






一言蔽之,上述三种算法就是使用神经网络的拟合能力将动作价值函数拟合出来。具体三种算法的不同在神经网络的更新和损失函数中有所体现。
DQN网络:首先明确DQN网络有同一种网络框架的两个网络,分别是
目标网络和训练网络。
动作价值函数的更新方程:
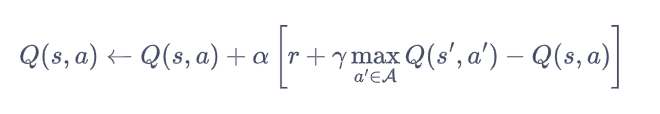
损失方程为:
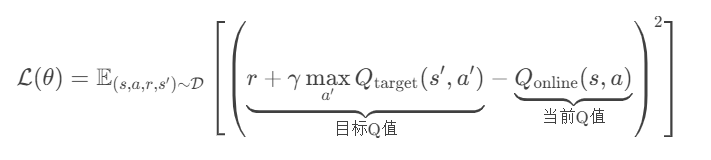
训练网络: 目标网络:
算法流程:

也就是说,目标网络更新较慢,而训练网络更新较快。这样的目的是为了加快训练和提高训练的稳定性。若只是用训练网络,由于 TD 误差目标本身就包含神经网络的输出,因此在更新训练网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。
通俗来说训练网络像一个正在跑步的运动员,不断调整自己的跑步策略(通过梯度下降更新参数),试图跑向终点(最小化损失函数);目标网络像是一个临时固定的终点标志,每隔一段时间才移动一次(硬更新)或缓慢拖动(软更新)。如果终点一直乱动(即直接用训练网络计算目标Q值),运动员会晕头转向(训练不稳定)。固定终点后,运动员有了明确方向,跑得更稳(收敛更稳定)。
Double DQN:
为解决Q值的高偏估计问题,引入D DQN网络。高偏估计是指在目标网络本身也有误差时,会导致在选择策略时由于噪声的存在而选择错误的噪声导致Q值大的动作(比如正确的Q值为0时噪声会导致影响很大),当我们用 DQN 的更新公式进行更新时,也就会被过高估计了。同理,我们拿这个Q来作为更新目标来更新上一步的Q值时,同样会过高估计,形成正反馈循环(高估越来越严重)。
为此,引入两个不同的网络来估计,这样即使其中一套神经网络的某个动作存在比较严重的过高估计问题,由于另一套神经网络的存在,这个动作最终使用的Q值不会存在很大的过高估计问题。
两种算法区别: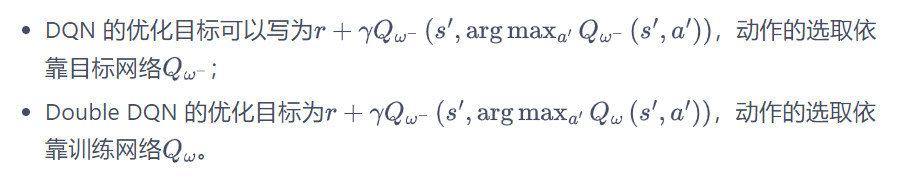
DQN中直接使用目标网络通过输入状态来选择最优动作,并直接输出最大Q值; Double DQN则是首先使用
来选择最优动作,然后将选择的最优动作和状态输入
来获取最大Q值。
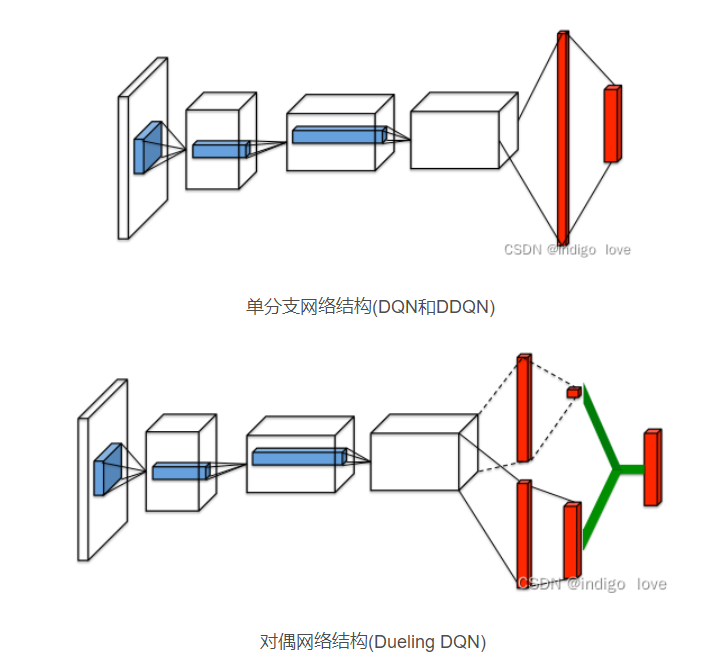
Dueling DQN :
重新定义损失函数,加入了优势函数A,简单改变了Q网络结构,将DQN单分支的网络改为Dueling DQN的双分支的网络结构。
详情推荐看 DQN 改进算法 (boyuai.com),博主写的非常详细。


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









