







热力图是一种可视化工具,用于显示数据集中各个项目之间的相对频繁程度或热度。它可以帮助用户更好地理解数据集中的主要趋势和模式。热力图通常以不同的颜色或强度表示不同的数据项,并且可以在不同的维度上进行比较。
在热力图中,每个数据点或者数据项都有一个对应的频率或者热度值。可以使用不同的颜色或强度来区分不同的数据项,并通过热力图的形式来显示数据集中各个项目之间的相对频繁程度或热度。热力图经常用于数据可视化和探索性数据分析中,以帮助人们更好地理解数据并发现其中的规律和趋势。
以鸢尾花数据集为例
先对数据集进行预处理,然后训练逻辑回归模型,最后打印一下预测值。
import pandas as pd
from sklearn.datasets import load_iris
dataset=load_iris()
features = pd.DataFrame(dataset.data,columns=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'])
targets = pd.DataFrame(dataset.target,columns=['target'])
#导入数据拆分方法
from sklearn.model_selection import train_test_split
feature_train,feature_test,target_train,target_test = \
train_test_split(features,targets,test_size=0.2,random_state=999)#拆分数据集,选20%数据作为测试用,随机系数999
#先打乱,在拆分,覆盖更多情况
from sklearn.linear_model import LogisticRegression
#导入逻辑回归模型
model = LogisticRegression()
#fit(x,y) x:特征 y:标签
model.fit(feature_train,target_train['target'])
target_predicted = model.predict(feature_test)
print(target_predicted) #预测结果
print(target_test['target']) #实际结果
绘制热力图
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
#计算准确率
accuracy = accuracy_score(target_test, target_predicted)
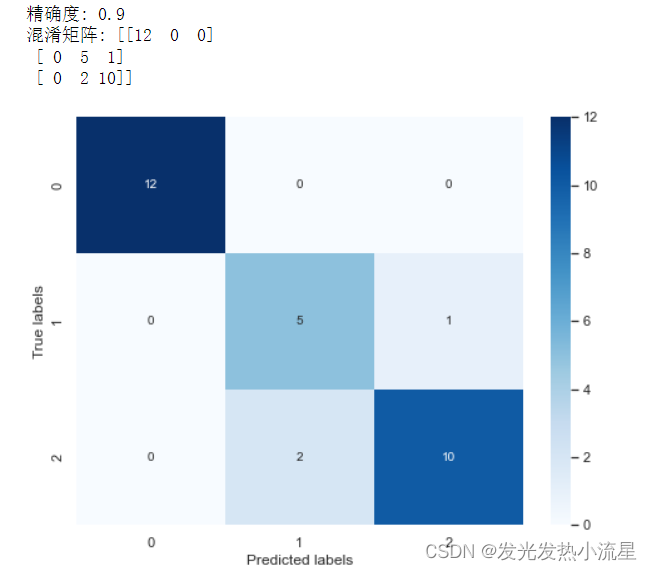
print("精确度:", accuracy)
#计算混淆矩阵
conMat = confusion_matrix(target_test, target_predicted)
print("混淆矩阵:", conMat)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(conMat, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()运行后结果如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











