







文章目录
前言
本教程在前面教程的基础上安装Hadoop,需要的Hadoop安装包和配置文件在正文。如有错误,恳请兄弟姐妹们批评指正。
一、配置无密钥登录
在三台虚拟机分别执行以下操作
1.生成密钥文件

2.将公钥信息复制到授权文件

3.添加权限

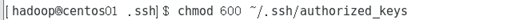
4.测试
如果可以不输密码就登录其他节点,说明配置成功。



配置无密钥登录是安装Hadoop的一个前提
二、安装Hadoop
1.上传安装包
我们使用xftp7将本地安装包上传到centos

这里我们使用的Hadoop版本是3.3.0,兄弟姐妹们可以去官网下载
同样可以使用我的这个安装包
链接:https://pan.baidu.com/s/1S6IJgHv1GHpKTydqwju10A
提取码:9870
2.解压
在centos01中,先将安装包移到softwares目录下,然后进入该目录解压

可以发现,该目录下已经有解压完的文件夹

3.重命名
进入modules目录下进行重命名

4.配置系统变量
4.1 配置
修改/etc/profile文件,这样我们不进入Hadoop的安装目录就能使用Hadoop相关命令。
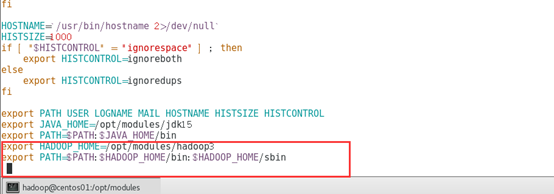
记得刷新

4.2 测试

输入hadoop后如果输出以上内容说明配置成功
5.修改~/.bashrc
只是配置好上一步的话,当我们新打开一个终端时必须刷新一下profile文件才能不进入Hadoop目录使用Hadoop命令。而修改了该文件可以解决这个问题

加入jdk和Hadoop目录

保存后记得刷新
6.配置Hadoop环境变量
这一步需要修改三个文件,分别是hadoop-env.sh mapred-env.sh yarn-env.sh。这三个文件位于hadoop3/etc/hadoop下。
分别执行以下命令并加入代码,见下图。




7.配置HDFS
这一步需要修改三个文件,分别是core-site.xml hdfs-site.xml workers
需要添加的内容在下面
链接:https://pan.baidu.com/s/1Dyd9qhw778DkV7JwMxOjvg
提取码:9870
兄弟姐妹们只需要复制粘贴即可。注意格式哦
workers文件还要注意每一个主机名占一行,后面不要有空格
这三个文件中各属性的含义含兴趣的兄弟姐妹可以自行百度,这里不再赘述。
7.1 core-site.xml


7.2 hdfs-site.xml


7.3 workers

8.配置YARN
这一步需要修改两个文件,分别是mapred-site.xml yarn-site.xml
需要添加的内容在下面
链接:https://pan.baidu.com/s/15EpbtxCVwJqb1N-XNRv6Rg
提取码:9870
8.1 mapred-site.xml


8.2 yarn-site.xml


9.复制到其他节点
打开另外两台虚拟机然后再复制


10.格式化NameNode
在centos01上格式化namenode

11.启动Hadoop
由于之前已经配置了环境变量,所以不在Hadoop安装目录下也能使用Hadoop命令
start-all.sh启动Hadoop集群

也可以使用start-dfs.sh和start-yarn.sh分别启动hdfs和yarn
12.测试
12.1 查看各节点的进程
分别在三个节点输入jps查看当前运行的进程
centos01中

centos02中

centos03中

只有显示如上才说明Hadoop安装成功
12.2 创建目录测试
输入以下命令在hdfs上创建目录

打开浏览器输入http://centos01:9870进入wen页面
点击utilities可以查看hdfs中的文件

总结
至此,我们成功地安装了Hadoop,如果期间遇到问题,兄弟姐妹们可以选择百度或者按此教程每一步检查一下。如果还是不行直接把安装目录删掉重新配置,可以解决99%的问题[滑稽]。















 2590
2590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









