







Linux线程中写过生产者消费者模型,这次研究读者写者模型。
读者写者模型遵循的规则
读者-写者模型同样遵循321规则:
- 写-写互斥,即不能有两个写者同时进行写操作。
- 读-写互斥,即不能同时有一个线程在读,而另一个线程在写。
- 读-读允许,读者和读者之间没有关系,即可以有一个或多个读者同时读。
读者优先
如果一个读者申请进行读操作时已有另一个读者正在进行读操作,则该读者可直接开始读操作。而此时写者正在被阻塞,只有所有的读者都读完,写者才会被唤醒。
//读者优先
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#include <iostream>
using namespace std;
struct data
{
string str;
};
//临界区数据,读者写者分别读和写入shareData
data shareData;
//读优先保证当已经有读者在读时,后续的读者可以直接开始读操作
//当然,写者必须等没有读者读时才能写
sem_t mutex_readCount, mutex_write;
//读者的数量
int readCount;
//读者
void* Reader(void* param)
{
printf("线程 %ud: 正在等待读\n",pthread_self());
int readWait = rand()%5;
sleep(readWait);
//读者数量++
sem_wait(&mutex_readCount);
readCount++;
if(readCount == 1)
{
//当读者数量>0时,写者不能写
sem_wait(&mutex_write);
}
sem_post(&mutex_readCount);
//读者进行读操作
printf("线程 %ud: 开始进行读\n", pthread_self());
cout<<"读者读出数据:"<<shareData.str<<endl;;
printf("线程 %ud: 读取完毕\n", pthread_self());
//读完以后,读者数量--
sem_wait(&mutex_readCount);
readCount--;
if(readCount == 0)
{
//读者数量为0,写者可以写了
sem_post(&mutex_write);
}
sem_post(&mutex_readCount);
pthread_exit(0);
}
//写者
void* Writer(void* param)
{
printf("线程 %ud: 正在等待写\n",pthread_self());
int writeWait = rand()%5;
sleep(writeWait);
string& writeStr= ((data*)param)->str;
//多个线程写时,使用mutex_write进行互斥
sem_wait(&mutex_write);
printf("线程 %ud: 开始写入:%s\n",pthread_self(),writeStr.c_str());
shareData.str=writeStr;
printf("线程 %ud: 写完\n",pthread_self());
sem_post(&mutex_write);
pthread_exit(0);
}
int main()
{
srand((unsigned)time(NULL));
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_t tid4;
pthread_t tid5;
readCount=0;
shareData.str="默认值";
sem_init(&mutex_readCount, 0, 1);
sem_init(&mutex_write, 0, 1);
readCount = 0;
//创建几个线程,分别为写者和读者,进行测试
pthread_create(&tid2, NULL, Reader, NULL);
data w1;
w1.str="abc";
pthread_create(&tid1, NULL, Writer, (void*)&w1);
pthread_create(&tid4, NULL, Reader, NULL);
pthread_create(&tid5, NULL, Reader, NULL);
data w2;
w2.str="1234";
pthread_create(&tid3, NULL, Writer, (void*)&w2);
sem_destroy(&mutex_readCount);
sem_destroy(&mutex_write);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
pthread_join(tid3,NULL);
pthread_join(tid4,NULL);
pthread_join(tid5,NULL);
return 0;
}
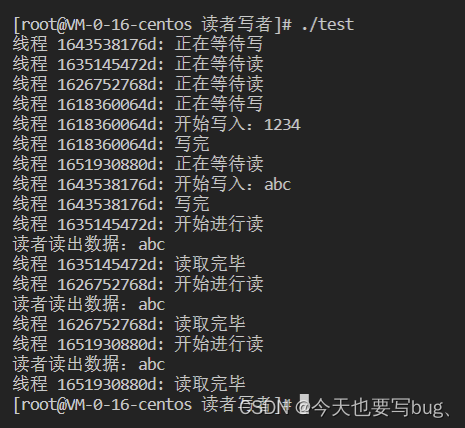
写者优先
如果一个读者申请进行读操作时已有另一写者在等待访问共享资源,则该读者必须等到没有写者处于等待状态后才能开始读操作。
换句话说,如果一个读者A申请进行读操作,并且写者想进行写操作,此时A会与写者竞争锁,如果写者竞争成功则写者先写,后续来的写者由于多线程原因会处于等待状态(等前一个写者写完),只有当等待状态的写者数量为0时,读者A才可以进行读。
如果读者A竞争成功则A先读,后续的读者B仍然要与写者竞争。
//写者优先
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#include <iostream>
using namespace std;
struct data
{
string str;
};
//临界区数据,读者写者分别读和写入shareData
data shareData;
//写优先必须保证必须等写者都写完,读者才能读,所以用rwMutex来控制其关系
//用mutex_write信号量来控制写者和写者之间互斥关系,当有读者读时,写者不能写
//由于读者和读者之间没有关系,所以不需要锁
//mutex_writeCount和mutex_readCount分别对读者和写者数量进行原子操作
sem_t rwMutex, mutex_writeCount, mutex_readCount, mutex_write;
//写者的数量和读者的数量
int writeCount, readCount;
//mutex主要用处是避免写者同时与多个读者进行竞争,读者中信号量RWMutex比mutex先释放,则一旦有写者,写者可马上获得资源RWMutex
sem_t mutex;
//读者
void* Reader(void* param)
{
printf("线程 %ud: 正在等待读\n",pthread_self());
int readWait = rand()%5;
sleep(readWait);
//读者获取rwMutex信号量,
//读优先必须保证必须等写者都写完,读者才能读,所以写者先获取rwMutex,当全部写完后才释放
//如果写者没释放读者就来读,读者会被挂起
sem_wait(&mutex);
sem_wait(&rwMutex);
//读者数量++
sem_wait(&mutex_readCount);
readCount++;
if(readCount == 1)
{
//当读者数量>0时,写者不能写
sem_wait(&mutex_write);
}
sem_post(&mutex_readCount);
//到这里,读者申请读成功,立刻释放rwMutex,这样后续的读者和写者就能竞争rwMutex了
//并且由于mutex,写者可以避免和多个读者竞争rwMutex
sem_post(&rwMutex);
sem_post(&mutex);
printf("线程 %ud: 开始进行读\n", pthread_self());
//读者进行读操作
cout<<"读者读出数据:"<<shareData.str<<endl;;
printf("线程 %ud: 读取完毕\n", pthread_self());
//读完以后,读者数量--
sem_wait(&mutex_readCount);
readCount--;
if(readCount == 0)
{
sem_post(&mutex_write);
}
sem_post(&mutex_readCount);
pthread_exit(0);
}
//写者
void* Writer(void* param)
{
printf("线程 %ud: 正在等待写\n",pthread_self());
int writeWait = rand()%5;
sleep(writeWait);
string& writeStr= ((data*)param)->str;
sem_wait(&mutex_writeCount);
writeCount++;
writeWait++;
if(writeCount == 1)
{
//已经有一个写者,获取rwMutex,当写者数量为0时释放它,读者才能读
sem_wait(&rwMutex);
}
sem_post(&mutex_writeCount);
//多个线程写时,使用mutex_write进行互斥
sem_wait(&mutex_write);
printf("线程 %ud: 开始写入:%s\n",pthread_self(),writeStr.c_str());
shareData.str=writeStr;
printf("线程 %ud: 写完\n",pthread_self());
sem_post(&mutex_write);
sem_wait(&mutex_writeCount);
writeCount--;
if(writeCount == 0)
{
sem_post(&rwMutex);
}
sem_post(&mutex_writeCount);
pthread_exit(0);
}
int main()
{
srand((unsigned)time(NULL));
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_t tid4;
pthread_t tid5;
writeCount=readCount=0;
shareData.str="默认值";
sem_init(&rwMutex, 0, 1);
sem_init(&mutex_writeCount, 0, 1);
sem_init(&mutex_readCount, 0, 1);
sem_init(&mutex_write, 0, 1);
sem_init(&mutex, 0, 1);
//创建几个线程,分别为写者和读者,进行测试
pthread_create(&tid2, NULL, Reader, NULL);
data w1;
w1.str="abc";
pthread_create(&tid1, NULL, Writer, (void*)&w1);
pthread_create(&tid4, NULL, Reader, NULL);
pthread_create(&tid5, NULL, Reader, NULL);
data w2;
w2.str="1234";
pthread_create(&tid3, NULL, Writer, (void*)&w2);
sem_destroy(&rwMutex);
sem_destroy(&mutex_writeCount);
sem_destroy(&mutex_readCount);
sem_destroy(&mutex_write);
sem_destroy(&mutex);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
pthread_join(tid3,NULL);
pthread_join(tid4,NULL);
pthread_join(tid5,NULL);
return 0;
}
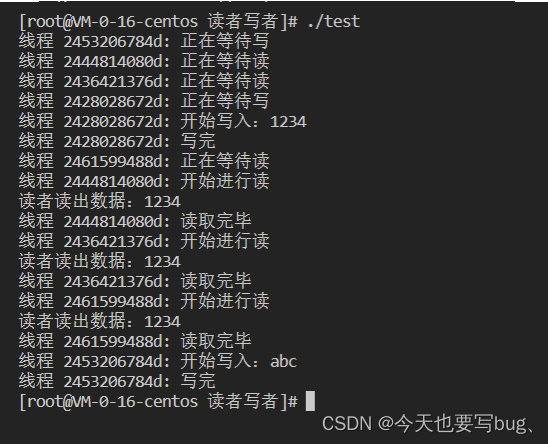
读者和写者公平竞争
上面两种方式都会导致读者或者写者饥饿,即读者一直读或者写者一直写的情况。下面解决这个问题,采取的策略是:
- 读者和写者优先级相同;
- 写者、读者互斥访问;
- 只能⼀个写者访问临界区;
- 可以有多个读者同时访问临街资源
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#include <iostream>
using namespace std;
struct data
{
string str;
};
//临界区数据,读者写者分别读和写入shareData
data shareData;
//读优先保证当已经有读者在读时,后续的读者可以直接开始读操作
//当然,写者必须等没有读者读时才能写
sem_t mutex_readCount, mutex_write;
//flag实现公平竞争
sem_t flag;
//读者的数量
int readCount;
//读者
void* Reader(void* param)
{
printf("线程 %ud: 正在等待读\n",pthread_self());
int readWait = rand()%5;
sleep(readWait);
//在读之前,先和写者竞争flag
sem_wait(&flag);
//读者数量++
sem_wait(&mutex_readCount);
readCount++;
if(readCount == 1)
{
//当读者数量>0时,写者不能写
sem_wait(&mutex_write);
}
sem_post(&mutex_readCount);
sem_post(&flag);
//读者进行读操作
printf("线程 %ud: 开始进行读\n", pthread_self());
cout<<"读者读出数据:"<<shareData.str<<endl;;
printf("线程 %ud: 读取完毕\n", pthread_self());
//读完以后,读者数量--
sem_wait(&mutex_readCount);
readCount--;
if(readCount == 0)
{
//读者数量为0,写者可以写了
sem_post(&mutex_write);
}
sem_post(&mutex_readCount);
pthread_exit(0);
}
//写者
void* Writer(void* param)
{
printf("线程 %ud: 正在等待写\n",pthread_self());
int writeWait = rand()%5;
sleep(writeWait);
string& writeStr= ((data*)param)->str;
//在写之前,先和读者竞争flag
sem_wait(&flag);
//多个线程写时,使用mutex_write进行互斥
sem_wait(&mutex_write);
printf("线程 %ud: 开始写入:%s\n",pthread_self(),writeStr.c_str());
shareData.str=writeStr;
printf("线程 %ud: 写完\n",pthread_self());
sem_post(&mutex_write);
sem_post(&flag);
pthread_exit(0);
}
int main()
{
srand((unsigned)time(NULL));
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_t tid4;
pthread_t tid5;
readCount=0;
shareData.str="默认值";
sem_init(&mutex_readCount, 0, 1);
sem_init(&mutex_write, 0, 1);
sem_init(&flag, 0, 1);
readCount = 0;
//创建几个线程,分别为写者和读者,进行测试
pthread_create(&tid2, NULL, Reader, NULL);
data w1;
w1.str="abc";
pthread_create(&tid1, NULL, Writer, (void*)&w1);
pthread_create(&tid4, NULL, Reader, NULL);
pthread_create(&tid5, NULL, Reader, NULL);
data w2;
w2.str="1234";
pthread_create(&tid3, NULL, Writer, (void*)&w2);
sem_destroy(&mutex_readCount);
sem_destroy(&mutex_write);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
pthread_join(tid3,NULL);
pthread_join(tid4,NULL);
pthread_join(tid5,NULL);
return 0;
}
对⽐读者优先策略,可以发现,读者优先中只要后续有读者到达,读者就可以进⼊读者队列, ⽽写者必须等待,直到没有读者到达。
没有读者到达会导致读者队列为空,即 readCount ==0,此时写者才可以进⼊临界区执⾏写操作。⽽这⾥ flag 的作⽤就是阻⽌读者的这种特殊权限(特殊权限是只要读者到达,就可以进⼊读者队列)。


















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











