








if (0 >= preg_match('/^[[:graph:]]{12,}$/', $password))
{
echo 'Wrong Format';
exit;
}
正则匹配
[:graph:]:是除空格符(空格键与[TAB]键)之外的所有按
^ :匹配你要用来查找的字符串的开头
$:匹配结尾
{12,} :匹配重复12次或多次–>长度大于12
所以可见字符超过12个
$reg = '/([[:punct:]]+|[[:digit:]]+|[[:upper:]]+|[[:lower:]]+)/';
if (6 > preg_match_all($reg, $password, $arr))
break;
字符串中,把连续的符合,数字,大写,小写作为一段,
至少分六段,例如a12SD+io8可以分成a 12 SD + io 8六段
$ps = array('punct', 'digit', 'upper', 'lower');
foreach ($ps as $pt)
{
if (preg_match("/[[:$pt:]]+/", $password))
$c += 1;
}
p s = 数组 / / [ [ : p u n c t : ] ] 任何标点符号 [ [ : d i g i t : ] ] 任何数字 [ [ : u p p e r : ] ] 任何大写字母 [ [ : l o w e r : ] ] 任何小写字母 < b r / > 进行匹配,如果 p a s s w o r d 匹配到了就进行 + 1 操作赋给 ps = 数组//[[:punct:]] 任何标点符号 [[:digit:]] 任何数字 [[:upper:]] 任何大写字母 [[:lower:]] 任何小写字母<br />进行匹配 ,如果password 匹配到了 就进行 +1 操作 赋给 ps=数组//[[:punct:]]任何标点符号[[:digit:]]任何数字[[:upper:]]任何大写字母[[:lower:]]任何小写字母<br/>进行匹配,如果password匹配到了就进行+1操作赋给c
if ($c < 3) break;
if ("42" == $password) echo $flag;
在匹配次数里面
c
要大于
3
<
b
r
/
>
大写,小写,数字,符号这四种类型至少要出现三种
<
b
r
/
>
但是最后
c 要大于3 <br />大写,小写,数字,符号这四种类型至少要出现三种<br />但是最后
c要大于3<br/>大写,小写,数字,符号这四种类型至少要出现三种<br/>但是最后password 还要等于 42 就有点困难了
42 转换
转换成16进制 
已经符合了正则3 这里的a 可以写成大写 x是小写
让它符合正则1也很容易,在前面补0就可以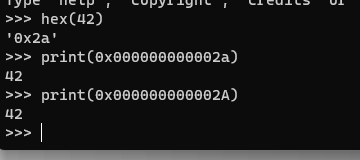
但是还没有满足正则二的条件 差符合
可以使用科学计数法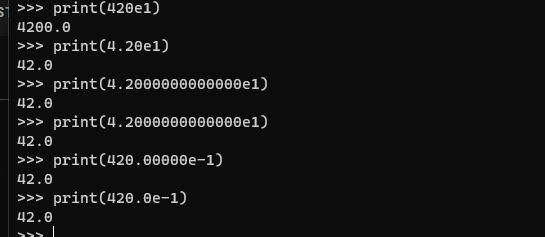
但是感觉输入进去只有
420.000000000000e-1
这样才成功 ,因为.点会破坏判断相等时进行的转换
所以有- 才满足正则二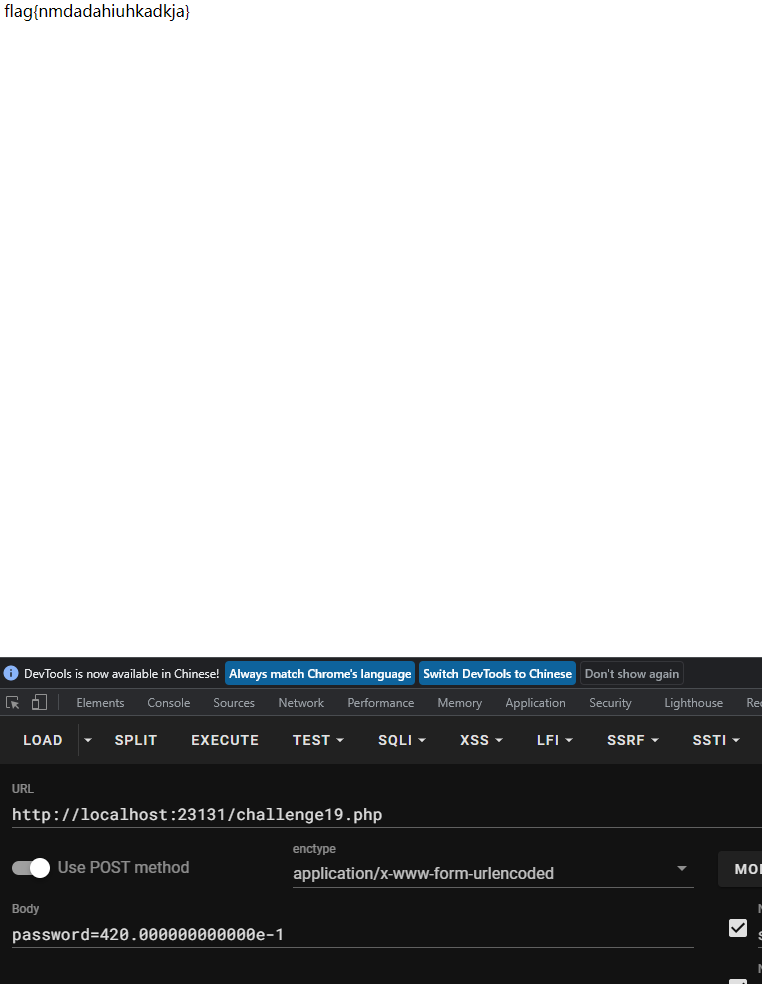















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









