








文章目录
推荐阅读
相关文章
- 【1】【机器学习笔记1】一元线性回归模型及预测_Twilight Sparkle.的博客-CSDN博客_一元线性回归模型预测
- 【2】【机器学习笔记4】逻辑回归模型_Twilight Sparkle.的博客-CSDN博客_逻辑回归模型
- 【3】对数损失和交叉熵损失_InceptionZ的博客-CSDN博客_深度学习对数和交叉熵的区别是什么
参考文章
前言
早在写逻辑回归二分类时就提到过多分类的问题,时隔两个月终于可以把当初这个坑填上了。softmax本应该属于深度学习的笔记,但归为机器学习的笔记,也没什么不妥。好了,闲话不多说。
本篇为softmax多分类器的原理与公式详细推导,关于softmax的具体代码实现和应用将在下一章说明。
softmax多分类器简介
softmax多分类器,一种基于softmax函数的分类器,它可以预测一个样本属于每个样本的概率。softmax一般用于神经网络的输出层,叫做softmax层。
不过不必担心,本篇文章对神经网络没有要求,即使没学过神经网络,也可以学会softmax,并在下一篇文章中学会自己实现softmax代码并完成一个具体的训练和预测示例。
如何利用softmax对样本进行分类
问题引入
如何使用训练集训练一个基于softmax函数的多分类模型,并使用该模型对测试集进行预测?
好吧,这个问题引入写的有点草率了,想了一会儿没啥好写的,就是多分类问题。
明确变量与集合
为了在接下来的推导过程中不搞混各变量的含义,我们需要先明确涉及的变量和集合。
- 设样本集含有
N个样本,令样本集为X,则 X = { x 1 , x 2 , x 3 . . . , x N } X = \{x^1,x^2,x^3...,x^N\} X={x1,x2,x3...,xN}。注意这里使用的上标,这样写是为了后续方便表示样本的特征。 - 设任意一个样本含有
M个特征,令任意一个样本为 x x x,则 x = ( x 1 , x 2 , x 3 , . . . , x M ) x = (x_1,x_2,x_3,...,x_M) x=(x1,x2,x3,...,xM)。则第i个样本的第j个特征表示为 x j i x_j^i xji。 - 设样本集共分为
K类。记分类集为C,则 C = { c 1 , c 2 , . . . , c K } C = \{c_1,c_2,...,c_K\} C={c1,c2,...,cK}。 - 设样本集对应的label集为
Y,每一个样本对应一个y,则 Y = { y 1 , y 2 , y 3 , . . , y N } Y=\{y_1,y_2,y_3,..,y_N\} Y={y1,y2,y3,..,yN}。其中, y i y_i yi 的值为 0 ∼ K − 1 0 \sim K-1 0∼K−1 中的一个整数。
进一步处理
对label向量化
回顾二分类问题,样本的label要么是0,要么是1。现在变成多分类了,那么样本的label就变成了 0 ∼ K − 1 0 \sim K-1 0∼K−1 中任意一个整数。这就不便于我们计算了,所以需要将label进行向量化:
若第i个样本属于第K个分类,即
y
i
=
c
k
y_i=c_k
yi=ck。那么对其进行向量化后:
y
i
=
(
0
,
.
.
.
,
1
,
.
.
.
,
0
)
y_i = (0,...,1,...,0)
yi=(0,...,1,...,0)
仅在第K-1的位置上值为1,其他位置均为0。
示例
假设共有5个分类,样本
x
i
x^i
xi 属于第3类,则:
y
i
=
(
0
,
0
,
1
,
0
,
0
)
y_i = (0,0,1,0,0)
yi=(0,0,1,0,0)
对样本特征进行加权组合
在进入softmax层之前,不得不提到特征的加权组合。在神经网络中,这一步的处理其实叫做隐藏层,不过这里就不对隐藏层做拓展了。
为了使softmax拥有一套完整的流程,我们这里对样本特征进行最简单的线性加权组合:
现在有任意一个样本
x
=
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
M
)
x = (x_1,x_2,x_3,...,x_M)
x=(x1,x2,x3,...,xM) 。
x
i
x_i
xi表示该样本的第
i
i
i个特征。令
z
k
=
w
k
T
x
+
b
k
=
(
∑
i
=
1
M
w
k
,
i
x
i
)
+
b
k
z_k = w_k^Tx+b_k = (\sum_{i=1}^Mw_{k,i}x_i)+b_k
zk=wkTx+bk=(i=1∑Mwk,ixi)+bk
现在多出了几个参数,下面对它们进行说明:
- z z z:对样本 x x x的特征进行线性加权组合后得到的输出, z = ( z 1 , z 2 , . . . , z K ) z = (z_1,z_2,...,z_K) z=(z1,z2,...,zK) 。有几个分类就有就有几个 z k z_k zk。
-
z
k
z_k
zk:表示对样本的特征进行权值向量为
w
k
w_k
wk 的线性变换后得到的值,为
标量。 - w k w_k wk:第k个权值向量,维度与 x x x一样, ( 1 , N ) (1,N) (1,N)。
将 b k b_k bk放在 w k w_k wk 里:
只需要将 w k w_k wk加一列,即 w k = ( . . . , b k ) w_k = (...,b_k) wk=(...,bk),
然后再往 x x x加一列,即 x = ( . . . , 1 ) x = (...,1) x=(...,1) 。
就可以将 z k z_k zk 的表达式变为: z k = w k T x z_k = w_k^Tx zk=wkTx
图示(不含 b k b_k bk的情况):
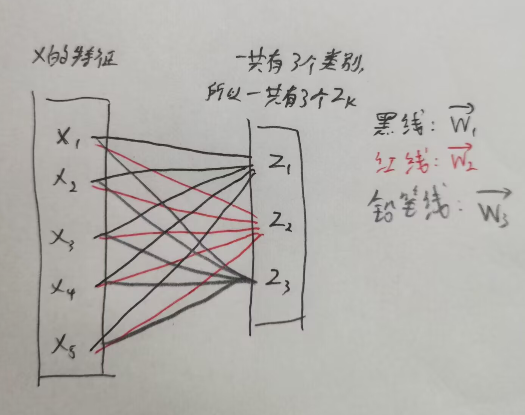
softmax激活函数
激活函数也是神经网络里的称呼,直接叫softmax函数也没问题。
简单来说,softmax预测分类是作用在
z
k
z_k
zk 上的,这也是为什么之前我们需要对样本特征进行加权组合得到
z
k
z_k
zk。接下来给出公式:
a
k
=
P
(
y
=
c
k
∣
x
,
θ
)
=
e
z
k
∑
i
=
1
K
e
z
i
,
k
=
0
,
1
,
.
.
.
,
K
−
1
a_k = P(y=c_k|x,\theta) = \frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}},k = 0,1,...,K-1
ak=P(y=ck∣x,θ)=∑i=1Keziezk,k=0,1,...,K−1
稍微解释一下这个公式:在模型参数 θ \theta θ固定,且样本已知的情况下,该样本属于第K个分类的概率等于后面那一坨公式。(本文中 θ \theta θ即各权值向量 w k w_k wk)
通过softmax激活函数得到各分类预测概率
将一个样本对应的 a k a_k ak 全部算出来,这些 a k a_k ak 就是该样本属于各分类的预测概率。
示例
假设一个样本
x
x
x的特征进行加权组合后得到的
z
z
z为:
z
=
(
0.6
,
1.1
,
−
1.5
,
1.2
,
3.2
,
−
1.1
)
z = (0.6,1.1,-1.5,1.2,3.2,-1.1)
z=(0.6,1.1,−1.5,1.2,3.2,−1.1)
经过softmax激活后:
a
=
(
0.055
,
0.090
,
0.0067
,
0.10
,
0.74
,
010
)
a = (0.055,0.090,0.0067,0.10,0.74,010)
a=(0.055,0.090,0.0067,0.10,0.74,010)
比如其中的0.74表示:在已知权值
w
w
w 的情况下,某一个样本
x
x
x 属于第5个分类的概率为0.74。
那么如果这是在做测试集的测试,根据“属于谁的概率最大就选谁”的原则,我们可以说x的预测分类为第5个分类,即 l a b e l = 4 label = 4 label=4 。不过在训练集训练模型时,我们只求到x属于每个类别的概率。
在神经网络中,将上述过程描述为神经网络的正向传播。
总结softmax的正向传播流程
- 固定模型参数 θ \theta θ ,在本篇文章中, θ \theta θ 即各权值向量 w k w_k wk。
- 对于一个样本 x = ( x 1 , x 2 , . . . , x M ) x = (x_1,x_2,...,x_M) x=(x1,x2,...,xM),先对它的特征做加权组合得到 z = ( z 1 , . . , z K ) z = (z_1,..,z_K) z=(z1,..,zK)。在本篇文章中,我们仅做了一次线性加权组合。而在神经网络中,可能会对x的特征做多次变换,即隐藏层不止一层。
- 对 z z z 进行softmax激活得到 a = ( a 1 , . . . a K ) a = (a_1,...a_K) a=(a1,...aK), a k a_k ak 表示样本x属于第k类的概率。
引出新的问题
我们进行正向传播时,是在模型参数 θ \theta θ 已知的情况下进行。而我们现在已知的只有训练集,怎么根据训练集得到这个模型参数 θ \theta θ 呢?
答案是迭代。我们可以随机初始化模型参数 θ \theta θ,然后通过某种算法一轮一轮的更新 θ \theta θ ,直到 θ \theta θ 收敛。
在softmax分类器中,我们使用梯度下降算法对 θ \theta θ进行优化。关于梯度下降算法请见相关文章【1】,在这里就不多说了。
softmax损失函数
损失函数之前的文章已经提到过N次了,不过这里还是说一下。损失函数是用来衡量label预测值和真实值之间的某种差距的函数。常见的损失函数有0-1损失函数、对数损失函数、平方损失函数等等。每种模型需要选择的损失函数不同。如果损失函数选择不当,会对优化过程造成很大影响,详情请见相关文章【2】。
损失函数和代价函数的区别
说来惭愧,我一直都没真正搞清楚损失函数和代价函数的区别,所以之前写文章可能存在这两个词汇混用的问题。这次专门区分一下两者的区别。
损失函数
损失函数(Loss Function )是定义在单个样本上的,描述单个样本的label预测值与真实值的某种差距。一般记为 L ( y ^ , y ) L(\hat y,y) L(y^,y) 。
代价函数
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。一般记为
J
(
.
.
.
)
J(...)
J(...)。“...”指代的一般为模型未知参数,有许多种写法。
J
(
.
.
.
)
=
1
N
∑
i
=
0
N
−
1
L
(
y
^
,
y
)
J(...) = \frac{1}{N}\sum_{i=0}^{N-1}L(\hat y,y)
J(...)=N1i=0∑N−1L(y^,y)
其中,N为本次参加训练的样本个数。
我们进行梯度下降时使用的是
代价函数求偏导,而对代价函数求偏导其实只需要对损失函数求偏导,然后求个平均就是代价函数求偏导。所以接下来的求偏导过程写的是对损失函数求偏导。不过在最后的总结时,会对损失函数求偏导的结果求平均变成代价函数求偏导的结果。
softmax的损失函数表达式
softmax分类器选用的是交叉熵损失函数。有的文章也说是选用对数损失函数。这是因为:
对数损失函数(Log loss function)和交叉熵损失函数(Cross-entroy loss function)表达式本质式一样的。不过这两种损失函数对应的上一层结构不同,对数损失函数经常对应的是Sigmoid函数的输出,用于二分类问题;而交叉熵损失函数经常对应的是Softmax函数的输出,用于多分类问题。详情请见相关文章【3】。
L ( y ^ , y ) = − ∑ k = 1 K y k l o g a k L(\hat y,y) = -\sum_{k=1}^Ky_kloga_k L(y^,y)=−k=1∑Kyklogak
注,log通常以2为底,有的文章也会使用ln。
其中:
- y ^ \hat y y^: 单个训练样本label预测值, y ^ = ( a 1 , . . . , a k ) \hat y = (a_1,...,a_k) y^=(a1,...,ak); 例如: y ^ = ( 0.055 , 0.090 , 0.0067 , 0.10 , 0.74 , 010 ) \hat y = (0.055,0.090,0.0067,0.10,0.74,010) y^=(0.055,0.090,0.0067,0.10,0.74,010)
- y y y:单个训练样本label真实值, y = ( y 1 , . . . , y k ) y = (y_1,...,y_k) y=(y1,...,yk); 例如: y = ( 0 , 0 , 0 , 0 , 1 , 0 ) y = (0,0,0,0,1,0) y=(0,0,0,0,1,0)
- y k y_k yk: 单个训练样本属于第k类的真实值,取值0或1
- a k a_k ak:单个训练样本属于第k类的预测值,为一个概率值
对代价函数进行梯度下降
梯度下降算法步骤
回顾梯度下降算法的步骤:
- 初始化模型未知参数 W = ( w 1 , . . , w K ) W = (w_1,..,w_K) W=(w1,..,wK),其中每一个 w k w_k wk 为向量,维度与样本x相同。K的值与类别数相同。
- 重复进行以下公式直到收敛:
w k = w k − α ∂ J ∂ w k , k = 0 , 1 , . . . , K − 1 w_k = w_k - \alpha \frac{\partial J}{\partial w_k},\quad k = 0,1,...,K-1 wk=wk−α∂wk∂J,k=0,1,...,K−1
对上述公式进行说明:
为什么没有 b k b_k bk?
b k b_k bk被融合到向量 w k w_k wk里了。最后总结结果时会单独把 b k b_k bk 提出来。
α \alpha α是什么?
学习率,是需要人工调整的超参数。它控制的是梯度下降中每一步的跨度大小。关于学习率更多说明请见相关文章【1】。
这个公式里明明是对代价函数J求偏导,为什么下面推导的是损失函数求偏导?
刚才在区分代价函数和损失函数时有说过,对求得的损失函数偏导求平均就是代价函数求偏导的结果。
损失函数求偏导的详细推导
此部分参考了文章:参考文章【1】
之前提到的softmax损失函数:
L
(
y
^
,
y
)
=
−
∑
k
=
1
K
y
k
l
o
g
a
k
(
1
)
L(\hat y,y) = -\sum_{k=1}^Ky_kloga_k~~~~~(1)
L(y^,y)=−k=1∑Kyklogak (1)
其中,
a
k
=
e
z
k
∑
i
=
1
K
e
z
i
(
2
)
z
k
=
w
k
T
x
=
∑
i
=
1
M
w
k
,
i
x
i
(
3
)
k
=
0
,
1
,
.
.
.
,
K
−
1
\begin{split} & a_k = \frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}}~~~~~~(2) \\ & z_k = w_k^Tx = \sum_{i=1}^Mw_{k,i}x_i~~~(3)\\ & k = 0,1,...,K-1 \end{split}
ak=∑i=1Keziezk (2)zk=wkTx=i=1∑Mwk,ixi (3)k=0,1,...,K−1
现在需要求:
∂
L
(
y
^
,
y
)
∂
w
k
\frac{\partial L(\hat y,y)}{\partial w_k}
∂wk∂L(y^,y)
根据链式求导法则,有:
∂
L
(
y
^
,
y
)
∂
w
k
=
∂
L
(
y
^
,
y
)
∂
z
k
⋅
∂
z
k
∂
w
k
(
4
)
\frac{\partial L(\hat y,y)}{\partial w_k} = \frac{\partial L(\hat y,y)}{\partial z_k}·\frac{\partial z_k}{\partial w_k}~~~~(4)
∂wk∂L(y^,y)=∂zk∂L(y^,y)⋅∂wk∂zk (4)
1 求解
∂
z
k
∂
w
k
\frac{\partial z_k}{\partial w_k}
∂wk∂zk
∂
z
k
∂
w
k
=
∂
(
w
k
T
x
)
∂
w
k
=
x
(
5
)
\begin{split} \frac{\partial z_k}{\partial w_k} & = \frac{\partial (w_k^Tx)}{\partial w_k} = x ~~~~(5) \end{split}
∂wk∂zk=∂wk∂(wkTx)=x (5)
2 求解 ∂ L ( y ^ , y ) ∂ z k \frac{\partial L(\hat y,y)}{\partial z_k} ∂zk∂L(y^,y)
这也是整个softmax最关键的一步,很多教程推完这里就结束了。
根据(2)式,
a
j
a_j
aj 均包含
z
z
z的所有分量,所以要求
z
k
z_k
zk 的偏导,所以对于
z
k
z_k
zk的偏导,每一个
a
j
a_j
aj 都有贡献:
∂
L
(
y
^
,
y
)
∂
z
k
=
∑
j
=
1
K
[
∂
L
(
y
^
,
y
)
∂
a
j
∂
a
j
∂
z
k
]
(
6
)
\frac{\partial L(\hat y,y)}{\partial z_k} = \sum_{j=1}^K[\frac{\partial L(\hat y,y)}{\partial a_j}\frac{\partial a_j}{\partial z_k}]~~~~(6)
∂zk∂L(y^,y)=j=1∑K[∂aj∂L(y^,y)∂zk∂aj] (6)
2.1 求解
∂
L
(
y
^
,
y
)
∂
a
j
\frac{\partial L(\hat y,y)}{\partial a_j}
∂aj∂L(y^,y)
∂
L
(
y
^
,
y
)
∂
a
j
=
∂
(
−
∑
j
=
1
K
y
j
l
o
g
a
j
)
∂
a
j
=
−
y
j
a
j
(
7
)
\begin{split} \frac{\partial L(\hat y,y)}{\partial a_j} & = \frac{\partial (-\sum_{j=1}^Ky_jloga_j)}{\partial a_j} = - \frac{y_j}{a_j}~~~~(7) \end{split}
∂aj∂L(y^,y)=∂aj∂(−∑j=1Kyjlogaj)=−ajyj (7)
2.2 求解 ∂ a j ∂ z k \frac{\partial a_j}{\partial z_k} ∂zk∂aj
刚才说过,每一个 a j a_j aj 都要对 z k z_k zk 求导,那自然有两种情况: j = k j = k j=k 和 j ≠ k j \neq k j=k 。现在对这两种情况分开讨论。
2.2.1 当
j
≠
k
j \neq k
j=k
∂
a
j
∂
z
k
=
∂
(
e
z
j
∑
i
=
1
K
e
z
i
)
∂
z
k
=
−
e
z
j
1
(
∑
i
=
1
K
e
z
i
)
2
e
z
k
=
−
e
z
j
∑
i
=
1
K
e
z
i
⋅
e
z
k
∑
i
=
1
K
e
z
i
=
−
a
j
a
k
(
8
)
\begin{split} \frac{\partial a_j}{\partial z_k} &= \frac{\partial(\frac{e^{z_j}}{\sum_{i=1}^Ke^{z_i}})}{\partial z_k} \\ & = -e^{z_j}\frac{1}{(\sum_{i=1}^Ke^{z_i})^2}e^{z_k} \\ & = -\frac{e^{z_j}}{\sum_{i=1}^Ke^{z_i}}·\frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}} \\ & = -a_ja_k ~~~~~(8) \end{split}
∂zk∂aj=∂zk∂(∑i=1Keziezj)=−ezj(∑i=1Kezi)21ezk=−∑i=1Keziezj⋅∑i=1Keziezk=−ajak (8)
2.2.2 当
j
=
k
j=k
j=k
∂
a
j
∂
z
k
=
∂
a
k
∂
z
k
=
∂
(
e
z
k
∑
i
=
1
K
e
z
i
)
∂
z
k
=
e
z
k
∑
i
=
1
K
e
z
i
−
(
e
z
k
)
2
(
∑
i
=
1
K
e
z
i
)
2
=
e
z
k
∑
i
=
1
K
e
z
i
(
1
−
e
z
k
∑
i
=
1
K
e
z
i
)
=
a
k
(
1
−
a
k
)
(
9
)
\begin{split} \frac{\partial a_j}{\partial z_k} &= \frac{\partial a_k}{\partial z_k}\\ &=\frac{\partial(\frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}})}{\partial z_k} \\ & = \frac{e^{z_k}\sum_{i=1}^Ke^{z_i}-(e^{z_k})^2}{(\sum_{i=1}^Ke^{z_i})^2} \\ & = \frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}}(1-\frac{e^{z_k}}{\sum_{i=1}^Ke^{z_i}}) \\ & = a_k(1-a_k)~~~~(9) \end{split}
∂zk∂aj=∂zk∂ak=∂zk∂(∑i=1Keziezk)=(∑i=1Kezi)2ezk∑i=1Kezi−(ezk)2=∑i=1Keziezk(1−∑i=1Keziezk)=ak(1−ak) (9)
2.2.3 将(7)、(8)、(9)代入(6)求解
∂
L
(
y
^
,
y
)
∂
z
k
=
∑
j
=
1
K
[
∂
L
(
y
^
,
y
)
∂
a
j
∂
a
j
∂
z
k
]
=
∑
j
=
1
K
[
−
y
j
a
j
∂
a
j
∂
z
k
]
=
−
y
k
a
k
∂
a
k
∂
z
k
+
∑
j
=
1
,
j
≠
k
K
[
−
y
j
a
j
∂
a
j
∂
z
k
]
=
−
y
k
a
k
a
k
(
1
−
a
k
)
+
∑
j
=
1
,
j
≠
k
K
[
−
y
j
a
j
⋅
−
a
j
a
k
]
=
y
k
(
a
k
−
1
)
+
∑
j
=
1
,
j
≠
k
K
y
j
a
k
=
−
y
k
+
y
k
a
k
+
∑
j
=
1
,
j
≠
k
K
y
j
a
k
=
−
y
k
+
a
k
∑
j
=
1
K
y
j
(
10
)
\begin{split} \frac{\partial L(\hat y,y)}{\partial z_k} & = \sum_{j=1}^K[\frac{\partial L(\hat y,y)}{\partial a_j}\frac{\partial a_j}{\partial z_k}] \\ & = \sum_{j=1}^K[-\frac{y_j}{a_j}\frac{\partial a_j}{\partial z_k}] \\ & = -\frac{y_k}{a_k}\frac{\partial a_k}{\partial z_k}+\sum_{j=1,j\neq k}^K[-\frac{y_j}{a_j}\frac{\partial a_j}{\partial z_k}] \\ & = -\frac{y_k}{a_k}a_k(1-a_k)+\sum_{j=1,j\neq k}^K[-\frac{y_j}{a_j}·-a_ja_k] \\ & = y_k(a_k-1)+\sum_{j=1,j\neq k}^Ky_ja_k \\ & = -y_k+y_ka_k+\sum_{j=1,j\neq k}^Ky_ja_k \\ & = -y_k+a_k\sum_{j=1}^Ky_j~~~~(10) \end{split}
∂zk∂L(y^,y)=j=1∑K[∂aj∂L(y^,y)∂zk∂aj]=j=1∑K[−ajyj∂zk∂aj]=−akyk∂zk∂ak+j=1,j=k∑K[−ajyj∂zk∂aj]=−akykak(1−ak)+j=1,j=k∑K[−ajyj⋅−ajak]=yk(ak−1)+j=1,j=k∑Kyjak=−yk+ykak+j=1,j=k∑Kyjak=−yk+akj=1∑Kyj (10)
ok,到这里已经初步求出了损失函数对
z
k
z_k
zk 的偏导。不过我们还可以对它进一步优化,所以我们现在考虑y的特点,前面说过:
y y y:单个训练样本label真实值, y = ( y 1 , . . . , y k ) y = (y_1,...,y_k) y=(y1,...,yk); 例如: y = ( 0 , 0 , 0 , 0 , 1 , 0 ) y = (0,0,0,0,1,0) y=(0,0,0,0,1,0)
也就是说向量y中只有一个值为1,所以 ∑ j = 1 K y j = 1 \sum_{j=1}^Ky_j = 1 ∑j=1Kyj=1 。
于是(9)式将变为:
∂
L
(
y
^
,
y
)
∂
z
k
=
a
k
−
y
k
(
11
)
\frac{\partial L(\hat y,y)}{\partial z_k} = a_k-y_k~~~~(11)
∂zk∂L(y^,y)=ak−yk (11)
其中,
- a k a_k ak: 单个训练样本属于第k类的预测值,为一个概率值。
- y k y_k yk: 单个训练样本属于第k类的真实值,取值0或1
到此为止,softmax最核心的偏导已经推导完毕。多么简约美妙的一个公式!
3.将(5)、(11)代入(4)求解L对
w
k
w_k
wk的偏导
∂
L
(
y
^
,
y
)
∂
w
k
=
∂
L
(
y
^
,
y
)
∂
z
k
⋅
∂
z
k
∂
w
k
=
(
a
k
−
y
k
)
x
\begin{split} \frac{\partial L(\hat y,y)}{\partial w_k}& = \frac{\partial L(\hat y,y)}{\partial z_k}·\frac{\partial z_k}{\partial w_k} \\ & = (a_k-y_k)x \end{split}
∂wk∂L(y^,y)=∂zk∂L(y^,y)⋅∂wk∂zk=(ak−yk)x
3.1 取出
b
k
b_k
bk
最开始说了,我们计算时先把 b k b_k bk 融进 w k w_k wk 了。现在将它取出来:
因为把
b
k
b_k
bk融合进
w
k
w_k
wk 后,
w
k
w_k
wk最后一个分量为
b
k
b_k
bk 。而
x
x
x最后一个分量为1。所以
z
k
z_k
zk对
w
k
w_k
wk 求偏导后,
b
k
b_k
bk那个分量对应的偏导就是1。所以
∂
L
(
y
^
,
y
)
∂
b
k
=
a
k
−
y
k
\frac{\partial L(\hat y,y)}{\partial b_k} =a_k-y_k
∂bk∂L(y^,y)=ak−yk
结果总结
好了,现在来总结一下softmax损失函数求偏导的结果:
∂
L
(
y
^
,
y
)
∂
w
k
=
(
a
k
−
y
k
)
x
∂
L
(
y
^
,
y
)
∂
b
k
=
a
k
−
y
k
\begin{split} & \frac{\partial L(\hat y,y)}{\partial w_k} = (a_k-y_k)x \\ & \frac{\partial L(\hat y,y)}{\partial b_k} =a_k-y_k \end{split}
∂wk∂L(y^,y)=(ak−yk)x∂bk∂L(y^,y)=ak−yk
更新权重
还记得梯度下降的步骤吗?
梯度下降更新权重时,是用的代价函数的偏导更新的,我们刚才求导的只是损失函数的偏导。所以还需要对它们求平均。
∂
J
∂
w
k
=
1
N
∑
i
=
0
N
−
1
(
a
k
−
y
k
)
x
∂
J
∂
b
k
=
1
N
∑
i
=
0
N
−
1
(
a
k
−
y
k
)
\begin{split} & \frac{\partial J}{\partial w_k} = \frac{1}{N}\sum_{i=0}^{N-1}(a_k-y_k)x \\ & \frac{\partial J}{\partial b_k} = \frac{1}{N}\sum_{i=0}^{N-1}(a_k-y_k) \end{split}
∂wk∂J=N1i=0∑N−1(ak−yk)x∂bk∂J=N1i=0∑N−1(ak−yk)
其中,N为本次参加训练的样本个数。另外,上述式子省去了上标
i
i
i,上标
i
i
i表示这是第i个样本。
顺带一提,像上面这种根据推出的结果反过去更新权重的流程,在神经网络中被称为
反向传播。
总结
softmax多分类模型的训练流程
给定训练集X,训练集X共分为K类:
-
随机初始化模型未知参数 θ \theta θ ,本篇文章中为随机初始化权重向量 w k , b k , k = 1 , 2 , . . . , K − 1 w_k,b_k,k=1,2,...,K-1 wk,bk,k=1,2,...,K−1。其中, w k w_k wk为向量, b k b_k bk 为标量。
-
梯度下降算法迭代更新模型参数直至收敛,每一轮具体流程如下:
- 先通过正向传播求得本轮训练样本预测值。
- 反向传播更新模型参数:
w k = w k − α ∂ J ∂ w k = w k − α 1 N ∑ i = 0 N − 1 ( a k − y k ) x , k = 0 , 1 , . . . , K − 1 b k = b k − α ∂ J ∂ b k = b k − α 1 N ∑ i = 0 N − 1 ( a k − y k ) , k = 0 , 1 , . . . , K − 1 \begin{split} & w_k = w_k - \alpha \frac{\partial J}{\partial w_k} = w_k-\alpha \frac{1}{N}\sum_{i=0}^{N-1}(a_k-y_k)x,\quad k = 0,1,...,K-1 \\ & b_k = b_k -\alpha \frac{\partial J}{\partial b_k} = b_k-\alpha \frac{1}{N}\sum_{i=0}^{N-1}(a_k-y_k),\quad k = 0,1,...,K-1 \end{split} wk=wk−α∂wk∂J=wk−αN1i=0∑N−1(ak−yk)x,k=0,1,...,K−1bk=bk−α∂bk∂J=bk−αN1i=0∑N−1(ak−yk),k=0,1,...,K−1
注意:上述公式省去了上标
i,上标i表示这是第i个样本。另外别把学习率的 α \alpha α和预测值 a a a搞混了,我写完了文章才发现这两个符号没处理好(写的长得比较像)。
softmax多分类模型的预测流程
经过训练后,模型参数已经确定。现在只需要用这些参数对需要预测的数据跑一遍正向传播就行。
不过可能在求出预测值后,需要加一步判断:哪个类别的概率最大,就认为该样本属于哪一类。
到此,整个softmax分类器说明完毕。
softmax多分类器的具体代码实现和应用
关于softmax的具体代码实现和应用将在下一篇文章介绍。在下一篇文章中,将会以经典的鸢尾花数据集为例,对其进行softmax多分类的手动代码实现。
下篇文章:【机器学习笔记14】softmax多分类模型【下篇】从零开始自己实现softmax多分类器(含具体代码与示例数据集)_Twilight Sparkle.的博客-CSDN博客

















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











