






GAN-Note
引言 Introduction
Generation: vector -> NN-generator = expect-output
Discrimination: output -> Discriminator = scale
算法
- 初始化生成器G和判别器D;
- 给G输入随机向量进行生成输出,输出与样本比较,更新D,让D学会区分真实样本和生成样本;
- 固定D,更新G,使G生成的样本在D的条件下获得更高分数.
- 重复2、3步

相关问题
生成器是否能自学习?
自动编解码器结构如下:
image -> NN-encoder -> vector -> NN-decoder -> image’
这其中的NN-encoder就相当于生成器.即训练一个自动编解码器,其中的NN-decoder可被当作自学习过的生成器.
但生成器是非线性的,当训练样本数量不足时,对于未见过的样本,生成效果不佳.此时可以用Variational Auto-encoder,其结构如下:
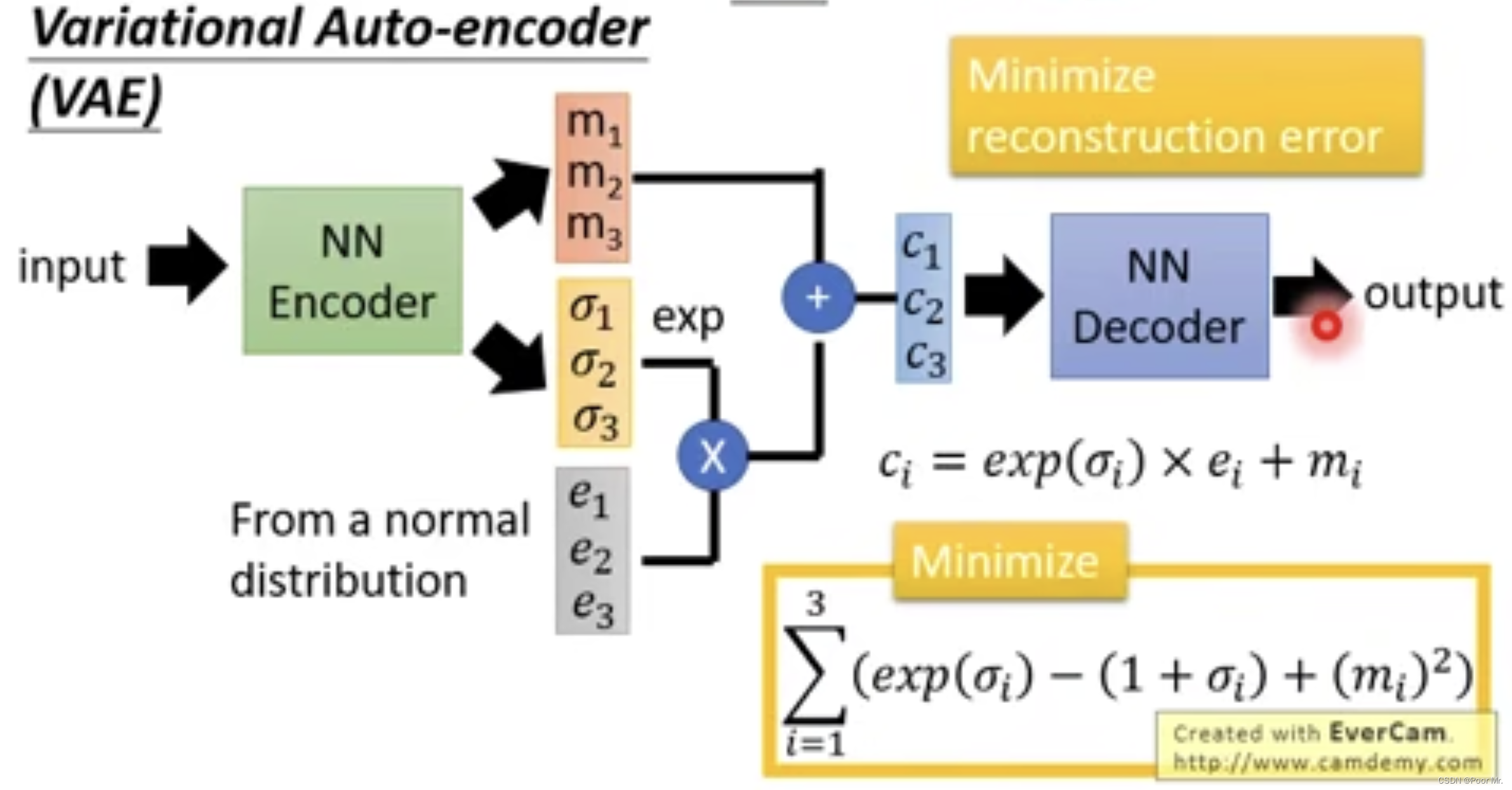
该方法通过在Encoder的输出向量中加入有关方差的扰动,从而增加Decoder的鲁棒性.
因此,生成器可以通过自动编解码器自学习.但是,也会造成几个问题.第一,像素级的评判标准不符合直观要求.第二,神经元之间相互隔离,需要更深的网络来建立联系.因为神经元对应的输出像素应该具有客观联系.
判别器能否生成?
可以.判别器之于生成器的优势在于判别器对于输出的打分是基于全局的,即判别器能学习到像素之间的关系.
判别器的生成规则是遍历所有输入x,将得分最高的x作为判别器的输出.
这种规则的缺点很明显:遍历x的代价太大.除此之外,训练样本分布会对这种规则下的判别器造成较大的影响(样本偏斜).因此样本的选取有较大的难度.
后一缺点的解决方法为:用上一轮训练的判别器去生成样本,用于替代下一轮的负样本. 直观解释为:判别器不断尝试主观正确的,不断修正其中客观错误的,最终使主观正确消除客观错误,拟合客观正确.
GAN的优势
- 从判别器来看:使用生成器来产生负样本
- 从生成器来看:生成阶段还是按元素进行对应,但判别器的全局观不会产生像素对像素的不符合主观印象的结果.
条件生成 Conditional Generation
Conditional GAN 和GAN的差别从生成器来说,生成器的输入除了原有的噪音向量,还多了一组条件输入; 判别器除了需要判别生成器输出质量,还要判别输入条件和生成器输出的符合度.
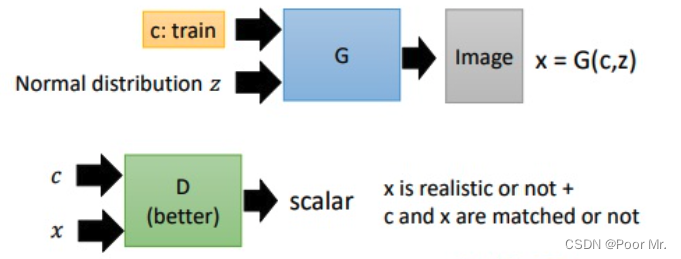
Text-to-Image
算法

目标函数增加了对于生成输出和条件输入不匹配的衡量.
判别器架构
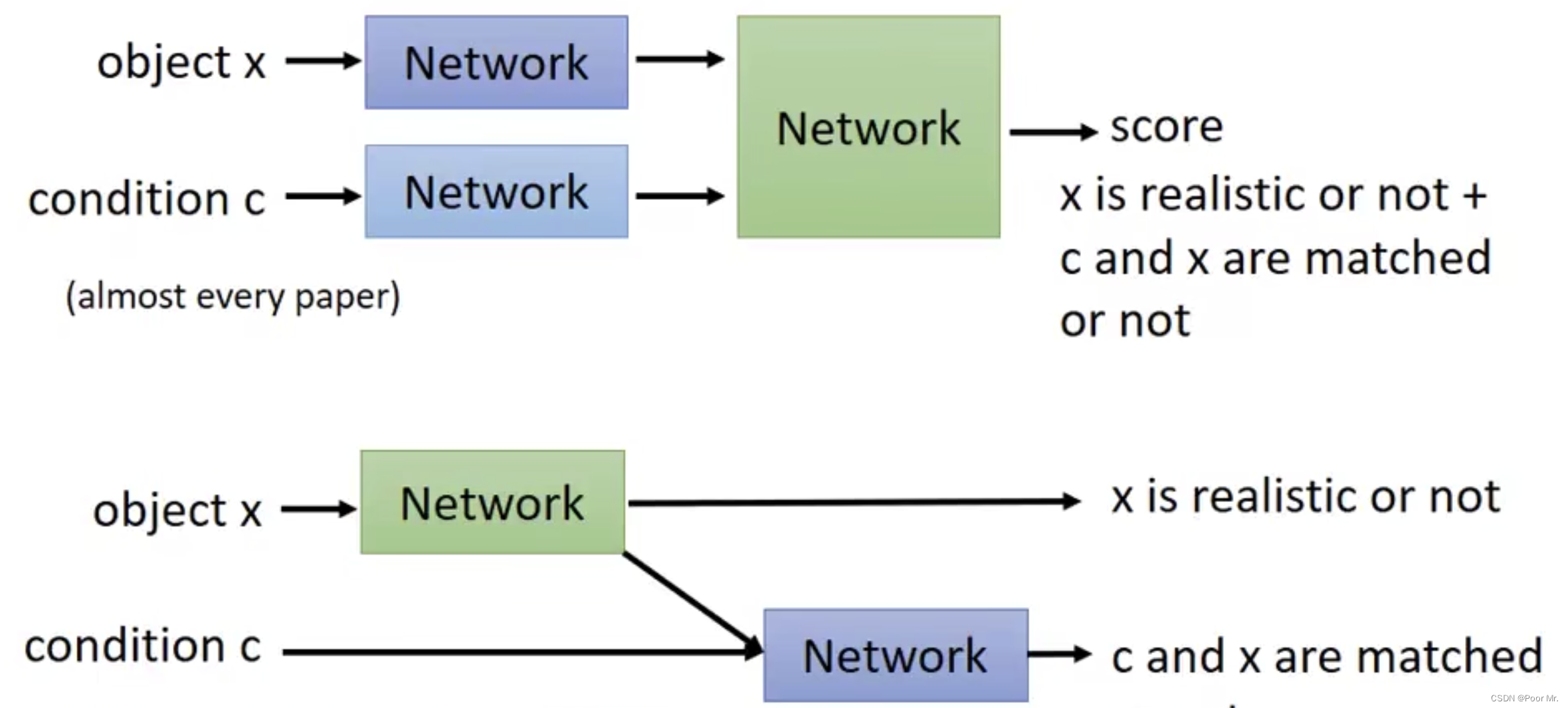
第二种相较于第一种,其分数能分别从真实度和匹配度来单独衡量.
Stack GAN
用两次Conditional GAN,先产生小图,再基于小图产生大图.
Image-to-Image
- 传统监督方法: 生成的图像和原图相似,但较为模糊;
- Conditional GAN: 生成的图像清晰,但和原图有一定差异.
因此,将两者结合,可以得到更好的效果
Patch GAN
对于输出较大的图像,判别器的大小如果覆盖整个图像,则参数量过多,容易造成过拟合.所以使用较小的判别器,每次只检查部分区域.
无监督条件生成 Unsupervised Conditional Generation
这里的无监督不是指没有标签,而是输入和输出类之间没有显式联系.
方法一: 直接转换法
直接用图像x生成图像y.这种端到端的方法,通常只能处理较为简单的任务,例如纹理或颜色的转换.
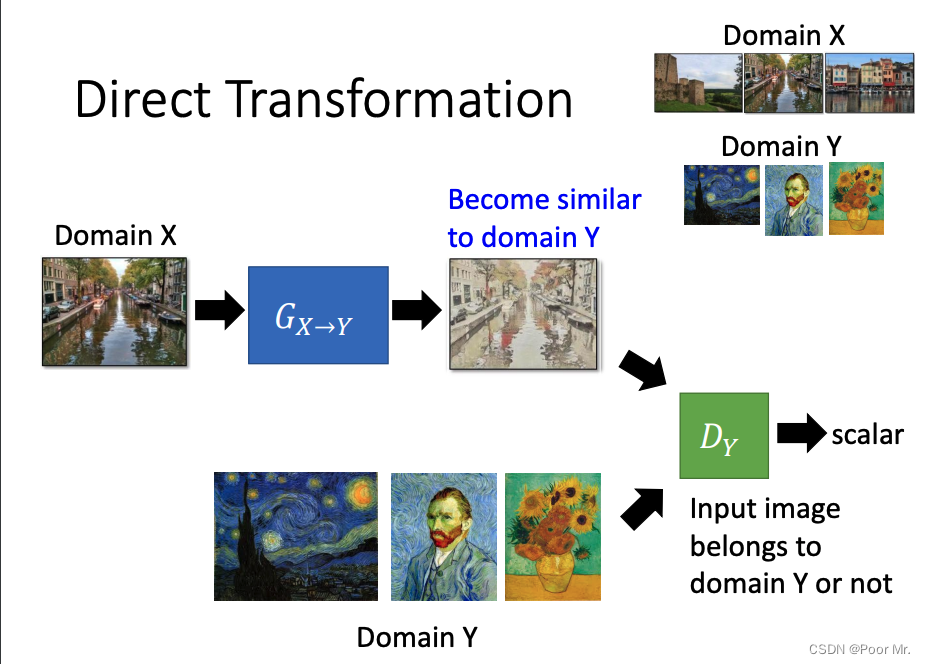
在生成器后添加一个类别检测器,来确保生成的图像属于类别Y. 除此之外,如果生成器的网络较深,可能会导致输入输出的差异较大,此时应该添加输入输出的相似度检测,保证输出的内容和输入保持一致.
CycleGAN
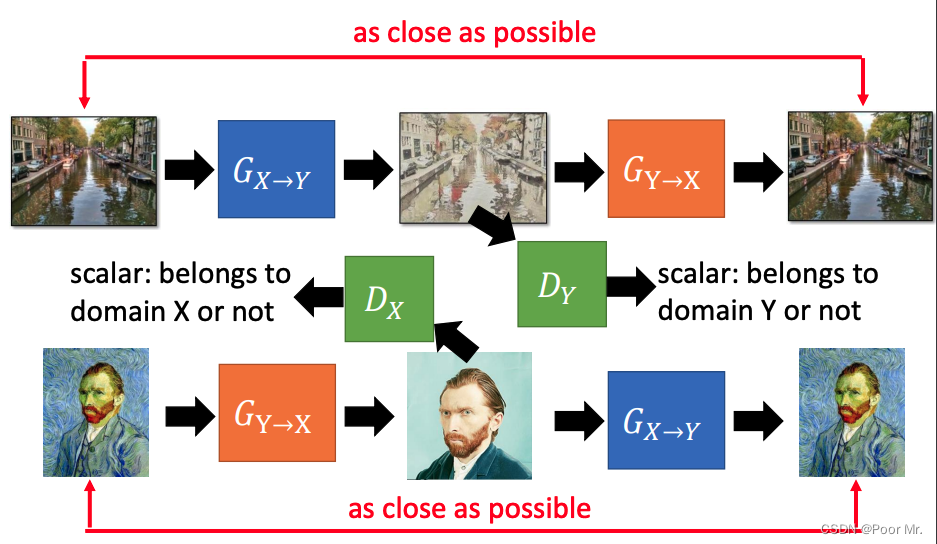
增加一个还原器,用于确保生成图片和原图片直接的相似度.
StarGAN
用于多个类别之间的互相转换.
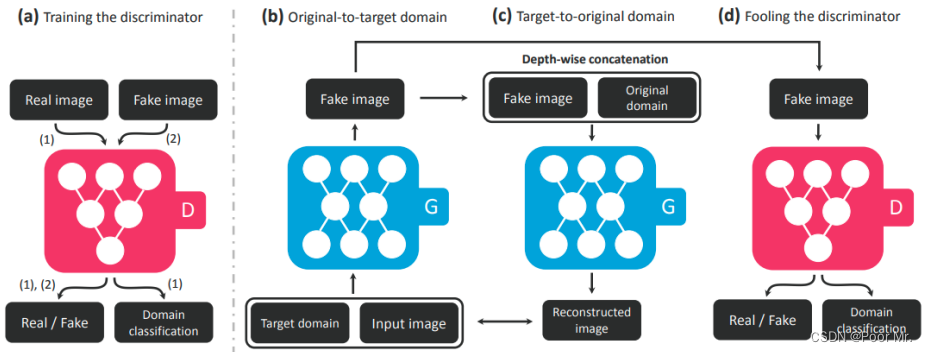
先训练一个判别器,既可以判别真假,又可以判别类别.再使用Cycle迭代生成图像,既要欺骗判别器,又要使生成图像和原始图像尽量接近.
主观上来看,StarGAN就是多类别的CycleGAN.
方法二: 空间映射法
将输入图像x的特征用Encoder抽取出来,利用特征进一步通过Decoder生成目标图像y.这种方法可以支持较大程度的变换.
训练
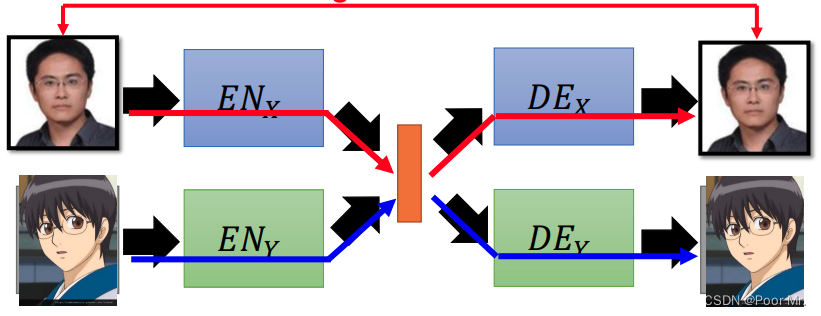
用同一类别的图训练同一类别的Encoder 和Decoder.但这种情况可能会出现特征抽取不一致的问题(两个Encoder对于特征的表达方式不同).解决该问题有以下几种方法:
- 两组Encoder的最后几层共享参数,两组Decoder的前面几层共享参数;
- 特征抽取后增加一个类别判别器,训练目标是欺骗该判别器,从而使两组Encoder的输出特征相似
- Cycle Consistency: X->ENx->DEy->ENy->DEx->X’.最小化X和X‘的重建误差.
- Semantic Consistency
声音转换
声音转换的大体和空间映射法差不多,好处在于将输入输出映射到相同的特征空间,避免了数据不匹配的问题.
基础理论 Basic Theory
生成图像的相似度分布满足概率分布函数.尝试去寻找参数来拟合对应的分布函数.用到的方法是最大似然估计.即最大化在假设参数θ的情况下,所有x出现的概率的 累积.
θ
∗
=
a
r
g
m
a
x
θ
∏
i
=
1
m
P
G
(
x
i
;
θ
)
\theta^* = \underset{\theta}{argmax}\prod^m_{i=1}P_G(x^i;\theta)
θ∗=θargmaxi=1∏mPG(xi;θ)
How to define the distribution?
在高斯分布中选取若干样本,分别通过一个定义分布的网络G,产生一个由诸多样本构成的分布PG.目标是找到网络G,使得分布PG和Pdata的差异尽量小.
G
∗
=
a
r
g
m
a
x
G
D
i
v
(
P
G
,
P
d
a
t
a
)
G^* = \underset{G}{argmax}Div(P_G, P_{data})
G∗=GargmaxDiv(PG,Pdata)
How to compute the divergence?
从database采样图片代替Pdata, 从高斯分布中采样向量并经过生成器产生图片代替PG. 利用判别器D来衡量两个分布的差异Div,即让真实图像得分更高,生成图像得分更低.
D
∗
=
a
r
g
m
a
x
D
{
E
[
l
o
g
D
(
x
d
a
t
a
)
]
+
E
[
l
o
g
(
1
−
D
(
x
G
)
)
]
}
D^* = \underset{D}{argmax}\{E[logD(x_{data})]+E[log(1-D(x_G))]\}
D∗=Dargmax{E[logD(xdata)]+E[log(1−D(xG))]}
这像是一个关于两个分布的二分类器
如果训练得到的目标分数越大,说明两个分布容易划分,即差异越大;分数越小,说明两个分布难以划分,即差异越小.
所以,divergence就是argmax内比较的目标函数V.因此优化生成器的方向便是寻找最优的映射网络G*:
G
∗
=
a
r
g
m
i
n
G
m
a
x
D
V
(
G
,
D
)
G^* = arg\underset{G}{min}\underset{D}{max}V(G,D)
G∗=argGminDmaxV(G,D)
直观上解释一下.V作为目标函数,一开始目标就是尽量区分正负样本,也就是要尽可能大.在训练完之后,如果V越小,说明两个分布采样出的样本越难划分,也就意味着两个分布越相似,生成器的效果越逼真.
GAN的通用框架 General Framework of GAN
f-divergence: 假设P和Q是两个不同的分布,p和q是对应的概率密度.若f(x)满足为凸函数且f(1)=0,则P和Q在f函数上的div为:
D
i
v
f
(
P
∣
∣
Q
)
=
∫
x
q
(
x
)
f
(
p
(
x
)
q
(
x
)
)
d
x
Div_f(P||Q)=\int_xq(x)f\left(\frac{p(x)}{q(x)}\right)dx
Divf(P∣∣Q)=∫xq(x)f(q(x)p(x))dx
(中间有一堆推导,放弃)
令P = Pdata, Q = PG, f* 为f的共轭函数,得
D
i
v
f
(
P
d
a
t
a
∣
∣
P
G
)
=
m
a
x
D
{
E
x
P
d
a
t
a
[
D
(
x
)
]
−
E
x
P
G
[
f
∗
(
D
(
x
)
)
]
}
Div_f(P_{data}||P_G)=\underset{D}{max}\{E_{x~P_{data}}[D(x)]-E_{x~P_{G}}[f^*(D(x))]\}
Divf(Pdata∣∣PG)=Dmax{Ex Pdata[D(x)]−Ex PG[f∗(D(x))]}
于是最优映射网络
G
∗
=
a
r
g
m
i
n
G
D
i
v
f
(
P
d
a
t
a
∣
∣
P
G
)
G^*=arg\underset{G}{min}Div_f(P_{data}||P_G)
G∗=argGminDivf(Pdata∣∣PG)
因此,通过变换f可以达到更换Div的计算方式,从而避免模型坍缩(PG分布变小,导致生成图像变化很小)或模型丢弃(PG分布只拟合了Pdata的部分分布,导致只生成某一种类型)等问题.
优化技巧 Tips for Improving
通常GAN使用的是JS-Div,这种情况下产生的两种分布往往没有交集,而两个没有交集的分布,其JS-Div等于log2.这会导致邻域的梯度都是0,难以训练.
不同的GAN尝试了不同的方法.
LSGAN
把sigmoid激活换成了linear.让梯度变成线性可训,而不是0或1.
WGAN
将JS-Div换成了Earth Mover’s-Distance.
Earth Mover’s-Distance
尝试将P分布转换为Q分布的方案称为moving-plan,所有moving-plan中距离最短的被称为Earth Mover’s-Distance.
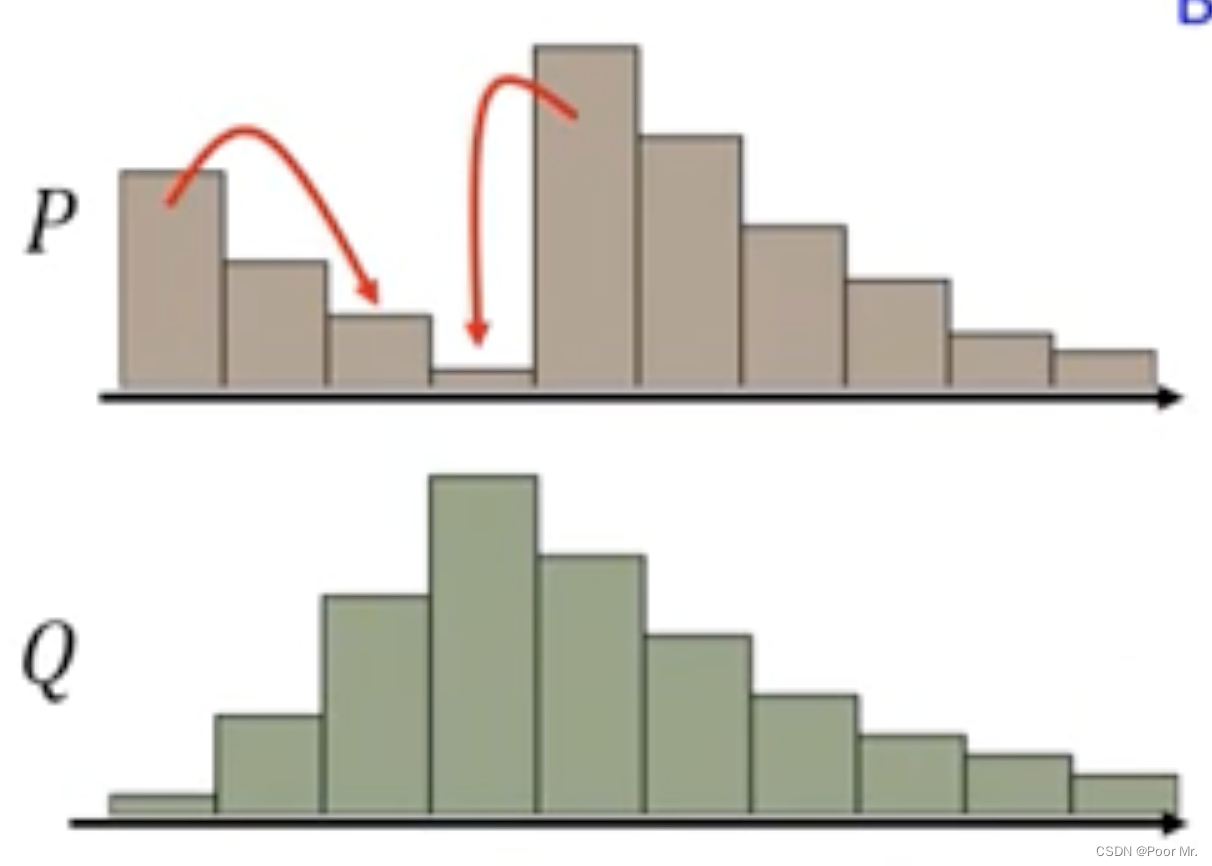
Earth Mover’s-Distance改变了JS-Div的非线性表现,使得优化器可以依此进行更新.
对应的目标函数
V
(
G
,
D
)
=
m
a
x
D
∈
1
−
L
i
p
s
c
h
i
t
z
{
E
x
P
d
a
t
a
[
D
(
x
)
]
−
E
x
P
G
[
D
(
x
)
]
}
V(G,D)=\underset{D\in 1-Lipschitz}{max}\{E_{x~P_{data}}[D(x)]-E_{x~P_{G}}[D(x)]\}
V(G,D)=D∈1−Lipschitzmax{Ex Pdata[D(x)]−Ex PG[D(x)]}
其中“1-Lipschitz”满足 || f(x1) - f(x2) || ≤ || x1 - x2 ||, 以此来确保判别器是平滑的.
然而,1-Lipschitz是很难去枚举的,尝试用各处梯度小于一这个条件去代替.
V
(
G
,
D
)
=
m
a
x
D
{
E
x
P
d
a
t
a
[
D
(
x
)
]
−
E
x
P
G
[
D
(
x
)
]
−
λ
E
x
P
p
e
n
a
l
t
y
[
m
a
x
(
0
,
∣
∣
∇
x
D
(
x
)
∣
∣
−
1
)
]
}
V(G,D)=\underset{D}{max}\{E_{x~P_{data}}[D(x)]-E_{x~P_{G}}[D(x)] -\lambda E_{x~P_{penalty}}[max(0, ||\nabla_xD(x)|| - 1)]\}
V(G,D)=Dmax{Ex Pdata[D(x)]−Ex PG[D(x)]−λEx Ppenalty[max(0,∣∣∇xD(x)∣∣−1)]}
其中,penalty的分布来自data和G分布任意两个采样的中点.
具体的算法改动如下:

(和上面的推导割裂感很强,不理解为什么要这么改)
EBGAN
用一个auto-encoder作为判别器,即用重构损失作为scale评价照片的真实性(重构损失越小,说明照片越真实).
优势在于,Auto-encoder可以被真实照片预训练,从而具有较好的重构能力,对真实图片的识别能力强,便具备较强的判别能力.
特征抽取 Feature Extraction
输入向量某一维度的改变对于输出的影响难以区分和解释.
InfoGAN
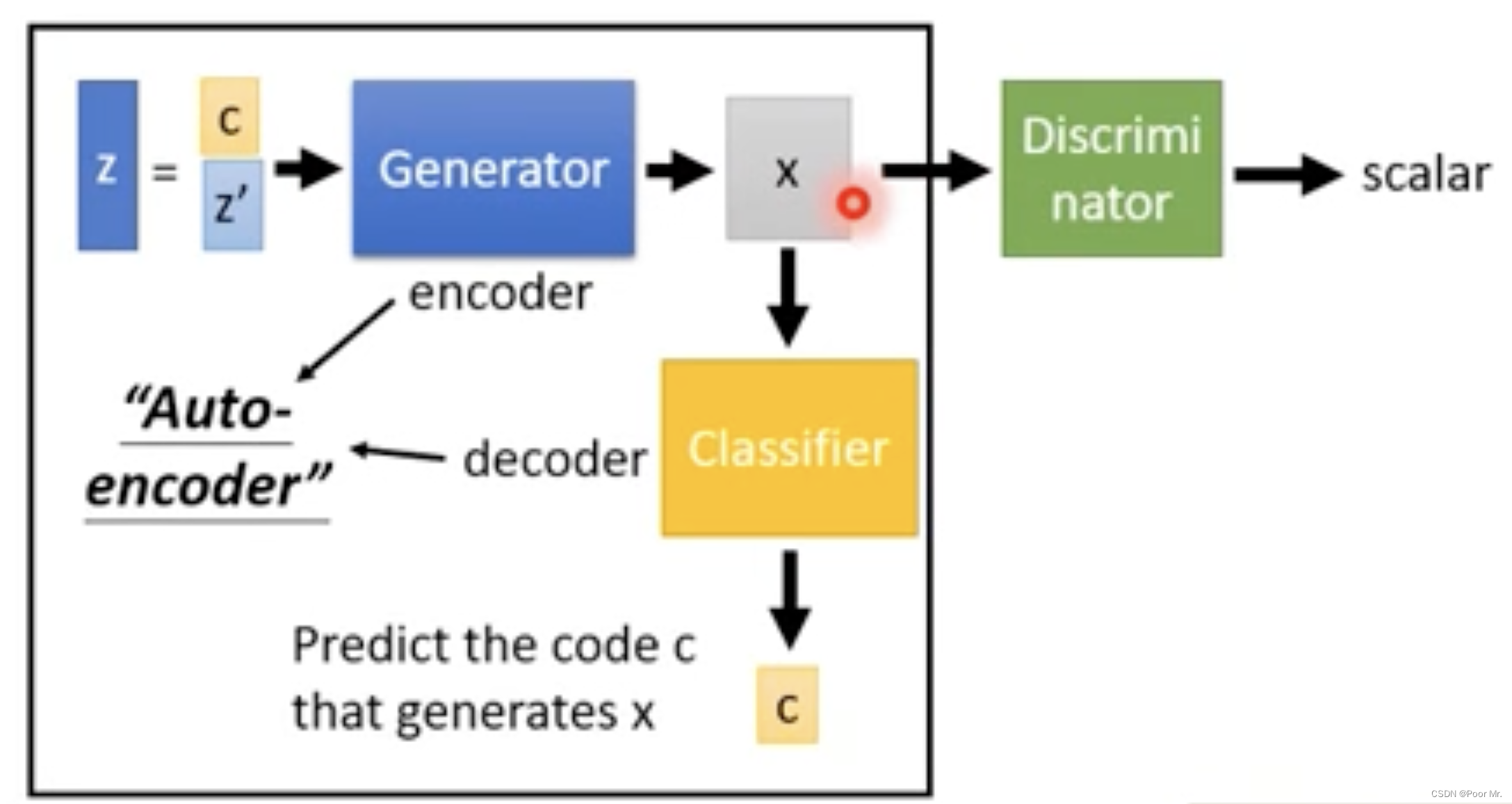
在GAN的基础上增加了对生成图片的Classifier,用于推理输入的c. 于是生成器有必要使c具有某些会对输出x产生明确影响的特征,从而有利于Classifier根据x推理出原来的c.
InfoGAN有效的通过特殊编码c的训练,使得生成器变得可控,增加了可解释性.
VAE-GAN
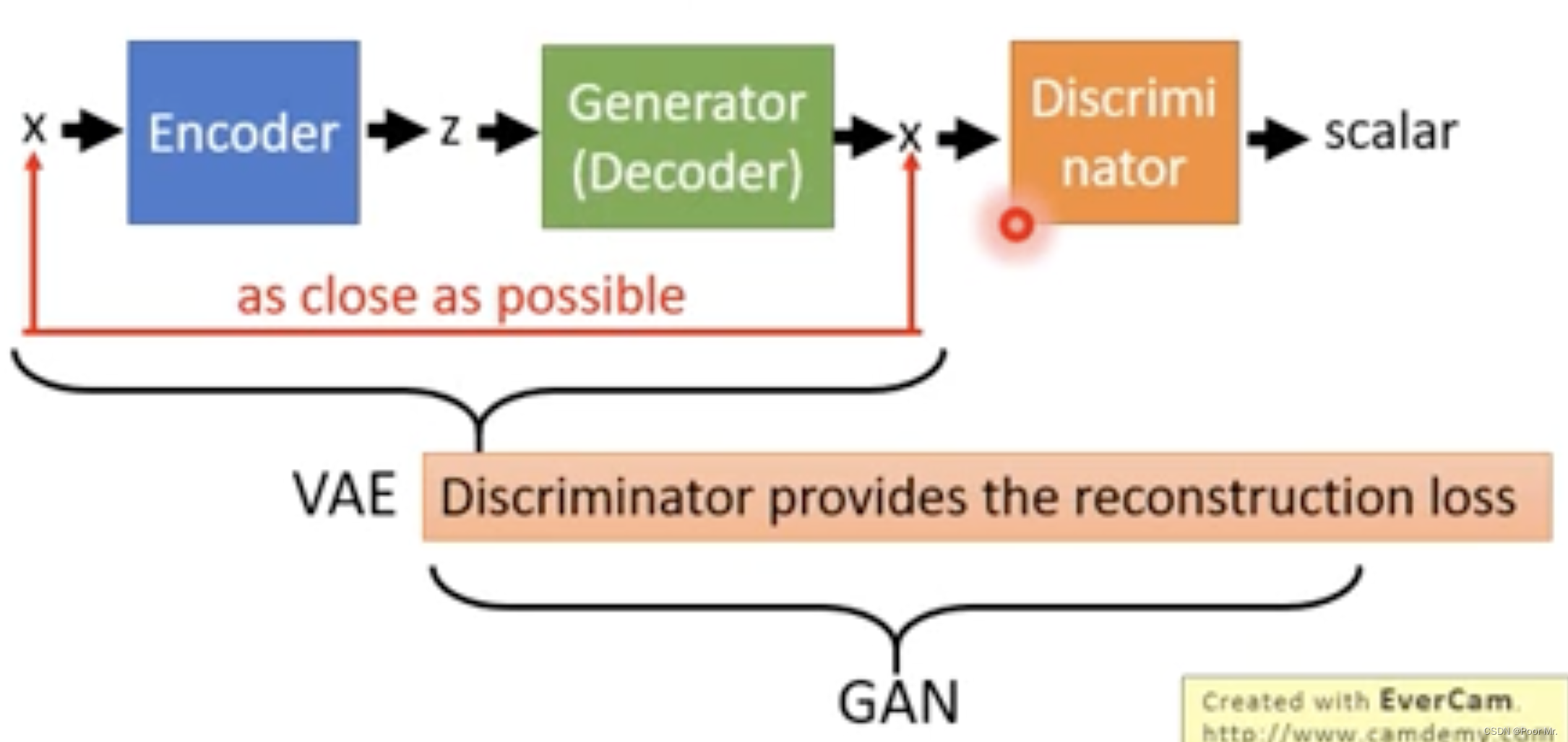
前半段VAE目标是使输入输出接近,但结果往往会比较模糊,不像是真实照片;后半段加入的判别器构成了GAN,使得输出图片可以向着真实(清晰)的方向进行优化.
算法如下:

一共会生成三类图像,真实、重建、虚假. 更新时,Encoder需要减少重建损失,并且减少Encoder编码和随机编码的Div; Decoder需要减少重建损失,并且增加重建和虚假间的差距; 判别器需要增加真实图像的可信度,并且减少重建与虚假的可信度.
BiGAN

将VAE的Encoder和Decoder拆开分别训练, 加入判别器用于判别向量-图片对的出处.训练的过程依旧是博弈,判别器尝试区分两者,编解码器尝试欺骗判别器.
训练结束即判别器无法区分时,说明Encoder和Decoder拥有相近的分布,此时的重构损失就极小了.
此外,BiGAN和AE有一定相似.两者有着相同的最优表现,但是两者的训练过程不同,而且不一定都能达到最优情况. BiGAN的结果可能是清晰但不同,AE的结果可能是模糊但相同.
我的理解是,BiGAN通过拆分编解码器进行训练,两者的分布即使可能相似(差异Div小),但对应的映射中,不同维度所代表的含义会不同, BiGAN学到了更多的语义信息.
Domain-adversarial training
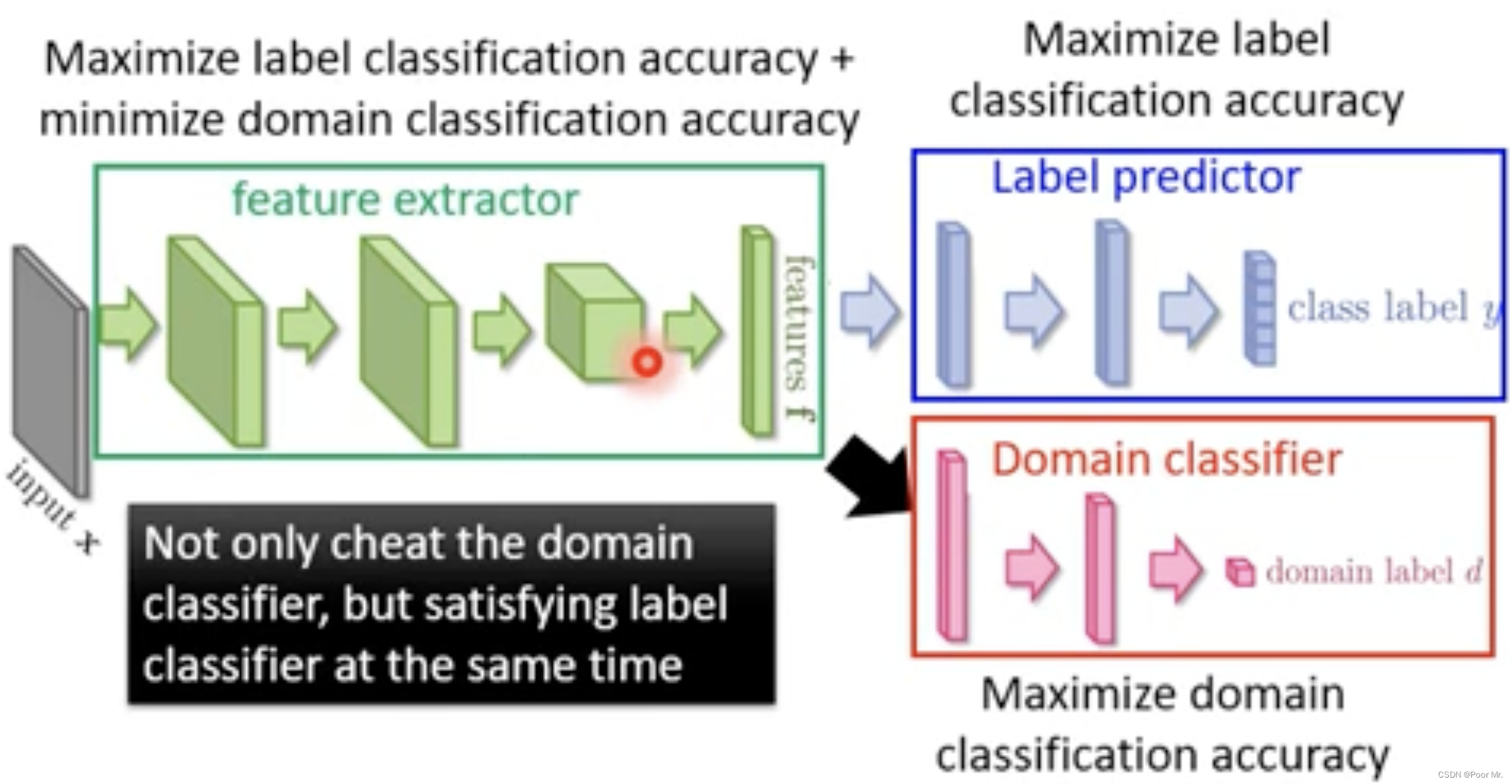
在训练中通过欺骗Domain Classifier来抽取映射中两个Domain的共同特征,剔除不利于欺骗的相异信息.
照片编辑 Photo Editing
GAN+Auto-encoder
已知生成器的输入向量每一维度都代表特定的特征.尝试寻找每一维度所对应的特征.
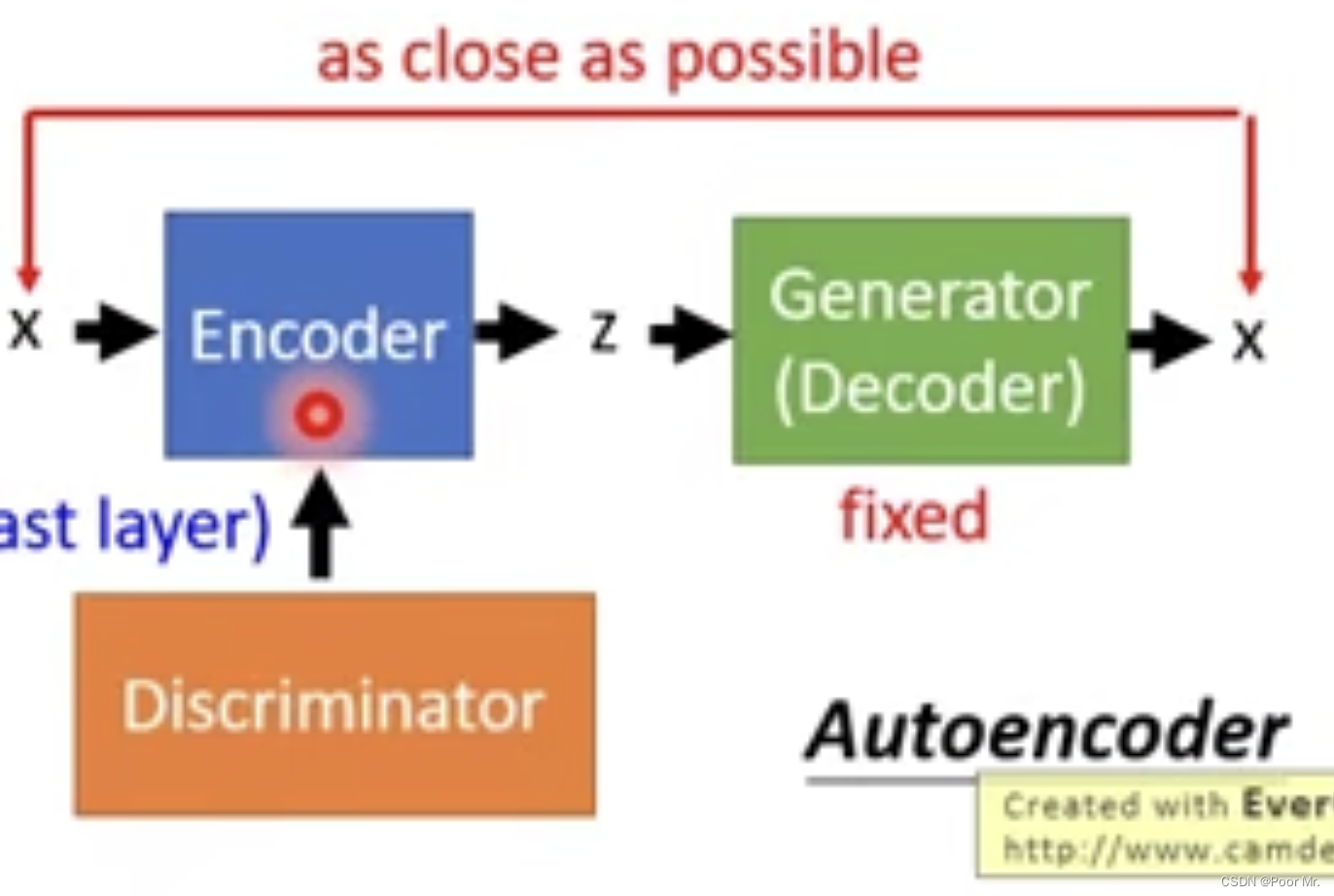
生成器是预训练的. 目的是训练一个Encoder,使其能够正确解析出对于生成器而言图片的向量表示.
Attribute Representation
将所有图片输入训练后的Encoder,得到对应的向量表示.
根据某种特征f 将图片分类,可以得到该特征的转移向量:
z
f
=
1
N
1
∑
x
∈
f
E
n
(
x
)
−
1
N
2
∑
x
′
∉
f
E
n
(
x
′
)
z_f = \frac{1}{N_1}\sum_{x\in f}En(x) -\frac{1}{N_2}\sum_{x' \notin f}En(x')
zf=N11x∈f∑En(x)−N21x′∈/f∑En(x′)
称zf为特征f的属性表示Attribute Representation.于是通过增加向量zf,就可以使没有特征f的图片转换为有特征f.
序列生成 Sequence Generation
条件序列生成
Reinforcement Learning (human feedback)
以chat-bot为例.
chatbot根据输入给出输出, 人类根据输入和输出给出Reward.
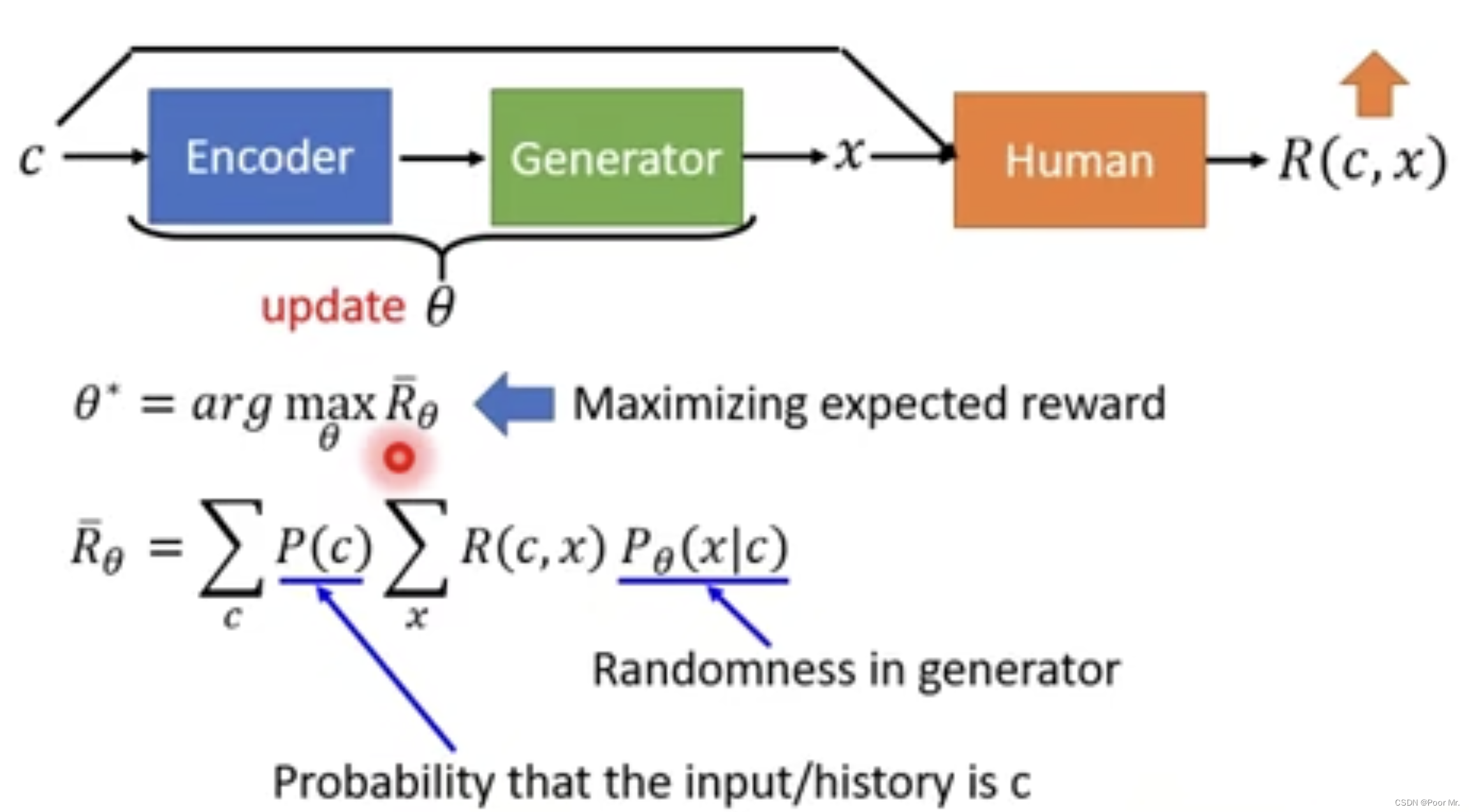
Rθ代表当前编解码器奖赏的期望,训练目标是最大化奖赏的期望.
然而现实中期望只能通过大量采样来拟合,这个过程中θ被隐藏在采样信息中,无法直接求梯度. 可以使用policy gradient:

注意:每次更新完参数,都要重新基于新的θ进行采样,进而进行下一步更新.
这种增强学习的方式,往往需要大量的人工评估,导致可行性不高.因此引入GAN中的判别器作为feedback.
GAN (discriminator feedback)
使用判别器代替人类,对于c-x对话 判别是否是真人对话. 与RL不同的是,判别器也要进行参数的更新. 其训练过程就是增加真实对话的Reward,减少生成对话的Reward.
课程中提到该方法会涉及sampling process,导致没有办法微分.不能理解...
无监督条件序列生成
Text Style Transfer
这和图像风格迁移一样,也有直接转换和映射转换.只是需要将数据从图像换成文本token序列.
Unsupervised Abstractive Summarization
用GAN的方式代替Seq2Seq的方式.将文本和摘要视为两个domain,依次来实现无监督的GAN.具体的实现和Cycle GAN类似.
Unsupervised Translation
和摘要的处理方式一样
评估 Evaluation
生成器关于图片的输出服从特定的分布,也就是说输出图片是有对应的概率的.但图片概率和图片质量没有绝对的联系.因此,将图片生成的概率用于评估的效果并不好.
可以通过下面方式进行评估:
- 预训练一个分类器,输出是关于类别的概率. 如果概率差距明显,说明容易判别,图片质量高.
- 生成多个图片,所有分布取平均,如果各类别均衡,则称为多样性.
所以评估标准便是单个类别清晰,多个类别均衡.可以用Inception Score来度量:
I
n
c
e
p
t
i
o
n
s
c
o
r
e
=
∑
x
∑
y
P
(
y
∣
x
)
l
o
g
P
(
y
∣
x
)
−
∑
y
P
(
y
)
l
o
g
P
(
y
)
Inception\;score =\sum_x\sum_y P(y|x)logP(y|x) - \sum_yP(y)logP(y)
Inceptionscore=x∑y∑P(y∣x)logP(y∣x)−y∑P(y)logP(y)
此外,不希望GAN记住train data中的内容,可以用K近邻来确保GAN生成了新的图片.















 2739
2739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









