







一、语音信号:
语音信号是从传感器中按一定时间间隔对物理声音进行采样,得到的一维时间信号。
其物理基本描述单位为振幅和时间。
二、频谱图
把一维的语音信号,经过分帧、加窗等处理,再经短时傅里叶变换**(STFT),得到其每帧的一系列相位值和一系列幅度值**。如果是得到幅度值,称为幅度谱(也称频谱图)。如果是得到相位图,称为相位谱。下图为幅度谱。
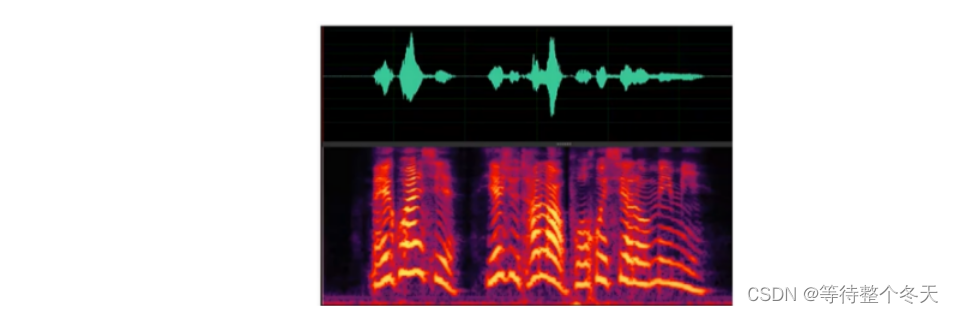
横轴是时间帧(时间),纵轴是频率, 颜色深浅代表幅度的强弱。则整张图可表示语音信号的各个频率分量随着时间变化,其幅度的强弱的变化。
三、基频,共振峰.
从幅度谱上可以看到横的明显条状带,这说明不同强度的频率分量有很大不同。这些强度较高的条带从下(低)到上(高)被称为基频、第一共振峰、第二共振峰…。
基频说明了声带发出的声音的(基音)振动的频率变化,而共振峰说明了声带发出的基音与声道谐振的声音的频率的变化。这些基频和共振峰变化模式可以代表语音的不同音素。
四、声码器
将频谱图转换为波形的系统称之为声码器。
五、频谱提取的基本过程
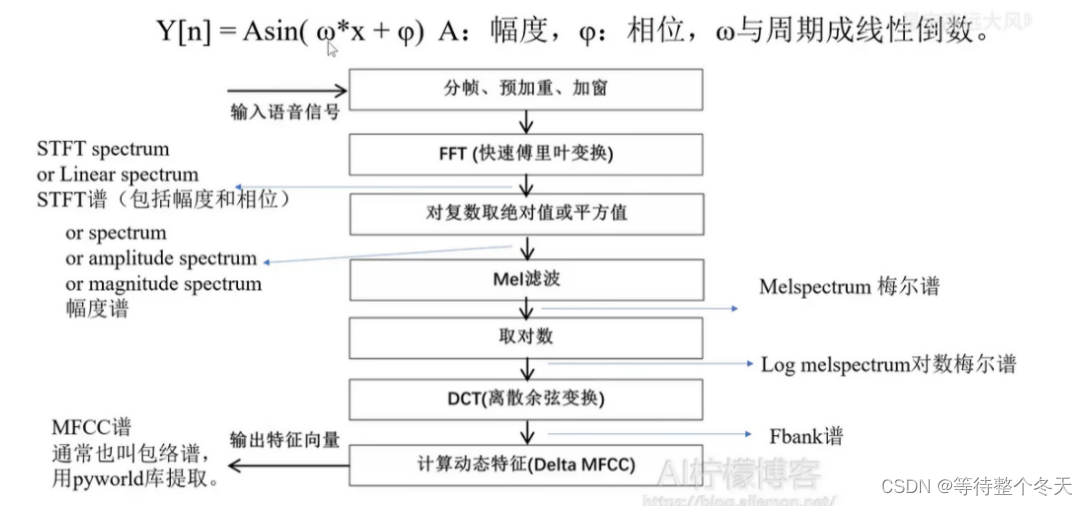
对复数取绝对值或平方值后相位特征被抹除,剩下幅度,STFT基本指代幅度谱
时域信号:一维的信号,Y代表幅度,X代表采样点
信号长度(signal) = 采样时间(time) x 采样率(Sample rate)
如一条语音
时间表示法
长度为2秒,采样率为16000HZ,则在计算机中表示为(2* 16000)的一维向量。
采样点表示法
也可说语音的长度是32000,但此时必须确定采样率,才能确定其实际时长。
因此在语音的表示数据量不变的情况下,采样率增大,则时间减小。
-
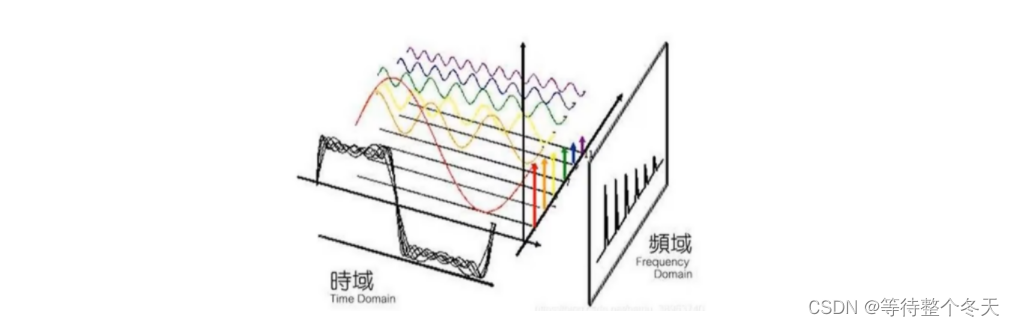
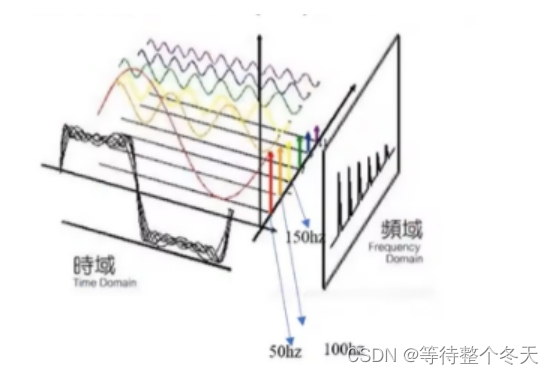
傅里叶变换
获取信号各个成分的频率分量
Fourier的基本思想:
以适当的某种频率间隔,将语音分解为一组基础信号,再用傅里叶算法,计
算出每组信号的幅度和相位。即一段信号,能得到一组不同的基础信号的幅度和相位!
[1,L1] --> fourier-- >幅度[256] ,相位[256]
-
分帧
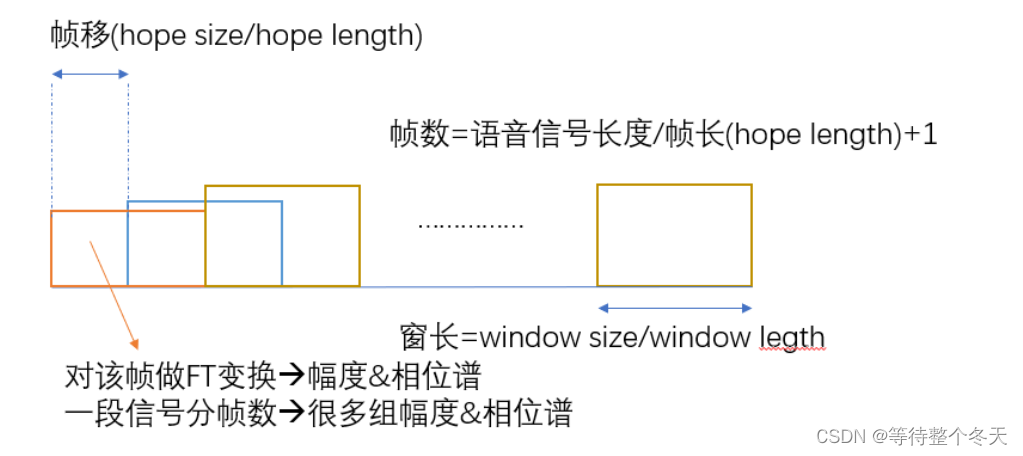
-
很多组幅度&相位
组数由n_fft(傅里叶变换点数)决定
频率组数=n_ fft//2 +1假设n_ fft= 256,则设定了“129” 组不同频率的参数。
频率组的频率是多少?则根据该窗的长度确定频率组间隔,从0开始线性增加信号分量的频率。频率依次为1 x(1/T)、 2 x(1/T)…129 x (1/T)
例如:窗长=320,SR = 16000(采样率)
该窗时间长度:T= 320/ 16000 = 0.02秒
则频率组间隔= 1/T= 1/0.02= 50
则,若设n_ fft= 256,
频率组的频率即为:50hz ,100hz,150hz, … (129* 50)hz
接下来,用Fourier算法,根据这些频率求出其幅度和相位
-
- FT变换

输出(1,176,101)
n_fft/2+1:每帧可以提取到176组不同的幅度相位,win_length/采样率:每两个频率间隔
101=16000//160+1 hop_lenth:帧移
- mel谱
在幅度谱的基础上,乘以“梅尔变换”,得到80维度的梅尔谱。这种谱的80个频率组更接近人耳的听觉感知范围。但是相应地,蕴含的语音信息比幅度谱要少一些。
注意,深度学习中的梅尔谱大多数情况下指对数梅尔谱! ! !
幅度谱: 10 hz 20 hz 30hz …
梅尔谱: 10 151718… (对数增长组)
mag(幅度谱):(1+n_fft//2,T)
参考资料
【1】维涅斯的大火花. [天子学习]深度学习中的语音信号处理基础&代码实现[EB/OL]. [2023.10.30]. https://www.bilibili.com/video/BV1f3411C7kb/?spm_id_from=333.337.search-card.all.click&vd_source=a7949f48ad3098f6c26f5b0dfda80b0d.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











