LRU缓存算法的含义、应用背景、理解以及Java代码实现
- LRU:全称least recently used,中文名为最近最少使用,它是最常用的缓存淘汰策略。
- LRU算法的应用背景:
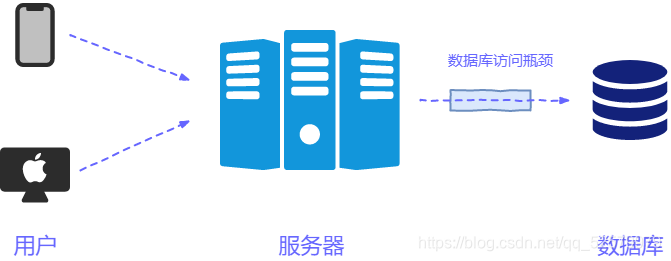
- 让我们先思考一下互联网应用的整体流程,没错,大致流程就是下面这张图。
- 正如图中所示,当大量用户访问服务器时,服务器会频繁请求数据库调取数据,此时数据库的访问就很有可能出现瓶颈,那么我们可以在服务器本地缓存用户信息,缓解频繁访问数据库的压力,但是缓存数据总得有一个上限,我们采用什么算法解决达到上限之后的数据淘汰问题呢?今天要谈的LRU缓存算法正是为了解决此问题。
- LRU算法的理解:我们假设,每个缓存都具有优先级,每次使用缓存都应该将缓存的优先级提高,很久没有使用的缓存优先级最低,最应该被淘汰。回到实际的应用程序中,我想大家应该觉得这是理所当然的,很久没有使用的用户信息确实应该从缓存中淘汰掉,应该去保留那些频繁使用的用户信息,这有利于产生更高的利益。
- Java代码实现
package yuzhuoran.算法练习;
import java.util.HashMap;
import java.util.Map;
public class LRUCache<T, V> {
int size = 0;
int capacity = 0;
Map<T, Node<T, V>> cache;
Node<T, V> first;
Node<T, V> last;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
}
public V get(T key) {
if(cache.containsKey(key)) {
Node<T, V> node = cache.get(key);
this.getHigh(node);
return node.content;
}
return null;
}
public void getHigh(Node<T, V> node) {
Node<T, V> firstNode = this.first;
if(node.getPrev() == null) {
return;
}
else if(node.getNext() == null) {
node.getPrev().setNext(null);
this.last = node.getPrev();
}
else {
node.getPrev().setNext(node.getNext());
node.getNext().setPrev(node.getPrev());
}
this.first = node;
this.first.setNext(firstNode);
this.first.setPrev(null);
firstNode.setPrev(this.first);
}
public void put(T key, V value) {
Node<T, V> node = this.cache.get(key);
if(node != null) {
node.content = value;
this.getHigh(node);
return;
} else {
node = new Node<>(key,value);
}
Node<T, V> firstNode = this.first;
Node<T, V> lastNode= this.last;
if(firstNode == null) {
this.first = node;
this.last = node;
cache.put(key,this.first);
} else if(this.size == this.capacity) {
this.last = this.last.getPrev();
try {
this.last.setNext(null);
this.first = node;
this.first.setNext(firstNode);
firstNode.setPrev(this.first);
cache.remove(lastNode.key);
cache.put(key,this.first);
return;
} catch (NullPointerException e) {
this.first = node;
this.last = node;
cache.remove(lastNode.key);
cache.put(key,this.first);
return;
}
} else {
this.first = node;
this.first.setNext(firstNode);
firstNode.setPrev(this.first);
cache.put(key,this.first);
}
this.size++;
}
public String toString() {
StringBuilder sb = new StringBuilder();
Node<T, V> node = this.first;
while (node != null) {
sb.append(node.key + ":" + node.content + " , ");
node = node.getNext();
}
return sb.toString();
}
class Node<T, V> {
Node<T, V> next;
Node<T, V> prev;
T key;
V content;
public Node() {
}
public Node(T key, V content) {
this.key = key;
this.content = content;
}
public Node<T, V> getNext() {
return next;
}
public void setNext(Node<T, V> next) {
this.next = next;
}
public Node<T, V> getPrev() {
return prev;
}
public void setPrev(Node<T, V> prev) {
this.prev = prev;
}
}
public static void main(String[] args) {
LRUCache<Integer,String> cache = new LRUCache<>(3);
cache.put(1,"1");
cache.put(2,"2");
cache.put(3,"3");
cache.get(1);
System.out.println(cache.toString());
}
}























 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









