







2021RTSS:Balancing Energy Efficiency and Real-Time Performance in GPU Scheduling
目录
一、背景介绍
- GPU的流行和应用:如今,GPU因其卓越的性能在嵌入式平台上已经非常流行。将需要大量计算和并行处理的任务卸载到GPU上,可以显著提升网络物理系统和自主应用的性能。
- 实时多任务的重要性:实时多任务处理是开发这种GPU加速应用的基本前提。例如,用户可以创建多个流,并将独立的内核分配到这些流中以实现并行内核执行,从而实现加速并提高GPU资源效率。
问题分析
- 功耗管理的必要性:功耗管理是嵌入式环境中高效使用GPU的主要因素之一。适当的功耗管理可以减少由于内核同步和资源利用造成的能源浪费,提高系统的可扩展性和可靠性,并减少额外的冷却需求。
- 空间多任务调度的问题:每个内核可能无法充分利用GPU的所有内部计算单元。为更好地利用GPU资源并减少多个GPU内核共享GPU时的等待时间,最近的一些实时GPU调度方案采用了空间多任务方法,将GPU划分为计算单元,使两个或两个以上的内核可以同时在GPU上运行。这种方法虽然提高了实时性能和资源效率,但在能耗方面考虑较少。
研究问题
- 能耗增加:采用空间多任务调度的GPU内核的能耗可能比一次只执行一个内核的简单方法要高。这是因为大多数商用GPU缺乏细粒度的功率门控,因此当使用空间多任务时,即使某些计算单元处于闲置状态,它们仍然会消耗动态功率。同时,分配较少计算单元的内核执行时间更长,从而进一步增加能耗。
sBEET框架
- sBEET框架介绍:本文提出了sBEET,一个在嵌入式GPU上平衡能效和实时性能的调度框架。sBEET在运行时根据功率模型计算的能耗预测,做出计算资源(如NVIDIA GPU中的流多处理器)分区的调度决策。通过这种方法,sBEET允许同时执行内核来提高实时性能,同时减少GPU的能耗。
主要贡献
- 能耗分析:推导了GPU内核在使用和不使用空间多任务时的功耗和能耗分析,发现空间多任务的使用可能导致更高的能耗。
- 运行时调度算法:开发了一种运行时调度算法,通过动态调整资源分区程度,减少非抢占式GPU内核的截止时间未命中,并在现有空间多任务方法上提高了能效。
- 实验验证:通过在最新商用嵌入式GPU平台上的一系列实验场景,展示了sBEET在实时性能和能耗方面的实际效果。
二、相关知识
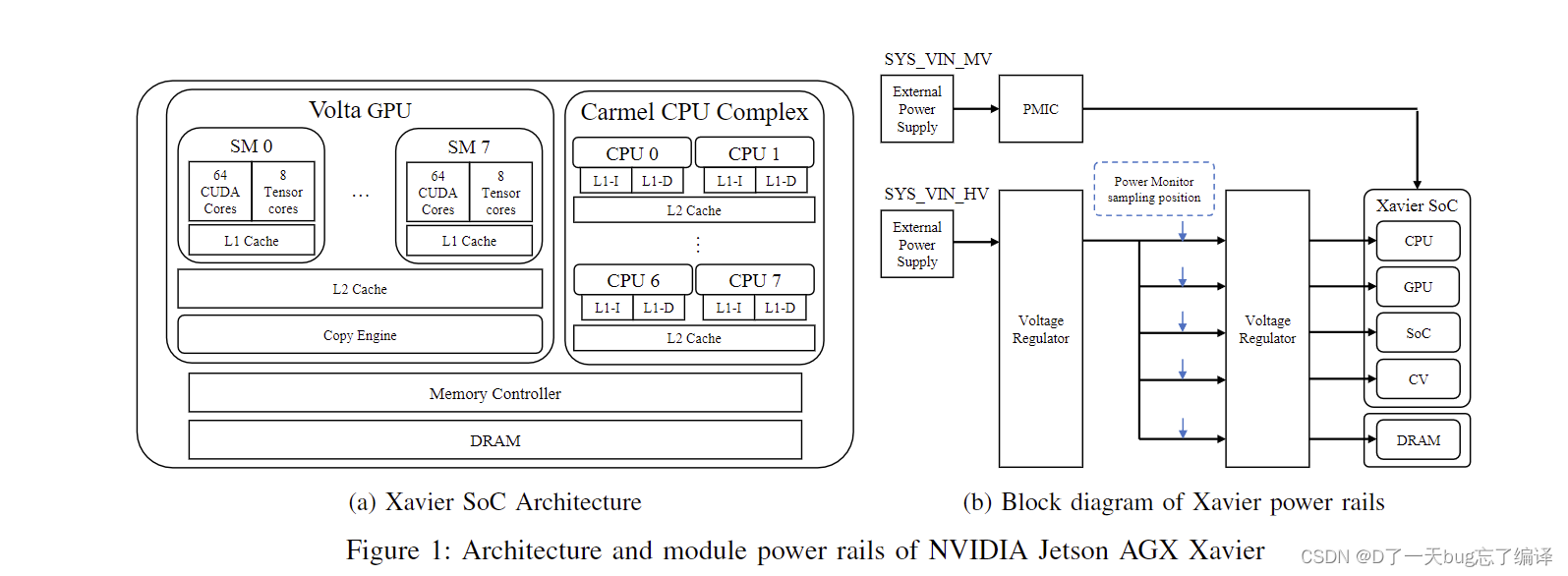
NVIDIA Jetson AGX Xavier
这篇文章讨论的是最新的嵌入式GPU平台NVIDIA Jetson AGX Xavier,其架构如图1a所示。该平台使用的系统芯片(SoC)具有以下特点:
- Carmel CPU Complex:包含八个64位ARMv8 Carmel CPU内核,每个内核运行频率为2265MHz,配有128KB的指令缓存和64KB的数据缓存。每两个内核共享2MB的L2缓存,所有CPU内核共享一个4MB的L3缓存。
- Volta GPU:集成了512个核心的Volta GPU,GPU和CPU共享16GB的2133MHz内存,整个系统功耗低于30瓦。GPU包括八个执行引擎(也称为流多处理器SM),每个SM包含64个CUDA核心和8个Tensor核心。每个SM有128KB的L1缓存,所有SM共享一个512KB的L2缓存。此外,还包括多个其他计算单元和加速器,如深度学习加速器(DLA)、视觉加速器和视频编码/解码器。
SM组织和内核执行
CUDA编程模型提供了用户可以直接与之交互的GPU架构抽象。执行任何CUDA程序的一般步骤包括:
- 在CPU和GPU两侧分配内存。
- 将输入数据从CPU内存复制到GPU内存。
- 执行GPU程序。
- 将结果从GPU内存复制到CPU内存。
- 释放GPU内存。
运行在GPU上的部分称为CUDA内核,每个内核由不同的CUDA线程并行执行。线程的集合称为线程块,线程块被组织成网格。用户在启动内核之前定义块和网格的数量。用户还可以使用CUDA流实现多个CUDA内核的并行执行,每个流管理一个FIFO队列用于内核执行。一旦内核在GPU上启动,其执行不能被抢占(除非来自具有更高优先级的流的另一个内核)。线程块几乎以循环方式分配到SM上,不能在SM之间迁移。一个SM可以根据资源需求(如共享内存、线程数量和寄存器文件数量等)同时运行多个块。默认情况下,内核使用GPU的所有SM并按先进先出(FCFS)顺序执行。
Xavier AGX的功耗管理
Jetson AGX Xavier有两个输入电压轨:SYS VIN HV和SYS VIN MV,每个轨具有不同的输入电压范围,即SYS VIN HV为9V至19V,SYS VIN MV为5V。设备可以在这些电压轨之间切换以提高功率效率。图1b中的电压轨的功耗可以通过内置功率监视器测量,其范围高达26V。为了在设备检测到闲置时优化功率效率,设计了一些与电路相关的功率管理机制:
- 时钟门控:移除时钟信号。
- 功率门控:关闭电路内的电源。
- 轨道门控:关闭整个轨道的电源。
GPU同时支持轨道门控和时钟门控,但电路如何工作的具体细节尚未公开。不过,实验确认即使在最新的Xavier AGX GPU上,也没有实现SM级别的功率/时钟门控。
三、系统模型和假设
任务集模型
文章中考虑的任务集 Γ 由 n 个实时非抢占周期任务组成,每个任务具有受限的截止时间。重点关注内核执行和内存复制操作。每个任务 τi 的特征如下:
:任务
单个作业的GPU部分的累积最坏情况执行时间(包括内存复制和内核)。
- Ti:周期或最小到达时间间隔。
- Di:每个作业的相对截止时间,且 Di≤Ti
任务 τi由一系列作业 组成,其中
表示任务 τi 的第 j个作业。根据空间GPU多任务的思想,每个任务
的作业
可以分配不同数量的SM进行执行。因此,我们使用
表示作业
的最坏情况执行时间,其中 m 表示分配给
的SM数量。
任务执行时间的组成
:从主机到设备内存的最坏情况数据复制时间。
:分配了 m 个SM时,作业
的最坏情况内核执行时间。
:从设备到主机内存的最坏情况数据复制时间。
任务利用率
任务 τi 的利用率定义为分配不同数量的SM时的平均利用率,计算公式为:。其中 M 是设备上SM的总数,而
。需要注意的是,
,反之 τi无论分配多少SM都不能调度。
作业的分类
根据内核执行时间 ,每个作业
可以分类为线性加速或非线性加速:
- 线性加速作业:如果
。 这种情况适用于通常具有大量线程块且内存需求合理的内核,因为分配更多的SM时,这些内核的线程块可以均匀分布在SM上并行执行。
- 非线性加速作业:如果存在一种情况,即加速与分配的SM数量不成线性关系,即
。 这种情况发生在只有少量线程块或饱和GPU的内存资源(例如带宽、共享内存、寄存器等)的内核上。
四、相关工作
GPU上的时间多任务处理
先前一些工作已经在时间域中改进了GPU的利用率:
- TimeGraph:这是一个实时GPU任务调度器,它为不同优先级的任务分配时间预算,并定期补充这些预算【TimeGraph: GPU scheduling for real-time multi-tasking environments】。
- Elliott等人:他们将GPU建模为共享资源,并使用实时同步协议将GPU集成到实时多处理器系统中【Globally scheduled real-time multiprocessor systems with GPUs】。
- Kim等人:他们提出了一种基于服务器的方法,解决了同步方法中的忙等待和长优先级反转问题【A server-based approach for predictable GPU access with improved analysis】。
上述方法将GPU任务视为非抢占式任务。另一方面,一些其他工作引入了基于软件的机制来实现实时GPU任务的抢占式调度。关键思想是将长时间运行的内核分解成更小的段,以便在这些段的边界上进行抢占【Supporting preemptive task executions and memory copies in GPGPUs】【RGEM: A responsive GPGPU execution model for runtime engines】【GPES: a preemptive execution system for GPGPU computing】。
然而,无论GPU任务是否可抢占,时间多任务处理都可能面临资源未充分利用的问题,因为每个GPU任务可能无法充分利用GPU的所有计算单元【The case for GPGPU spatial multitasking】。此外,如果非抢占式调度GPU任务,它们可能会经历长时间的等待时间。抢占式调度的使用可以减少这种等待时间,但实现基于软件的机制并不简单,因为它们需要修改设备驱动程序,而最近的GPU所提供的硬件级抢占仅有有限的优先级级别(例如,NVIDIA Pascal和Volta架构中仅有两个优先级【Volta tuning guide】)。
GPU上的空间多任务处理
空间多任务处理,也称为空间资源共享或GPU分区,重点是多个任务可以在GPU的不同计算单元子集上同时执行。以下是一些相关工作:
- Jain等人:他们提出了对计算单元以及板载DRAM进行空间分区,以实现并行内核执行、更好的资源利用和性能隔离【Fractional GPUs: Software-based compute and memory bandwidth reservation for GPUs】。
- Sun等人:他们提出了通过考虑GPU内核执行前的长数据传输时间并将内核建模为可成型并行作业,最小化GPU内核静态调度的完工时间的算法【Real-time scheduling upon a host-centric acceleration architecture with data offloading】。
- Kang等人:他们专注于移动延迟敏感工作负载,并提出了空间资源预留技术,为高优先级任务保留计算单元,以帮助减少前台应用被后台任务阻塞的时间【Priority-driven spatial resource sharing scheduling for embedded graphics processing units】。
- Wang等人:他们开发了一种质量服务(QoS)机制,根据各个GPU内核的QoS目标动态分配资源【Quality of service support for fine-grained sharing on gpus】。
- Saha等人:他们提出了结合时间和空间多任务的空间时间GPU管理(STGM),在速率单调(RM)策略下提高任务集可调度性【Stgm: Spatio-temporal gpu management for real-time tasks】。
GPU节能的资源分配
以下是一些关于GPU节能资源分配的相关工作:
- Wang和Ranganathan:他们开发了一种指令级预测机制,通过估算应用程序所需的SM数量来节省能量【An instruction-level energy estimation and optimization methodology for GPU】。
- Wang等人:他们提出了电源门控策略,以关闭未使用的资源。由于切换开销通常会导致负能量节省,他们确保未使用的电路保持关闭足够长的时间以补偿开销【Power gating strategies on GPUs】。
- Hong和Kim:他们提出了一种综合功率和性能预测方法,通过建立基于资源的功率模型,找到每个工作负载的最佳SM数量,以实现最高的每瓦性能【An integrated GPU power and performance model】。他们还提出了一种理论方法,如果电路级支持电源门控,未使用的SM可以通过电源门控机制关闭。
- Aguilera等人:他们提出了QoS感知动态资源分配,并在GPGPU-Sim中实验证明了该方法的有效性【QoS-aware dynamic resource allocation for spatial-multitasking GPUs】。
- Sun等人:他们提出了一种运行时QoS管理机制,动态调整SM分配,使闲置的SM可以通过电源门控减少能耗【Smqos: Improving utilization and energy efficiency with qos awareness on gpus】。
- Zahaf等人:他们提出了一种异构多核处理器(如ARM big.LITTLE)的能耗和性能的一般模型,并提出了一种启发式方法,以减少软实时可成型并行任务的能耗【Energy-efficient scheduling for moldable real-time tasks on heterogeneous computing platforms】。
- Tasoulas等人:他们根据资源需求对GPU工作负载进行分类,并在GPGPU-Sim中通过配对工作负载和电源门控未使用的SM实现能量节省【Improving GPU performance with a power-aware streaming multiprocessor allocation methodology】。然而,这些结果不能直接应用于实际硬件平台,因为当今的GPU尚未实现每个SM的电源门控。
五、 sBEET框架
A. 功率和能量分析
功率模型: Isci和Martonosi提出了一个最初为CPU功率建模设计的通用框架,它将总功耗P定义为来自闲置内核(在案例中是SMs)的闲置功率、泄漏功率(静态功率)
和来自活动SMs的动态功率
的总和。按照这种方法,时间t的GPU瞬时功耗可以写成:
取决于内核特性,包括内存访问和使用的SMs数量。
可以分解为每个作业消耗的每SM功率的线性和。对于一组在时间t同时在GPU上执行的作业J={J1, J2, ..., Jn},可以重写为:
需要注意的是,当GPU的所有SM都处于闲置状态时,GPU处于功率门控状态,没有来自和
的功耗。此外,由于动态(和闲置)功耗与活动(和闲置)SM数量成线性关系,以下条件成立:
使用P,时间段[t1, t2]内GPU的能耗可以计算如下:
现在考虑一组在时间段[t1, t2]内调度在GPU上的作业J={J1, J2, ..., Jn}。根据调度决策,J中的一些作业在时间可能是活动的,而其他作业可能是闲置的。我们定义一个二进制指标
,如果第k个SM在时间t被作业Ji使用,则返回1,否则返回0。使用这个指标:
定理1: 如果J中的作业是线性加速作业,则带有空间多任务的作业集J的调度不能比不带空间多任务的调度更节能。(“空间多任务”是指在GPU上同时运行多个任务的能力)
证明: 考虑一个由两个作业组成的作业集,J={J1, J2},它们在时间t1同时到达。对于该作业集,有两种可能的调度可以在有和没有空间多任务的情况下获得:(a)在M个SM上顺序执行第一个作业J1,然后在M个SM上执行第二个作业J2(无空间多任务),以及(b)在m1个SM上同时执行J1,在m2个SM上同时执行J2,其中m1 + m2 = M(带空间多任务)。为方便起见,假设,即J2比J1完成得晚。
为了评估这两种调度的能效,考虑一个时间间隔,这个时间间隔足够长,可以在这两种调度下完成作业集的执行。时间间隔δ内这两种调度的能耗分别如下:
假设存在一种情况,使得带空间多任务的调度比不带空间多任务的调度更节能,即∃m1∃m2,。由于我们考虑的是线性加速作业,因此
,其中
被假设为一个已知常数。然后,
。
对于任何m,,所以前两项为0,
这导致了。这与我们的假设矛盾。
引理2: 对于非线性加速作业,定理1不一定成立。
定理1表明,对于线性加速作业,空间多任务策略不可避免地会导致一些SM在GPU活动时处于闲置状态;因此,闲置SM的功耗会影响调度的整体能耗,这种调度的能效低于不带空间多任务的调度。然而,引理2打开了一种可能性,即对于每个非线性加速作业,可能存在一个最优的SM数量,使其能效最高。
定义1: 任务的能量最优SM数量
被定义为在任意时间间隔
内,该任务执行时能耗最低的SM数量。
这是在所有可能的SM数量分配情况下,任务τi的最大执行时间。
时间间隔举例说明
假设我们有一个任务τi,在不同的SM分配下其执行时间如下:
- 分配1个SM:执行时间为20秒
- 分配2个SM:执行时间为10秒
- 分配4个SM:执行时间为5秒
在这种情况下,任务τi的最大执行时间是20秒(当分配1个SM时)。因此,时间间隔δ至少需要是20秒,以确保我们可以完整地观察任务在所有SM分配情况下的执行过程。
示例1: 考虑一个任务集Γ,其中包含以下两个在具有M个相同计算单元的GPU上的线性加速任务。这些任务的内存复制操作和GPU执行时间列在表I中。这些任务运行在不同的CUDA流中,因此可以进行同步内存复制和并行内核执行。考虑以下两种情况:带和不带空间多任务调度这两个任务的调度。

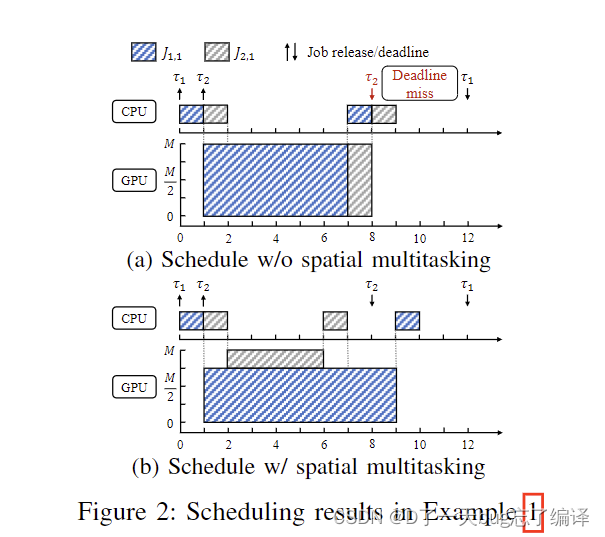
图2a显示了不带空间多任务的调度。由于只有两个任务且τ1比τ2先到达,任何节能调度策略都会产生相同的调度。在t = 0时,J1被调度到GPU上,因为没有其他作业准备好。内存复制后,它在[1, 7)期间占用了所有GPU核心。接下来的作业在t = 1到达,但由于被
阻塞,
的GPU执行不能在t = 7之前开始,最终它错过了截止时间。
图2b显示了带空间多任务的调度。通过使用4个SM运行,两个作业
和
可以在不丢失截止时间的情况下进行调度。然而,图2b中的调度能耗大于图2a中的调度能耗,这可以从定理1中容易推导出来。
综上所述,上述示例表明,使用不带空间多任务的GPU作业调度由于较早作业的阻塞时间可能会导致截止时间错过。虽然使用空间多任务解决了这个问题,但它可能会增加能耗,因为减少了所有GPU单元闲置的时间,如上述分析所示。受此示例启发,我们的目标是:(i)通过利用空间多任务技术来最小化截止时间错过,(ii)通过在可能的情况下运行每个作业与最优数量的SM来最大化减少能耗的机会。
B. Scheduling Framework
框架设计
-
服务器和工作线程:
- sBEET由一个服务器和多个工作线程组成。与NVIDIA的多处理服务(MPS)类似,服务器接收GPU任务并分配给工作线程,每个工作线程在独立的CUDA流上运行。
- 这样,sBEET可以在需要时启用空间多任务以实现并行内核执行。
-
工作线程数量限制:本文将工作线程的数量限制为两个
-
初始化阶段
工作线程和CUDA流的创建:- 服务器在初始化阶段创建两个工作线程和两个CUDA流,每个工作线程绑定到一个流。
- 当任务被分配给工作线程时,它将在相应的CUDA流上运行。
- 工作线程通过一个全局共享数据结构相互通信,该数据结构也是在初始化阶段创建的。
任务信息的存储: - 每个任务的WCET、功耗配置文件和最优SM数量也存储在服务器中。

运行时调度算法(算法1)
-
输入:
:当前可用的SM集合。
-
过程:
-
GPU闲置时:
- 如果所有SM都可用,调用SM分配算法(算法2)来获得为任务
。
- 如果找到有效的SM分配,则执行任务并将其从准备队列中移除。
- 如果所有SM都可用,调用SM分配算法(算法2)来获得为任务
-
GPU部分闲置时:
- 如果部分SM可用,将当前正在运行的任务
和新任务
- 如果找到有效的SM分配,则执行任务并将其从准备队列中移除。
- 如果部分SM可用,将当前正在运行的任务
-
SM分配失败时:
- 如果找不到有效的SM分配,或所有SM都忙,重复上述过程,直到所有任务都被访问
-

SM分配算法(算法2)
-
输入:
-
过程:
-
GPU闲置时:
- 从最大SM数开始迭代分配,直到找到一个最优的SM数。
- 计算生成调度的预期能耗,选择能耗最小的可行调度。
-
GPU部分使用时:
- 比较两种情况的预期完成时间:(1)立即用最优SM数执行
- 如果第二种情况更快,返回空,表示不立即执行新任务,否则分配SM并生成调度。
- 比较两种情况的预期完成时间:(1)立即用最优SM数执行
-

调度生成算法(算法3)
-
输入:
- m′:
:时间间隔。
:在
-
过程:
-
初始化:
- 将
时刻,使用 m′个SM。
- 如果当前没有正在运行的任务
。
- 否则,将
(任务
为
,即
- 将
-
考虑其他任务:
- 初始化剩余SM数量
为当前时刻的未使用SM数。
- 按到达时间的升序遍历
- 对每个任务,计算需要分配的SM数
- 如果没有剩余的SM,则跳过此任务。
- 将
安排在
- 更新下一个时间点
。
- 对每个任务,计算需要分配的SM数
- 初始化剩余SM数量
-
安排主要任务:
- 第3行:将主要任务 Ji,j 安排在当前时间 tnow,使用 m′ 个SM。
- 第4-9行:如果没有其他任务在运行,设置下一个时间点为当前时间;否则,安排正在运行的任务并更新下一个时间点为两个任务中较早的完成时间。
安排其他任务:
- 第10-16行:初始化剩余SM数量,并遍历其他预期到达的任务,计算所需的SM数,如果没有剩余的SM,则跳过该任务。
- 第17-22行:将其他任务安排在适当的时间点,并更新下一个时间点。如果到达预定结束时间,则停止调度生成。
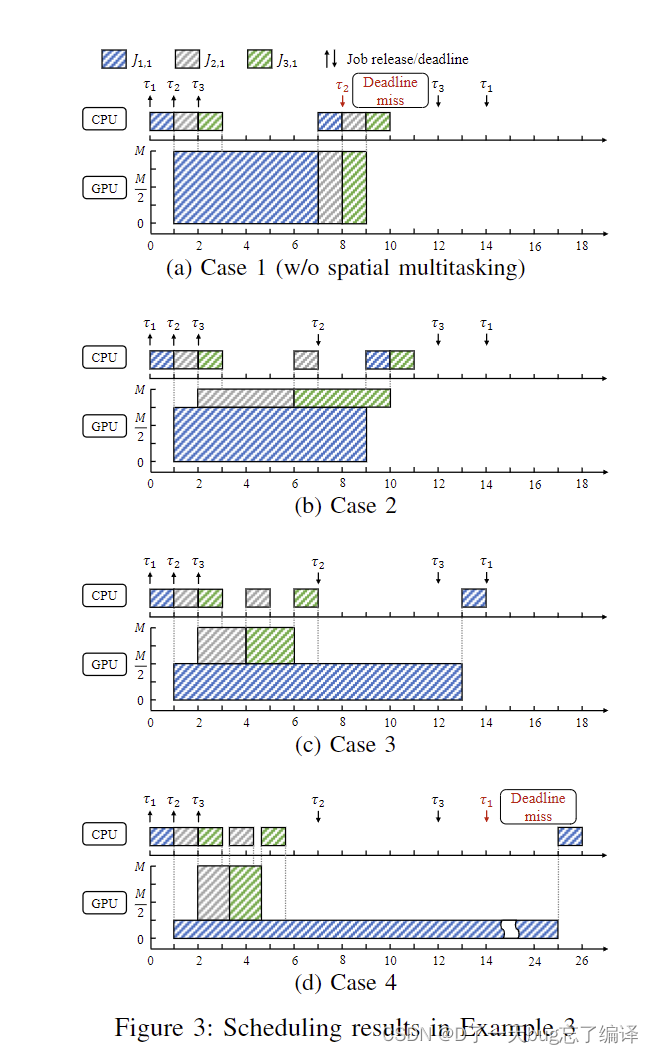
任务集和配置
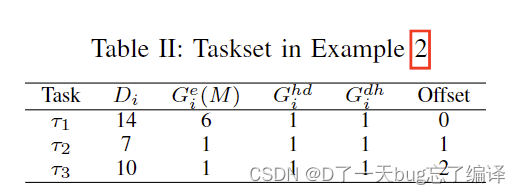
四种调度情况
图3展示了四种不同的调度情况:
图3(a): 不带空间多任务的调度 (Case 1)
- 在t = 0时,任务 τ1 到达并开始执行。
- 它在内存拷贝后,从 [1, 7) 期间占用所有的SM。
- 在t = 1,任务 τ2 到达,但由于被 τ1 阻塞,它无法在t = 7之前开始执行,最终错过了截止时间。
- 在t = 2,任务 τ3 到达,但同样被 τ1 阻塞。
图3(b): 空间多任务调度 (Case 2)
- 在t = 0时,任务 τ1开始执行,但这次它只占用 3/4 *M的SM。
- 这样,任务 τ2和 τ3\ 可以在 t=1和 t=2开始执行,占用剩余的 M/4的SM。
- 所有任务在各自的截止时间前完成,没有任务错过截止时间。
图3(c): 空间多任务调度 (Case 3)
- 在t = 0时,任务 τ1 开始执行,这次它占用 M/2 的SM。
- 这样,任务 τ2 和 τ3 可以在 t=1 和 t=2 开始执行,占用剩余的 M/2 的SM。
- 所有任务在各自的截止时间前完成,没有任务错过截止时间。
图3(d): 空间多任务调度 (Case 4)
- 在t = 0时,任务 τ1 开始执行,但这次它只占用 M/4 的SM。
- 这样,任务 τ2和 τ3 可以在 t=1 和 t=2 开始执行,占用剩余的 3M/4的SM。
- 然而,由于 τ1占用的SM太少,它的执行时间被大幅延长,导致 τ1 在截止时间后完成,错过了截止时间。
分析和结论
-
能耗分析:
- 图3(a):由于没有空间多任务,所有任务依次执行,导致 τ2错过截止时间。
- 图3(b) 和 图3(c):通过空间多任务技术,所有任务可以并行执行,且在截止时间前完成,节省了能耗。
- 图3(d):虽然使用了空间多任务,但由于 τ1 分配的SM过少,执行时间被延长,导致 τ1 错过截止时间。
-
调度优化:
- 图3(b) 和 图3(c) 展示了不同SM分配下的空间多任务调度。两者都能使所有任务在截止时间前完成,但需要权衡SM分配以优化能耗和执行时间。
- 图3(d) 说明了SM分配不足会导致任务执行时间延长,可能会错过截止时间。
六、结论
空间多任务的能耗分析
论文首先分析了空间多任务对GPU能耗的影响。尽管空间多任务可以同时执行多个GPU内核,提高任务调度的可调度性,但在SM闲置时仍会消耗电能。具体来说,当一些SM未被使用时,它们仍然会消耗静态功耗和部分动态功耗,这降低了整体的能效。
sBEET调度器的设计
为了应对上述问题,论文提出了sBEET调度器。sBEET通过以下方式实现能效和实时性能的平衡:
- 利用空间多任务:在需要时启用空间多任务,以提高任务的并行执行能力。
- 预测能耗:在运行时预测每个调度决策可能带来的能耗,选择能效最优的调度策略。
实验验证
实验结果验证了sBEET的有效性:
- 减少截止时间错过:与其他方法相比,sBEET显著减少了任务错过截止时间的情况,表明其在实时性能方面的优势。
- 能效提升:尽管使用了空间多任务,sBEET的能耗与非空间多任务方法相似。对于能够满足截止时间的任务,sBEET实现了更高的能效,这表明其在能耗优化方面的效果。
















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











