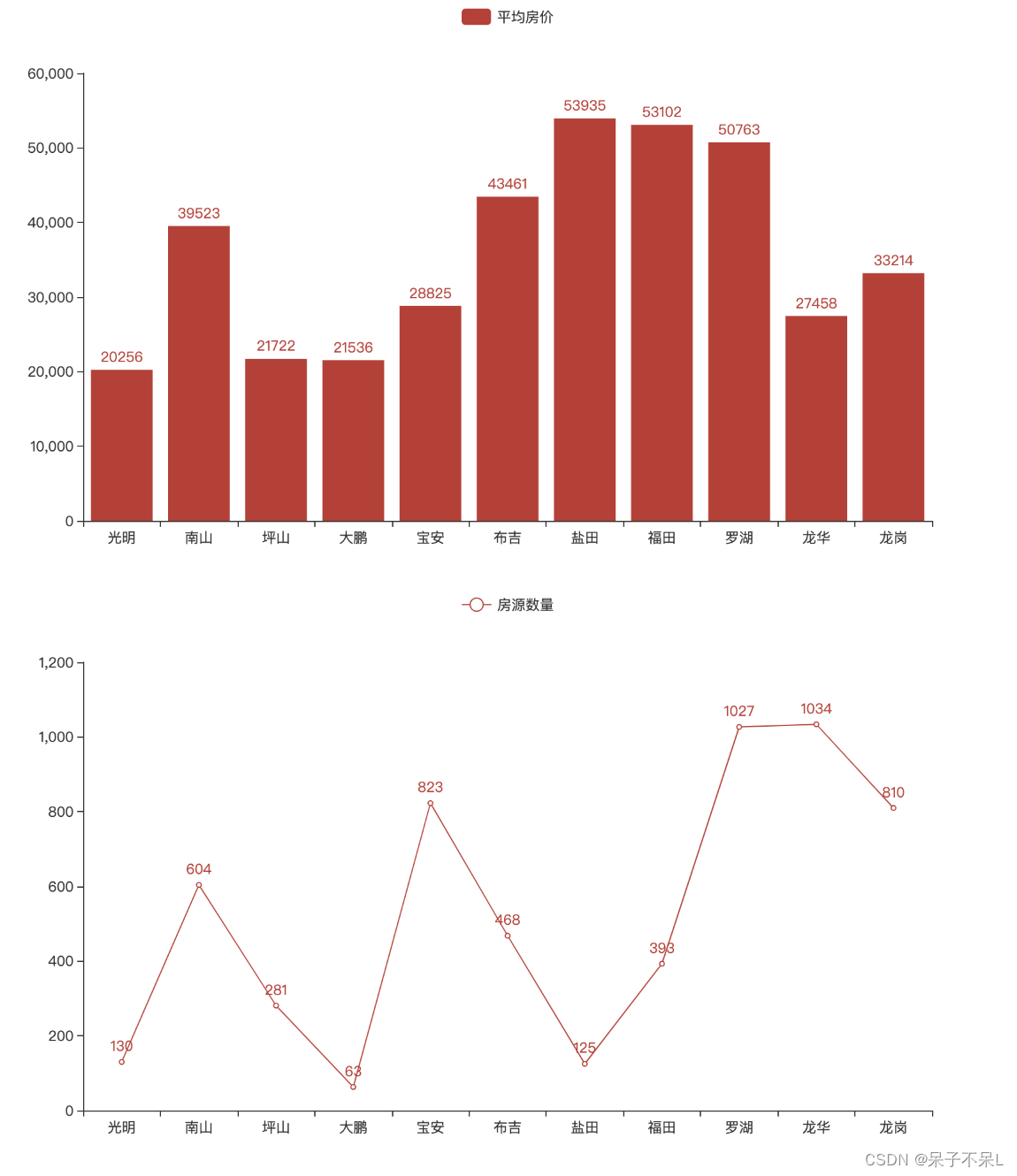
- 可以拖动的页面布局
page = Page(layout=Page.DraggablePageLayout)
page.add(bar,line)
page.render('拖动布局.html') # 保存到html文件,打开html文件将图表拖至需要的位置点击保存,生成 json 文件# source,Page第一次渲染后的 html 文件
# chart_config, 布局配置文件
# dest,重新生成的 html 存放路径
page.save_resize_html(
source='拖动布局.html',
cfg_file='./chart_config.json',
dest='顺序多图-可拖动页面布局.html',
)十四、选项卡多图
- 绘制柱形图+折线图的选项卡多图
- 柱形图:各区的平均房价
- 折线图:各区的房源数量
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 柱形图
tb1 = df.groupby('区域').agg({'单价': np.mean}).reset_index()
tb1['单价'] = tb1['单价'].astype(int)
x, y = list(tb1['区域']), list(tb1['单价'])
bar = Bar()
bar.add_xaxis(x)
bar.add_yaxis('平均房价', y)
# bar.render_notebook()
# 折线图
tb2 = df.groupby('区域').agg(房源数量=('标题', 'count')).reset_index()
x, y = list(tb2['区域']), list(tb2['房源数量'])
line = Line()
line.add_xaxis(x)
line.add_yaxis('房源数量', y)
# line.render_notebook()
tab = Tab()
# 一个 tab.add() 为一个选项卡
tab.add(bar,'柱形图')
tab.add(line,'折线图')
tab.render_notebook()
十五、并行多图
- 绘制柱形图+折线图的并行多图
- 柱形图:各区的平均房价
- 折线图:各区的房源数量
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
# 柱形图
tb1 = df.groupby('区域').agg({'单价': np.mean}).reset_index()
tb1['单价'] = tb1['单价'].astype(int)
x, y = list(tb1['区域']), list(tb1['单价'])
bar = Bar()
bar.add_xaxis(x)
bar.add_yaxis('', y)
# bar.render_notebook()
# 折线图
tb2 = df.groupby('区域').agg(房源数量=('标题', 'count')).reset_index()
x, y = list(tb2['区域']), list(tb2['房源数量'])
line = Line()
line.add_xaxis(x)
line.add_yaxis('', y)
# line.render_notebook()- 左右布局
grid = Grid()
# pos_left 左边缘距离
# pos_right 右边缘距离
grid.add(bar,grid_opts=opts.GridOpts(pos_left='55%'))
grid.add(line,grid_opts=opts.GridOpts(pos_right='55%'))
grid.render_notebook() 
- 上下布局
grid = Grid()
# pos_top 上边缘距离
# pos_bottom 下边缘距离
grid.add(bar,grid_opts=opts.GridOpts(pos_top='55%'))
grid.add(line,grid_opts=opts.GridOpts(pos_bottom='55%'))
grid.render_notebook() 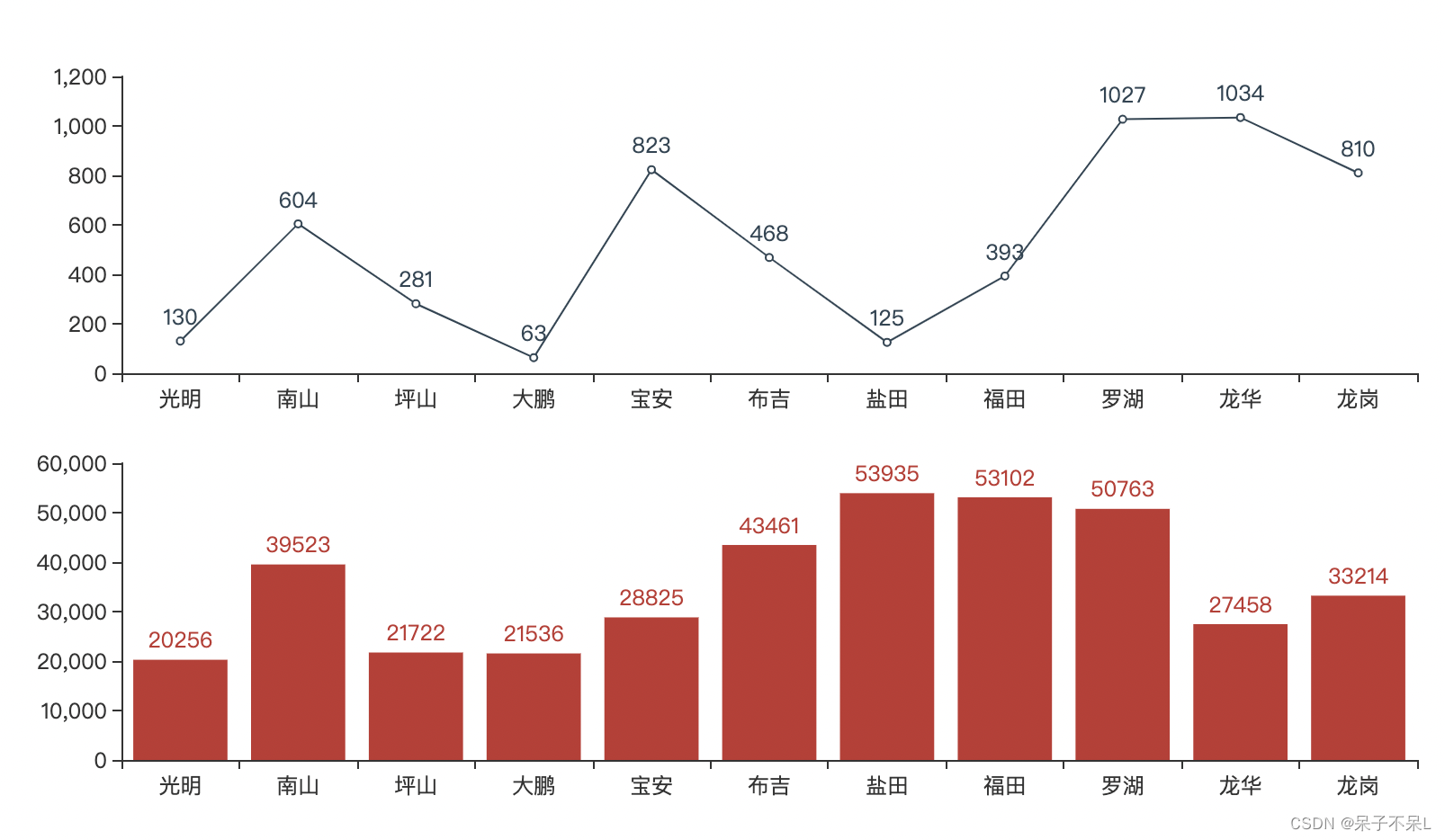
十六、时间线轮博多图
- 时间轴:建造年份
- 地图:各区房源数量分布
- 每年一个地图,按年播放地图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', engine)
tb = df.groupby(['建造年份', '区域']).agg({'标题': 'count'}).reset_index()
tb['区域'] = tb['区域'] + '区' # 添加后缀
tb.rename(mapper={'标题': '房源数量'}, axis=1, inplace=True)
dt = list(tb['建造年份'].sort_values().unique())
tl = Timeline()
for i in dt:
map_ = Map()
data = tb[tb['建造年份'] == i][['区域','房源数量']].values.tolist()
map_.add('房源数量',data,'深圳')
map_.set_global_opts(
title_opts=opts.TitleOpts(title=f'{i}年各区房源数量'),
visualmap_opts=opts.VisualMapOpts(max_=max(tb['房源数量'])),
)
tl.add(map_,f'{i}年')
tl.render_notebook() 
十七、矩形树图
以区域分组,求房源数量,并绘制矩形树图
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import *
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db?charset=utf8')
df = pd.read_sql('select * from db.house_data', con=engine)
tb = df.groupby('区域').agg(房源数量=('标题','count')).reset_index()
lis = [ {'name':x,'value':y} for x,y in zip(tb['区域'],tb['房源数量'])]
data = [{'name':'深圳','children':lis}]
data
‘’‘
[{'name': '深圳',
'children': [{'name': '光明', 'value': 130},
{'name': '南山', 'value': 604},
{'name': '坪山', 'value': 281},
{'name': '大鹏', 'value': 63},
{'name': '宝安', 'value': 823},
{'name': '布吉', 'value': 468},
{'name': '盐田', 'value': 125},
{'name': '福田', 'value': 393},
{'name': '罗湖', 'value': 1027},
{'name': '龙华', 'value': 1034},
{'name': '龙岗', 'value': 810}]}]
’‘’
tree_map = TreeMap()
tree_map.add(
'房源数量',
data,
label_opts=opts.LabelOpts(
horizontal_align='center', # 水平排列剧中
vertical_align='top', # 垂直排列靠上
formatter='{b}:{c}', # b:数据项名称;c:指标值
)
)
tree_map.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=max(tb['房源数量']))
)
tree_map.render_notebook()
十八、雷达图
以“主要定位”分组,求相应指标的均值,并绘制雷达图
import numpy as np
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
# 示例Radar - Basic_radar_chart
# 王者荣耀英雄
df = pd.read_csv('./dataset/heros.csv')
# tb.head()
# tb.columns
tb = df.groupby('主要定位').agg({
'最大生命': np.mean,
'最大法力': np.mean,
'最高物攻': np.mean,
'最大物防': np.mean,
'最大每5秒回血': np.mean,
'最大每5秒回蓝': np.mean,
'最大攻速': np.mean}).reset_index()
tb
# 构造每个指标的名称及最大的刻度值
columns = tb.drop(columns='主要定位').columns.to_list()
'''
['最大生命', '最大法力', '最高物攻', '最大物防', '最大每5秒回血', '最大每5秒回蓝', '最大攻速']
'''
schema = [{'name':col,'max':tb[col].max()} for col in columns]
'''
[{'name': '最大生命', 'max': 8312.4},
{'name': '最大法力', 'max': 1822.0},
{'name': '最高物攻', 'max': 395.5},
{'name': '最大物防', 'max': 456.0},
{'name': '最大每5秒回血', 'max': 115.8},
{'name': '最大每5秒回蓝', 'max': 40.31578947368421},
{'name': '最大攻速', 'max': 0.37799999999999995}]
'''
# 6大类英雄颜色值(图例)
colors = ['red','green','blue','gold','brown','purple']
radar = Radar()
radar.add_schema(schema)
# 循环插入六大类英雄的数据
for x,y in zip(tb['主要定位'],colors):
# 嵌套列表
data = tb[tb['主要定位'] == x][columns].values.tolist()
# /前面的参数必须通过位置传惨
# *后面的参数必须通过关键字传惨
radar.add(x,data,color=y)
radar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
radar.render_notebook()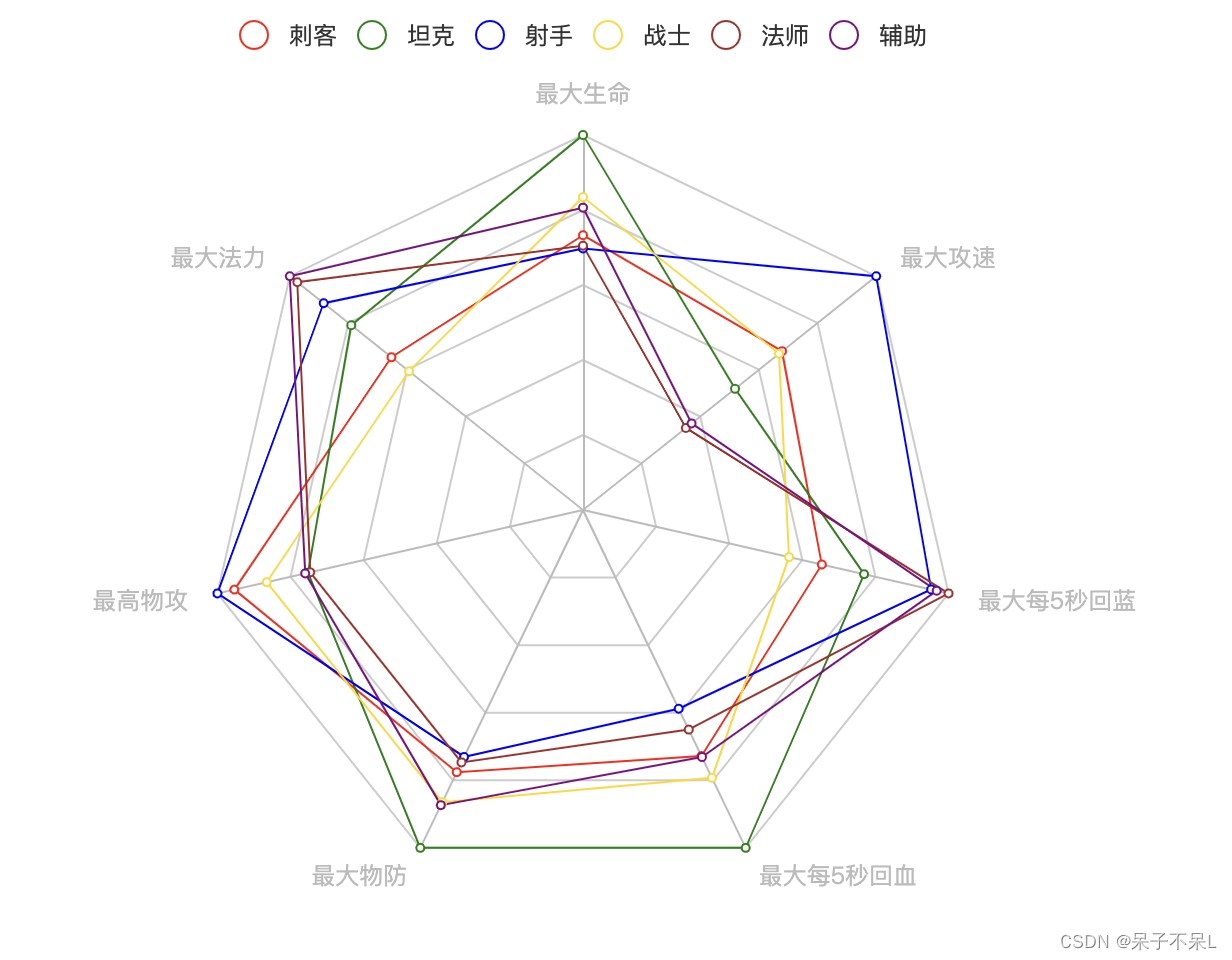














 5886
5886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









