






1.变量
2.注释
3.print
4.数据结构
(1)字符串是以两个单引号或两个双引号包裹起来的文本
(2)转义字符:字符串里常常存在一些如换行、制表符等有特殊含义的字符,这些字符称之为转义字符。比如 \n 表示换行, \t 表示制表符,Python还允许用 r“ ” 表示“ ” 内部的字符串默认不转义
(3)not 运算为非运算,即把 True 变成 False , False 变成 True
(4)使用 type() 函数来获取某值的类型、
5.算术运算符
| 运算 | 说明 |
| a+b | a加b |
| a-b | a减b |
| a*b | a乘以b |
| a/b | a除以b |
| a//b | a除以b后向下圆整,丢弃小数部分 |
| a**b | a的b次方 |
6.类型转换
7.列表
(1)列表(list)是一个有序的序列结构,序列中的元素可以是不同的数据类型
(2)列表可以进行一系列序列操作,如索引、切片、加、乘和检查成员等
(3)将列表中的各元素用逗号分隔开,并用中括号将所有元素包裹起来 例a=[1,ab,'haha']
(4)使用append()方法添加元素,该方法会在列表末尾位置添加数据元素,使用remove()方法删除元素
a.append(x) #x为要添加的元素
a.remove(x) #x为要删除的元素(5)Python语言中所有的索引都是从 0 开始计数的,如果列表中有 n 个元素,那么最后一个元素的索引是 n-1
(6)使用 del 函数配合列表索引,删除索引位置的元素 del a[2]
(7)通过 insert() 方法在指定的索引位置添加数据元素 a.insert(1,'haha')
(8)Python内置的用于判断列表长度的函数为 len()
(9)切片操作 列表名称[起始索引位置:最后索引位置:步长]如果未输入步长,则默认步长为 1注意的是,起始索引位置的值包含在返回结果中,而最后索引位置的值不包含在返回结果中。
8.元组
(1)元组(tuple)数据结构与列表类似 a=(1,ab,'haha')
(2)元组中的元素是不可变的,即一旦初始化之后,就不能够再做修改(报错:元 组对象不支持赋值)
(3)由于元组是不可变的,因此元组对象没有append()、insert()和del这样的方法,实际上,tuple的使用可以使得代码更安全,防止错误赋值导致重要对象的改变。
9.字典
(1)字典是一种大小可变的键值对集,其中的键(key)和值(value)都是Python对象
(2)字典的创建使用大括号 {} 包含键值对,并用冒号 : 分隔键和值,形成 键:值对a={1:'a',2:'b'}
(3)字典中的数据元素是无序的,并不会按照初始化的顺序排列。不同键所对应的值可以相同,但是字典中的键必须是唯一的
a=[1,2,3]
b=['a','b','c']
test={}
for key,value in zip(a,b):
test[key]=value
print(test)(5)字典的元素访问(以及插入、设置)方式与列表和元组一样。不同的是,列表和元组的索引号是按照顺序自动生成,而字典的索引号是键
(6)字典的删减有三种方法
10.集合
(1)集合(set)是一种无序集,它是一组键的集合,不存储值
(2)在集合中,重复的键是不被允许的。集合可以用于去除重复值
(3)集合也可以进行数学集合运算,如并、交、差以及对称差等 ,集合的创建有两种方式:使用 set() 函数或者使用大括号{} , 需要注意的是,创建空集合,必须使用 set() ,而不是{},因为{}表示创建一个空的字典 a=set([1,2,1,3])打印时会去除23之间的1
11.选择结构
(1)if a>b:
执行语句
(2)if a>b:
执行语句
else:
执行语句
(3)if a>b:
执行语句
elif a=b:
执行语句
elif ...:
.
else:
执行语句12循环结构
(1)for 元素变量 in 序列:
执行语句
(2)while a>b:
执行语句13文件的写入
(1)对文件操作之前需要用 open() 函数打开文件
(2)对文件数据的读取是用的 read() 方法, read() 方法将返回文件中的所有内容
(3)记得每次用完文件后,都要关闭文件 f.close()。否则,文件就会一直被Python占用,不能被其他进程使用
(4)写入的操作和读取是类似的,不过用的是 write() 函数,同时需要将打开文件的 mode 参数设置为 w
f=open('路径','r')
context=f.read()
print(context)
f.close()
f=open('路径','r')
f.write('hahaha')
f.close()14.函数
def hanshu(x): #关键字 函数命名(输入参数):
函数主体
return s #返回变量def fun(x,y,*args):
s=1+x+y
for i in args;
s=s+i
return s
print(fun(1,2,3,4,5,6))15.lambda函数
fun=lambda x,y,z:1+x+y+z
print(fun(1,2,3)) #716.局部变量与全局变量
(1)局部变量是指那些有固定的变量作用域,只有在此作用域内才能调用此变量。具体而言,比如函数内的局部变量的作用域仅限于函数内.
(2)全局变量是相对局部变量而言的作用范围在全局,即在初始定义赋值后,无论是函数、类、lambda函数内都可以引用全局变量。在关键词 def 、class、lambda 之外定义的变量,都作为全局变量。
(3)在定义变量时使用关键词“global”即可将函数内的局部变量定义为全局变量
(4)当某局部变量和全局变量都有相同变量名时,函数内引用该变量会直接调用函数内定义的局部变量。
17.Numpy
import numpy as np
n=np.array([[1,2,3],[4,5,6]])
print(type(n))
print(n)(2)将数据转为ndarray对象后,会需要按某种方式来抽取数据ndarray对象提供了两种索引方式:
import numpy as np
n=np.array([[1,2,3],[4,5,6]])
c=n[n>2]
print(c)(3)数据转为ndarray对象
import numpy as np
a=[1,2,3]
print(type(a))
print(a)
np_ar=np.array(a)
print(type( np_ar))
print(np_ar)(4)切分、重构、转置
import numpy as np
a=[[1,2,3],[4,5,6]]
print(type(a))
print(a)
np_ar=np.array(a)
print(type(np_ar) )
print(np_ar)
print('######')
print(np_ar[0:2,1:3]) #切片
np_ar2=np_ar.reshape(1,6) #重构
print(np_ar2)
print(np_ar.T) #转置(5)内置操作函数
18.matplotlib
Thumbnail gallery — Matplotlib 2.0.2 documentation![]() https://matplotlib.org/2.0.2/gallery.html
https://matplotlib.org/2.0.2/gallery.html
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(8,4))
x = np.linspace(0, 10,1000)
y = np.sin(x)
z = np.cos(x**2)
plt.plot(x,y,label="sin(x)" ,color="r",linewidth=2)
plt.plot(x,z,"b--" , label="cos (x^2)")
plt.xlabel("Time( s )")
plt.ylabel("volt")
plt.title("PyPlot First Example")
plt.ylim(-1.2,1.2)
plt.legend()
plt.show()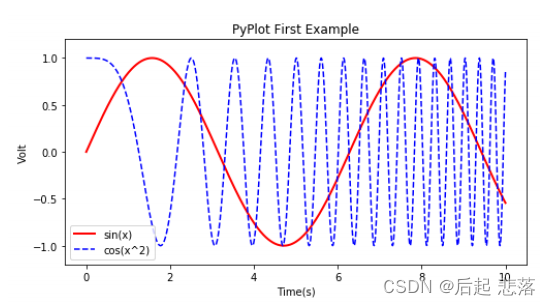
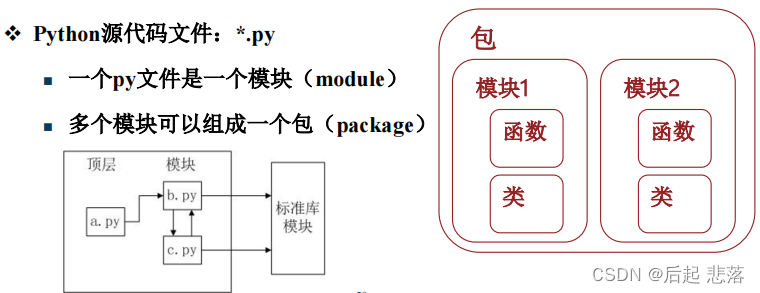
19.python模块















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









