







优化九:编译器控制的预取以减少丢失惩罚或丢失率
硬件预取的替代方案是编译器在处理器需要数据之前插入预取指令来请求数据。
预取有两种类型:
■ 寄存器预取将值加载到寄存器中。
■ 高速缓存预取仅将数据加载到高速缓存。
这两种类型都可以分为有错或无错的,即预取的地址是否会导致虚拟地址错误或保护错误的异常。使用这个术语,一个普通的加载指令可以被认为是一个“有错的寄存器预取指令”。无错的预取指令如果遇到异常,就会变成空操作。
最有效的预取是“对程序语义不可见”的:它不改变寄存器和内存的内容,也不会引起虚拟内存错误。现在大多数处理器都提供无错的缓存预取指令。这一节假设使用无错的缓存预取,也叫非绑定预取。
预取技术只有在处理器可以在预取数据的同时继续执行时才有意义;也就是说,缓存不会停顿,而是在等待预取数据返回的同时继续提供指令和数据。这样的计算机的数据缓存通常是非阻塞的。和硬件控制的预取一样,目标是让执行和预取数据重叠。
循环是重要的目标,因为它们适合于预取优化。如果不命中代价很小,编译器只需要展开循环一次或两次,并将预取和执行调度起来。如果不命中代价很大,它就使用软件流水或者展开很多次来预取未来迭代的数据。发出预取指令会产生指令开销,所以编译器必须小心确保这种开销不会超过收益。通过专注于可能是缓存不命中的引用,程序可以避免不必要的预取,同时显著提高平均内存访问时间。
优化十:利用HBM扩展内存层次
HBM是High Bandwidth Memory的缩写,是一种高速的计算机内存接口,用于三维堆叠的同步动态随机存取存储器(SDRAM)。HBM的特点是将多个DRAM芯片通过硅通孔(TSV)技术垂直堆叠在一起,并与处理器封装在同一个芯片内,实现了高容量、高带宽、低功耗和低延迟的内存方案。
由于大多数通用服务器处理器需要的内存容量超过了HBM封装技术能够提供的范围,所以有人提出了将封装在处理器内部的DRAM用作大容量的L4缓存,这些缓存的容量可以达到128 MiB到1 GiB甚至更多,远远超过了当前片上L3缓存的容量。使用这样大的基于DRAM的缓存会引起一个问题:标记(tag)应该放在哪里?这取决于标记的数量。假设我们使用64B的块大小,那么一个1 GiB的L4缓存需要96 MiB的标记,这比CPU上的缓存中存在的静态内存还要多。将块大小增加到4 KiB,可以显著减少标记存储,只需要256 K个条目或者不到1 MiB的总存储空间,这可能是可以接受的,考虑到下一代多核处理器中L3缓存的容量为4~16 MiB或者更多。
然而,这样大的块大小有两个主要问题。第一,缓存可能会被低效地使用,当许多块中的内容不需要时;这被称为碎片化问题,它也出现在虚拟内存系统中。此外,传输这样大的块如果大部分数据没有被使用也是低效的。第二,由于块大小很大,缓存中能够保存的不同块的数量就很低,这可能导致更多的不命中,特别是冲突和一致性不命中。解决第一个问题的一个部分解决方案是添加子块(subblock)。子块允许块中的部分数据是无效的,需要在不命中时才获取它们。子块技术,然而,并不能解决第二个问题。
标记存储是使用较小块大小的主要障碍。一个可能的解决方案是将L4缓存的标记存储在HBM中。乍一看这似乎是行不通的,因为每次访问L4缓存都需要两次访问DRAM:一次是为了标记,另一次是为了数据本身。由于随机访问DRAM所需的时间很长,通常是100个或更多处理器时钟周期,所以这种方法被放弃了。Loh和Hill(2011)提出了一个巧妙的解决方案:将标记和数据放在HBM SDRAM中的同一行中。虽然打开行(最终关闭它)需要很长时间,但是访问行中不同部分所需的CAS延迟只有新行访问时间的三分之一左右。因此我们可以先访问块中的标记部分,如果命中了,那么再使用列访问来选择正确的字。Loh和Hill(L-H)提出了一种组织L4 HBM缓存的方法,使得每个SDRAM行由一组标记(在块头部)和29个数据段组成,构成一个29路组相联缓存。当访问L4时,打开适当的行并读取标记;如果命中,则再进行一次列访问以获取匹配数据。
Qureshi和Loh(2012)提出了一种改进方法,称为合金缓存(alloy cache),可以减少命中时间。合金缓存将标记和数据融合在一起,并使用直接映射的缓存结构。这样可以将L4访问时间减少到一个HBM周期,通过直接索引HBM缓存并进行标记和数据的突发传输。
合金缓存相比L-H方案,将命中时间减少了超过两倍,但是以增加不命中率1.1~1.2倍为代价。在这两种方案中,不命中都需要两次完整的DRAM访问:一次是为了获取初始标记,另一次是为了访问主存(这甚至更慢)。如果我们能够加快不命中检测,我们就能够减少不命中时间。有两种不同的解决方案来解决这个问题:一种是使用一个映射来跟踪缓存中的块(不是块的位置,只是是否存在);另一种是使用一个内存访问预测器,使用历史预测技术来预测可能的不命中,类似于用于全局分支预测的技术。
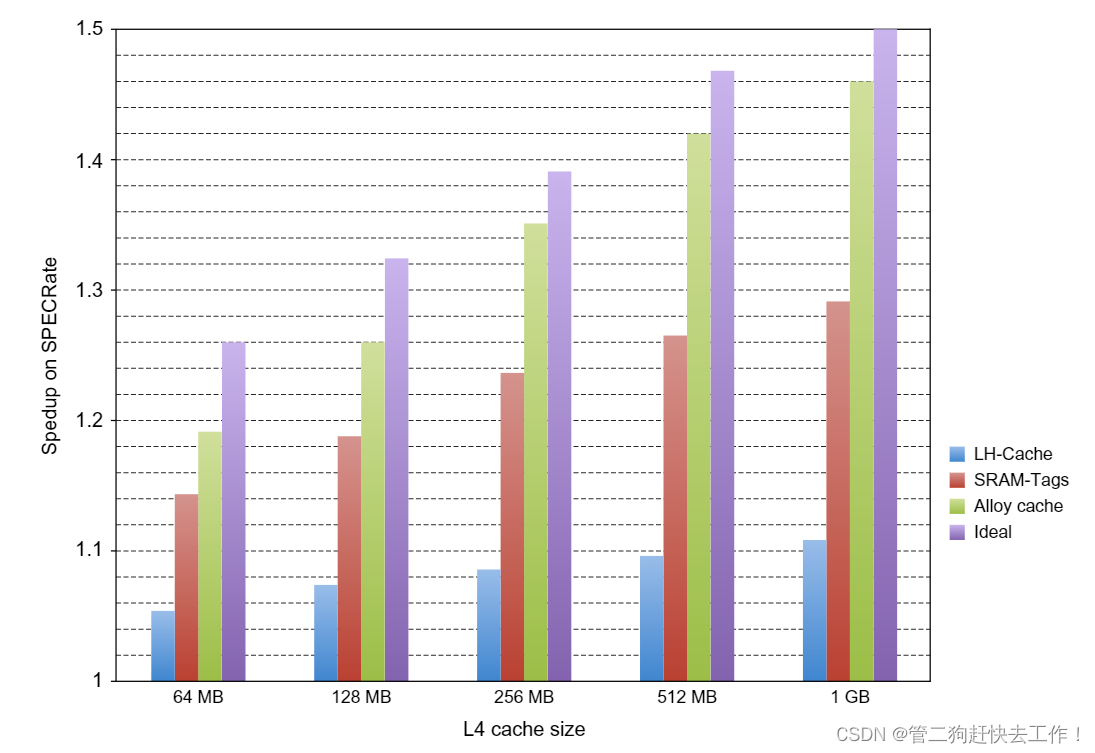
运行 LH 方案、SRAM 标签方案和理想 L4(理想)的 SPECrate 基准测试时的性能加速; 加速 1 表示 L4 缓存没有任何改进,如果 L4 完美并且不占用访问时间,则可以实现 2 的加速。 使用 10 个内存密集型基准测试,每个基准测试运行八次。 使用随附的未命中预测方案。 理想情况假设仅需要访问和传输 L4 中请求的 64 字节块,并且 L4 的预测精度是完美的(即,以零成本知道所有未命中)。















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











