







文章是整理的如何不费力的理解self-attention公式的方法,以及如何理解其中的代码
这是文章结构,按照如下流程:
简化版self-attention(无矩阵权重)——self-attention——Causal attention——Multi-head attention
就可以掌握self-attention及其变种的由来。
一、简化版self-attention
这里的简化版,指的就是无矩阵权重。
对于应用attention机制的transform架构而言,主要解决的是什么问题呢?
通过注意力机制,网络的文本encoder部分能够有选择地访问所有输入token,这意味着某些输入token在生成特定输出标记时比其他输入token更重要。而attention就是放大网络对特定token的重要程度,增加其的关注度。
(1)Tokenizer分词器
上面可能看的人有点迷糊,让我们切换到一个机器翻译的具体任务上。

我们的目标很简单,就是把这段德语句子转化成英语。由于这些单词并非计算机所能编码传输的形式,对于输入的语料,经过tokenizer后转化成token后,这里的token指的是计算机所能处理最小单元,有不同的tokenizer,得到的token也不同,但输入和输出的高维映射是不变的。
这里的token在计算机内存中是以数字形式展现,比如说英语句子,Can you help me? can对应token是1,you对应token是2,help对应token是3,me对应token是4,?对应的token是5,因此这个句子经过tokenizer,得到的token是[1, 2, 3, 4, 5].
(2)上下文向量context vector计算
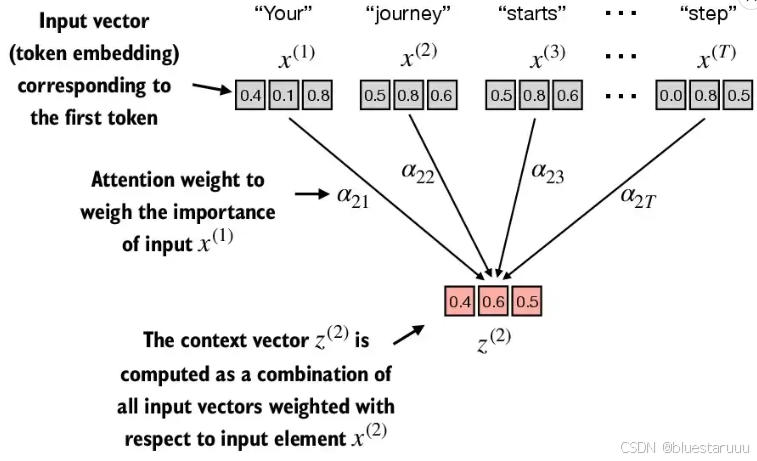
在把输入都转化成token之后,就遇到一个问题,怎样确定需要预测的query和已知的input之间的对应关系?
虽然我们不能得到类似数学函数那样的一一映射,但是可以研究query和input之间的关联性,在这里的关联性就是权重。权重的计算方式也非常简单,计算query和input的点积即对应的权重。
因此可以得到输入的query和input各个x的权重,这里的输入是,如图所示,
是一个d维向量,代表单词your,其余类推。
目标:计算对于每一个 的对应上下文向量
的对应上下文向量
是
的加权和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









