







朴素贝叶斯算法是一种基于贝叶斯理论的有监督学习算法。之所以说“朴素”,是因为这个算法是基于样本特征之间互相独立的“朴素”假设。正因为如此,由于不用考虑样本特征之间的关系,朴素贝叶斯分类器的效率是非常高的。
1.贝叶斯定理:
2.朴素贝叶斯算法的不同方法:
朴素贝叶斯算法包含多种方法,在sklearn中,朴素贝叶斯有三种方法,分别是贝努力贝叶斯,高斯贝叶斯和多项式贝叶斯。
- 贝努力朴素贝叶斯:
贝努力朴素贝叶斯,这种方法比较适合于符合贝努力分布的数据集,贝努力分布也被称为"二项分布"或者是“0-1分布”。
下面我们来动手实践下:
#导入数据生成工作
from sklearn.datasets import make_blobs
#导入数据拆分工具
from sklearn.model_selection import train_test_split
#生成样本数量为500,分类数为5的数据集
X,y=make_blobs(n_samples=500,centers=5,random_state=8)
#将数据集拆分
X_train,X_test,y_train,y_teat=train_test_split(X,y,random_state=8)
#使用贝努力贝叶斯拟合数据
from sklearn.naive_bayes import BernoulliNB
nb=BernoulliNB()
nb.fit(X_train,y_train)
print('测试集得分:{}'.format(nb.score(X_test,y_teat)))
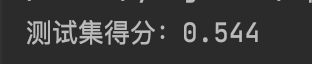
2.高斯朴素贝叶斯:
高斯朴素贝叶斯,顾名思义,是假设样本的特征符合高斯分布,或者说符合正态分布时所用的算法。
下面我们来动手实践下:
#导入数据生成工作
from sklearn.datasets import make_blobs
#导入数据拆分工具
from sklearn.model_selection import train_test_split
#生成样本数量为500,分类数为5的数据集
X,y=make_blobs(n_samples=500,centers=5,random_state=8)
#将数据集拆分
X_train,X_test,y_train,y_teat=train_test_split(X,y,random_state=8)
#使用贝努力贝叶斯拟合数据
from sklearn.naive_bayes import GaussianNB
nb=GaussianNB()
nb.fit(X_train,y_train)
print('测试集得分:{}'.format(nb.score(X_test,y_teat)))
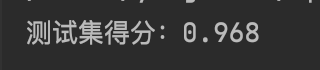
结果分析:
看起来,使用高斯朴素贝叶斯方法建立的模型得分要好的多,这说明我们生成的手工数据集的特征基本上符合正态分布。
事实上,高斯朴素贝叶斯也确实是能够胜任大部分的分类任务,这是因为在自然科学和社会科学领域,有大量的现象都是呈现出正态分布的状态。
- 多项式朴素贝叶斯:
多项式朴素贝叶斯,从名字也可以推断出它主要是用于拟合多项式分布的数据集。
下面我们来动手实战下:
#导入数据生成工作
from sklearn.datasets import make_blobs
#导入数据拆分工具
from sklearn.model_selection import train_test_split
#生成样本数量为500,分类数为5的数据集
X,y=make_blobs(n_samples=500,centers=5,random_state=8)
#将数据集拆分
X_train,X_test,y_train,y_teat=train_test_split(X,y,random_state=8)
#使用贝努力贝叶斯拟合数据
from sklearn.naive_bayes import MultinomialNB
nb=MultinomialNB()
nb.fit(X_train,y_train)
print('测试集得分:{}'.format(nb.score(X_test,y_teat)))
事实上,上述代码是错误的,因为多项式朴素贝叶斯要求输入的X值必须非负,所以我们需要对数据进行预处理下。
#导入数据生成工作
from sklearn.datasets import make_blobs
#导入数据拆分工具
from sklearn.model_selection import train_test_split
#生成样本数量为500,分类数为5的数据集
X,y=make_blobs(n_samples=500,centers=5,random_state=8)
#将数据集拆分
X_train,X_test,y_train,y_teat=train_test_split(X,y,random_state=8)
from sklearn.preprocessing import MinMaxScaler
sca=MinMaxScaler().fit(X_train)
X_train_sca=sca.transform(X_train)
X_test_sca=sca.transform(X_test)
#使用贝努力贝叶斯拟合数据
from sklearn.naive_bayes import MultinomialNB
nb=MultinomialNB()
nb.fit(X_train_sca,y_train)
print('测试集得分:{}'.format(nb.score(X_test_sca,y_teat)))
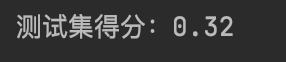
结果分析:
多项式朴素贝叶斯只适合用来对非负离散数值特征进行分类,典型的例子就是对转化为向量后的文本数据进行分类。















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









