







- 进入淘宝网站,登录账户,搜索化妆品,去掉url里的无关参数,然后找到url如下
https://s.taobao.com/search?q=%E5%8C%96%E5%A6%86%E5%93%81
- 右击检查,点击Network,Response刷新,得到以下界面
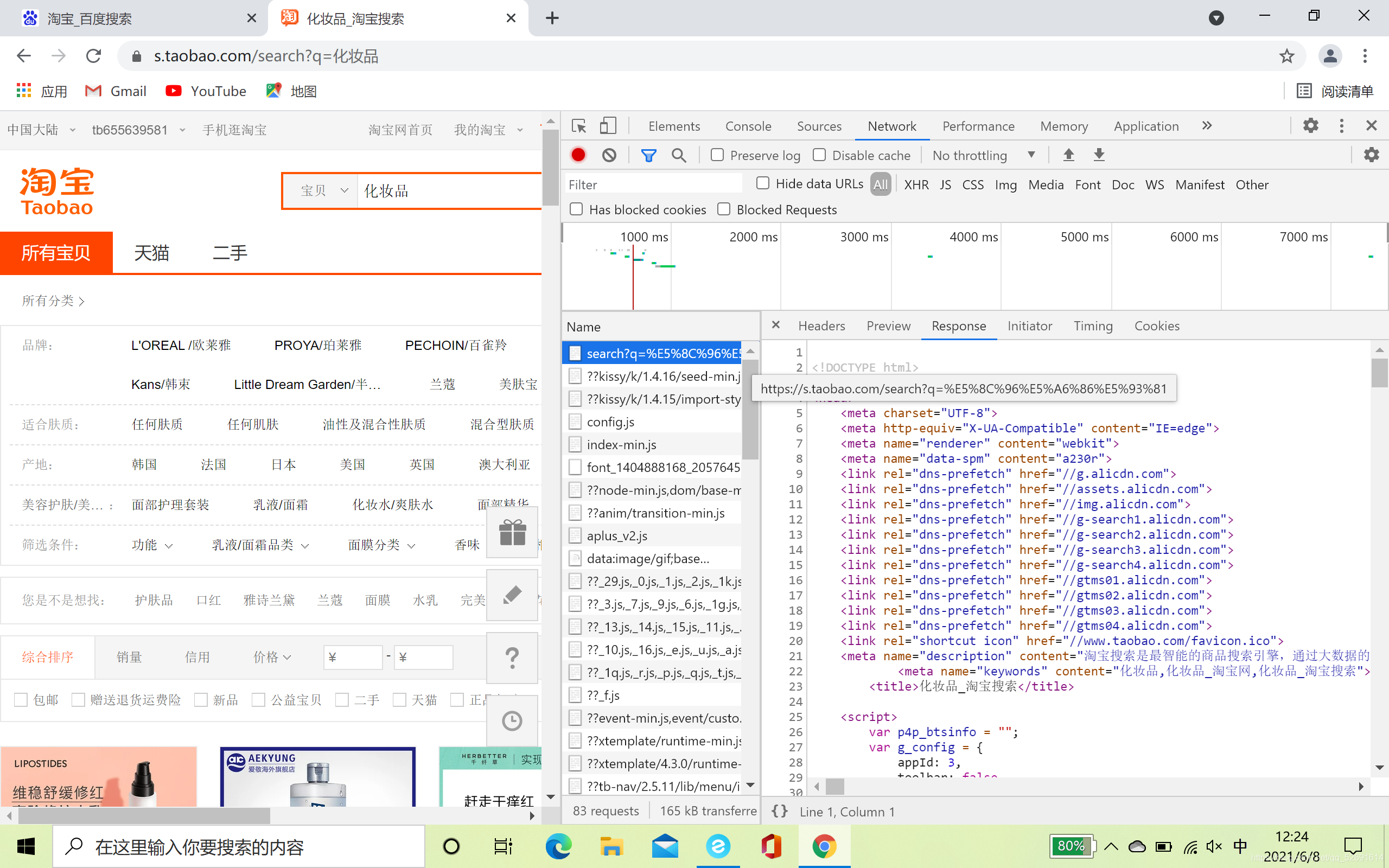
- 按Ctrl+F搜索某一个商品的信息,比如第一个,搜索198.00,如下图
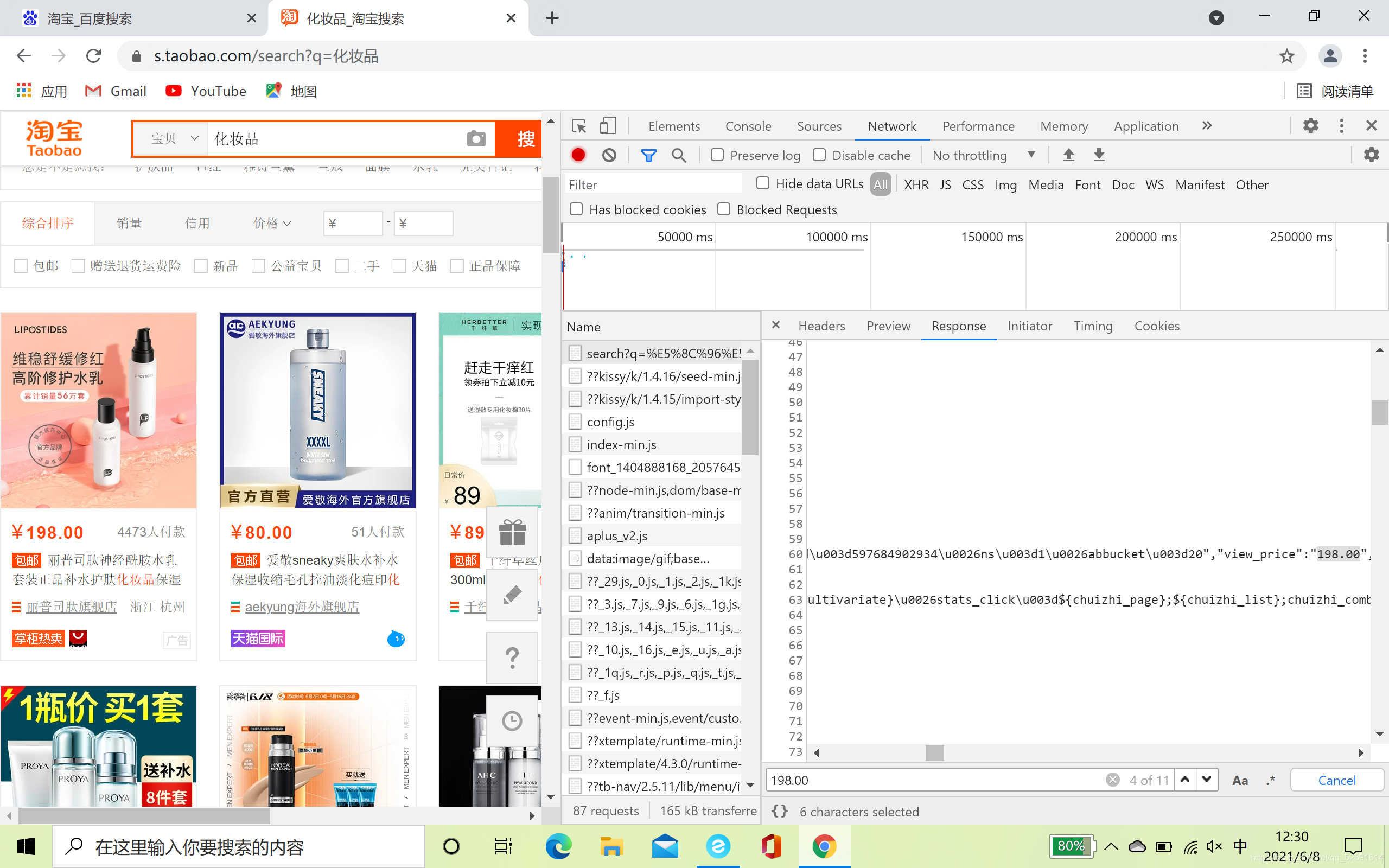
- 然后就看见了商品的信息也在这一行,也是以json字典的格式存储的

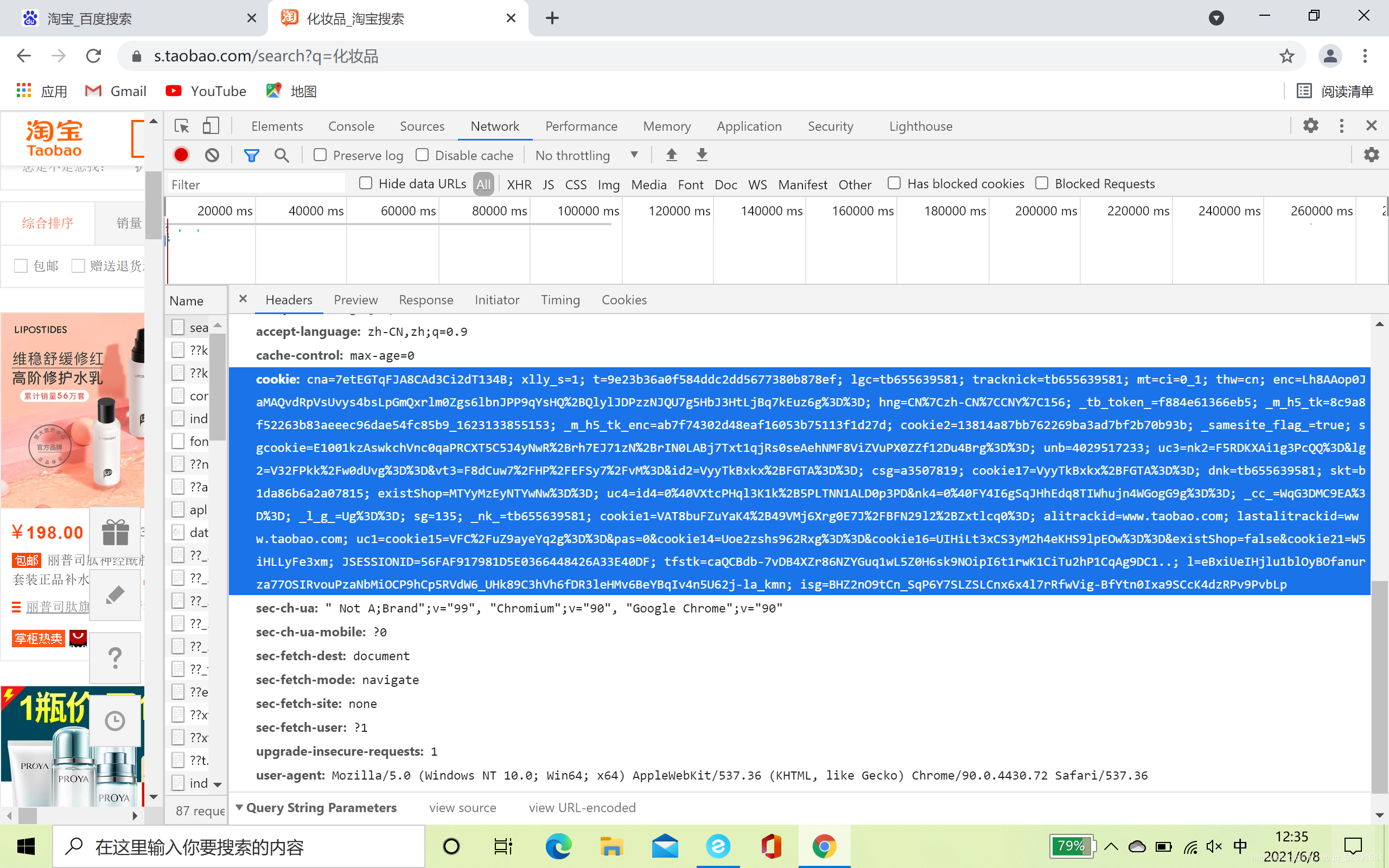
- 大概思路了解了,现在开始写代码了,要复制cookie和useragent,淘宝还是有一定反爬措施的。
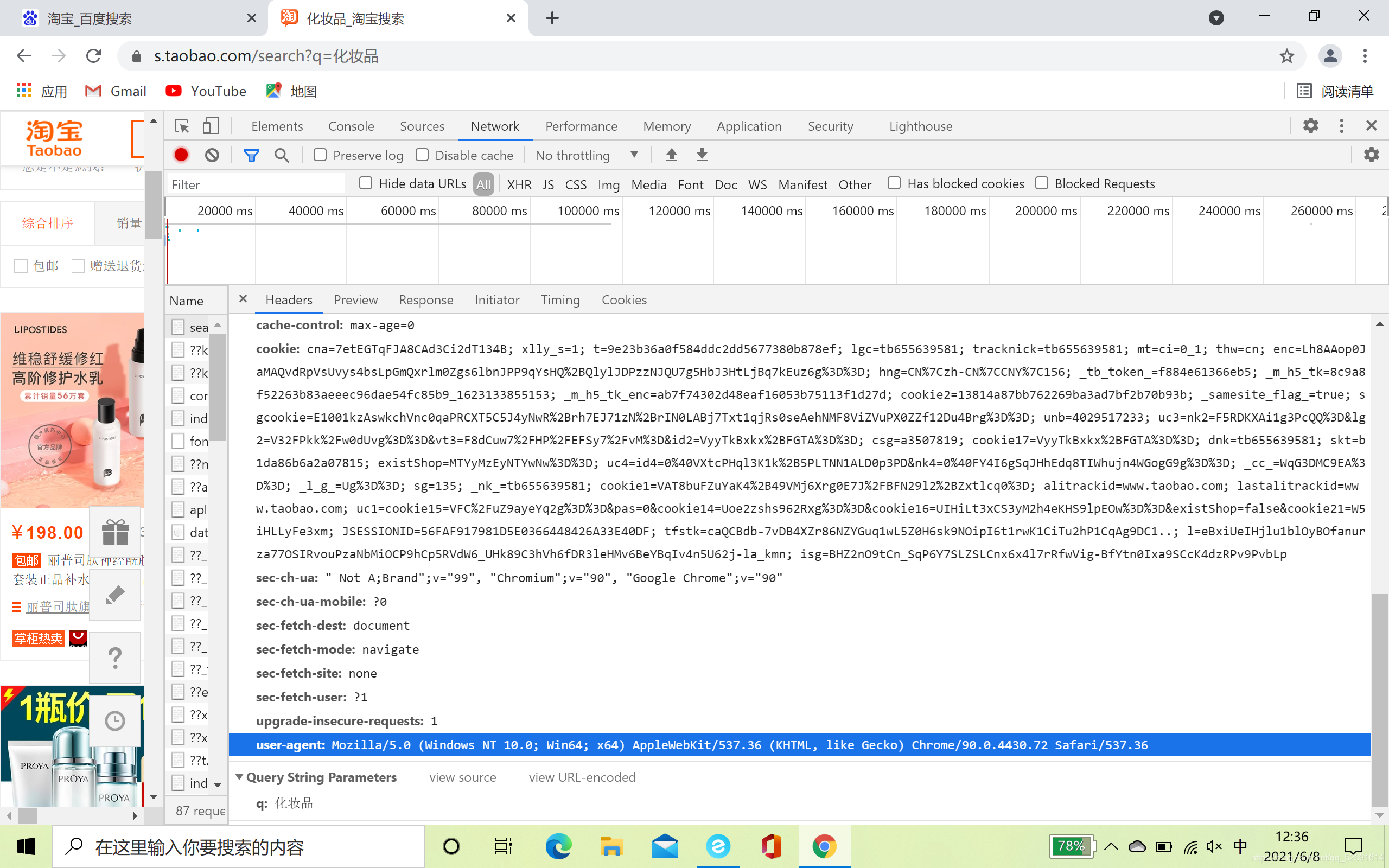
- 代码
import re
import requests
import time
url = "https://s.taobao.com/search?q=%E5%8C%96%E5%A6%86%E5%93%81&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.21814703.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306"
data = list()
# 请求首页函数
def get_data(url):
headers = {
'User-Agent': '自己从网页复制的',
'Cookie': '自己从网页复制的'
}
res = requests.get(url=url, headers=headers)
if res.status_code == 200:
print("请求成功")
response = res.content.decode('utf8')
return response
def parse_data(response):
#商品名,价格,成交额,店铺名称
shangpinming = re.findall(r'"raw_title":"(.*?)"', response)
print(shangpinming)
danjia = re.findall(r'"view_price":"(.*?)"', response)
print(danjia)
chengjiaoe = re.findall(r'"view_sales":"(.*?)人付款"', response)
print(chengjiaoe)
dianpumingcheng = re.findall(r'"nick":"(.*?)"',response)
print(dianpumingcheng)
# 执行函数 主程序
def main(num):
url = "https://s.taobao.com/search?q=%E5%8C%96%E5%A6%86%E5%93%81&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.21814703.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306"
html = get_data(url)
if html:
response = get_data(url)
df = parse_data(response)
print(df)
if __name__ == '__main__':
for i in range(1, 10):
main(i)
time.sleep(2)
-
运行结果
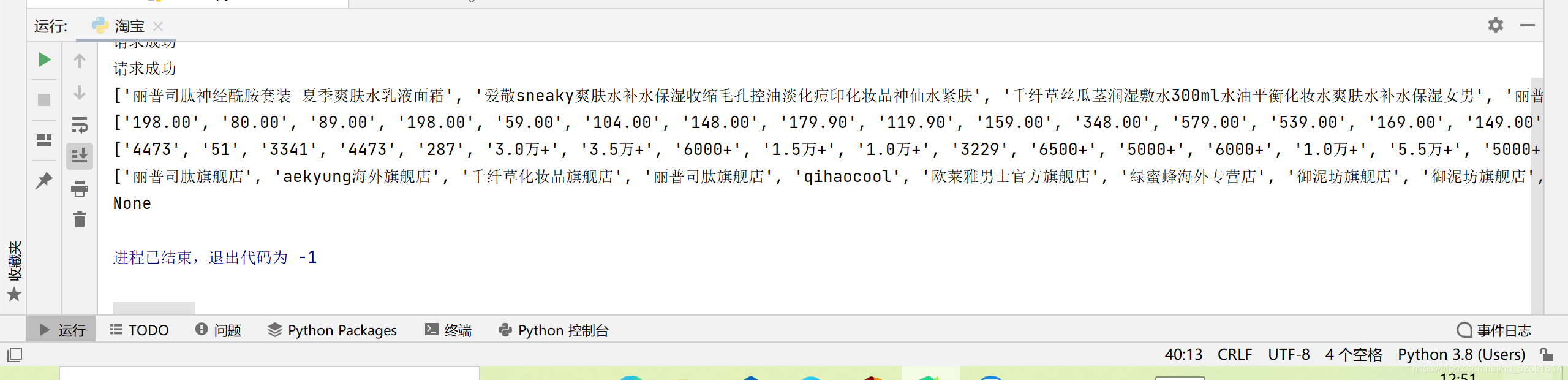
-
随后将数据存入表中即可,这里数据提取用的是正则,我简单列举一部分用法
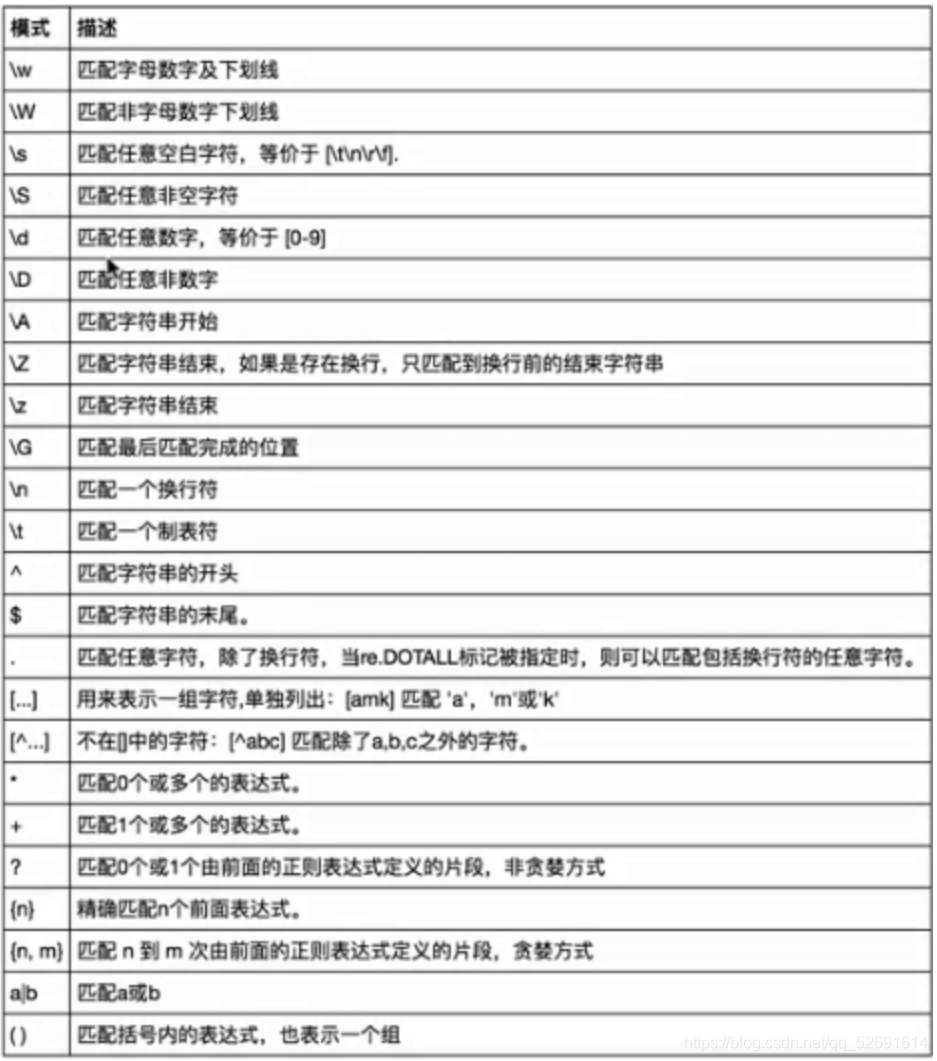
















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











